[Introduction] GPT-5.5 exposed for "fake thinking," secretly switched to 'mini' after two hours of use. $200 monthly fee buys you a "Schrödinger's brain." Trace command provides concrete evidence, official documentation personally acknowledges. Users are flocking to complain: OpenAI, who are you trying to fool?
ChatGPT has been caught "dumbing down" again!
Just in the last couple of days, it blew up on X first.
User Lisan al Gaib discovered that after using GPT-5.5 for an hour or two, it suddenly became stupid, with every request answered instantly and quality plummeting off a cliff.
Yet the interface still displayed "GPT-5.5 Extended Thinking."
In other words, the thinking label was still there, but the thinking itself had vanished.

$200/month for a "Schrödinger's Model"
On the OpenAI developer forum, a complaint post blew up simultaneously.
Agentify.sh stated that GPT-5.5 would suddenly lose its ability to follow instructions during use.
Watching it excitedly announce it was "fixed," only to produce code so poor it triggered a mass rollback.
UI tasks that the previous 5.5-med could handle easily now couldn't even manage the simplest changes.
Upgrading to 5.5-high didn't work. Upgrading again to xhigh, still no luck.
And xhigh, which used to run for several hours, now clearly lasted a shorter time.
As soon as the post went up, the replies exploded.
Some directly reverted to 5.4.
One used the highest tier, xhigh, but found it "clearly worse than last week, frequent errors on long tasks, not following the workflow at all."
One reported an even more bizarre situation: "Simple queries also take ages to process, and if you interrupt to correct its direction, it completely ignores you and continues with its previous incorrect plan."
That's right, everyone was describing the same phenomenon—GPT's brain had been swapped out at some unknown point.
GPT-5.5's current performance is on par with 5.3, no exaggeration. It was amazing the first few days, but now you can't find a trace of that original model.

Not an illusion, OpenAI spells it out in black and white
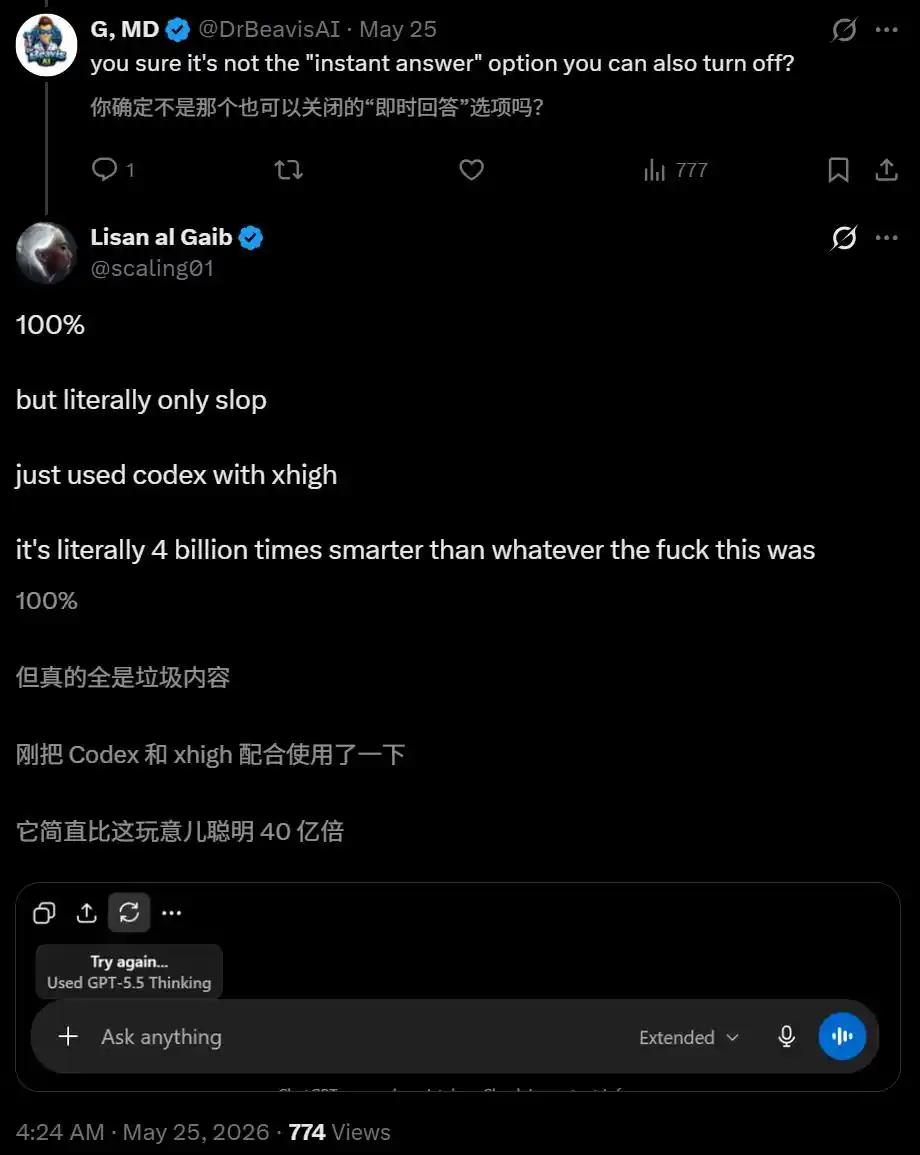
To verify, Lisan al Gaib conducted a comparative test.
Same account, Extended Thinking on the ChatGPT side produced garbage, but switching to xhigh on the Codex side immediately restored normal performance.
In his own words, Codex was "literally 4 billion times smarter than this thing."
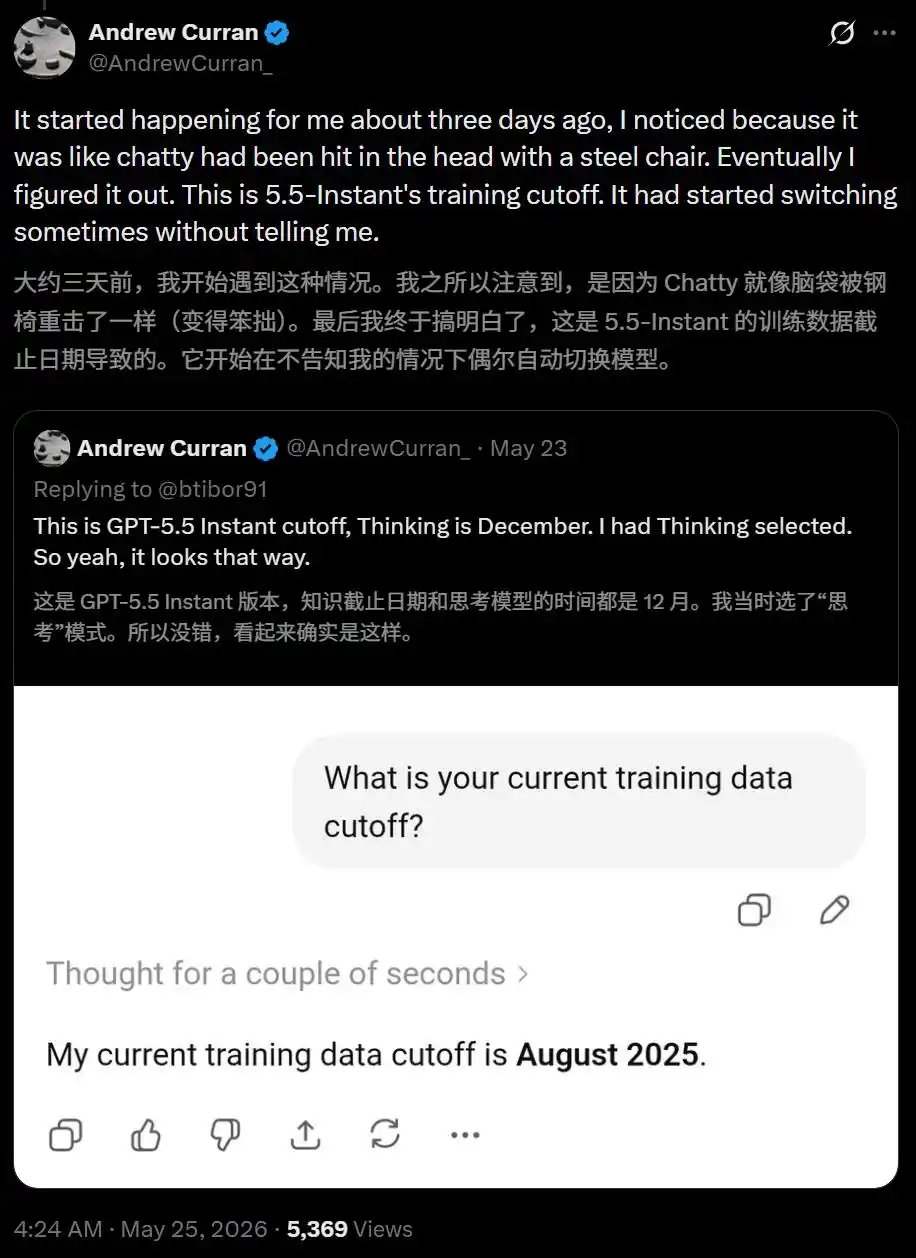
Developer Andrew Curran came up with a clever trick—directly asking the model, "What is the cutoff date for your training data?"
The model answered: August 2025.
The problem? The cutoff date for GPT-5.5 Thinking is December. August is the cutoff date for the Instant version!
In other words, he selected Thinking, but the system actually ran Instant for him.
Not a single word of the model label on the interface changed, but the model behind it had been secretly swapped......
The funny thing is, this time OpenAI itself nailed the coffin shut for users in its own help documentation.
According to the official explanation in the OpenAI Help Center, Plus users can send a maximum of 160 GPT-5.5 messages every 3 hours.
After that quota is used up, the system will silently switch to the mini model until the quota resets.
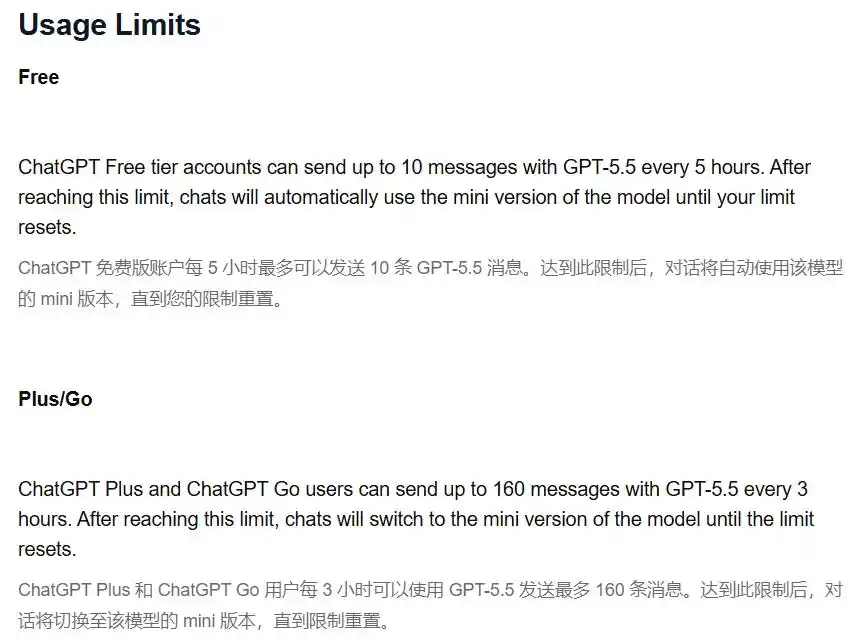
Note the word "silently."
No pop-up notification, no change in the model label, no visual feedback whatsoever.
You still think you're using the flagship model, while on the other end it has quietly been replaced with mini.
Pro users, don't celebrate too soon either.
Heavy thinking mode, the top reasoning tier exclusive to Pro users, is also subject to capacity throttling when server load is high. Again, without any warning.
In other words, a $200/month Pro subscription buys you a service that can be "switched out" at any moment.

This kind of "label unchanged, brain swapped" operation was caught even earlier on the Codex side.
In February this year, an issue appeared on GitHub where a Pro user used a trace command to discover that they were requesting GPT-5.3 Codex, but the actual model returned was GPT-5.2.
Not even 5.2 Codex, but the lower-tier base 5.2.
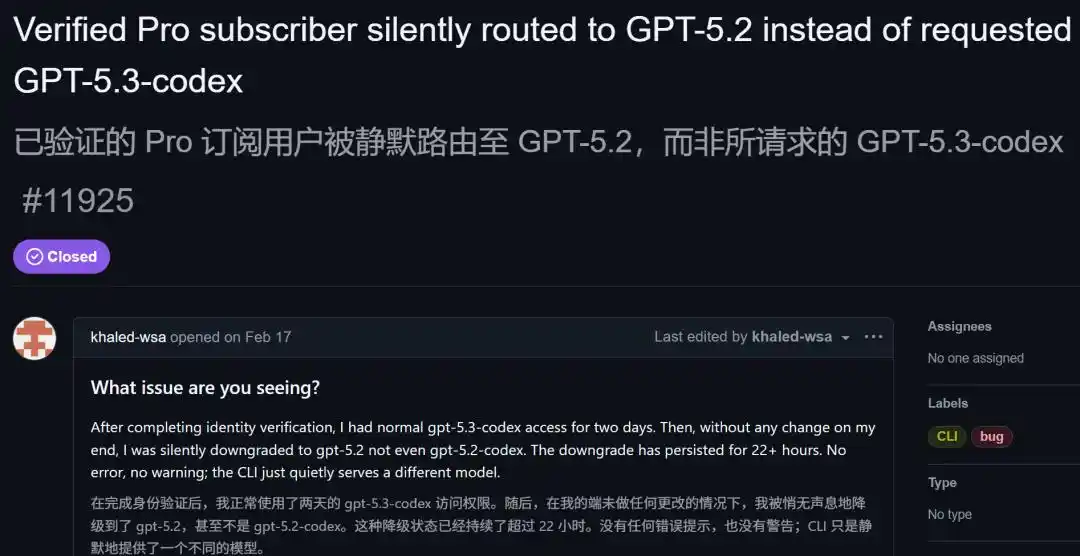
He posted the reproduction command:
- RUST_LOG='codex_api::sse::responses=trace' codex exec --skip-git-repo-check -s read-only -m 'gpt-5.3-codex' 'hi' 2>&1 >/dev/null | rg -o --replace '$1' '"model":"([^"]+)"' | head -n1
- Output: gpt-5.2-2025-12-11
- Expected: gpt-5.3-codex
Multiple Pro users confirmed the same downgrade under the same issue.
And this kind of downgrade is "sticky," it doesn't revert on its own, and there's no explanation.

Even on the day GPT-5.5 was released in April, there were user reports that the speed of Fast mode was similar to Standard, but billing was still at the Fast rate.
A simple task took 7 minutes and 49 seconds, when normally it should be 5-6 minutes.
OpenAI admitted it, and then... nothing
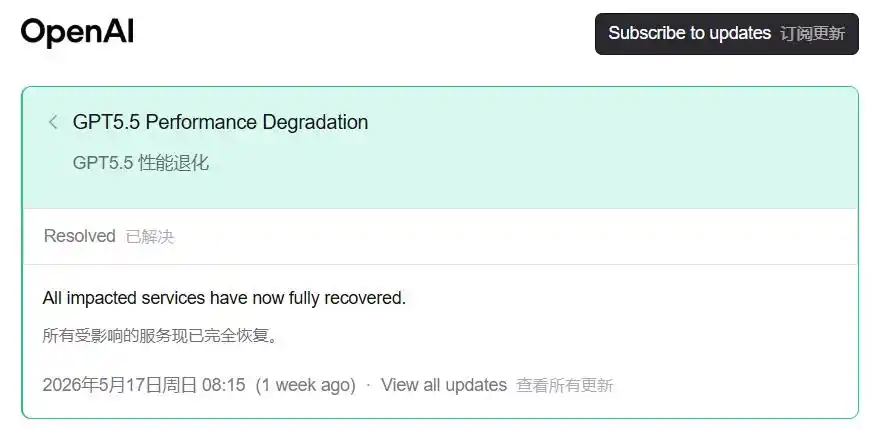
On May 15, a record appeared on OpenAI's status page.
GPT5.5 Performance Degradation, We are investigating reports of performance degradation for GPT-5.5 from some users.
On May 17, the status was updated to "Resolved."
But judging from the timeline of forum posts, complaints about "brain drain" from May 24-26 were even more intense than the wave on May 15.
Either the "resolved" problem came back, or it was never truly solved in the first place.
Every upgrade comes with a "brain drain controversy"
While all companies face complaints about their models "getting dumber," OpenAI hasn't missed a single one with every update from GPT-5 to GPT-5.5.
Every time OpenAI says it's investigating, every time it says it's resolved, and then continues with the next version.
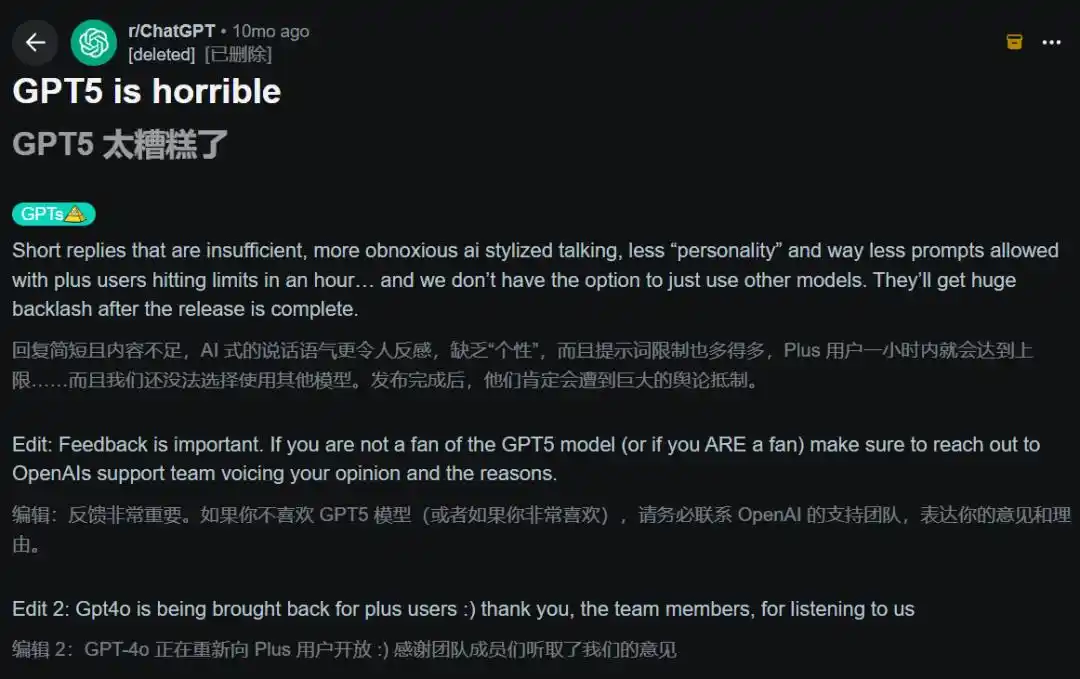
August 2025, GPT-5's debut. The hot post on Reddit was titled directly "GPT-5 is so bad." Users complained about short replies, more refusals, less personality.
OpenAI was forced to urgently restore the GPT-4o option. Altman personally admitted in a Reddit AMA, "bumpier than we expected."
December 2025, GPT-5.2. Translation quality regressed, fabricated non-existent APIs, refused to execute style instructions that 5.1 could easily handle.
February 2026, GPT-5.3-Codex. Pro users silently downgraded to 5.2, trace command confirmed.
March 2026, GPT-5.4. A post titled "GPT-5.4 has clearly regressed in Codex" appeared on the OpenAI community forum, with all replies confirming.
Early May 2026, GPT-5.5 Instant launched. Reply length shortened by 30%, emojis almost disappeared. User summary: Accuracy improved, but warmth vanished.
Late May 2026, now. Complaints about Thinking mode "brain drain" erupted again.
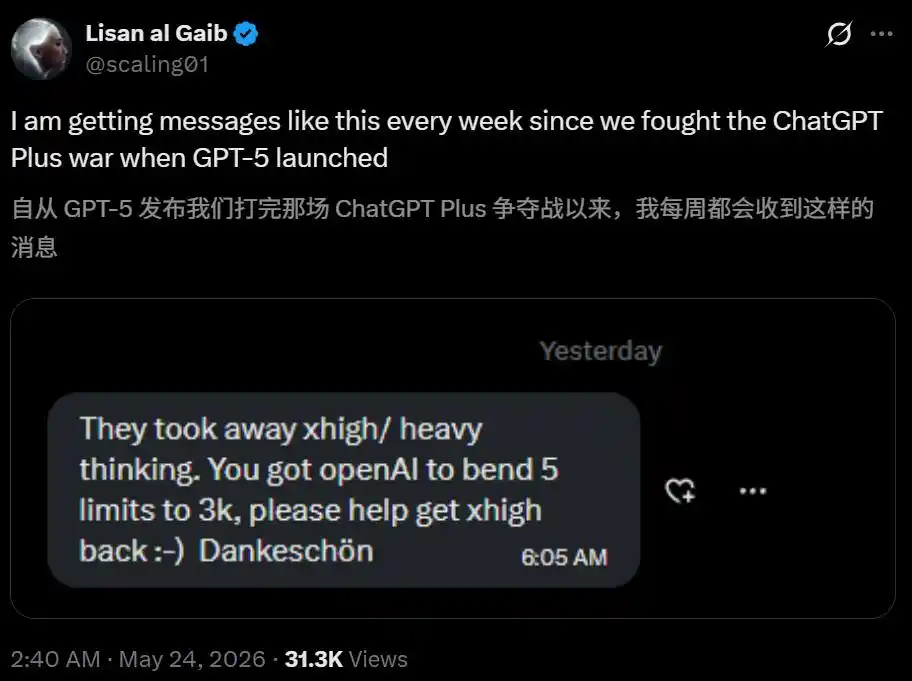
Lisan al Gaib revealed that since he led the fight for ChatGPT Plus quotas during GPT-5's release, "I receive DMs like this every week."
The latest one was someone asking him to help get their xhigh/heavy thinking back.
The day it benchmarks strongest is launch day
chatgptdisaster.com compiled 1087 verified user complaints, one frequently mentioned scenario is "routing layer failure," where the UI shows GPT-5.5 Pro, but the output is completely from another tier.
Users describe a reproducible pattern: after a long session, the model starts "completely ignoring what you say," but the top-tier label is still hanging on the model selector.

The most absurd footnote is that the mechanism for Plus users automatically switching to mini after using 160 messages/3 hours is described as a "feature" in OpenAI's official documentation.
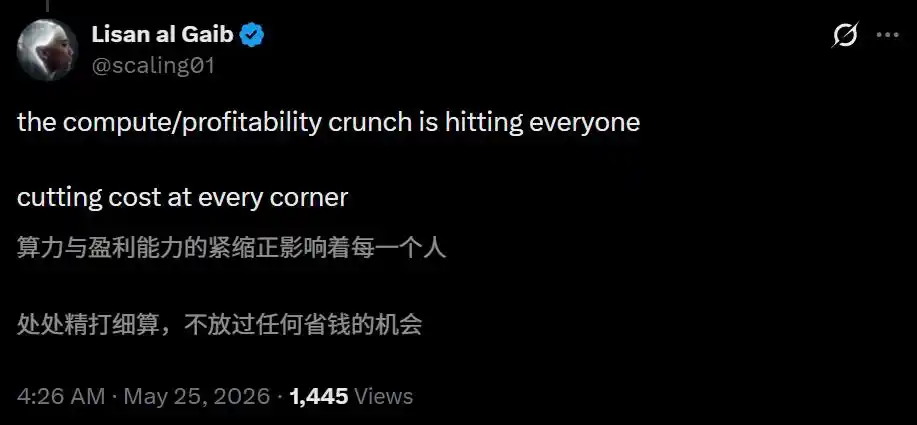
Why is this happening? Lisan al Gaib's analysis suggests the answer is two words: cost-saving.
The crunch on compute power and profitability is affecting everyone. Cutting corners everywhere, not missing any opportunity to save a buck.
Yet, in the same week GPT-5.5 users were collectively complaining, traces of GPT-5.6 had already appeared in Codex backend logs.
Internal codename iris-alpha, 1.5 million token context, Polymarket gave an over 85% probability for a June release.
On one side, 5.5 users can't even secure a basic experience; on the other, 5.6 is already quietly running real traffic in the background.
This is the 2026 ASI race.
The speed of creating new models is getting faster and faster, but making an old model run a single session properly is getting harder and harder.
The day it benchmarks strongest is always launch day, and every day after is Schrödinger's GPT.

Reference: https://x.com/scaling01/status/2058643470357590058?s=20
This article is from the WeChat public account "AI Era," author: ASI Apocalypse; Editor: Moses