Vừa rồi, Anthropic chính thức ra mắt mô hình mới Claude Sonnet 5, mô tả đây là "mô hình Sonnet mang tính Agent mạnh mẽ nhất từ trước đến nay", có thể lập kế hoạch, sử dụng các công cụ như trình duyệt, terminal và hoạt động tự chủ ở mức mà vài tháng trước còn cần đến các mô hình lớn hơn, đắt tiền hơn mới đạt được.
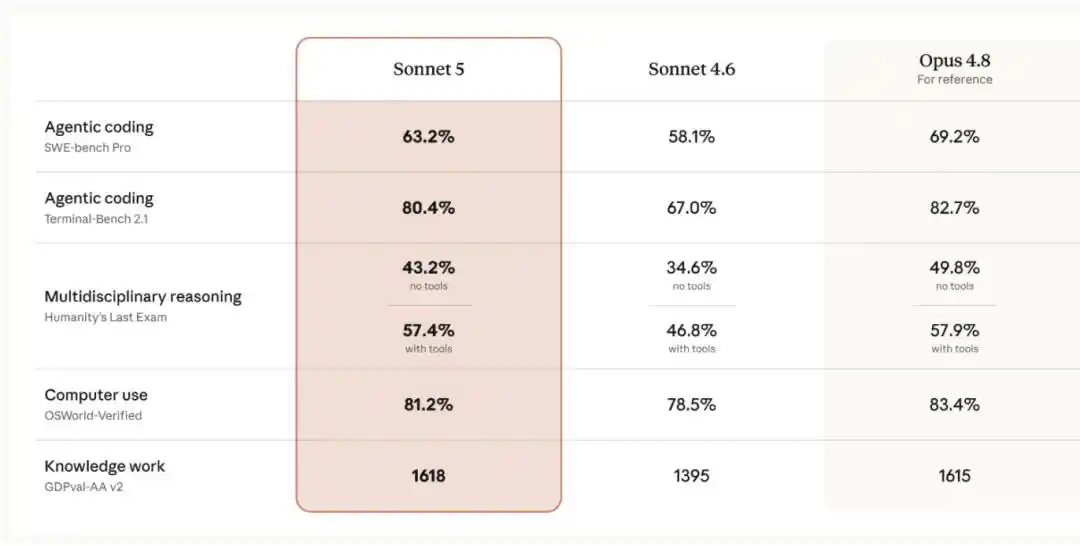
So với Sonnet 4.6, Sonnet 5 có sự cải thiện đáng kể về hiệu năng trong lĩnh vực suy luận, sử dụng công cụ, lập trình và công việc tri thức, tiệm cận hơn với Opus 4.8, nhưng giá thấp hơn.
Phía chính thức cho biết, đối với các nhà phát triển, kỷ nguyên AI Agent thực sự bắt đầu từ các mô hình cấp Sonnet: Claude Sonnet 3.5, 3.6 và 3.7 là một trong những mô hình đầu tiên thể hiện khả năng ấn tượng trong lập trình và sử dụng công cụ. Tuy nhiên, gần đây, sự cải thiện rõ rệt nhất về khả năng Agent chủ yếu xuất hiện trên các mô hình cấp Opus.
Còn Claude Sonnet 5 đã thu hẹp đáng kể khoảng cách này: hiệu năng của nó đã gần với Opus 4.8, nhưng giá lại thấp hơn. So với thế hệ trước Sonnet 4.6, nó có sự cải thiện đáng kể trên các khía cạnh then chốt về hiệu năng agent như suy luận, sử dụng công cụ, lập trình và công việc tri thức. Cụ thể so sánh như hình dưới đây:
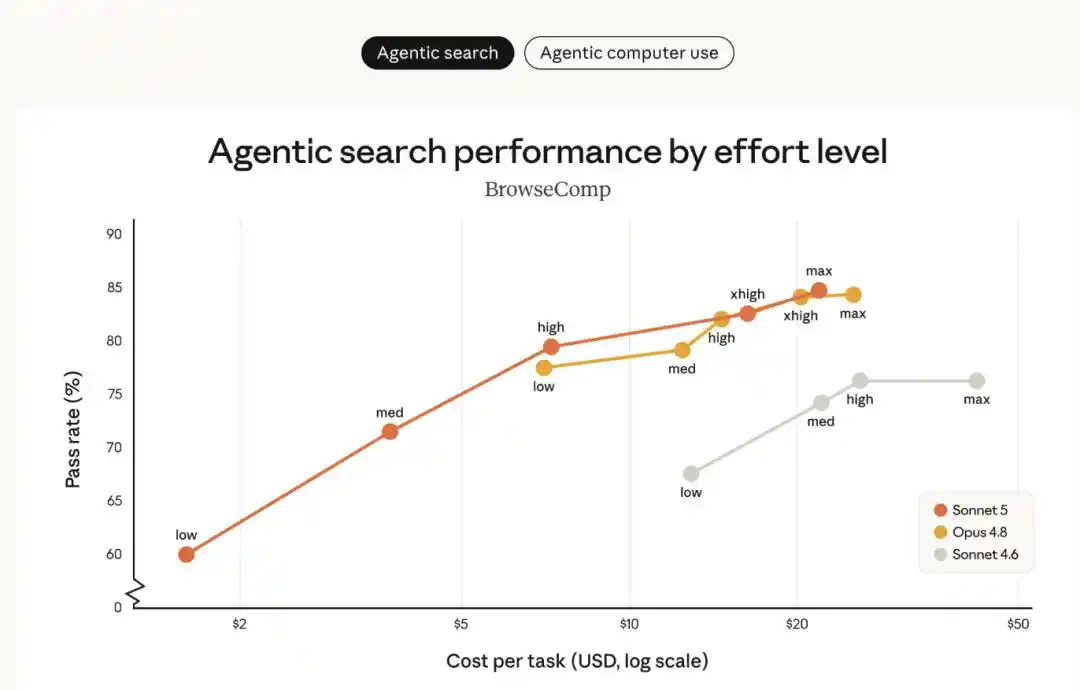
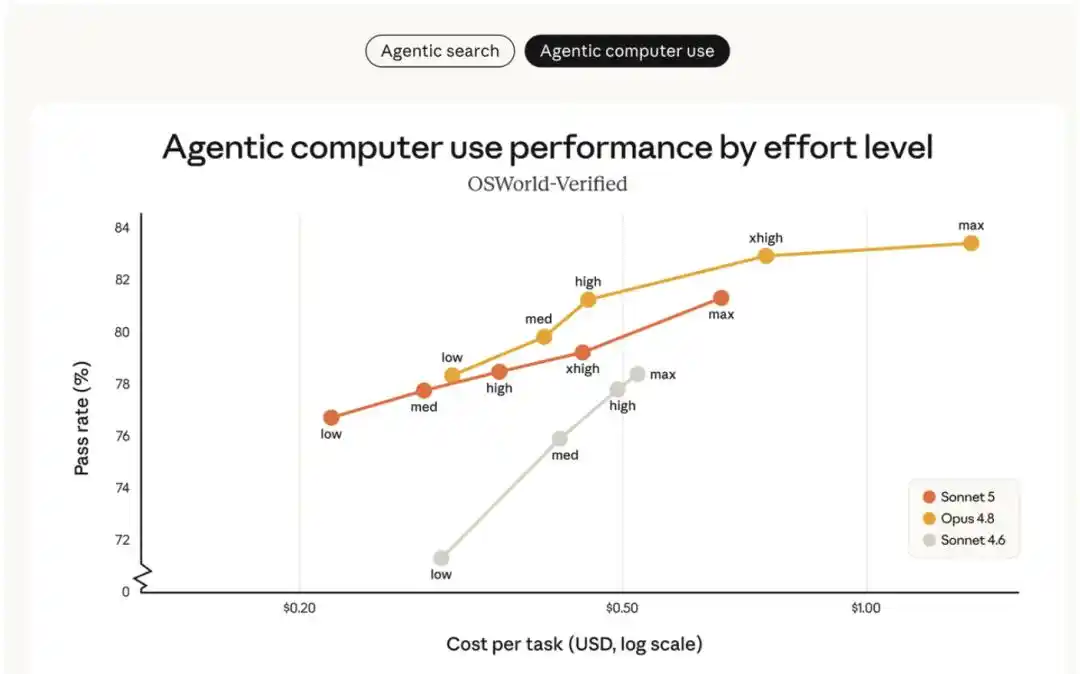
Hình dưới đây so sánh Sonnet 5 với Sonnet 4.6 và Opus 4.8 trong đánh giá tìm kiếm thông minh BrowseComp và đánh giá sử dụng máy tính OSWorld‐Verified, ở các mức "nỗ lực" khác nhau:
- Sonnet 5 (đường màu cam) có hiệu năng được cải thiện rõ rệt so với Sonnet 4.6 (đường màu xám), và phạm vi lựa chọn về chi phí-hiệu suất cũng rộng hơn so với Opus 4.8 (đường màu vàng).
- Ở mức nỗ lực trung bình, Sonnet 5 cải thiện đáng kể hiệu quả chi phí; ở mức nỗ lực cao hơn, hiệu năng của nó trong một số nhiệm vụ có thể sánh ngang với Opus 4.8.
- Giữa Sonnet 5 và Opus 4.8, người dùng có thể linh hoạt điều chỉnh mức độ nỗ lực dựa trên nhiệm vụ cụ thể để tìm điểm cân bằng chi phí và hiệu suất phù hợp nhất với nhu cầu của mình.
Đường cong chi phí - hiệu suất ở các mức độ nỗ lực khác nhau được thể hiện như hình trên. Mô hình Sonnet tốt nhất trước đây (Sonnet 4.6) không thể nào so được với Opus 4.8. Sonnet 5 cung cấp nhiều lựa chọn về chi phí - hiệu suất hơn so với Sonnet 4.6, trong một số trường hợp có thể đạt đến trình độ của Opus 4.8. Biểu đồ này hiển thị mức giá Sonnet 5 là $3 / triệu token đầu vào, $15 / triệu token đầu ra. Với giá dùng thử trước ngày 31 tháng 8 ($2 / triệu token đầu vào, $10 / triệu token đầu ra), chi phí thực tế của Sonnet 5 thậm chí còn thấp hơn so với biểu đồ. Mức giá của Opus 4.8 là $5 / triệu token đầu vào, $25 / triệu token đầu ra.
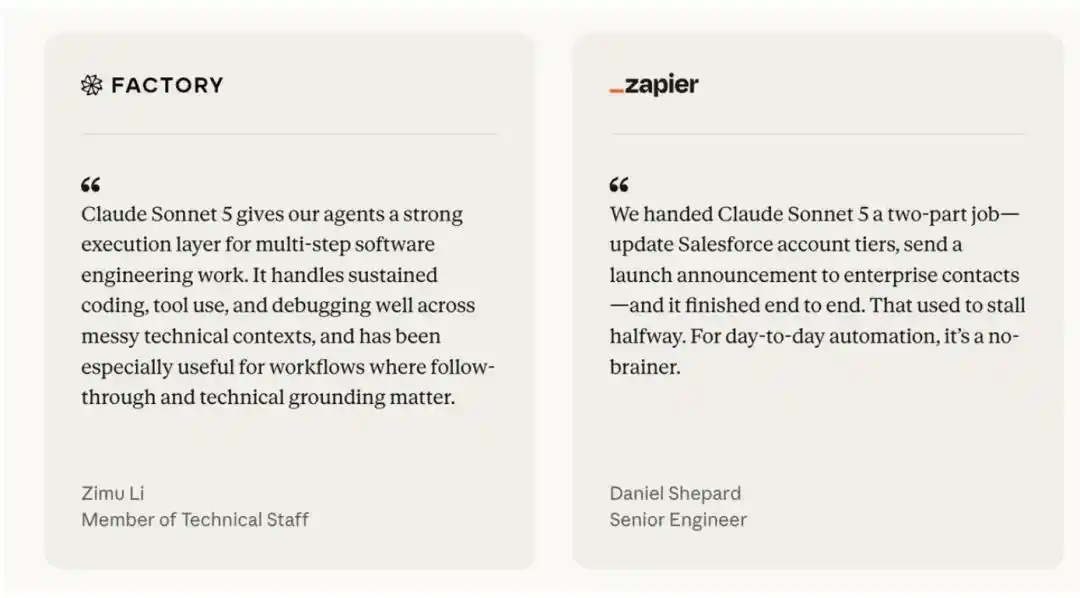
Phản hồi từ các đối tác truy cập sớm của Anthropic luôn nhất quán: Sonnet 5 có khả năng agent tự chủ (agentic) hơn so với các mô hình tiền nhiệm. Người thử nghiệm mô tả rằng, nó có thể hoàn thành các nhiệm vụ phức tạp - mà các mô hình Sonnet trước đây sẽ dừng lại giữa chừng; nó chủ động kiểm tra đầu ra của mình mà không cần được nhắc rõ ràng; và nó thực hiện tất cả công việc agent này với mức giá cực kỳ hấp dẫn:
Đánh giá An ninh
Đánh giá an ninh trước khi triển khai của Anthropic phát hiện, Sonnet 5 nhìn chung được cải thiện so với Sonnet 4.6. Về mặt an ninh của agent tự chủ, mô hình này hoạt động tốt hơn trong việc từ chối các yêu cầu độc hại và chống lại các nỗ lực chiếm quyền trong các cuộc tấn công tiêm prompt. Tỷ lệ ảo giác và hành vi xu nịnh của mô hình đều thấp hơn Sonnet 4.6. Trong kiểm toán hành vi tự động (thử nghiệm hành vi sai trái trên diện rộng, như hỗ trợ lạm dụng và lừa đảo), Sonnet 5 đạt điểm thấp hơn (tức an toàn hơn).
Tuy nhiên, so với Opus 4.8 và Claude Mythos Preview mạnh hơn, nó thực sự thể hiện tỷ lệ hành vi sai trái cao hơn một chút trong đánh giá này.
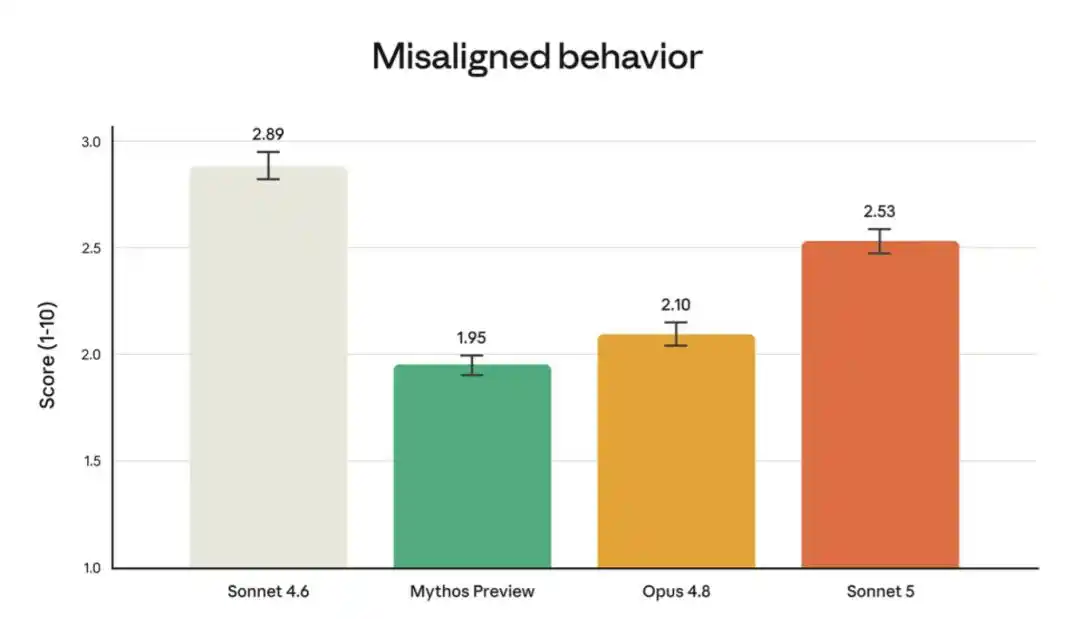
Hình trên cho thấy tỷ lệ hành vi sai trái trong kiểm toán hành vi tự động, kiểm tra này thử nghiệm một lượng lớn hành vi xấu trong nhiều ngữ cảnh và bối cảnh khác nhau (xem danh sách đầy đủ và kết quả từng hành vi trong Mục 6.4 của Thẻ hệ thống Sonnet 5). Tỷ lệ hành vi sai trái của Sonnet 5 nhìn chung thấp hơn Sonnet 4.6, nhưng cao hơn Mythos Preview và Opus 4.8.
Anthropic cho biết, họ không cố ý huấn luyện Sonnet 5 cho các nhiệm vụ an ninh mạng. Nó có thể thực hiện một số nhiệm vụ mạng thông thường, vô hại, nhưng khi đánh giá các kỹ năng mạng tiềm ẩn nguy hiểm (như phát triển các chương trình khai thác lỗ hổng phần mềm), hiệu suất của nó kém hơn đáng kể so với các mô hình như Opus 4.8 và Mythos 5.
Hình dưới đây thể hiện điểm số từ một trong các đánh giá, thử nghiệm khả năng của mô hình trong việc phát triển chương trình khai thác lỗ hổng cho trình duyệt Firefox. Sonnet 5 liên tục không thể phát triển được chương trình khai thác hoàn chỉnh, có thể sử dụng, nhưng tỷ lệ thành công một phần của nó cao hơn một chút so với Sonnet 4.6. Sự cải thiện sau này có thể bắt nguồn từ sự cải thiện về trí thông minh tổng quát, chứ không phải từ đào tạo cụ thể.
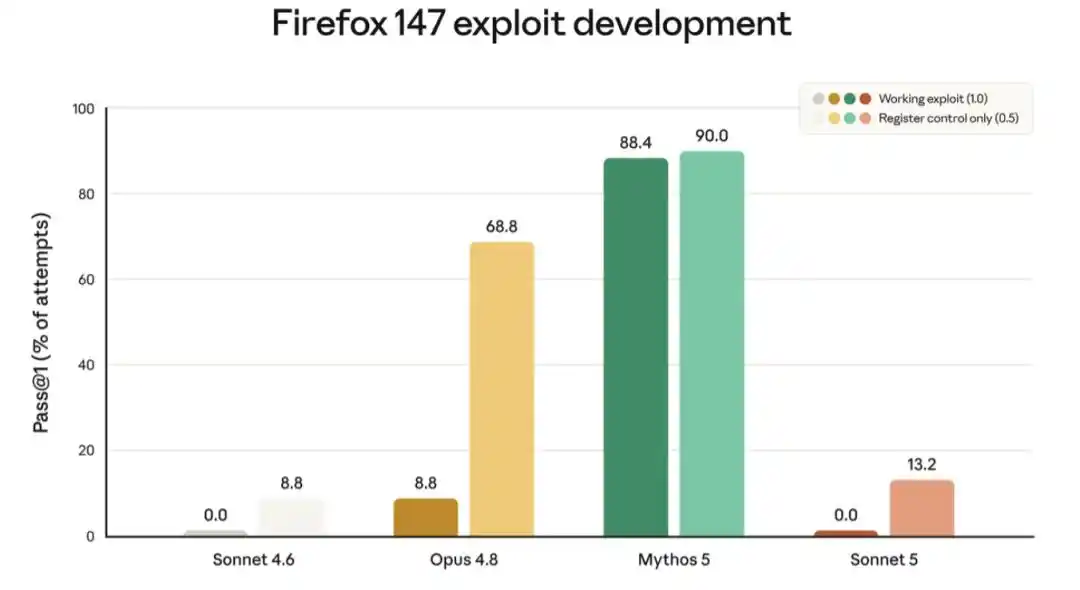
Hình trên thể hiện điểm số của các mô hình trong việc phát triển thành công chương trình khai thác cho lỗ hổng phần mềm trong Firefox 147 (đánh giá này được phát triển hợp tác với Mozilla; tất cả lỗ hổng đã được vá trong Firefox 148). Đối với mỗi mô hình, biểu đồ cột bên trái thể hiện tần suất mô hình (trong điều kiện không có rào chắn an ninh) phát triển được chương trình có thể khai thác, biểu đồ cột bên phải thể hiện tần suất thành công một phần. Cả hai mô hình Sonnet đều không thể phát triển thành công chương trình có thể khai thác (điểm đều là 0.0%); tỷ lệ thành công một phần của Sonnet 5 cao hơn một chút so với Sonnet 4.6. Khả năng mạng của cả hai mô hình Sonnet đều yếu hơn đáng kể so với Opus 4.8 và Mythos 5.
Vì Sonnet 5 trong các nhiệm vụ này mạnh hơn một chút so với thế hệ trước, Anthropic đã mặc định kích hoạt các rào chắn an ninh mạng. Các rào chắn này - có khả năng phát hiện và ngăn chặn việc sử dụng mạng nguy hiểm trong thời gian thực - giống với các rào chắn trong Claude Opus 4.7 và 4.8 (vì Anthropic đánh giá rủi ro an ninh mạng tổng thể của Sonnet 5 thấp hơn, mức độ nghiêm ngặt của các rào chắn thấp hơn so với những rào chắn được kích hoạt trong Fable 5 - cái sẽ ngăn chặn nhiều nhiệm vụ an ninh mạng rộng hơn).
Báo cáo đánh giá đầy đủ của Anthropic về Sonnet 5 trên nhiều bài đánh giá an ninh và khả năng, xem chi tiết tại Thẻ Hệ thống Claude Sonnet 5.
Định giá
Từ hôm nay, Claude Sonnet 5 đã chính thức có mặt trên tất cả các kênh. Để chào mừng ra mắt, Anthropic đưa ra mức giá ra mắt ưu đãi có thời hạn:
- Từ nay đến ngày 31 tháng 8 năm 2026: Đầu vào là $2 / triệu token, đầu ra là $10 / triệu token
- Sau đó trở về mức giá tiêu chuẩn: Đầu vào $3 / triệu token, đầu ra $15 / triệu token
Đồng thời, họ thông báo tăng toàn diện giới hạn tốc độ (rate limits) cho Chat, Cowork, Claude Code và nền tảng Claude, để phù hợp với mức tiêu thụ token lớn hơn do chế độ "nỗ lực" cao hơn mang lại.
Lưu ý
Xác minh An ninh Mạng
Sonnet 5 đã được đưa vào "Chương trình Xác minh An ninh Mạng" của Anthropic. Chương trình này hiện đã mở để sử dụng trên các nền tảng sau:
- Nền tảng Claude gốc
- Nền tảng Claude trên AWS
- Claude trong Microsoft Foundry (được lưu trữ trên Azure và Anthropic)
Claude trên Google Vertex cũng sẽ sớm được hỗ trợ.
Các tổ chức đã tham gia chương trình này sẽ tự động được cấp quyền truy cập tương tự trên Sonnet 5, không cần đăng ký lại. Nếu công việc an ninh mạng của bạn cần ít hạn chế về rào chắn an ninh, Anthropic khuyến nghị sử dụng Claude Opus 4.8.
Giải thích về Cập nhật Tokenizer và Định giá
Sonnet 5 là bản nâng cấp của Sonnet 4.6, nhưng sử dụng tokenizer hoàn toàn mới, để tối ưu hóa hiệu suất xử lý văn bản (tương tự như thay đổi tokenizer được giới thiệu trong Claude Opus 4.7).
Thay đổi mang lại là: cùng một nội dung đầu vào, bây giờ sẽ được ánh xạ thành nhiều token hơn, mức tăng cụ thể khoảng 1.0~1.35 lần, tùy thuộc vào loại nội dung.
Vì lý do này, mức giá dùng thử mà Anthropic đặt ra, chính là để giúp người dùng chuyển sang Sonnet 5 mà tổng chi phí sử dụng về cơ bản không đổi.
Giải thích về Điều chỉnh Giới hạn Tốc độ
Vào ngày 26 tháng 4 năm 2026, Anthropic đã tăng giới hạn tốc độ cho tất cả các mức sử dụng đối với các mô hình Sonnet và Haiku, và đơn giản hóa các gói của nền tảng Claude gốc thành ba cấp độ: Start, Build, Scale.
Trong bản cập nhật này, Anthropic tiếp tục tăng giới hạn tốc độ cho Chat, Cowork, Claude Code và nền tảng Claude, để phù hợp với mức tiêu thụ token lớn hơn do chế độ "nỗ lực" cao hơn mang lại.
Bạn có thể xem cấp độ hiện tại và các giới hạn cụ thể trong Claude Console, hoặc tham khảo tài liệu để biết thêm chi tiết.
Giải thích về Chỉnh sửa Điểm Đánh giá (Bổ sung)
- Humanity’s Last Exam: Anthropic đã cập nhật mô hình chấm điểm cho bài đánh giá này, và dựa trên đó đã sửa điểm của Sonnet 4.6 thành 34.6% (không công cụ) và 46.8% (có công cụ). Do đó, điểm số này khác với dữ liệu được báo cáo trong blog ra mắt Sonnet 4.6, đặc biệt lưu ý ở đây.
- OSWorld‐Verified: Anthropic đã tối ưu hóa cách thức chạy bài đánh giá này, để phản ánh chân thực hơn hiệu suất của mô hình trong các tình huống thực tế, và đã sửa điểm của Sonnet 4.6 thành 78.5%. Đây cũng là lý do khiến điểm số này không nhất quán với dữ liệu trong blog ra mắt Sonnet 4.6.
Phản hồi Trải nghiệm của Nhà phát triển
Claude Sonnet 5 vừa ra mắt, mọi người cũng đã bắt đầu trải nghiệm và đánh giá.
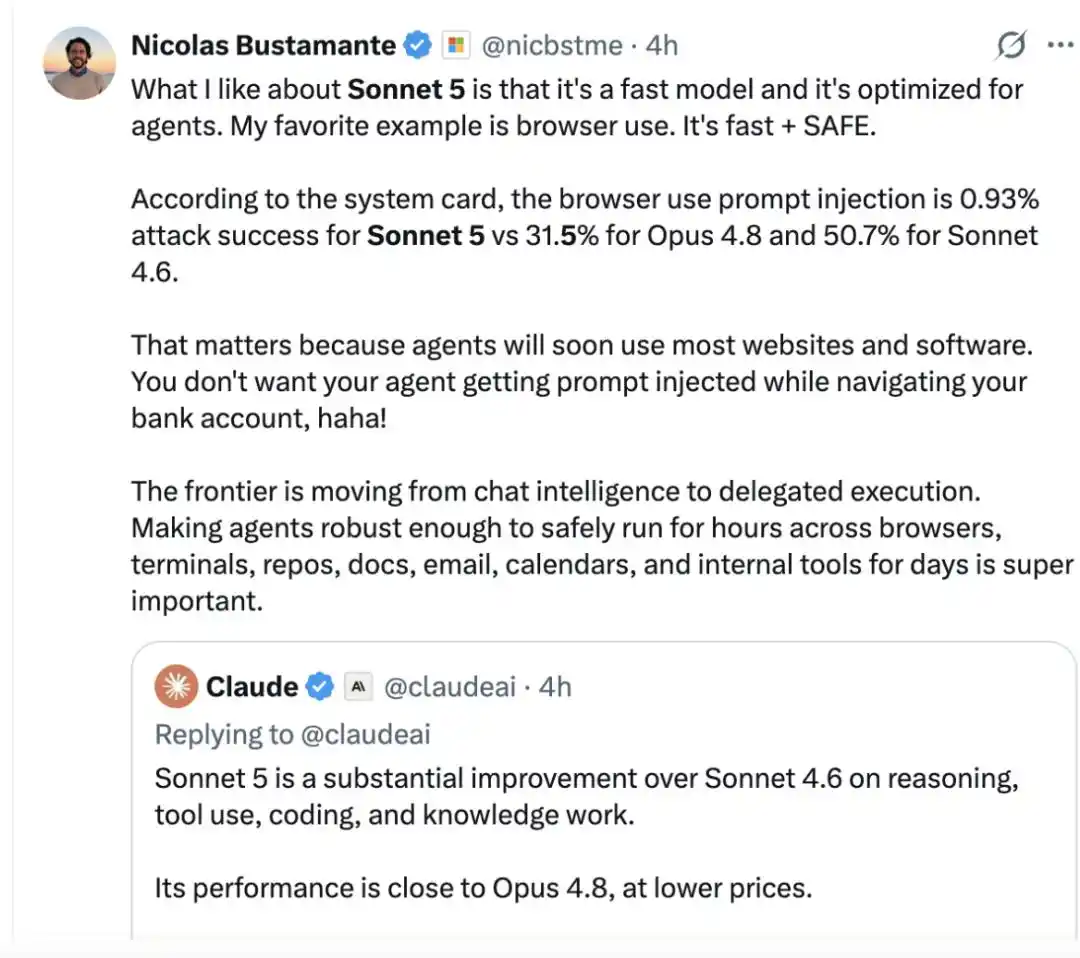
Người dùng Nicolas Bustamante cho biết, điều anh thích ở Sonnet 5 là nó rất nhanh và được tối ưu hóa cho Agent. "Ví dụ tôi thích nhất là sử dụng trình duyệt: vừa nhanh, vừa an toàn."
Theo kết quả trong thẻ hệ thống, tỷ lệ thành công của cuộc tấn công tiêm prompt trong trường hợp sử dụng trình duyệt, Sonnet 5 chỉ có 0.93%, trong khi Opus 4.8 là 31.5%, Sonnet 4.6 là 50.7%.
Tuy nhiên, cũng có người dùng cho rằng, "Quá đắt."
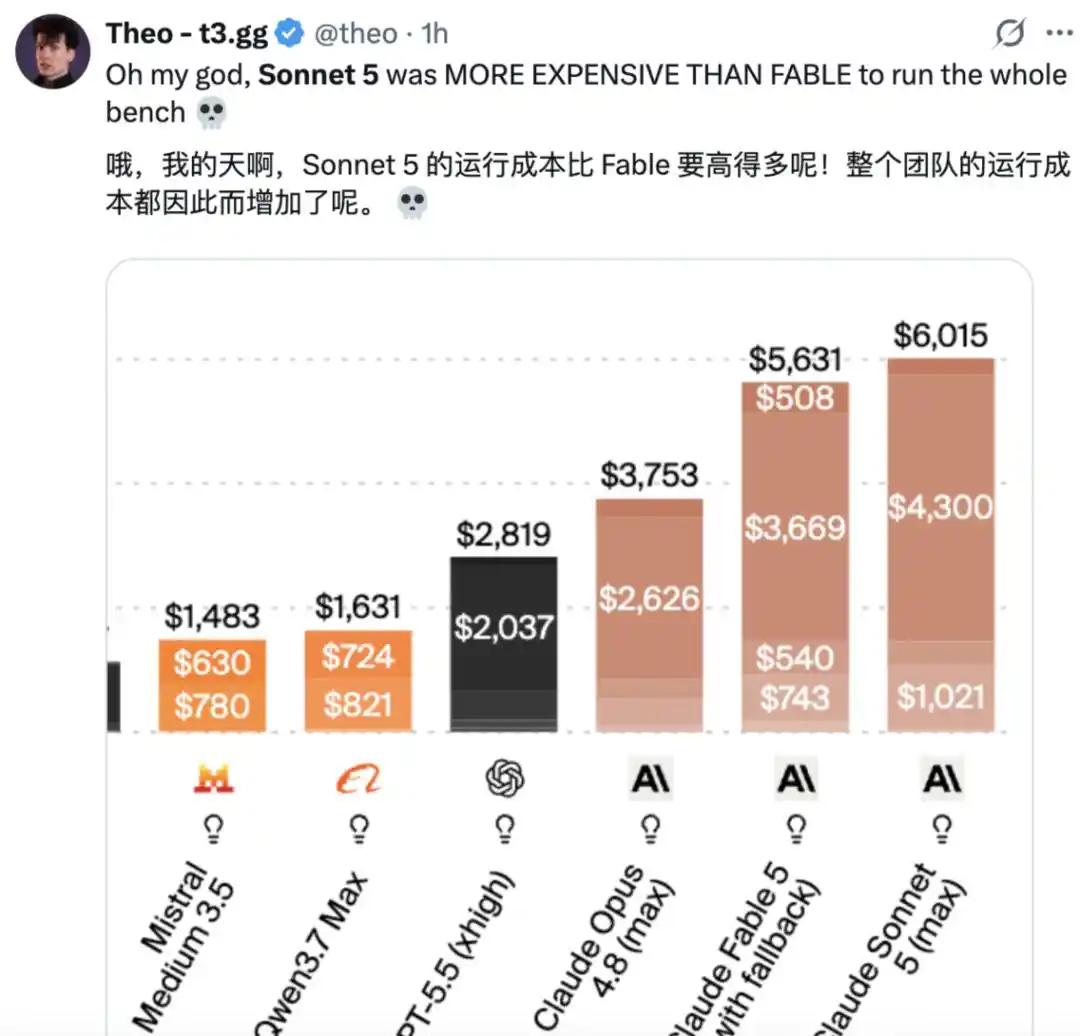
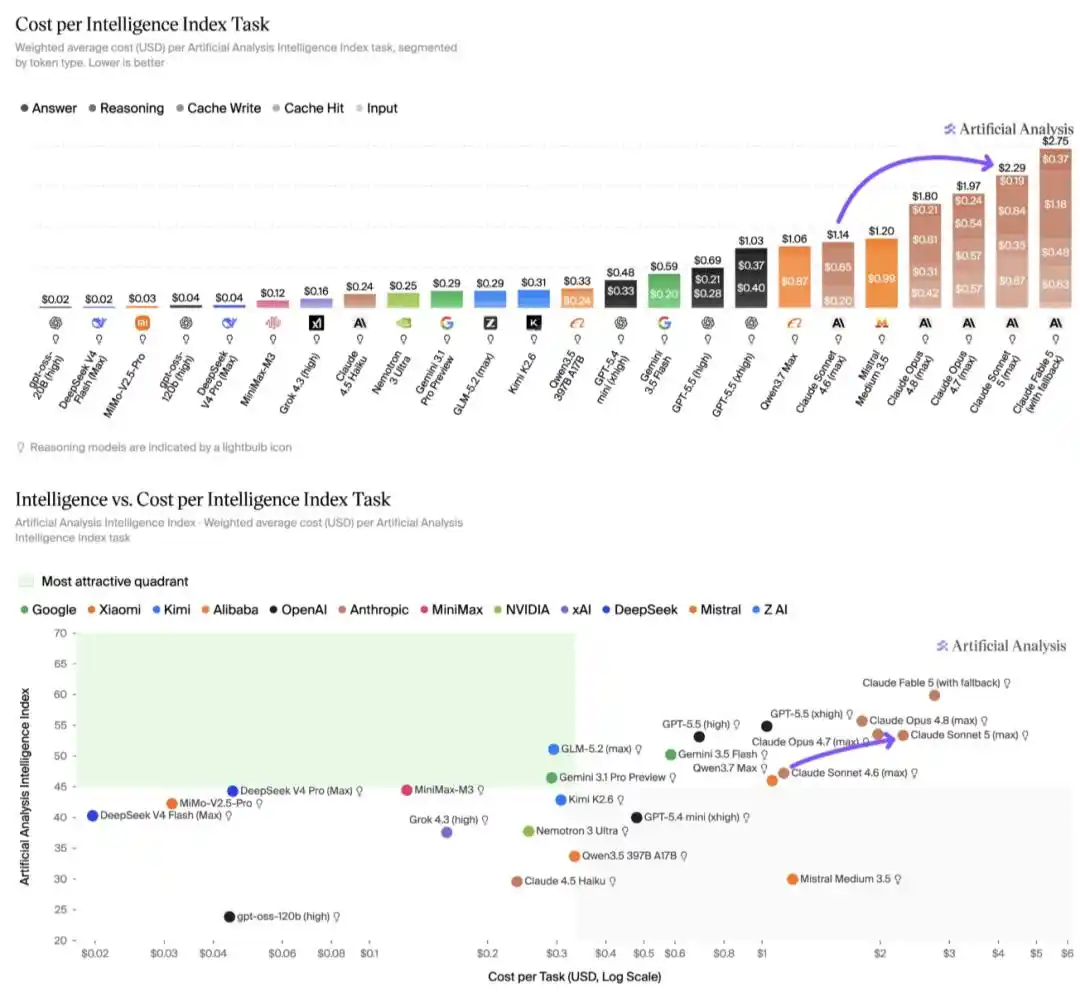
Theo phân tích của Artificial Analysis, trên Chỉ số Thông minh (Intelligence Index), chi phí vận hành của Claude Sonnet 5 là 2.29 đô la cho mỗi nhiệm vụ, tăng khoảng 2 lần so với Sonnet 4.6, và cũng cao hơn khoảng 15% so với Claude Opus 4.8. Sự gia tăng chi phí này hoàn toàn do lượng token sử dụng tăng lên, khiến Claude Sonnet 5 trở thành một trong những mô hình có chi phí vận hành cao nhất, chỉ sau Claude Fable 5.
Còn bạn thì sao, thấy mô hình mới thế nào, chào mừng để lại bình luận và trao đổi!
Liên kết tham khảo:
https://x.com/claudeai/status/2072017450611142835
https://www.anthropic.com/news/claude-sonnet-5
https://x.com/ArtificialAnlys/status/2072062595482456431
Bài viết này từ tài khoản công chúng WeChat "机器之心" (ID:almosthuman2014), tác giả: quan tâm AI





