The 2026 Google I/O developer conference left only one impression: arrogance.
Not only did they cram AI agents seamlessly into all core traffic portals like search, browsers, phones, and smart glasses like force-feeding a duck, but they also threw out three killer bombs in a row: Gemini 3.5 Flash, the video model Omni, and the brand-new AI assistant Spark.
After flexing its muscles, Sundar Pichai even boasted by announcing that Gemini's monthly active users had surpassed 900 million, and simultaneously announced a significant price reduction.
The message couldn't be clearer:I'm stronger and cheaper than you.
If that's not a declaration of war, what is?
01
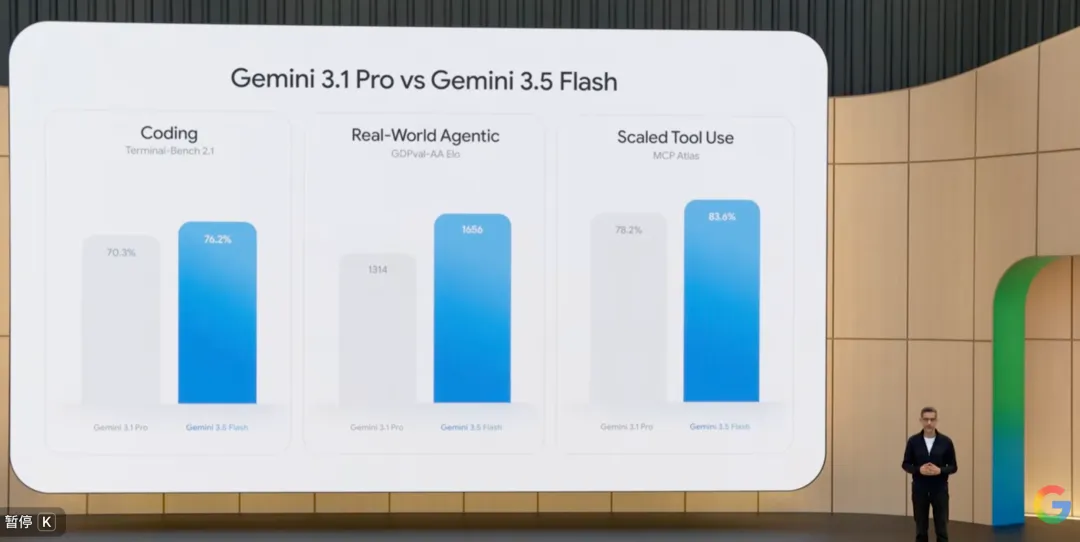
Undoubtedly, the most dazzling highlight of the conference was the debut of Gemini 3.5 Flash.
Normally, "Pro" represents the core strength, while "Flash" represents lightweight and speed.
In terms of model parameters, 3.5 Flash is indeed smaller than 3.1 Pro, yet its performance surpassed the latter in almost all reasoning and coding benchmarks:
In the GSM8K test for complex mathematical reasoning, 3.5 Flash scored 95.8%, surpassing 3.1 Pro's 93.2%; in the full version of the SWE-bench for code generation capability, 3.5 Flash achieved a solve rate of 38.4%, far exceeding 3.1 Pro's 32.1%......
Why?
According to the "Gemini 3.5 Technical Report" released by DeepMind, there are two key core technologies.
Extreme Knowledge Distillation: Google did not simply rely on brute-force compute to train Flash this time. Instead, it used a never-before-disclosed "Gemini 3.5 Ultra" as a teacher model for dimensional reduction distillation of Flash.
According to a tweet analysis by Jeff Dean, Chief Scientist at DeepMind, the proportion of fine-tuning on high-quality reasoning chain datasets for 3.5 Flash increased by 400% compared to the previous generation.
This means it inherited the "logical brain" of a super-large model, rather than a memorized "knowledge base."
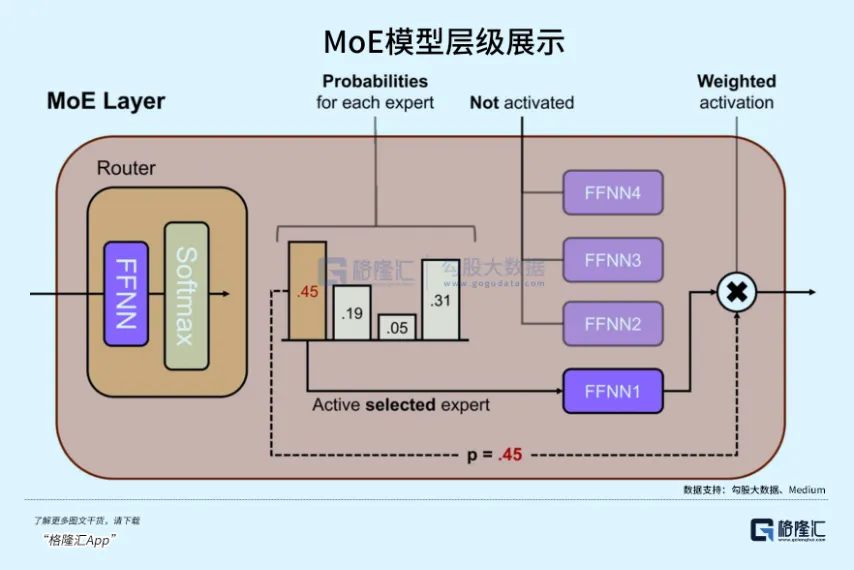
A Novel MoE Architecture (Mixture of Experts): Inside 3.5 Flash, Google employed more fine-grained expert networks.
Traditional MoE might only have 8 or 16 experts, activating only 1-2 per task, sufficient for supporting trillion-parameter scale models.
However, according to an analysis from a16z's 2026 AI Infrastructure Investment Memo, 3.5 Flash employs 256 micro-experts, activating the most efficient 4 of them during each inference.
This is why it can cover an extremely vast multimodal feature space while maintaining an extremely low number of activated parameters.
In the TTFT (Time to First Token) metric, 3.5 Flash has reached below 65 milliseconds.
A human blink takes 100-150 milliseconds.
In short, when it operates as an agent, from a human physiological perspective, there is virtually no perceptible delay.
For developers requiring frequent tool calls, multi-round reflection, and extremely low latency, this is the perfect super-agent foundation.
Only with such extreme engineering optimization can "device-side deployment" dominance be established in a fiercely competitive environment.
First, the native multimodal Gemini Omni Flash.
Omni means all-around, targeting the earlier GPT-4o. Just from the name, you can feel the intensity of the rivalry.
At least in terms of performance, Gemini Omni Flash is far more deserving of the "o" character than GPT-4o.
Early models like Sora or Gemini 1.5 were essentially patchwork, converting speech to text and then text to vision.
But this released Omni features true native end-to-end multimodal alignment. It natively understands temporal coherence and physical laws within videos, and latency dropped from the industry average of 400-600 milliseconds to 120 milliseconds.
An example from the keynote: a user wearing a camera pours water; as the cup nearly fills, Omni can say "Stop stop stop!" 0.5 seconds before the water overflows.
This kind of real-time inference about the physical state of the real world seems simple but is profoundly significant:AI has officially evolved from a chatbot on a screen into a real-world auxiliary tool.
Although still in its early stages.
Second, the intelligent assistant Spark.
According to a The Verge interview with an Android engineering VP, Spark has been granted native API control at the system layer of Android 17.
In short, the complex workflows that previously required you to open many apps can now be handled without lifting a finger. Just tell Spark what you need, and it can handle everything for you—even sending messages in your tone, sorting emails, summarizing schedules, tracking webpage updates, identifying hidden charges on bills, batch-processing documents, and so on......
In other words, with an AI assistant in the future, we might hardly need apps anymore; any complex operation is simplified into a single command.
Third, smart glasses.
Why glasses again?
At least in Google's view, seamless access to vision and hearing is the ultimate host for multimodal large models.
These glasses appear without any fancy aesthetics, focusing entirely on utility:
4-gram Micro-OLED full-color waveguide lenses with a light transmittance as high as 85%;
Equipped with a self-developed lightweight Gemini edge-side chip, local inference latency ≤12ms, capable of real-time translation, image recognition, and scene analysis without an internet connection;
Natively integrated with the Spark agent, syncing with phone and cloud data to deliver personalized services like schedule reminders, real-time translation, and environmental alerts.
In short, it's about bypassing the phone screen and embedding the agent into the human first-person perspective through glasses.

There's simply too much content. Google seems to have dumped all its trump cards at once, proclaiming a truth to the market:
An algorithm without an entry point is nothing.
The era of chasing model parameters and benchmark scores is over. Pure model providers no longer have a moat. The future is a four-dimensional space battle of "device + cloud + ecosystem + hardware."
Cramming AI into its suite is reshaping the entire internet's traffic distribution logic: from "users actively search/click" to "AI agents actively distributing services."
For the vast majority of developers and small-to-medium enterprises, this is excellent news because the underlying compute and models become extremely cheap, allowing everyone to focus on application-layer innovation.
But other competitors right now probably just want to curse out loud.
02
When Sundar Pichai casually announced on stage that "Gemini's monthly active users have officially surpassed 900 million," it caused quite a stir in the audience.
900 million—more than all the MAUs of its US competitors combined.
How was this achieved?
The answer is simple and brutal: Forced integration.
Google doesn't need to spend on advertising for user acquisition like independent AI companies. It just needs to add an icon next to Chrome's address bar, integrate a shortcut in the bottom navigation bar of 3 billion Android phones, push a full update within Google Workspace......
The customer acquisition cost is basically zero.
More crucially, in the coming period, the gaze of 900 million active users as they look at products with smart glasses, the logical adjustments made when using Spark to handle tasks, and the interactions with the Omni visual model will generate a massive amount of high-quality, multimodal real-world feedback data, all of which will become nourishment for Gemini 4.
This forms an extremely robust barrier:The better the model -> the more people use it -> the more data generated -> the better the model becomes.
To rapidly strengthen this loop, Google directly declared a price war on all competitors: The AI Ultra subscription was slashed from $249.99/month to $99.9/month.
The input price for 1 million tokens for 3.5 Flash was driven down to $0.02, and the output price for 1 million tokens is $0.08.
What kind of magical price is this?
For comparison, the industry average prices for similar-tier models are $0.15-0.2 and $0.6-1, respectively.
Sundar Pichai calculated: top customers process about 1 trillion tokens per day. Shifting 80% of the workload to Gemini 3.5 Flash for a year can save over $1 billion.
Why dare to sell AI at cabbage prices?
The biggest reliance is: vertically integrated computing infrastructure.
Including giants like OpenAI, Anthropic, despite their apparent success, are essentially "compute tenants," needing to buy computing power from Microsoft, Amazon, who in turn pay Jensen Huang (Nvidia).
Google has its own TPUs, coupled with the incredibly efficient sparse activation of 3.5 Flash's MoE architecture, compressing compute costs to the extreme.
It can leverage its heavy-asset advantage to deliver a dimensional blow to pure algorithm companies.
The logic is clear.
Foundation models are rapidly becoming commoditized. Like water and electricity, have you ever seen a water utility company making obscene profits?
Google isn't afraid of the model itself not being profitable, because it can make money back through search ads, cloud services, and fees from the Android ecosystem.
But for pure model API sellers like OpenAI, Anthropic, Cohere, Mistral, this is not feasible.
Investors probably want to press Sam Altman's head and ask:"Google's API price is only one-tenth of yours, and its performance is better. Tell me, how does your business model work?"
Competitive landscapes across multiple industries will thus enter an accelerated reshuffling period.
AI vendors, needless to say, must quickly find cheaper compute sources or venture into chipmaking themselves.
Next is Apple, still developing behind closed doors.
The combination of smart glasses + the Omni video model + Spark's native system-level control undoubtedly already threatens the iPhone.
According to Macquarie's "Consumer Electronics Trend Forecast Report": Within the next three years, the proportion of time spent on screenless interaction based on vision/voice is expected to jump from the current 8% to 35%.
If users get accustomed to using glasses and voice for daily work and entertainment, screen time will inevitably be significantly reduced.
If Apple cannot counter with sufficiently impressive wearable devices (Vision Pro is too heavy and expensive, destined to be a toy for a minority), its monopoly on mobile internet entry points will face an unprecedented challenge.
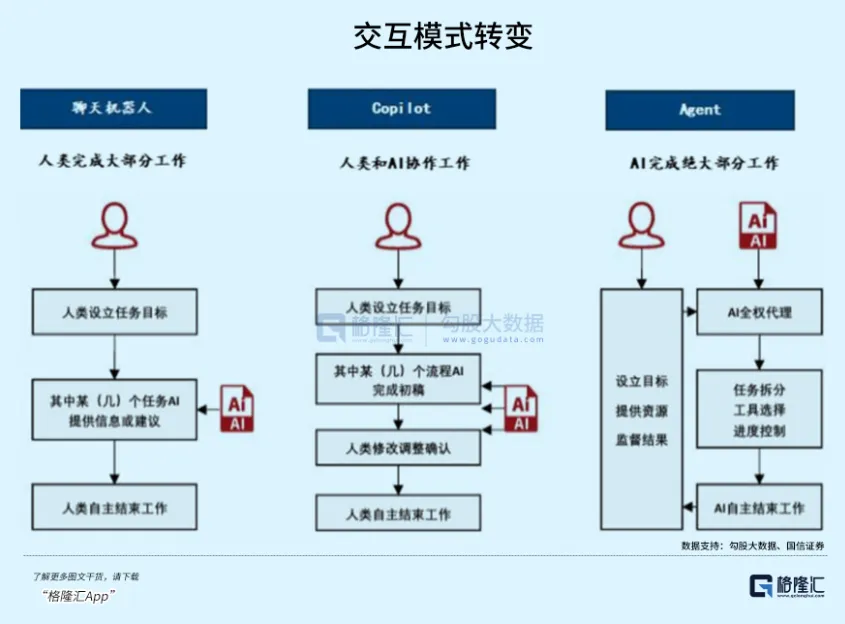
This is not an iteration; it's a revolution.
Google, with its three blades—technology, traffic, and price—has issued a declaration of war to all its rivals.
Is there anyone still laughing at its corporate bureaucracy now?






