This article is from:arise
Compiled by | Odaily Planet Daily (@OdailyChina); Translator | Azuma (@azuma_eth)
The core content of this article is only one — how to prepare for the potential largest airdrop in the prediction market track.
Data Issues That Must Be Declared
Before building each model, we need real and reliable data. The trading volume data of Polymarket has been widely misreported.
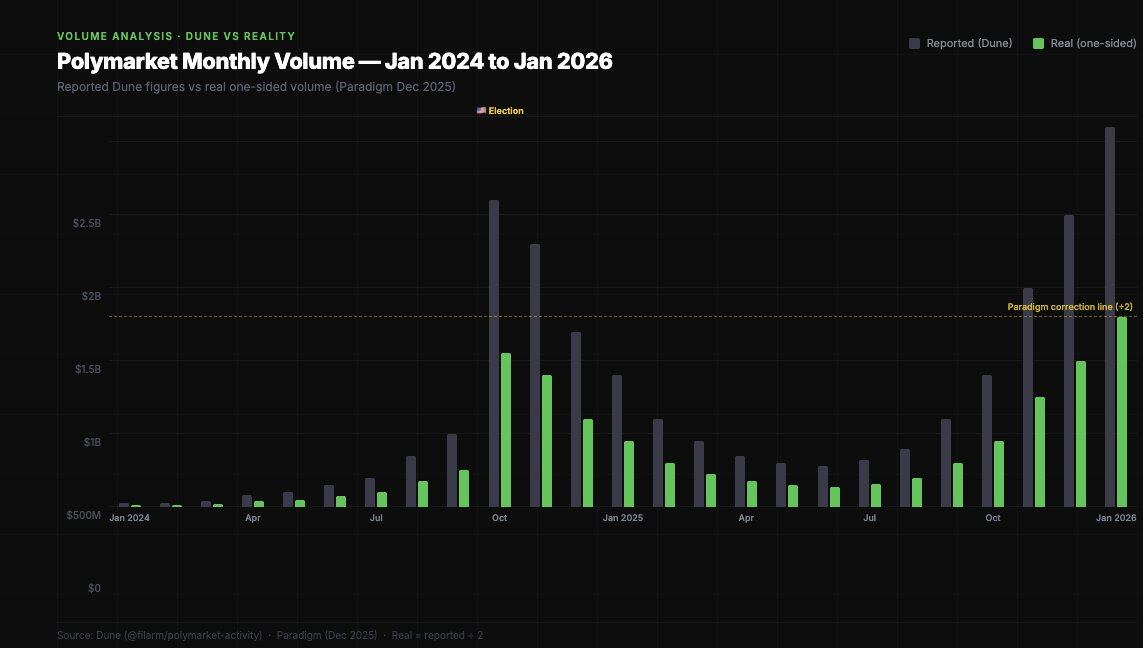
Paradigm published a key finding in a study in December 2025: Most Polymarket data dashboards count trading volume by summing all "OrderFilled" events, but this event is triggered on both the maker and taker sides of the same transaction, resulting in double counting. The actual trading volume is only about half of the number presented on the dashboards.
Dashboard volume vs. one-sided volume — the latter is the number that truly matters in airdrop modeling.
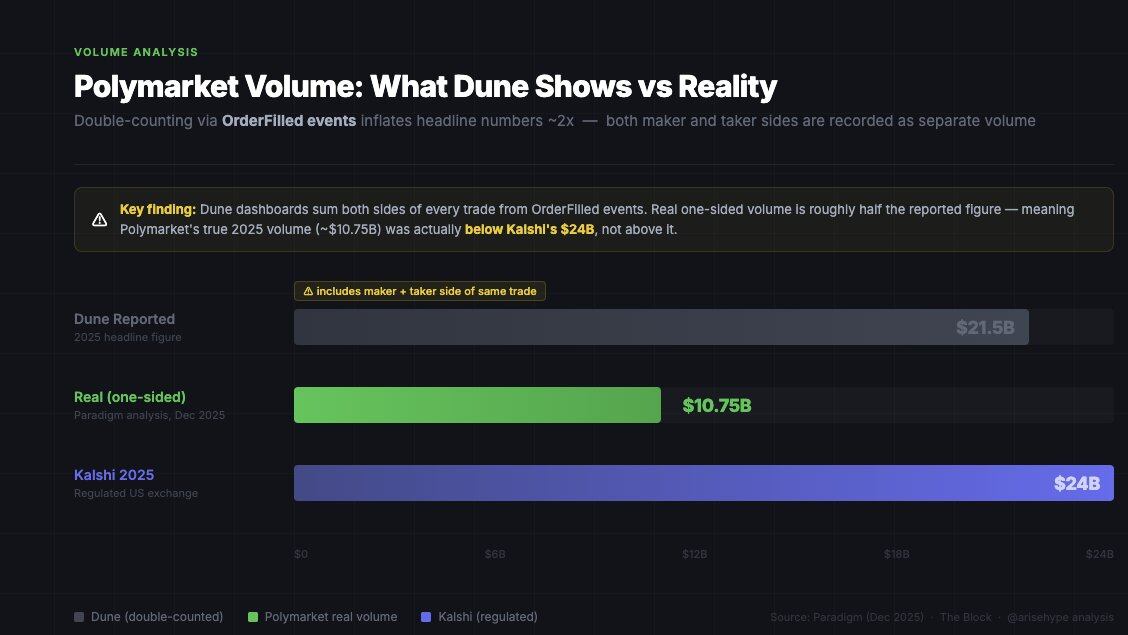
This is crucial for airdrop modeling. If Polymarket considers trading volume as a metric, they will only use internal data, not the various statistics on Dune. Your actual volume "score" is likely only half of what tools like Polycool show.
User Distribution
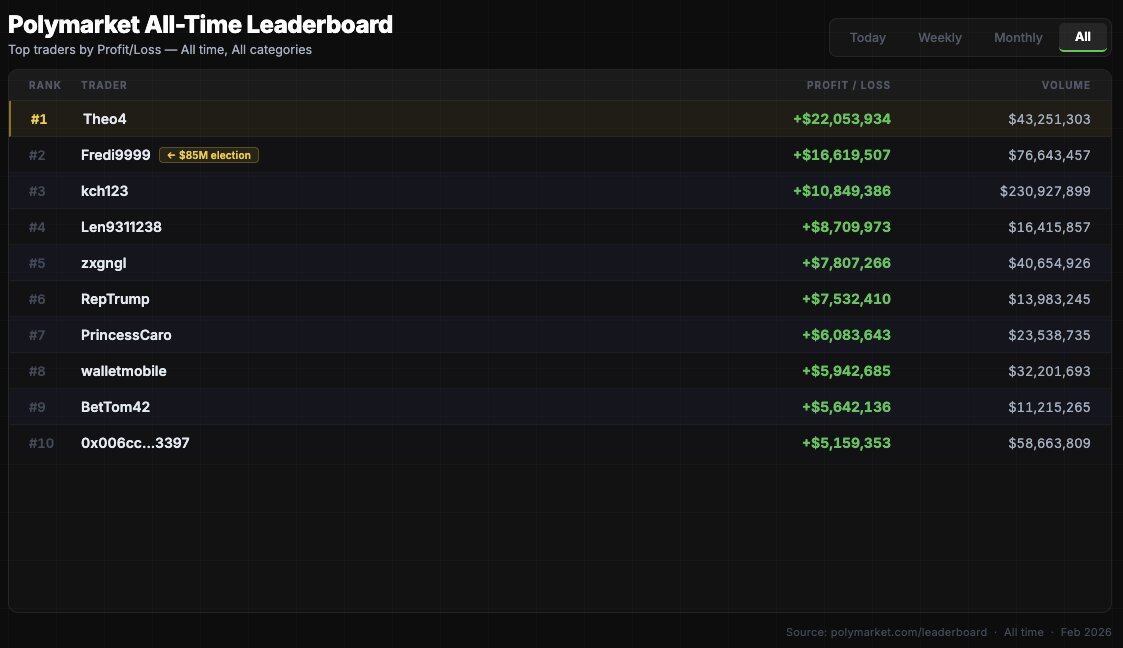
Regarding airdrop speculation, the most important dataset comes from a study by IMDEA Networks Institute, which covered over 86 million transactions (April 2024 – April 2025).
- Only 0.51% of addresses achieved profits exceeding $1,000;
- Only 1.74% of addresses (estimated) had a trading volume exceeding $50,000;
- The top 3 arbitrage addresses alone extracted $4.2 million in "risk-free profits";
- The top traders could profit over ten million dollars.
In terms of LP rewards, the stratification is even more pronounced.

79% of traders have never earned even $1 in LP rewards — this is currently the most overlooked interactive behavior. Among 314,000 traders, only 66,567 wallets have ever received LP rewards. This means only 21% of traders have ever provided liquidity. Compared to overall participation, this reward mechanism is clearly neglected.
Lower usage is generally seen as a signal of being "undervalued" in airdrop models.
Airdrop Precedents: What Has History Told Us?
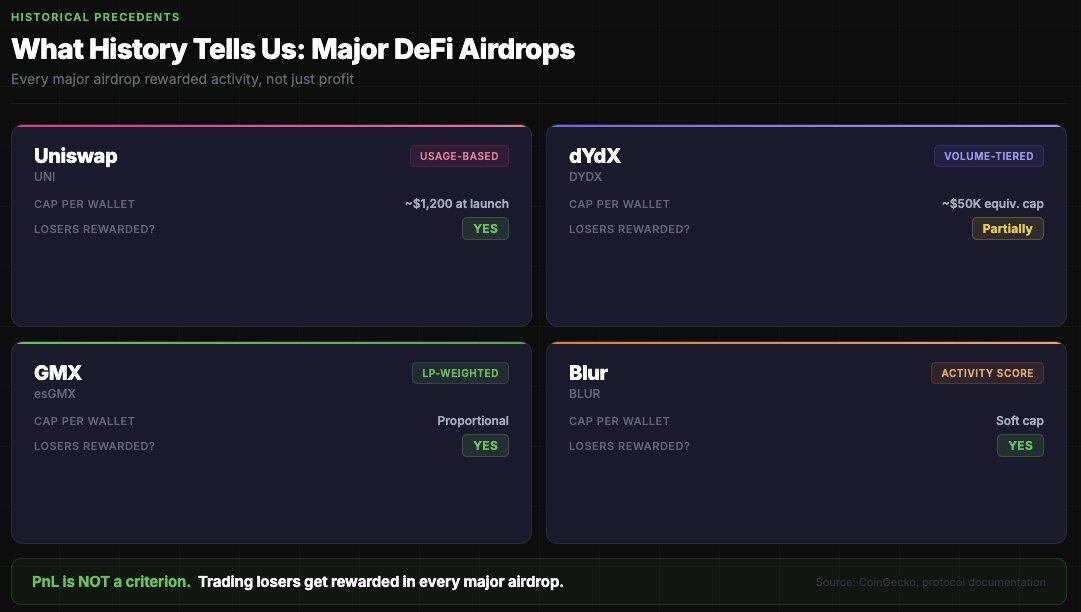
All major DeFi airdrops reward "active behavior," not "profitability." Polymarket will follow the same logic.
Commonalities of all large-scale airdrops include:
- Purely equal distribution would be abused by Sybil attacks (Polymarket will certainly not distribute equally);
- Purely distributing based on trading volume would overly concentrate the airdrop on whales (PR risk + SEC risk);
- Best strategy: tiered hierarchy + reward caps + multiple dimensions (volume + LP + diversity + active duration);
- In all major airdrops, losers are also rewarded — PnL is not a criterion.
The last point is crucial: If you traded $100,000 and lost $20,000, you are more likely to be rewarded than someone who traded $1,000 and made $500. The platform does not want to only incentivize profitable trading — that would more easily screen for insiders.
Reverse Thinking: How to Limit Whales?
Some airdrop calculators on the market use the simplest volume ratio model: Airdrop share = Individual volume / Total volume × Airdrop amount.
This is wrong because mainstream airdrops consistently use a "diminishing curve."
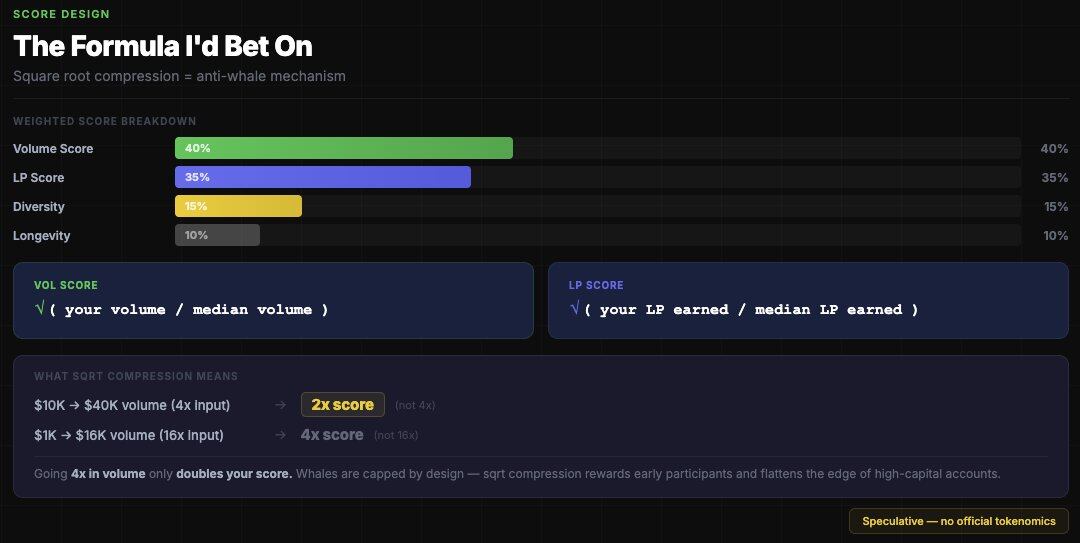
The model I'm more inclined to bet on is that Polymarket will use square root compression to limit the airdrop size for whales — for example, every 4x increase in volume only yields a 2x increase in score, which would completely change the airdrop results for the whale group.
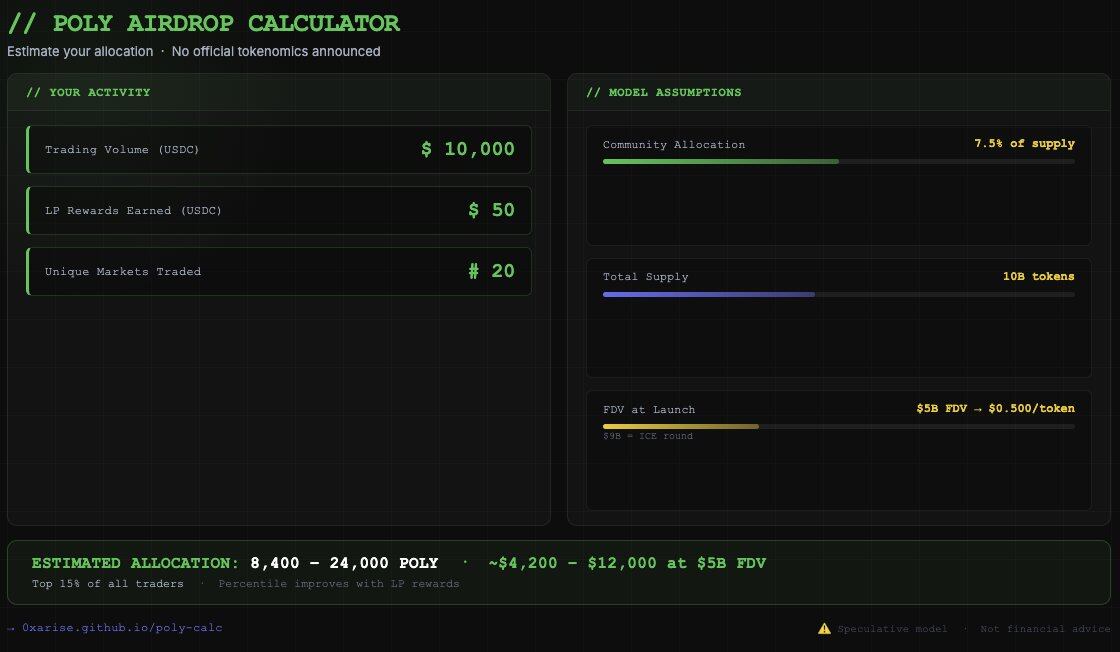
So how much would top wallets get? Assuming a total POLY supply of 10 billion, with 7.5% allocated for community airdrop (750 million POLY), and an FDV at TGE of $30–90 billion.
Without a cap on airdrop amount per address, for a volume of $85 million (taking top trader fredi999 as an example), the model estimates about 3–5 million POLY. At a $90 billion FDV, this is equivalent to $3–4.5 million. Theoretically possible, but the PR effect would be terrible.
A more realistic scenario is to cap the airdrop per address, e.g., the cap might be 500,000–2 million POLY. At a $5 billion FDV, top addresses could get about $450,000–$1 million.
"LP" vs. "Volume": Where is the Opportunity Now?
If you start interacting with Polymarket in February 2026 with a principal of $5,000, mathematically, deploying LP is a more favorable option for new participants.
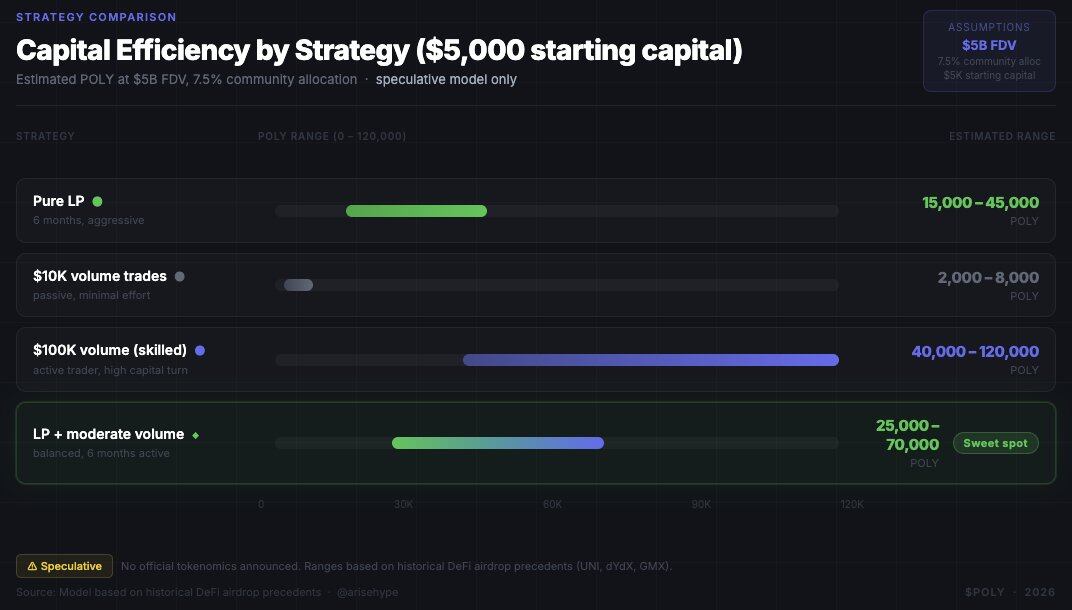
- To earn $49 in LP rewards (top 10%), you need to consistently place limit orders in high-reward markets. This is achievable in 30–60 days using $500–$1,000 in capital.
- To earn $1,563 in LP rewards (top 1%), higher capital or sustained high-frequency participation is required.
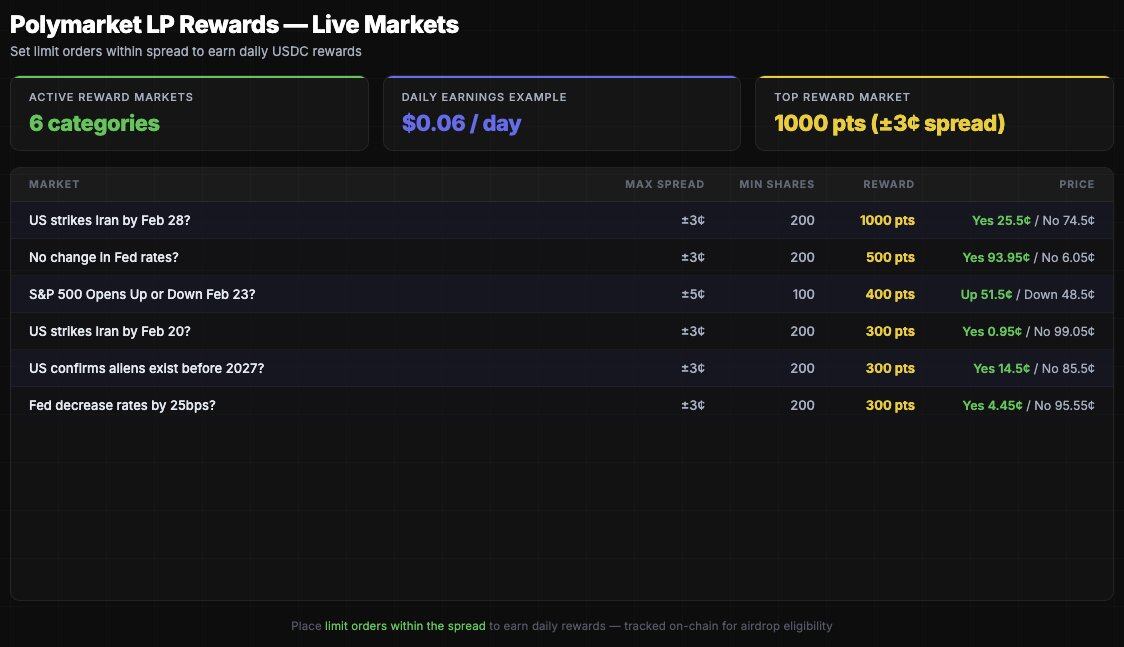
As for volume, you need to accumulate real volume without wash trading:
- Trade in 5 or more different categories of markets (politics, crypto, sports, science, culture);
- Hold positions for at least 1–24 hours before closing;
- Do not engage in wash trading the same market across different addresses;
- Lose money moderately — this is proof of "real participation";
- Target markets with volume > $500,000 (Polymarket might filter out micro markets);
- Single bet size: $50–$500.
Airdrop Model Speculation
The airdrop will not be as most people expect.
Most airdrop guesses are based on the simplest volume-weighted distribution, but Polymarket will do it smarter and more interestingly. They have on-chain LP data, which is clean, verifiable, and all measured in USD. They also have volume data that can filter out Sybil patterns. They also have wallet age, market diversity, and geographic distribution data.
This is my model — Polymarket has not confirmed anything, so this is just my speculation.
- Volume weight: 40% — will use a square root compression formula, minimum threshold around $500;
- LP reward weight: 35% — on-chain verifiable, Sybil-resistant;
- Market diversity weight: 15% — number of unique markets participated in;
- Active duration weight: 10% — number of active months before the snapshot.
Additionally, Polymarket will cap rewards per address (likely $500,000), otherwise the top 50 addresses would get too large a share, damaging the community narrative. Losers will receive the same reward as profiteers with equivalent volume; profitability is not a criterion — this cannot be philosophically justified and would create perverse incentives.
79% of traders have never received $1 in LP rewards. If LP weight accounts for 35% of the airdrop formula, the most capital-efficient behavior currently is to provide limit orders in high-volume markets and start accumulating on-chain verifiable proof of contribution.
In short, POLY could become the largest airdrop in the history of prediction markets. Calculated at a $9 billion FDV, the total value of the community airdrop could reach $450–$900 million. Even capturing just 0.1% of that is $450,000. This is why optimizing LP data now is more important than most people realize.