Vừa qua, DeepSeek V4 đã thực hiện một bản cập nhật.
Họ đã ra mắt framework giải mã dự đoán (Speculative Decoding) mới tên là DSpark, đồng thời open-source toàn bộ framework giải mã dự đoán toàn diện hỗ trợ phiên bản này có tên DeepSpec.
DeepSeek-V4-Pro-DSpark không phải là một kiến trúc model hoàn toàn mới, mà là phiên bản DeepSeek-V4-Pro được tích hợp thêm module giải mã dự đoán. Trọng tâm của bản cập nhật này nằm ở việc triển khai kỹ thuật, hơn là sự lặp lại về khả năng của chính model.
DSpark đã được triển khai trong luồng traffic trực tuyến thực tế của DeepSeek-V4 (Flash và Pro), tăng tốc đáng kể tốc độ suy luận của các mô hình ngôn ngữ lớn (LLM).

Báo cáo kỹ thuật: 《DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation》
Link báo cáo kỹ thuật: https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
Mục đích cốt lõi của DSpark là giải quyết các điểm nghẽn về độ trễ và thông lượng mà quá trình suy luận LLM phải đối mặt trong môi trường sản xuất (đặc biệt là trong các tình huống có mức độ đồng thời cao). Nói một cách đơn giản, DSpark đã kết hợp thành công "tạo sinh song song" với thông lượng cao và "xác thực nhận biết tải" thích ứng.
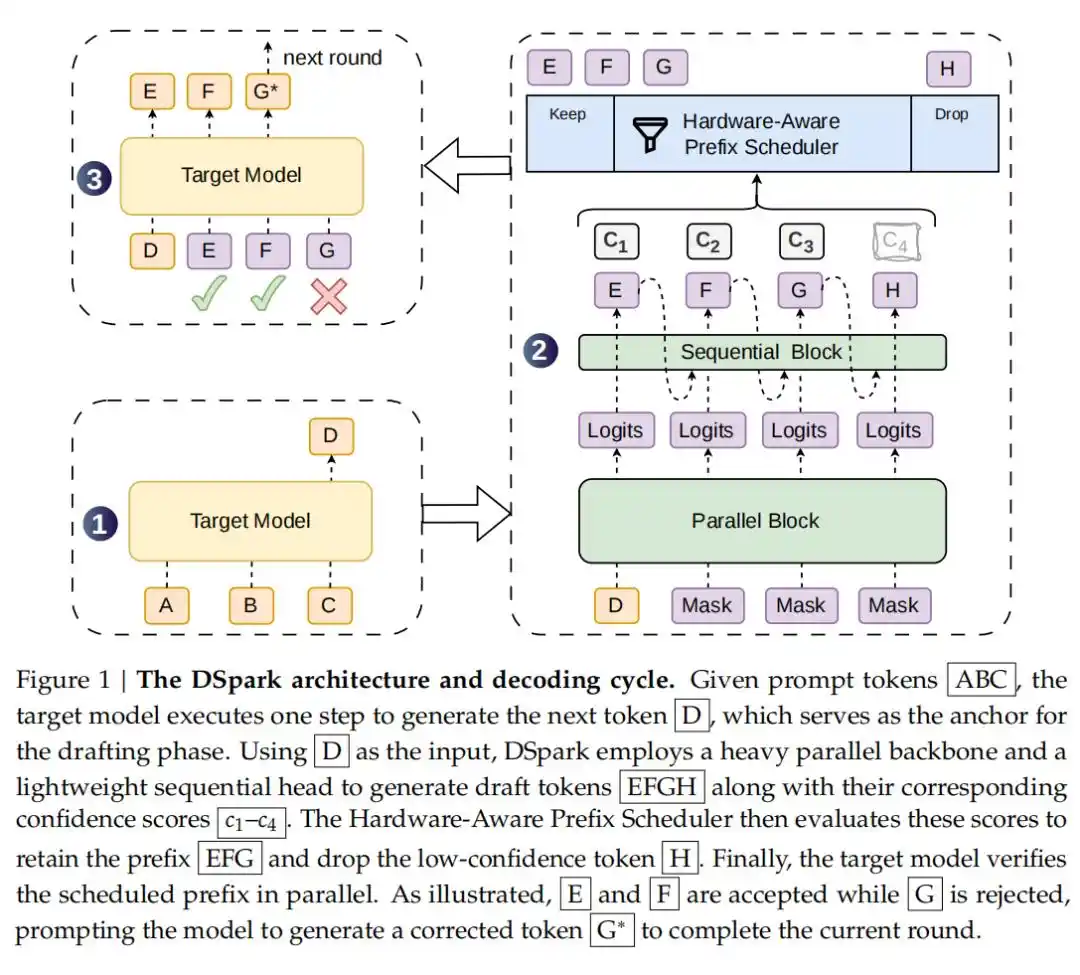
Giải mã dự đoán là một kỹ thuật tăng tốc suy luận cho các mô hình ngôn ngữ lớn mà không làm thay đổi phân bố đầu ra của mô hình. Ý tưởng cốt lõi là giới thiệu một "mô hình phác thảo" (draft model) nhẹ để tạo sẵn một số lượng ứng cử viên token nhất định, sau đó mô hình mục tiêu (target model) sẽ tiến hành xác thực hàng loạt và chấp nhận những ứng cử viên này, từ đó biến việc tạo sinh token tuần tự từng cái thành kiểm tra hàng loạt song song, giảm đáng kể độ trễ từ đầu đến cuối.
Trên cơ sở này, sự đổi mới của DSpark nằm ở việc giới thiệu kiến trúc tạo sinh bán tự hồi quy (Semi-Autoregressive Generation): nó giữ lại lợi thế về thông lượng cao của mô hình phác thảo song song, đồng thời bổ sung thêm một module tuần tự nhẹ để mô hình hóa mối quan hệ phụ thuộc giữa các token trong một khối, nhằm giảm thiểu vấn đề suy giảm tỷ lệ chấp nhận thường gặp ở các vị trí tiếp theo của mô hình phác thảo song song.
Ngoài ra còn có Xác thực theo lịch trình tin cậy nhận biết phần cứng (Confidence-Scheduled Verification): Giải mã dự đoán trước đây thường đưa tất cả các Token phác thảo được tạo ra đi xác thực một cách mù quáng. Khi hệ thống ở trạng thái tải cao, các Token ở phần đuôi có xác suất bị từ chối rất cao này sẽ lãng phí nghiêm trọng năng lực tính toán xử lý hàng loạt quý giá. DSpark giới thiệu một đầu tin cậy (Confidence Head) để đánh giá khả năng tồn tại của từng Token. Kết hợp với bộ lập lịch tiền tố nhận biết phần cứng, hệ thống có thể dựa trên đặc điểm thông lượng của engine theo thời gian thực để lập lịch động chiều dài xác thực tối ưu cho từng yêu cầu, chỉ phân bổ năng lực tính toán cho những Token có kỳ vọng lợi ích cao nhất.
Để triển khai trong cơ sở hạ tầng trực tuyến thực tế, bộ lập lịch của DSpark sử dụng cơ chế bất đồng bộ để tương thích với lập lịch không chi phí (ZOS) và phát lại đồ thị CUDA liên tục. Nó sử dụng dự đoán lịch sử từ hai bước trước đó để quyết định độ dài cắt ngắn động hiện tại, từ đó ẩn đi độ trễ lập lịch, tránh được sự tạm dừng của pipeline GPU, đồng thời đảm bảo khôi phục hoàn toàn không mất mát phân bố đầu ra của mô hình mục tiêu.
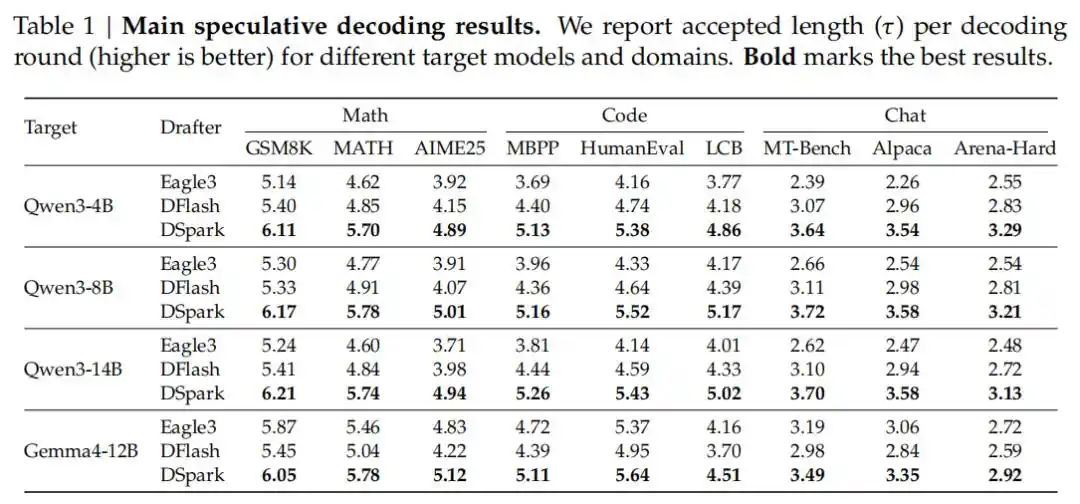
Trong các bài kiểm tra bao gồm nhiều lĩnh vực như suy luận toán học, tạo mã và hội thoại hàng ngày, DSpark đã vượt trội hơn đáng kể so với các mô hình tự hồi quy tiên tiến nhất hiện nay (Eagle3) và mô hình phác thảo song song (DFlash). Ví dụ, trên các mô hình mục tiêu thuộc dòng Qwen3 (4B, 8B, 14B), độ dài chấp nhận trung bình của nó cao hơn từ 26.7% đến 30.9% so với Eagle3, và từ 16.3% đến 18.4% so với DFlash.
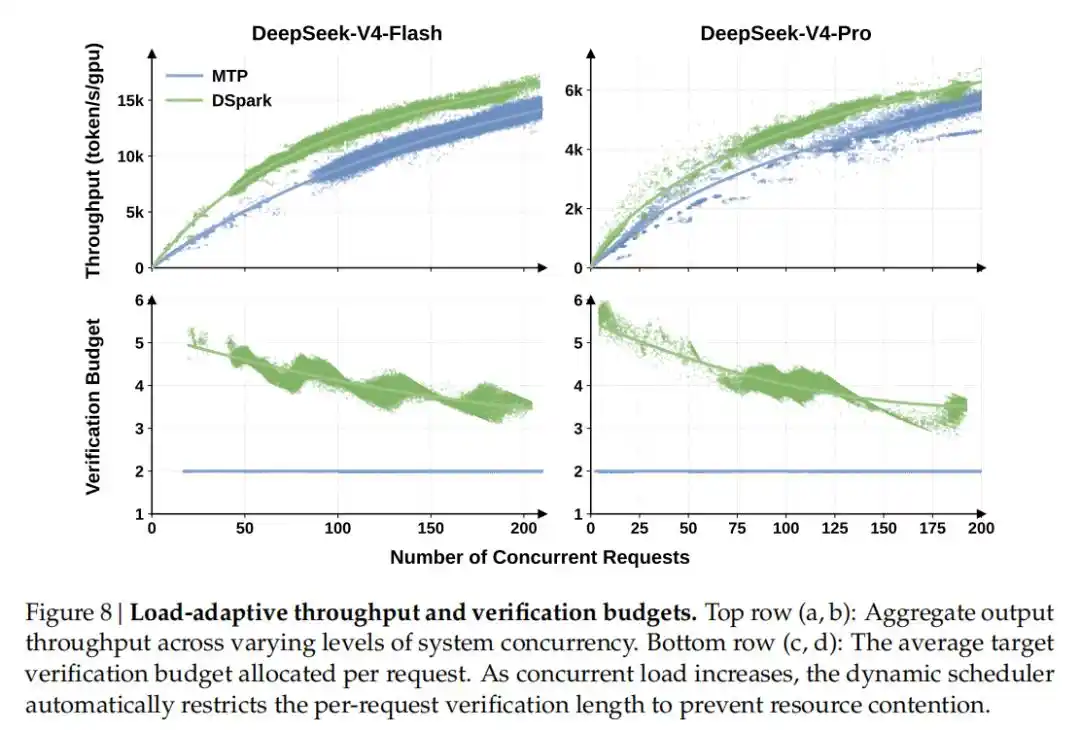
So với điểm chuẩn sản xuất đơn token thế hệ trước (MTP-1) đã được triển khai, trong khi duy trì cùng tổng thông lượng, DSpark đã tăng tốc độ tạo sinh của người dùng lần lượt 60%-85% (mô hình Flash) và 57%-78% (mô hình Pro).
Cùng với DSpark được open-source, DeepSpec cũng được công bố. Đây là một codebase toàn diện dùng để đào tạo và đánh giá các mô hình phác thảo giải mã dự đoán. Đó là "cơ sở hạ tầng nguồn mở" chứa đựng giải pháp này cũng như các triển khai thuật toán tiên tiến khác, bao gồm các công cụ chuẩn bị dữ liệu, triển khai mô hình phác thảo, mã đào tạo và script đánh giá.
DeepSpec chia toàn bộ quy trình thành ba giai đoạn: chuẩn bị dữ liệu, đào tạo và đánh giá. Ba giai đoạn này cần được chạy tuần tự, đầu ra của giai đoạn trước sẽ là đầu vào của giai đoạn sau.
Ở giai đoạn chuẩn bị dữ liệu, cần tải xuống dữ liệu lời nhắc, sử dụng engine suy luận để tạo lại câu trả lời cho mô hình mục tiêu và xây dựng bộ nhớ đệm mục tiêu (target cache). Đáng chú ý là, với cấu hình mặc định Qwen/Qwen3-4B làm ví dụ, dung lượng bộ nhớ đệm mục tiêu có thể lên tới khoảng 38 TB, cần đánh giá đầy đủ tài nguyên lưu trữ trước khi sử dụng.
Giai đoạn đào tạo có thể được khởi động thông qua bash scripts/train/train.sh. Script này sẽ gọi train.py và khởi động một worker cho mỗi GPU hiện hữu. Người dùng có thể chọn cấu hình mô hình mục tiêu và thuật toán khác nhau trong thư mục config/ bằng cách chỉ định config_path. Dự án cũng hỗ trợ điều chỉnh cài đặt đào tạo bằng cách ghi đè config_path, target_cache_dir và sử dụng --opts để sửa đổi các trường cấu hình đơn lẻ.
Về phần cứng, cấu hình mặc định và script của DeepSpec hướng đến môi trường một node 8 GPU. Nếu số lượng GPU ít hơn, người dùng cần giảm số lượng GPU hiện hữu trong CUDA_VISIBLE_DEVICES tương ứng.
Giai đoạn đánh giá được khởi động thông qua bash scripts/eval/eval.sh. Script đánh giá sẽ sử dụng checkpoint của mô hình phác thảo đã được đào tạo để đo lường tình trạng chấp nhận trên nhiều tác vụ chuẩn của giải mã dự đoán. Các tập dữ liệu đánh giá hiện được liệt kê trong dự án bao gồm GSM8K, MATH500, AIME25, HumanEval, MBPP, LiveCodeBench, MT-Bench, Alpaca và Arena-Hard-v2, bao phủ các loại tác vụ khác nhau như suy luận toán học, tạo mã, khả năng hội thoại và hỏi đáp tổng hợp.
Về mặt thuật toán, DeepSpec hiện có sẵn ba loại mô hình phác thảo: DSpark, DFlash và Eagle3. Về dòng mô hình mục tiêu, dự án hiện hỗ trợ Qwen3 và Gemma.
Việc open-source DeepSpec đã hợp nhất thực hành kỹ thuật giải mã dự đoán - vốn trước đây thường phân tán trong nội bộ các nhóm nghiên cứu - thành một bộ công cụ tiêu chuẩn hóa có thể tái tạo và mở rộng. Đối với các nhà nghiên cứu và kỹ sư muốn tăng tốc suy luận cho mô hình lớn của riêng họ, điều này có nghĩa là có thể đào tạo mô hình phác thảo tùy chỉnh trực tiếp trên một framework trưởng thành, bỏ qua rất nhiều công việc xây dựng cơ sở hạ tầng cơ bản lặp đi lặp lại.
Liên kết tham khảo:
https://github.com/deepseek-ai/DeepSpec/blob/main/DSpark_paper.pdf
https://github.com/deepseek-ai/DeepSpec
Bài viết này đến từ tài khoản WeChat công cộng "机器之心" (ID: almosthuman2014), tác giả: Zenan, Yang Wen





