“K2.6 là mô hình mã mạnh nhất của chúng tôi cho đến nay.” Kimi viết trên tài khoản công chúng.
Vào tối ngày 20 tháng 4, Kimi chính thức ra mắt mô hình mã nguồn mở K2.6 với khả năng lập trình và Agent mạnh mẽ hơn, cách thời điểm phát hành phiên bản trước đó K2.5 khoảng một quý.
Ở đây còn có một giai thoại nhỏ, có tin đồn rằng DeepSeek V4 cũng sẽ được ra mắt trong tuần này. Nếu mọi thứ diễn ra theo dự đoán của giới bên ngoài, đây sẽ là lần thứ N Kimi và DeepSeek “đụng độ”. Nhưng ở tầng cơ sở hạ tầng sâu hơn, còn có một tuyến ngầm: Kimi và DeepSeek, hai công ty khởi nghiệp mô hình lớn, cuối cùng sẽ bước vào cùng một dòng sông – cùng tiến thoái với các công ty khởi nghiệp chip trong nước.
Quay ngược thời gian về tháng 3 năm 2026, Dương Chí Lân (Yang Zhilin) đã có bài phát biểu trên sân khấu GTC của NVIDIA, đề cập đến lộ trình công nghệ của Kimi. Ông nói: “Nhiều tiêu chuẩn công nghệ đang được sử dụng phổ biến hiện nay, về bản chất là sản phẩm của tám chín năm trước, dần dần trở thành nút thắt cổ chai cho Scaling.”
Để giải quyết các vấn đề tương tự, Kimi đã đóng góp cho cộng đồng mã nguồn mở bộ tối ưu hóa bậc hai MuonClip được ứng dụng quy mô lớn lần đầu tiên, kiến trúc Kimi Linear giúp mô hình lớn xử lý ngữ cảnh dài hiệu quả hơn, và Attention Residuals tối ưu hóa kết nối các lớp mạng neural sâu.
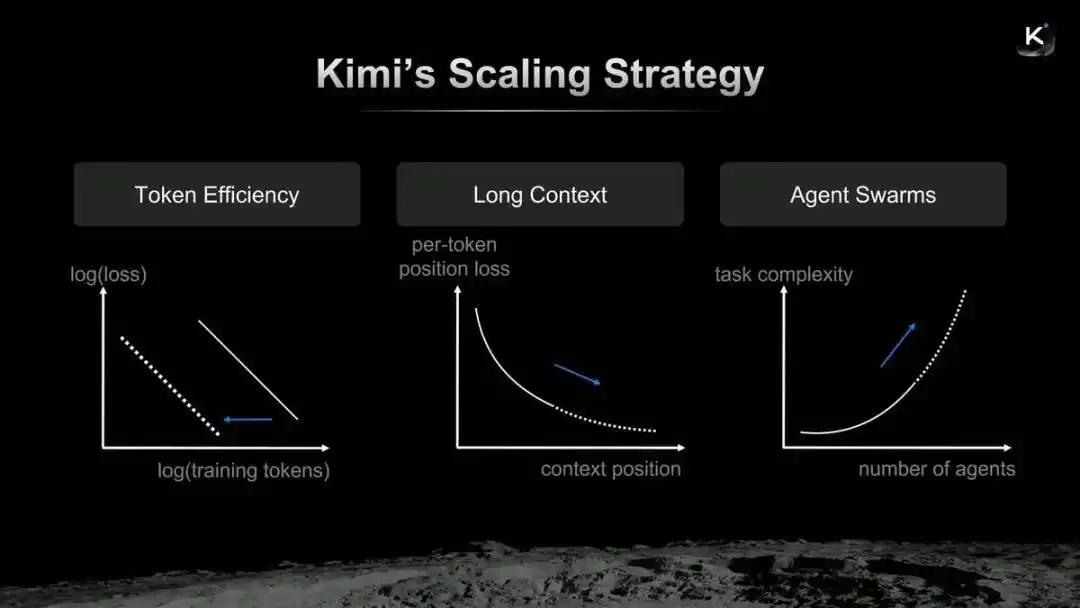
Chiến lược Scaling của Kimi
Dương Chí Lân cho rằng, có thể quy nạp logic tiến hóa của Kimi thành hiệu suất Token, ngữ cảnh dài và sự “hợp thể” của cụm Agent. Phiên bản Kimi K2.6 vừa ra mắt có thể hiểu là một bài tập mới mà Dương Chí Lân nộp trên con đường Scaling này.
Trang web chính thức của Kimi đã tích hợp K2.6
Mã code, Agent, và còn gì nữa?
Là một trong những khả năng dễ chuẩn hóa nhất, mã code là chiến địa bắt buộc của các mô hình tiên phong.
Từ K2, đến K2.5, rồi đến K2.6, Kimi duy trì nhịp độ lặp lại trung bình khoảng một quý trên một số mô hình mã nguồn mở, nhưng vì đây là một số phiên bản nhỏ, nó ngụ ý rằng Dương Chí Lân có lẽ còn nắm giữ nhiều lá bài át chủ bài hơn.
“Khả năng mã hóa đường dài của K2.6 được cải thiện đáng kể, trong thử nghiệm có thể mã hóa liên tục 13 giờ, viết hoặc sửa đổi hơn 4000 dòng code,” Kimi viết trong một tài liệu truyền thông, “Trên Kimi Code Bench, chuẩn đánh giá mã nội bộ nghiêm ngặt của Kimi bao gồm nhiều tác vụ đầu cuối phức tạp, điểm số của K2.6 đã tăng khoảng 20% so với K2.5.”
Hãy nhớ rằng K2.5 đã là một mô hình rất “mạnh mẽ”, từng đứng đầu bảng xếp hạng trên OpenRouter vào tháng 2. Một người trong cuộc gần gũi với Kimi đã đăng tải ảnh chụp màn hình lúc đó trên Moments của WeChat của người đồng sáng lập Trương Vũ Thao (Zhang Yutao), “Anh ấy dường như rất hài lòng với phiên bản này.”

Hiệu suất của K2.6 trên các bài kiểm tra chuẩn Agent tổng quát, lập trình và Agent thị giác
Đối với các framework Agent như OpenClaw, Hermes, cải tiến cốt lõi của K2.6 tập trung vào độ chính xác của việc gọi API và tính ổn định của hoạt động chạy lâu dài – một là nâng cao chi phí thực thi tác vụ, một là tối ưu hóa hiệu suất chi phí thực thi tác vụ.
Trong K2.5 ra mắt vào tháng 1, Kimi đã đề xuất khái niệm “cụm Agent”, chia nhỏ một tác vụ thành nhiều dự án con, tự động phân bổ cho các Agent thuộc các lĩnh vực khác nhau để theo dõi xử lý, từ đó rút ngắn thời gian xử lý tác vụ, đồng thời tránh khả năng toàn bộ dự án sụp đổ dưới luồng tác vụ nối tiếp.
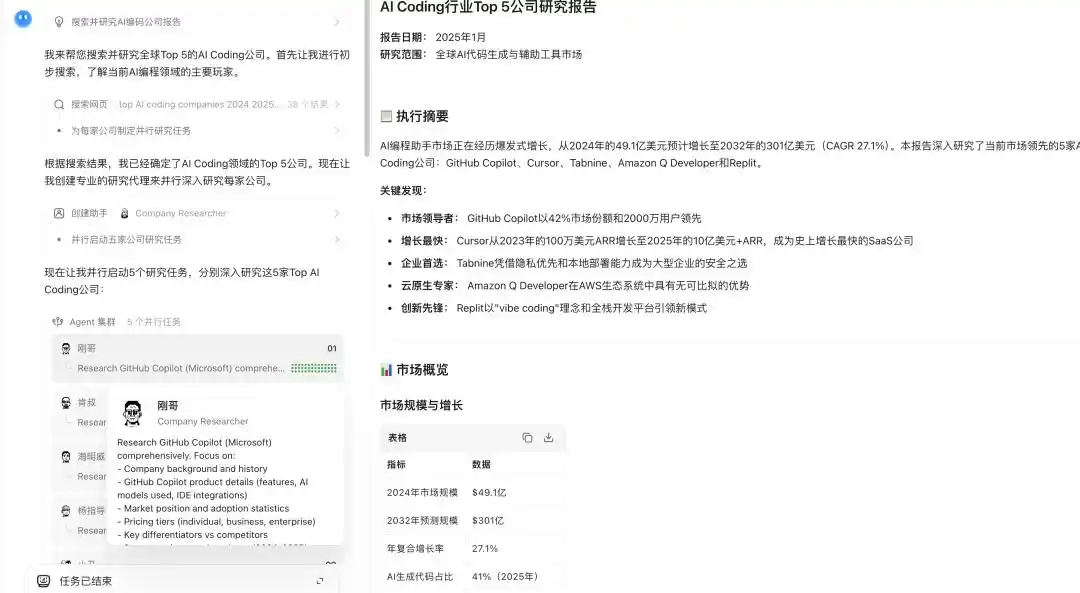
Trình diễn khả năng cụm Agent của Kimi K2.6
Trong phiên bản K2.6 mới, khả năng này được mở rộng hơn nữa, tích hợp xử lý song song tìm kiếm rộng và nghiên cứu sâu, phân tích tài liệu quy mô lớn và soạn thảo văn bản dài, cũng như tạo nội dung đa định dạng, hỗ trợ tối đa 300 Agent con hoàn thành song song 4000 bước hợp tác.
Nếu phải tóm tắt điểm nổi bật của Kimi K2.6 trong một câu, đại khái bao gồm: tiến hóa khả năng mã code và tác vụ đường dài, tiến hóa khả năng cụm Agent và tối ưu hóa khả năng tương thích với các framework Agent chủ đạo.
Nếu phải chọn một sở thích cá nhân từ các đặc tính chức năng trên, tôi cho rằng cụm Agent là khả năng có giá trị nhất, nó trực tiếp cụ thể hóa khả năng bùng nổ của tính toán song song – cho dù là mã code, hay tính ổn định của tác vụ đường dài, đây đều là những việc mà sự lặp lại mô hình phải làm, quan trọng hơn là, dựa trên những cải thiện khả năng này, thúc đẩy cách thức làm việc, hiệu suất và thậm chí là cách tương tác của Agent đổi mới.
Rốt cuộc, với tư cách là người dùng, tôi cần không phải là nó nói với tôi nó có thể làm thế nào, mà là nó có thể điều khiển Agent để giải quyết vấn đề thực tế của tôi, hình thành năng suất hiệu quả.
Khi K2.5 ra mắt, một nhà nghiên cứu trong giới học thuật đã bắt đầu sử dụng mô hình này để triển khai dự án nghiên cứu, đánh giá lúc đó là không có điểm yếu, có thể làm trợ lý nghiên cứu.
“Đa-Agent do chính thức cung cấp thực sự hiệu quả, năm ngoái nhiều Agent trong nước vẫn chỉ là đồ chơi.”
Nếu K2.5 của Kimi được đánh giá tốt cả trong và ngoài, thì K2.6 tiến thêm một bước trên cơ sở này, hiệu quả sẽ ra sao?
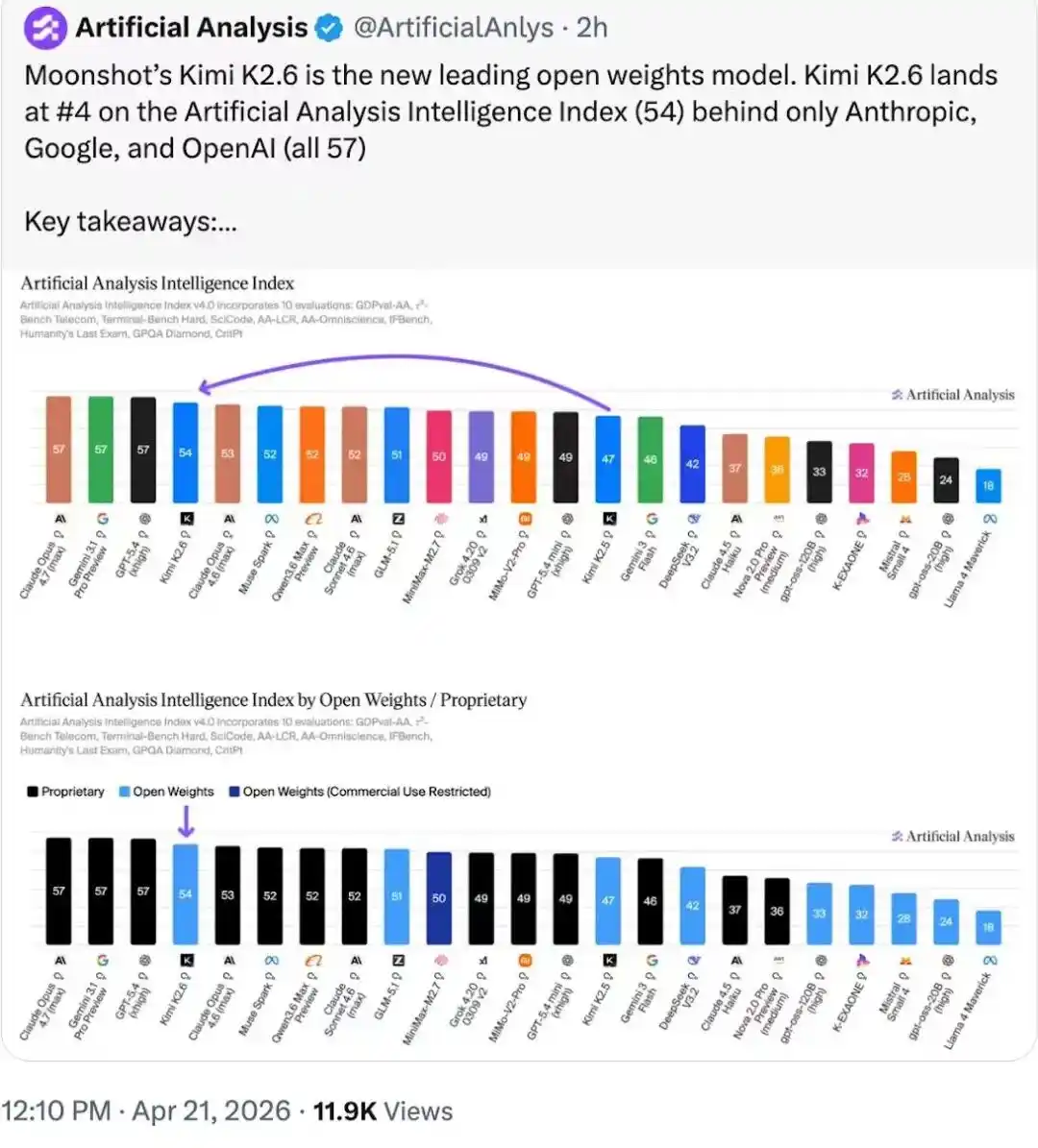
Bảng xếp hạng thông minh Artifacial Analysis, Kimi K2.6 chỉ đứng sau ba mô hình đóng, và dẫn đầu bảng xếp hạng trọng số mô hình mã nguồn mở
“Câu chuyện mới” trong lộ trình
Kimi luôn thỉnh thoảng tạo ra chút mới mẻ cho ngành, trong đó bao gồm MuonClip, Kimi Linear, Attention Residuals được đề cập trong lộ trình bài phát biểu của Dương Chí Lân, một số khám phá cũng nhận được sự ủng hộ tích cực từ giới đỉnh cao trong ngành.
Giữa tháng 3, Kimi công bố bài báo Attention Residuals, đề xuất sử dụng cơ chế chú ý để cải tạo kết nối dư, Musk trực tiếp đăng tweet cho rằng đây là “bước đột phá ấn tượng do Kimi thực hiện.”

Cuối tuần trước, Kimi đã công bố một bài báo mới 《Prefill-as-a-Service: KVCache of Next-Generation Models Could Go Cross-Datacenter》, (PrfaaS, dịch vụ tiền điền), đề cập đến khám phá mới về kiến trúc của Kimi, cốt lõi vẫn thảo luận về PD separation (Prefill và Decode).
PD separation không phải là chủ đề mới – giai đoạn Prefill của suy luận mô hình thuộc về tác vụ tập trung tính toán, giai đoạn Decode thì phụ thuộc vào băng thông bộ nhớ, bộ nhớ phải đọc ghi đi ghi lại KV Cache – kiến trúc này nhằm giải quyết việc tách rời tác vụ tập trung tính toán và tác vụ tập trung băng thông, nâng cao tỷ lệ sử dụng và thông lượng tính toán, từ đó giảm chi phí và tăng hiệu quả.
PD separation tuy tốt, nhưng cũng có một điểm nghẽn: phải dựa trên mạng tốc độ cao RDMA cùng phòng máy.
Điểm cốt lõi của bài báo PrfaaS của Kimi là: dựa trên mô hình hỗn hợp (Kimi Linear) thu nhỏ đáng kể thể tích bộ nhớ đệm KV, sau đó tách rời hoàn toàn Prefill và Decode thành các cụm dị thể khác nhau.
Ví dụ thử nghiệm được đề cập trong bài báo cho thấy, cụm tiền điền chuyên dụng PrfaaS sử dụng 32 H200 chủ đạo có tính toán cao; cụm giải mã PD cục bộ sử dụng 64 GPU H20 kết nối nội bộ qua RDMA; hai cụm thông qua đường truyền chuyên dụng VPC, tổng băng thông xuyên cụm khoảng 100Gbps. Mô hình thử nghiệm là mô hình hỗn hợp chú ý Kimi Linear tham số 1T.
Kết quả đo thực tế cho thấy, so với phương án cụm PD cùng 96 card H20, phương án PrfaaS‐PD xuyên trung tâm dữ liệu đã nâng thông lượng lên 54%, P90 TTFT (90% người dùng, thời gian chờ đợi từ khi gửi yêu cầu đến khi thấy chữ đầu tiên trả về) từ 9.73s giảm xuống 3.51s, giảm 64%, băng thông truyền KV cache xuyên trung tâm dữ liệu chỉ chiếm 13% tổng băng thông 100Gbps.
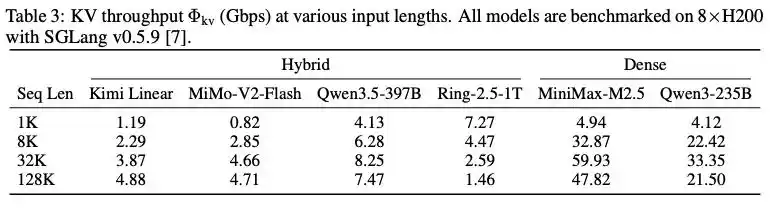
So sánh thông lượng KV giữa mô hình kiến trúc hỗn hợp và mô hình đặc ở các độ dài ngữ cảnh khác nhau
Để chứng minh ưu thế của kiến trúc mô hình hỗn hợp, bài báo đề cập đến một thí nghiệm: trên 8 card H200 và framework suy luận SGLang v0.5.9, tiến hành kiểm tra chuẩn cho nhiều mô hình chủ đạo, ở độ dài ngữ cảnh 32K, thông lượng KV của mô hình hỗn hợp chú ý MiMo‐V2‐Flash chỉ 4.66Gbps, trong khi mô hình chú ý đặc cùng quy mô MiniMax‐M2.5 cao tới 59.93Gbps, trực tiếp chứng minh kiến trúc chú ý hỗn hợp có thể nén nhu cầu truyền KV cache đến phạm vi mà mạng Ethernet thông thường có thể chịu tải.
“Xuyên trung tâm dữ liệu + phần cứng dị thể, mở khóa tiềm năng giảm đáng kể chi phí token đơn.” Kimi nói trên tài khoản chính thức.
Về giảm chi phí Token, tôi đã đề cập trong bài 《Nhân dân nhớ đến DeepSeek》 rằng, cả mô hình và phần cứng đều có không gian tối ưu hóa, Giáo sư Hồ Diên Bình (Hu Yanping) của Đại học Tài chính Kinh tế Thượng Hải đã đặc biệt đăng một dòng trên Moments của WeChat, nhấn mạnh việc giảm chi phí này không thể chỉ dựa vào một DeepSeek, “Việc giải quyết vấn đề phụ thuộc vào hiệu suất chi phí của cung cấp năng lực tính toán, sự nâng cấp xuyên thế hệ của chất lượng mô hình, sự tiến bộ liên tục của mô hình thông minh, hiệu ứng khuếch đại của việc kéo thông luồng công việc và kịch bản.”
Từ góc độ này, Kimi lại kể cho ngành một câu chuyện mới về giảm chi phí Token.
Mô hình Trung Quốc triệu hồi chip Trung Quốc
Trong bài báo về dịch vụ tiền điền, nhiều người chỉ chú ý đến tường thuật xuyên trung tâm dữ liệu, mà bỏ qua điểm phần cứng dị thể.
Cần lưu ý, H200 và H20 về kiến trúc chip vẫn là kiến trúc Hopper, phần cứng dị thể được đề cập trong bài báo ám chỉ sự dị thể về băng thông và tính toán, gợi mở của nó là: chúng ta có thể sử dụng một phần card trong nước mạnh về tính toán để làm Prefill, hoặc card trong nước mạnh về băng thông để làm Decode, tất nhiên cũng có thể trộn dùng với card nước ngoài để đạt được giảm chi phí tăng hiệu quả.
Có thể nói, đây là cánh cửa mà Kimi mở ra cho chip Trung Quốc trong việc suy luận mô hình lớn.
Theo quan điểm của một nhân sự năng lực tính toán trong nước, để đón làn sóng lợi ích lưu lượng do phương án dịch vụ tiền điền mang lại, vẫn phải đối mặt với vấn đề sinh thái cũ này.
Mấy năm qua, mô hình lớn Trung Quốc luôn bị ngăn ngoài năng lực tính toán trong nước vì khó khăn về sinh thái, nhưng còn một chi tiết khác không được chú ý: sản phẩm như H20, đã ngừng cung cấp một năm rồi. Nói cách khác, chip suy luận trong ngắn hạn chỉ có một lựa chọn là trong nước.
Với nhu cầu suy luận bùng nổ, so với cung cấp, thách thức sinh thái sẽ chuyển thành vấn đề thứ yếu – sự phụ thuộc của mô hình lớn Trung Quốc vào năng lực tính toán trong nước từ chỗ dùng hay không dùng cũng được, chuyển thành không dùng không được. Cũng vì điểm này, nhiều dự đoán đang thảo luận rằng DeepSeek V4 đang thích ứng với năng lực tính toán trong nước.
Tôi và thầy Hồ Diên Bình đã nói trong 《Lá thư thúc giục cuối cùng gửi DeepSeek》 rằng, thích ứng với năng lực tính toán trong nước, con đường này rất khó khăn đối với mô hình trong nước, nhưng nhìn từ thời gian dài hơn thì không thể không làm. Một việc không thể không làm, luôn phải có điểm khởi đầu, có lẽ DeepSeek V4 chính là điểm khởi đầu đó.
Bây giờ, DeepSeek V4 vẫn chưa tới, mà Kimi đã dùng thực tiễn của mình, thăm dò một con đường khả thi cho sự kết hợp mô hình Trung Quốc + chip Trung Quốc.
Kimi đi đầu làm đại diện mô hình đưa ra cành ô liu, vấn đề bây giờ giao cho các công ty khởi nghiệp chip trong nước.
Mọi người còn nhớ trong podcast mới nhất của 《the Dwarkesh Podcast》, phản ứng của Hoàng Nhân Tốn (Huang Renxun) khi được hỏi về cấm xuất khẩu chip sang Trung Quốc không? Ông nói, chip không phải là làm giàu uranium, cấm bán không thể ngăn cản tiến bộ chip Trung Quốc, họ vẫn có thể thông qua xếp chồng bạo lực chip trong nước để phát triển mô hình.
Tại sao Hoàng Nhân Tốn nói vậy? Bước tiếp theo của DeepSeek và Kimi, chính là câu trả lời tiêu chuẩn.
Bài viết này đến từ tài khoản công chúng WeChat “Tencent Technology”, tác giả: Tô Dương (Su Yang), biên tập: Từ Thanh Dương (Xu Qingyang)





