With the continuous improvement of LLM Code Agent capabilities, more and more researchers are realizing it's time to advance to the next stage of long-horizon tasks that are closer to real-world scenarios. Consequently, some benchmarks for evaluating long-horizon tasks have emerged, such as NL2RepoBench and BeyondSWE. The expected role of Code Agents is gradually shifting from repository maintainers to architects, capable of planning and completing long-horizon coding tasks for entire repositories.
Recently, the Gaoling School of Artificial Intelligence at Renmin University of China completed related research and officially released the DeNovoSWE dataset, focusing on long-horizon software engineering tasks, particularly repository-level code generation from scratch.

Paper link: https://arxiv.org/pdf/2606.10728
Repository link: https://github.com/AweAI-Team/DeNovoSWE
Data link: https://huggingface.co/collections/AweAI-Team/denovoswe
Through the mechanisms of Divide & Conquer and Critic & Repair, a high-quality dataset was constructed, successfully achieving scaling for long-horizon SWE tasks. This effort resulted in DeNovoSWE, an open-source, high-quality long-horizon SWE task dataset containing 4,818 real-world instances. This achievement provides large-scale data for training Code Agents' long-horizon capabilities, significantly enhancing their performance on such tasks.
The paper also proposes methods based on difficulty score filtering, effectively alleviating the trade-off between the proportion of difficult problems and trajectory quality.
Experiments show that the Qwen3-30B-A3B-Instruct model trained on DeNovoSWE improved from 5.8% to 47.2% on BeyondSWE-Doc2Repo and from 4.3% to 23.0% on NL2RepoBench, demonstrating the significant boost in repository-level code generation capabilities brought by long-horizon data.
Rebuilding an Entire Repository from a Single Document
Over the past year, with the scaling of large-scale SWE data in works like Scale-SWE, code agents have rapidly progressed on real software engineering tasks like SWE-bench. But as models become increasingly adept at "fixing an issue" or "changing a few lines of buggy code," a more critical question arises: Do agents truly possess long-horizon software engineering capabilities? Judging from the performance of frontier models on BeyondSWE-Doc2Repo and NL2RepoBench, the results are not ideal.
Real-world software development often isn't about modifying a single function or adding a conditional statement. It involves understanding requirements, planning architecture, creating files, designing APIs, handling dependencies, connecting modules, and ultimately making the entire repository run successfully in tests.
In other words, the real challenge lies in long-horizon repository-level generation: starting from a task document and generating a complete, executable, and verifiable software repository. This is precisely the problem DeNovoSWE aims to solve.
High-Quality "Generate from Scratch" Task Documents
In document-to-repository generation, the document is not just a README, nor a simple API list. It is essentially the sole task entry point for the agent to rebuild the entire repository.
A high-quality task document needs to meet at least two core standards.
First, it must be well-organized.
Repository-level tasks are inherently complex, involving multiple modules, interfaces, configurations, data structures, and interaction flows. If the document merely piles up function descriptions, the agent can easily get lost in fragmented information. Therefore, the document should first provide a clear overview of the repository, then divide into chapters based on capabilities or workflows, ensuring each part corresponds to a clear functional boundary.
Second, it must be written from the perspective of reliable evaluation.
The document cannot be too sparse, otherwise the task becomes an underdefined problem, potentially requiring the model to guess aimlessly to pass evaluation. Nor can it be too detailed, as that would directly leak implementation details, making the task unchallenging.
A truly high-quality document should describe the key behaviors on which evaluation depends: including import paths, public APIs, inputs and outputs, default parameters, exception behaviors, configuration items, pattern strings, return fields, etc., while also outlining the general functionalities to be implemented. In other words, the document should be sufficient for the agent to reproduce testable behaviors, but it should not become a copy of the implementation code.
This is also the core idea of DeNovoSWE: making documents readable, implementable, and verifiable.
The DeNovoSWE Method
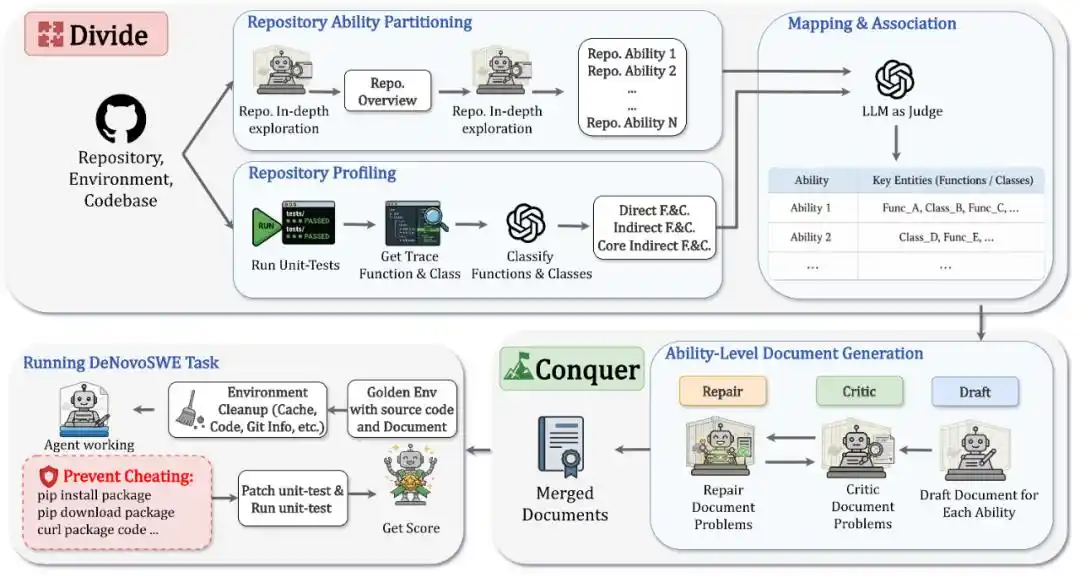
DeNovoSWE frames "generating a complete repository from a document" as a large-scale, verifiable long-horizon software engineering task. It does not rely on manually written documents but automatically constructs high-quality instances through a sandboxed multi-agent workflow. The entire method can be summarized in two steps: Divide and Conquer.
In the Divide stage, the system first analyzes the target repository, decomposing it into multiple repository capabilities.
Each capability corresponds to a core function or workflow within the repository, such as authentication and connection, data reading/writing, batch processing, export flows, etc. This way, the originally massive repository generation problem is split into several structurally clear document chapters.
Simultaneously, DeNovoSWE runs the original unit tests and collects execution traces to identify which functions, classes, and interfaces actually impact evaluation. This further distinguishes between direct components, core indirect components, and non-core indirect components: interfaces directly called by tests must be documented in detail; core indirect components that affect observable behaviors also need coverage; while non-core internal implementations can be left for the agent to handle freely.
In the Conquer stage, DeNovoSWE uses a Draft-Critic-Repair mechanism to generate documents for each capability one by one. The Draft agent writes an initial draft; the Critic agent checks for omissions of key APIs, behavioral contracts, or structural information; the Repair agent then fixes the document based on the feedback. This cycle iterates until each capability chapter is clear, complete, and aligned with evaluation.
Finally, the documents for different capabilities are merged into a single, comprehensive task document, serving as the sole basis for the agent to generate the repository from scratch.
Difficulty: Why is This a Long-Horizon Task?
The difficulty of DeNovoSWE tasks stems from a fundamental change: it's no longer issue-level fixing, but whole-repository generation.
In traditional SWE tasks, agents typically face an existing repository, needing only to locate a bug, modify local code, and pass tests.
In DeNovoSWE, the agent faces a cleaned environment: the original source code and tests are removed, git history is reset, and potential leakage channels like caches, site-packages residues, pip wheels, temporary compilation artifacts, etc., are also cleared. This means the agent must truly rely on the document to complete the entire repository rebuild. It needs to plan the project structure, create module files, define public interfaces, implement cross-file interactions, handle dependencies and configurations, and continuously fix errors across multiple rounds of editing and test feedback.
Any deviation in an API signature, return field, exception type, or default behavior can cause test failures. Errors can also accumulate over the long horizon: an early poorly designed module can affect multiple subsequent files and call chains.
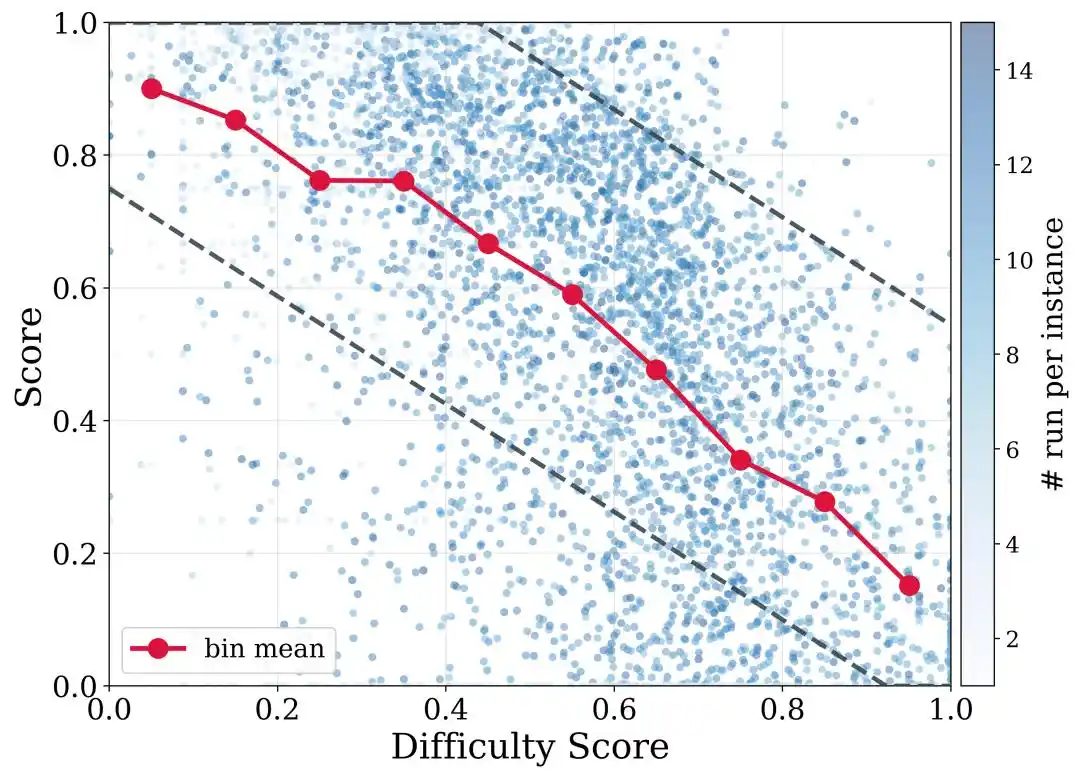
To further address the difficulty variance across different repositories, DeNovoSWE also proposes difficulty-aware trajectory filtering. In simple terms, easy tasks should require a higher pass rate, while difficult tasks should not be entirely discarded just for failing to achieve a perfect score. DeNovoSWE sets different filtering thresholds for different difficulty intervals based on structural complexity and LLM difficulty assessment, thereby balancing quality and diversity.
This is particularly important for long-horizon tasks: the more complex the repository, the harder it is to pass all tests in one go. Yet, the trajectories from challenging repositories, even with low scores or partial success, still contain valuable long-horizon planning and implementation capabilities.
Experimental Results
DeNovoSWE ultimately constructed 4,818 high-quality document-to-repository task instances. It is an executable, evaluable, and trainable long-horizon software engineering environment.
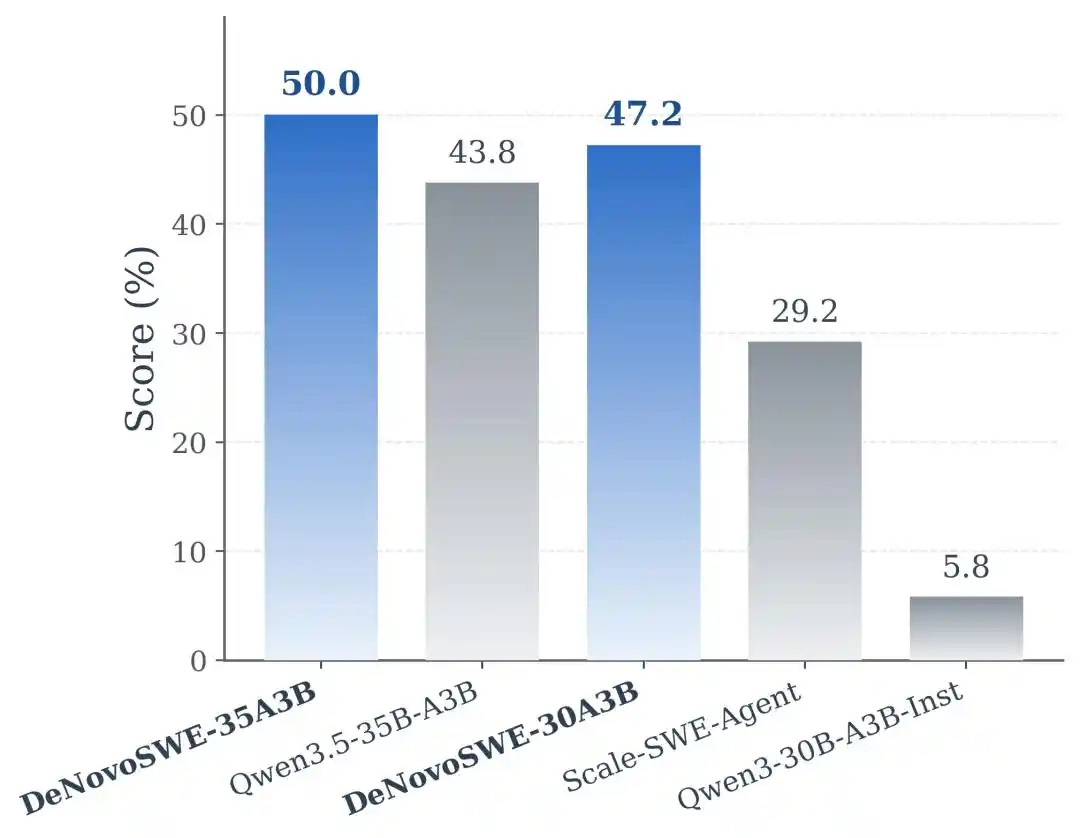
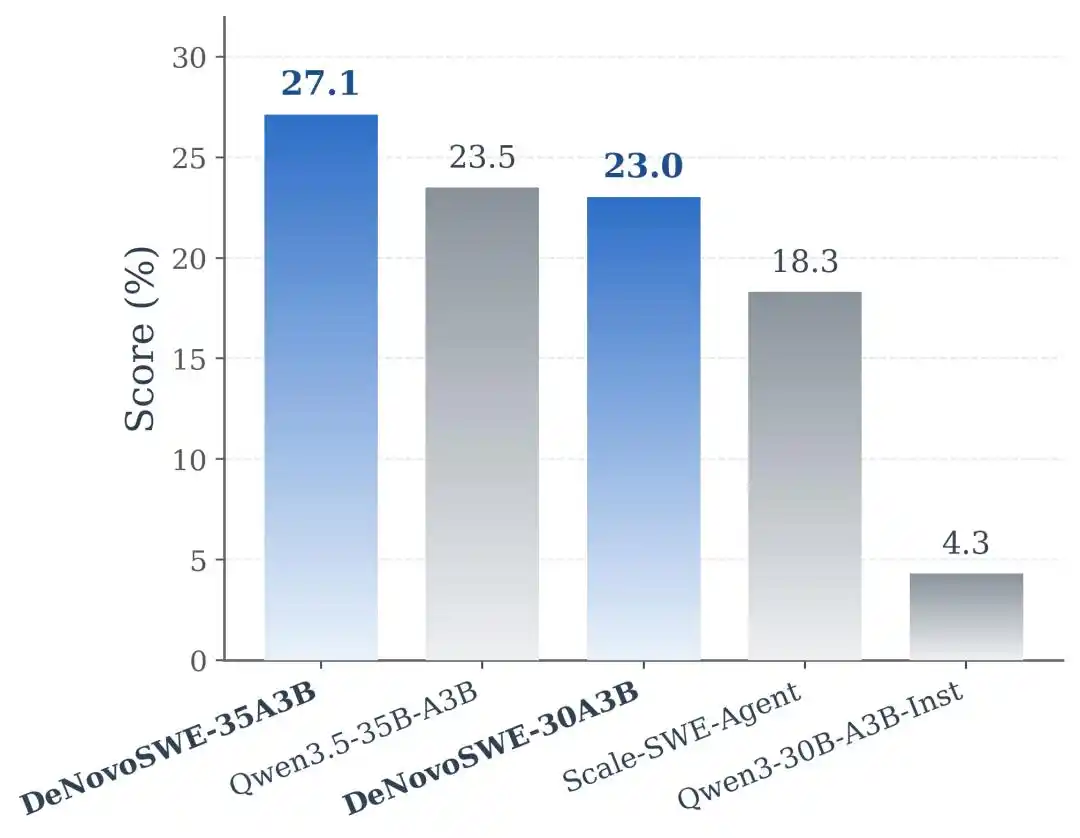
Experimental results show that DeNovoSWE brings significant improvements to models' long-horizon repository generation capabilities. For Qwen3-30B-A3B-Instruct, the original model scored only 5.8% on BeyondSWE-Doc2Repo and 4.3% on NL2RepoBench. Training with conventional issue-level SWE data like Scale-SWE-Agent improved these to 29.2% and 18.3%, indicating that general SWE data does have transfer effects. However, when the model was trained using DeNovoSWE, performance further increased to 47.2% and 23.0%.
This demonstrates that data oriented towards "fixing bugs" cannot fully replace data oriented towards "generating complete repositories" for long-horizon tasks. To truly teach agents repository-level engineering, specialized training environments built for long-horizon tasks are needed.
On the stronger Qwen3.5-35B-A3B backbone, DeNovoSWE similarly brought stable gains: BeyondSWE-Doc2Repo improved from 43.8% to 50.0%, and NL2RepoBench from 23.5% to 27.1%. This further indicates that the benefits of DeNovoSWE are not due to accidental adaptation to a specific model, but stem from the high-quality long-horizon data itself.
Conclusion
The next stage for code agents is not just about fixing individual issues faster, but about understanding documents, planning architecture, organizing modules, implementing interfaces, and ultimately generating a complete, runnable software repository.
DeNovoSWE systematically frames this goal into a trainable, verifiable, and scalable dataset. It answers a key question: What kind of data can truly train agents with long-horizon software engineering capabilities?
The answer is not more fragmented code, nor simpler problems, but high-quality, structured, evaluation-aligned, anti-leakage, full-repository generation tasks.
Starting from a single document, rebuild the entire repository. This is the threshold that long-horizon code agents need to cross.
Reference: https://arxiv.org/pdf/2606.10728
This article is from the WeChat public account "AI Era," edited by LRST.






