Mấy ngày gần đây, một mô hình nhỏ 3B đã gây sốt trên X, vì trong một số nhiệm vụ suy luận có thể xác minh độ khó (ví dụ như lập trình), nó đã lọt vào phạm vi hiệu suất của các mô hình tiên phong như Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, Kimi K2.5, trong khi kích thước của nó nhỏ hơn rất nhiều so với các mô hình này.

Mô hình này có tên là VibeThinker-3B, là một mô hình suy luận đặc chắc với 3 tỷ tham số, nhằm mục đích khám phá xem, trong quy mô mô hình nhỏ nghiêm ngặt, khả năng suy luận có thể xác minh có thể được đẩy đến mức độ nào.
Sau khi mô hình được công bố, nhiều người đã kinh ngạc trước thành tích của nó, và nói rằng muốn tự mình trải nghiệm.


Đáng chú ý là, nó còn là một mô hình trong nước, đến từ đội ngũ Weibo Sina.
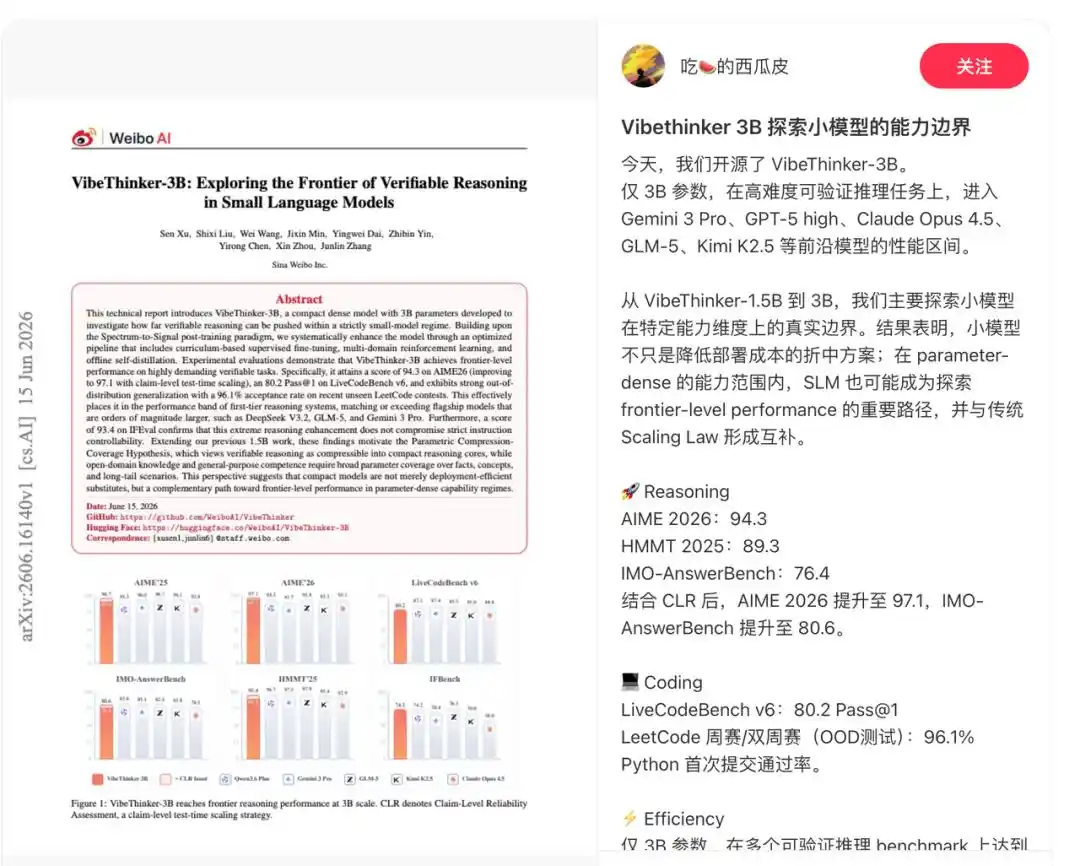
Báo cáo kỹ thuật cho thấy, mô hình này được thiết kế chuyên biệt cho các nhiệm vụ có tín hiệu xác minh đáng tin cậy, bao gồm suy luận toán học, lập trình thi đấu, suy luận STEM và thực thi lệnh với các ràng buộc rõ ràng.
Do đó, nó thể hiện xuất sắc trong các bài kiểm tra chuẩn. Nó đạt 94.3 điểm trong bài kiểm tra AIME26, 89.3 điểm trong bài kiểm tra HMMT25, 80.2 điểm (Pass@1) trong bài kiểm tra LiveCodeBench v6, và đạt tỷ lệ vượt qua 96.1% trong các cuộc thi tuần và thi đôi (biweekly contests) mới nhất không công khai trên LeetCode từ ngày 25/4/2026 đến 31/5/2026.

Mô hình này được huấn luyện như thế nào? Báo cáo kỹ thuật tiết lộ một số chi tiết.
Đầu tiên, nó được xây dựng dựa trên Qwen2.5-Coder-3B, và sử dụng quy trình Spectrum-to-Signal nâng cấp để huấn luyện hậu kỳ (post-training). Quy trình này tăng cường tổng hợp dữ liệu, lọc chất lượng và học theo lộ trình (curriculum learning) trong quá trình tinh chỉnh có giám sát (SFT), mở rộng việc học tăng cường theo phong cách MGPO sang nhiều lĩnh vực có thể xác minh, giữ lại toàn bộ đường đi suy luận ngữ cảnh dài, và củng cố các khả năng thông qua tự cô đặc ngoại tuyến (offline self-distillation) và học tăng cường chỉ dẫn (Instruct RL).
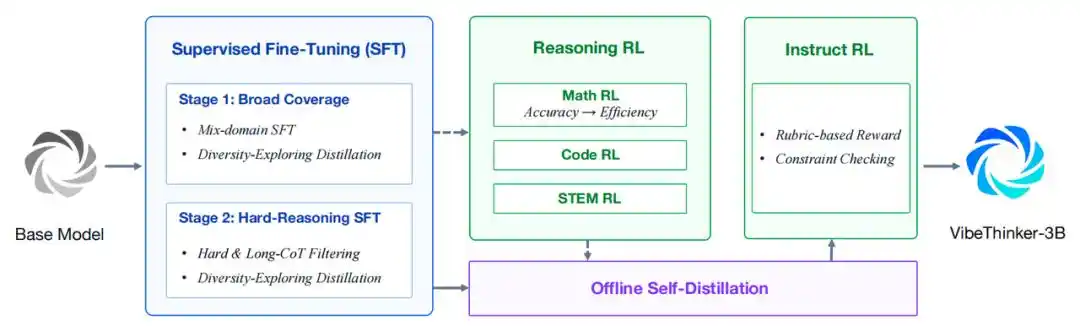
Quy trình huấn luyện tổng thể của VibeThinker-3B
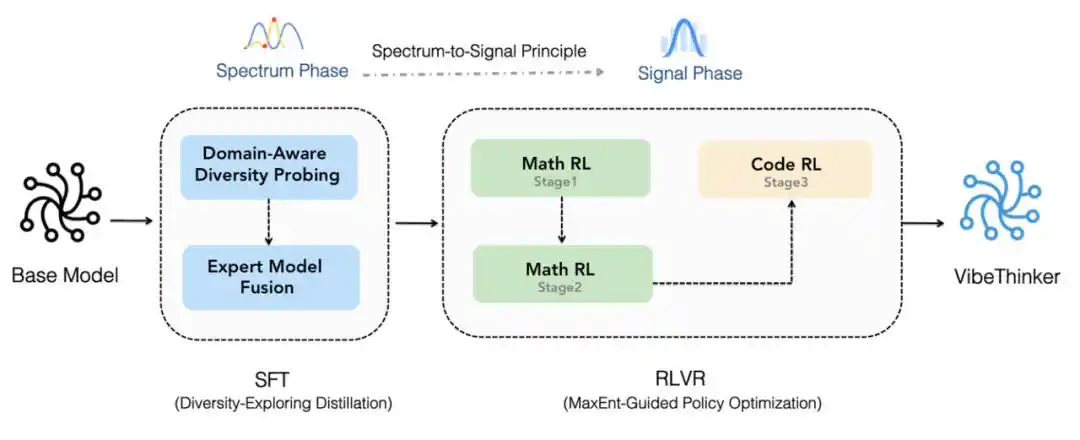
Quy trình Spectrum-to-Signal.
Ngoài ra, VibeThinker-3B còn giới thiệu Đánh giá Độ tin cậy Cấp độ Tuyên bố (Claim-Level Reliability - CLR), một chiến lược mở rộng quy mô lúc kiểm tra (test-time scaling) hướng tới suy luận có câu trả lời có thể xác minh. CLR tiếp tục nâng cao hiệu suất trong các bài kiểm tra chuẩn toán học, nâng AIME26 từ 94.3 lên 97.1, HMMT25 từ 89.3 lên 95.4, và nâng BruMO25 lên 99.2.
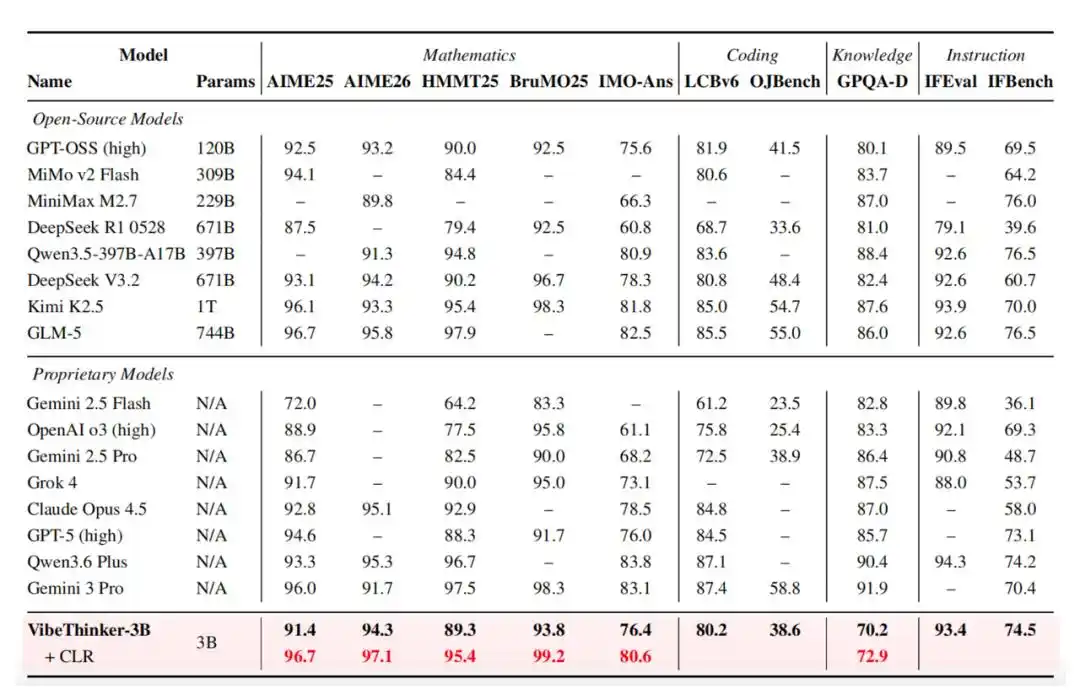
Quy trình huấn luyện cụ thể của nó như sau:
- SFT hai giai đoạn dựa trên lộ trình. Giai đoạn đầu tập trung vào phạm vi khả năng rộng rãi như toán học, lập trình, suy luận STEM, hội thoại chung và tuân thủ chỉ dẫn. Giai đoạn hai chuyển sang các mẫu suy luận khó hơn và tầm nhìn rộng hơn. Sự cô đặc khám phá đa dạng (Diversity exploration distillation) được sử dụng để giữ lại nhiều đường giải pháp hiệu quả.
- Học tăng cường suy luận đa lĩnh vực. VibeThinker-3B tái sử dụng MGPO. Học tăng cường được áp dụng lần lượt cho các nhiệm vụ toán học, lập trình và suy luận STEM. Quá trình huấn luyện sử dụng một cửa sổ ngữ cảnh dài 64K duy nhất để giữ lại toàn bộ đường đi suy luận miền thời gian dài.
- Tự cô đặc ngoại tuyến. Lọc và cô đặc các đường đi chất lượng cao từ các checkpoint RL toán học, lập trình và STEM, cuối cùng tạo thành một mô hình học sinh thống nhất. Điểm tiềm năng học tập được sử dụng để ưu tiên những đường đi đúng nhưng mô hình học sinh chưa bắt chước tốt.
- Instruct RL. Giai đoạn cuối cùng nâng cao khả năng kiểm soát đối với các hướng dẫn hướng tới người dùng. Đối với dữ liệu hướng dẫn nhạy cảm về định dạng và mở, bộ xác thực dựa trên quy tắc và mô hình phần thưởng dựa trên tiêu chí chấm điểm được sử dụng.
Trong một bài đăng gần đây, nhà nghiên cứu AI và blogger nổi tiếng Sebastian Raschka đã tổng kết có hệ thống các điểm chính được tiết lộ trong báo cáo kỹ thuật VibeThinker-3B, bao gồm những điểm sau:

Nếu bạn quan tâm đến những nội dung này, có thể đi xem chi tiết báo cáo kỹ thuật của họ. Hiện tại, mô hình cũng có thể tải xuống công khai.

Tiêu đề báo cáo: VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Liên kết báo cáo: https://arxiv.org/pdf/2606.16140
Liên kết HuggingFace: https://huggingface.co/WeiboAI/VibeThinker-3B
Tuy nhiên, phạm vi áp dụng của mô hình này có những hạn chế rõ ràng, vì nó không thể hiện xuất sắc trong các lĩnh vực cần kiến thức tổng quát.
Bên chính thức cũng chỉ rõ điểm này, và đưa ra "Giả thuyết Nén Tham số Bao phủ": các khả năng khác nhau phụ thuộc vào tham số mô hình theo những cách hoàn toàn khác nhau. Suy luận có thể xác minh gần hơn với một khả năng có thể nén cao, đặc chắc tham số, cốt lõi của nó nằm ở suy luận nhiều bước, thỏa mãn ràng buộc, tự sửa lỗi và xác minh câu trả lời. Khi không gian nhiệm vụ có cấu trúc đủ rõ ràng và tín hiệu phản hồi đủ đáng tin cậy, một mô hình nhỏ gọn cũng có thể có khả năng suy luận gần với mức tiên phong. Ngược lại, kiến thức lĩnh vực mở, hội thoại chung và hiểu biết các tình huống đuôi dài (long-tail) lại phụ thuộc nhiều hơn vào tham số quy mô lớn để bao phủ rộng rãi các sự kiện, khái niệm và kiến thức thế giới. Giả thuyết này rất mang tính gợi mở. VentureBeat trong bài báo đã viết: "Nó tiết lộ rằng có sự tách rời một phần giữa khả năng suy luận và kiến thức thực tế, và khả năng trước có thể được nén hiệu quả hơn so với những gì được nghĩ trước đây — một hiểu biết sâu sắc có tác động sâu rộng đến cách ngành công nghiệp nhìn nhận về thiết kế mô hình, chi phí triển khai và tính phổ biến của các tính năng AI cao cấp."

Tác giả cho biết, mục tiêu của họ không phải là tạo ra một mô hình nhỏ thay thế cho các mô hình quy mô lớn, mà là xem xét ranh giới thực sự của các mô hình nhỏ dọc theo các chiều kích khả năng cụ thể. Với VibeThinker-3B, họ hy vọng chỉ ra rằng, mô hình nhỏ không nên chỉ được coi là một giải pháp thỏa hiệp để giảm chi phí triển khai. Trong các lĩnh vực khả năng có cơ chế phản hồi và xác minh rõ ràng, các mô hình ngôn ngữ nhỏ đang thể hiện một con đường nghiên cứu đầy hứa hẹn, có khả năng đạt được hiệu suất ở mức tiên phong, và hình thành một mối quan hệ bổ sung cơ bản với mô hình mở rộng quy mô tham số truyền thống.
Hiện tại, mô hình này trong cộng đồng vẫn đang phải đối mặt với một số nghi ngờ. Nếu mọi người quan tâm đến mô hình này, tốt nhất nên tự mình thử nghiệm.

Liên kết tham khảo:
https://x.com/orcus108/status/2066876960073281582
Bài viết này đến từ tài khoản WeChat công cộng "机器之心" (ID:almosthuman2014), tác giả: Zhang Qian





