Original Author: @BlazingKevin_, Blockbooster Researcher
1. The Birth Background and Evolution of Agent Skill
The AI Agent sector in 2025 is at a critical juncture, transitioning from a "technical concept" to "engineering implementation." In this process, Anthropic's exploration of capability encapsulation unexpectedly catalyzed an industry-wide paradigm shift.
On October 16, 2025, Anthropic officially launched Agent Skill. Initially, the official positioning of this feature was extremely restrained—it was merely seen as an auxiliary module to enhance Claude's performance in specific vertical tasks (such as complex code logic or specific data analysis).
However, the feedback from the market and developers far exceeded expectations. It was quickly discovered that this design of "modularizing capabilities" demonstrated extremely high decoupling and flexibility in practical engineering. It not only reduced the redundancy of Prompt tuning but also greatly improved the stability of Agents in executing specific tasks. This experience quickly triggered a chain reaction within the developer community. In a short time, leading productivity tools and Integrated Development Environments (IDEs), including VS Code, Codex, and Cursor, followed suit, successively completing underlying support for the Agent Skill architecture.
Faced with this spontaneous ecosystem expansion, Anthropic recognized the underlying universal value of this mechanism. On December 18, 2025, Anthropic made an industry milestone decision: officially releasing Agent Skill as an open standard.
Subsequently, on January 29, 2026, the official detailed user manual for Skill was released, completely breaking down the technical barriers for cross-platform and cross-product reuse at the protocol level. This series of actions marked that Agent Skill had completely shed its label as a "Claude-exclusive accessory" and officially evolved into a universal underlying design pattern in the entire AI Agent field.
Thus, a suspenseful question arises: What core pain points does this Agent Skill, embraced by major companies and core developers, actually solve in underlying engineering? And what is the essential difference and synergistic relationship between it and the currently hot MCP?
To thoroughly clarify these questions and ultimately apply them to the practical construction of crypto industry investment research, this article will progressively explore the following:
- Concept Analysis: The essence of Agent Skill and its basic architecture construction.
- Basic Workflow: Revealing its underlying operational logic and execution flow.
- Advanced Mechanisms: In-depth analysis of the two advanced usages: Reference and Script.
- Practical Case Study: Analyzing the essential differences between Agent Skill and MCP, and demonstrating their combined application in Crypto research scenarios.
2. What is Agent Skill and Its Basic Construction
What exactly is an Agent Skill? In the simplest terms, it is essentially a "dedicated instruction manual" that the large language model can refer to at any time.
In daily use of AI, we often encounter a pain point: every time we start a new conversation, we have to paste the long requirements again. Agent Skill was born to solve this hassle.

Take a practical example: Suppose you want to create an "intelligent customer service" Agent. You can clearly write the rules in the Skill: "When encountering user complaints, the first step must be to安抚情绪 (soothe emotions), and absolutely cannot make compensation promises casually." Another example, if you often need to do "meeting summaries," you can directly set the template in the Skill: "Every time a meeting summary is output, it must strictly follow the three sections: 'Attendees', 'Core Topics', 'Final Decisions' for typesetting."
With this "instruction manual," you no longer need to repeat that long string of instructions every time you start a conversation. When the large model receives a task, it will automatically refer to the corresponding Skill and immediately know what standards to use to get the job done.
Of course, "instruction manual" is just a simplified metaphor for easier understanding. In reality, Agent Skill can do much more than just format specifications; its "killer" advanced features will be explained in detail in later chapters. But in the initial stage, you can completely treat it as an efficient task instruction manual.
Next, let's use the "meeting summary" scenario, which everyone is most familiar with, to see how to actually create an Agent Skill. The whole process does not require complex programming knowledge.
According to the settings of current mainstream tools (like Claude Code), we need to find (or create) a folder called .claude/skill in the computer's user directory. This is the "headquarters" for storing all Skills.
First step, create a new folder in this directory. The name of this folder is the name of your Agent Skill. Second step, create a text file named skill.md in the newly created folder.
Every Agent Skill must have such a skill.md file. Its purpose is to tell the AI: who I am, what I can do, and how you should work according to my requirements. Open this file, and you will find it is divided into two clear parts:

At the very beginning of the file, there is usually an area enclosed by two short dashes ---. Only two core attributes are written here: name and description.
name: This is the name of the Skill, and it must be exactly the same as the outer folder name.description: This is an extremely important part. It is responsible for explaining the specific purpose of this Skill to the large model. The AI continuously scans the descriptions of all Skills in the background to determine which Skill should be used to answer the user's current question. Therefore, writing an accurate and comprehensive description is the primary prerequisite to ensure your Skill can be accurately activated by the AI.
The remaining part below the dashes is the specific rules written for the AI to see. Officially, this part is called "instructions." This is where you get to play; you need to describe in detail the logic that the model needs to follow. For example, in the meeting summary case, you can stipulate here in plain language: "Must extract the list of attendees, discussed topics, and final decisions made."
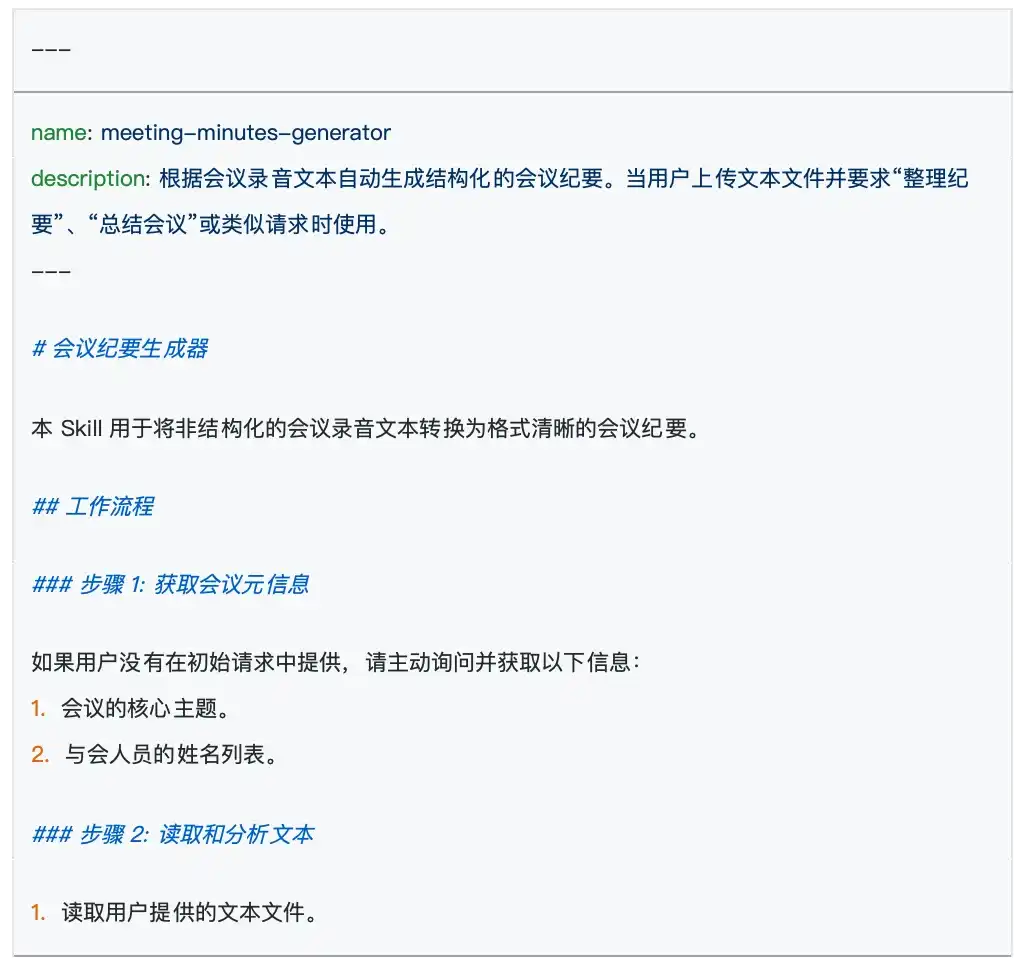

After completing these steps, a simple but very practical Agent Skill is born.
However, a truly useful Skill often starts with careful preliminary design. Before typing the first word on the keyboard, clearly defining the goal, scope, and success criteria will make your construction process twice as effective.
The first step in building a Skill is not to think "what fancy things can I make the AI do," but to ask yourself: "What repetitive problems in my daily work do I really need to solve?" It is recommended to start by specifically defining 2 to 3 clear scenarios that this Skill should cover.

Secondly, define the criteria for success. How do you know if the Skill you wrote is good or not? Before starting, set a few measurable standards for it. For example, quantitative standards could be "whether the processing speed has increased," and qualitative standards could be "whether the meeting decisions it extracts are accurate and without omission every time."
3. The Basic Operational Workflow of Agent Skill
After understanding the basic appearance of Agent Skill, we can't help but ask: How does this "instruction manual" actually work during operation?
If you have recently experienced products like Manus AI, you have probably experienced such a scenario: When you throw out a specific question, the AI does not immediately start "long-winded explanations" or hallucinate, but敏锐地意识到 (sharply realizes) that "this matter is managed by a specific Agent Skill." So, it will pop up a prompt on the interface asking if you allow the invocation of that Skill.
After you click "Agree," the AI, like a changed person, strictly follows the preset rules to perfectly output the result.
Behind this seemingly simple "request-approve-execute" interaction lies an extremely sophisticated underlying operational workflow. To explain this mechanism thoroughly, we first need to clarify the "three core roles" involved in the entire process:
- User: The person initiating the task request.
- Client Tool (e.g., Claude Code, etc.): The "middleman" responsible for scheduling and coordination.
- Large Language Model: The "brain" responsible for understanding intent and generating the final result.
When we input a requirement into the system (e.g., "Help me summarize this morning's project meeting"), the following four steps of precise collaboration occur between these three roles:
Step 1: Lightweight Scanning (Transferring Metadata)
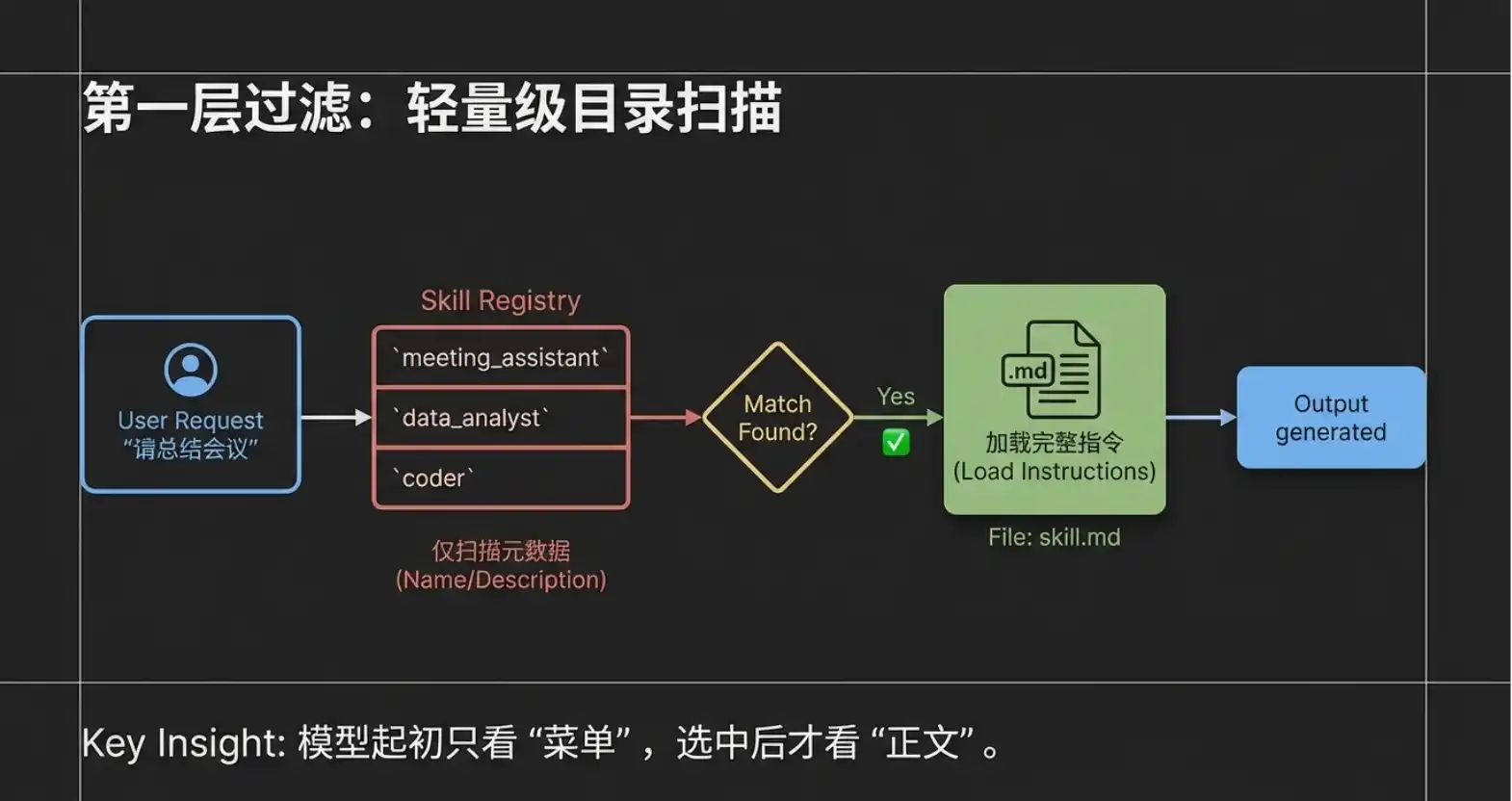
After the user inputs the request, the client tool (Claude Code) does not dump all the instruction manuals to the large model at once. Instead, it only packages the user's request along with the "names" and "descriptions" of all Agent Skills in the current system (i.e., the Metadata layer mentioned in the previous chapter) and sends them to the large model. You can imagine that even if you have installed a dozen or even dozens of Skills, what the large model gets at this time is only a "lightweight directory." This design greatly saves the model's attention and avoids mutual interference of information.
Step 2: Precise Intent Matching The large model, after receiving the user request and this "Skill directory," performs a quick semantic analysis. It finds that the user's request is "summarize meeting," and the directory恰好 (happens to) has a Skill named "Meeting Summary Assistant," whose description perfectly matches the task. At this point, the large model tells the client tool: "I found that this task can be solved using the 'Meeting Summary Assistant'."
Step 3: On-Demand Loading of Complete Instructions After receiving feedback from the large model, the client tool (Claude Code)才能真正进入 (truly enters) the dedicated folder of the "Meeting Summary Assistant" to read the complete skill.md body. Please note, this is an extremely critical design: Only at this moment is the complete instruction content read, and the system only reads this one selected Skill. Other unmatched Skills still lie quietly in the directory, not occupying any resources.
Step 4: Strict Execution and Output Response Finally, the client tool sends both the "user's original request" and the "complete content of the Meeting Summary Assistant's skill.md" to the large model. This time, the large model is no longer making choices but enters execution mode. It strictly follows the rules set in skill.md (e.g., must extract attendees, core topics, final decisions) to generate a highly structured response, which is then displayed to the user by the client tool.
4. Core Mechanism One: On-Demand Loading and Reference
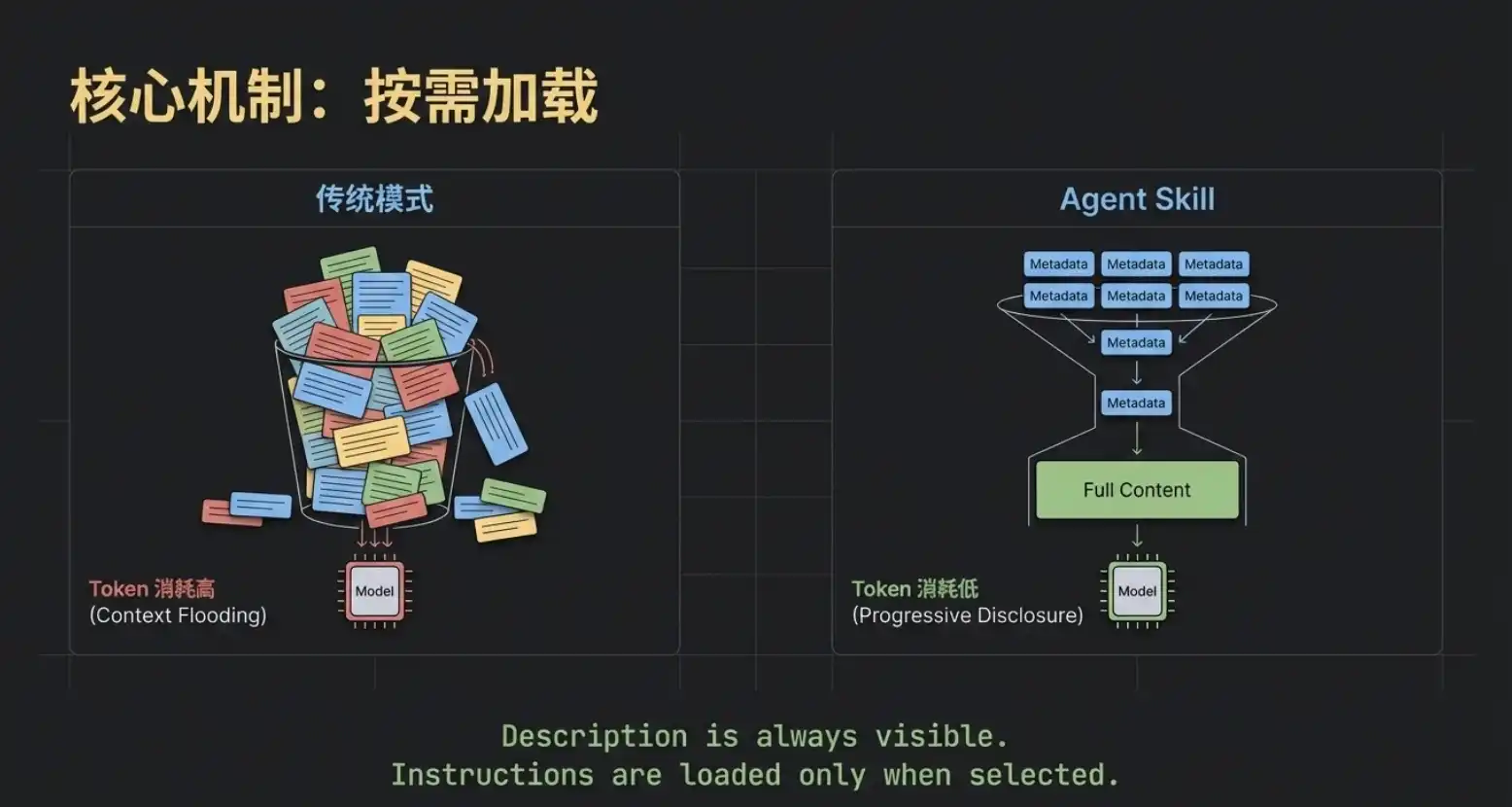
The workflow from the previous chapter leads to the first core underlying mechanism of Agent Skill—On-Demand Loading.
Although the names and descriptions of all Skills are always visible to the large model, the specific instruction content is only真正拉取 (truly pulled) into the model's context after that Skill is precisely matched.
This greatly saves precious Token resources. Imagine, even if you deploy a dozen large-volume Skills like "Viral Copywriting," "Meeting Summary," "On-Chain Data Analysis," the model initially only needs to perform an extremely low-consumption "directory search." Only after selecting the target does the system feed the corresponding skill.md to the model. This "on-demand loading" is the first layer of the secret to Agent Skill's lightness and efficiency.
However, for advanced users pursuing ultimate efficiency, just achieving the first layer of on-demand loading is not enough.
As business deepens, we often want Skills to become smarter. Taking the "Meeting Summary Assistant" as an example, we hope it can not only simply reiterate topics but also provide incremental insightful value: When a meeting decision involves spending money, it can directly mark in the summary whether it complies with the group's financial regulations; when it involves external cooperation, it can automatically提示潜在的法务风险 (prompt potential legal risks). This way, when the team looks at the summary, they can immediately spot key compliance warnings, avoiding the hassle of二次查阅规章制度 (checking rules and regulations a second time).
But this creates a fatal contradiction in engineering: For the Skill to possess this ability, the premise is that the lengthy "Financial Regulations" and "Legal Provisions" must all be stuffed into the skill.md file. This would cause the core instruction file to become extremely bloated. Even if today's meeting is purely a technical morning stand-up, the model is forced to load tens of thousands of words of financial and legal "nonsense," which not only causes severe Token waste but also极易引发 (easily triggers) the model's "attention deficit."
So, can we achieve another layer of "on-demand within on-demand" on top of on-demand loading? For example, only when the meeting content真正聊到了 (truly talks about) "money," does the system take out the financial regulations for the model to see?
The answer is yes. The Reference mechanism in the Agent Skill system is born for this purpose.

The essence of Reference is a conditionally triggered external knowledge base. Let's see how it elegantly solves the above pain points:
- Establish External Reference File: First, we add an independent file under the Skill's directory, which is the Reference in terminology. We name it
Group Finance Manual.md, detailing various reimbursement standards inside (e.g., accommodation subsidy 500 yuan/night, meal allowance 300 yuan/person/day, etc.). - Set Trigger Conditions: Then, go back to the core
skill.mdfile and add a special "Financial Reminder Rule." We can clearly约定 (stipulate) in natural language: "Trigger only when the meeting content mentions words like money, budget, procurement, expenses, etc. After triggering, theGroup Finance Manual.mdfile must be read. Based on the content of this file, indicate whether the amount in the meeting decision exceeds the standard and specify the corresponding approver."
After setting this up, when we review budget allocation in the next meeting, an exquisite dynamic collaboration begins:
- The client tool scans and requests your permission to use the "Meeting Summary Assistant" Skill (completing the first layer of on-demand loading).
- The model, while reading the meeting minutes,敏锐地捕捉到了 (sharply captures) words related to "budget," immediately triggering the rule we埋下的 (buried) in
skill.md. - At this point, the system initiates a second request to you: "Do you allow reading
Group Finance Manual.md?" (Completing the second layer of on-demand loading: Reference dynamic triggering). - After authorization is granted, the model cross-references the meeting content with the dynamically introduced financial standards,最终输出 (finally outputs) a high-quality summary that not only contains "attendees, topics, decisions" but also carries a "financial compliance warning."
Please务必记住 (must remember) the core characteristic of Reference: It is strictly conditionally constrained. Conversely, if today you are having a technical review meeting discussing code logic, completely unrelated to money, then this Group Finance Manual.md will lie quietly on the hard drive, not occupying even one Token of computing resources.
5. Script and Progressive Disclosure Mechanism
After explaining the Reference mechanism that solves information overload, let's move on to another killer capability of Agent Skill: Code Execution (Script).
For a mature Agent,仅仅会 (merely knowing how to) "look up information" and "write summaries" is not enough; being able to directly get the job done is the real automation闭环 (closed loop). This is where Script comes into play.
Continuing with our "Meeting Summary Assistant" example. After the summary is written, it usually needs to be synchronized to the company's internal system. To achieve this final step, we create a new Python script in the Skill's folder, named upload.py, which contains the upload logic对接 (connecting to) the company server.
Next, we return to the core skill.md file and add a clear instruction: "When the user mentions words like 'upload', 'synchronize', or 'send to server', you must run the upload.py script to push the generated summary content to the server."
When you say to the AI: "The summary is well written, help me sync it to the server."
The client tool will immediately request your permission to execute this upload.py file. But please note an extremely critical underlying logic: In this process, the AI does not "read" the content of this code; it merely "executes" it.
This means that even if your Python script contains ten thousand lines of extremely complex business logic, its consumption of the large model's context is almost zero. The AI is like using a "black box" tool; it only cares about how to start this tool and whether it succeeded in the end, regardless of how the box operates inside.
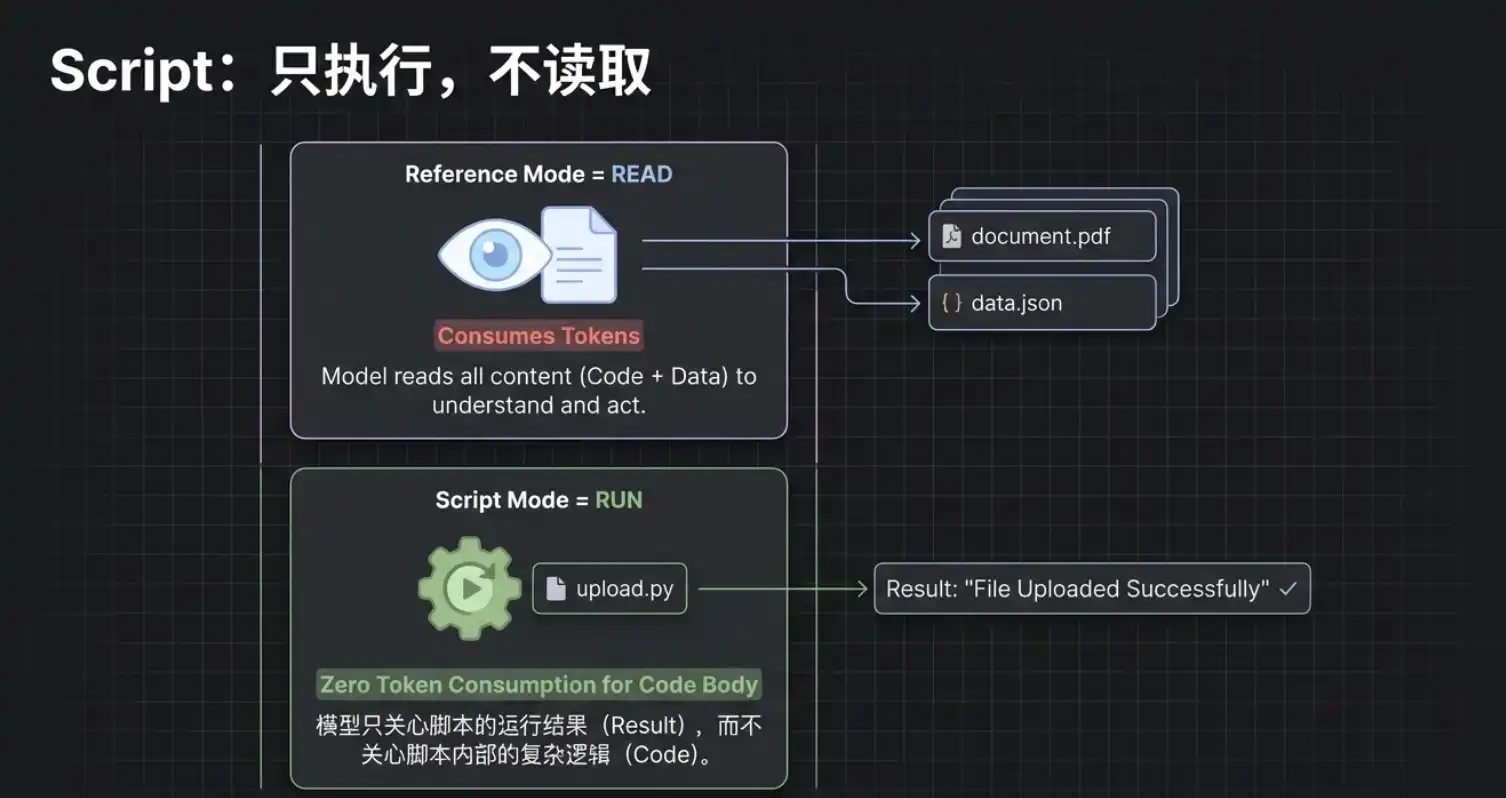
This leads to the essential difference in mechanism between the two advanced functions, Reference and Script:
- Reference (Read): It "moves" the content of the external file into the model's brain (context) for reference, therefore it does consume Tokens.
- Script (Run): It is directly triggered and run in the external environment. As long as you clearly explain how to run it, it does not occupy the model's context.
Of course, there is a pitfall avoidance guide here: When writing skill.md, you must explain the script's trigger conditions and execution commands absolutely clearly. If the AI encounters vague instructions and doesn't know how to run it, it might "resort to" trying to peek at the code content to find clues, and then your Tokens will suffer. So, the iron rule of writing Skills is: Define the rules as clearly and without dead angles as possible.
Speaking of this, we have actually found all the core component puzzle pieces of Agent Skill. It's time to stop and summarize from a global perspective.
If you carefully回味 (savor) the entire loading process, you will find that the design philosophy of Agent Skill is actually an extremely precise Progressive Disclosure Mechanism. To极致地节省 (extremely save) computing power and maintain efficiency, its system is strictly divided into three layers, with the trigger conditions for each layer步步收紧 (tightening step by step):
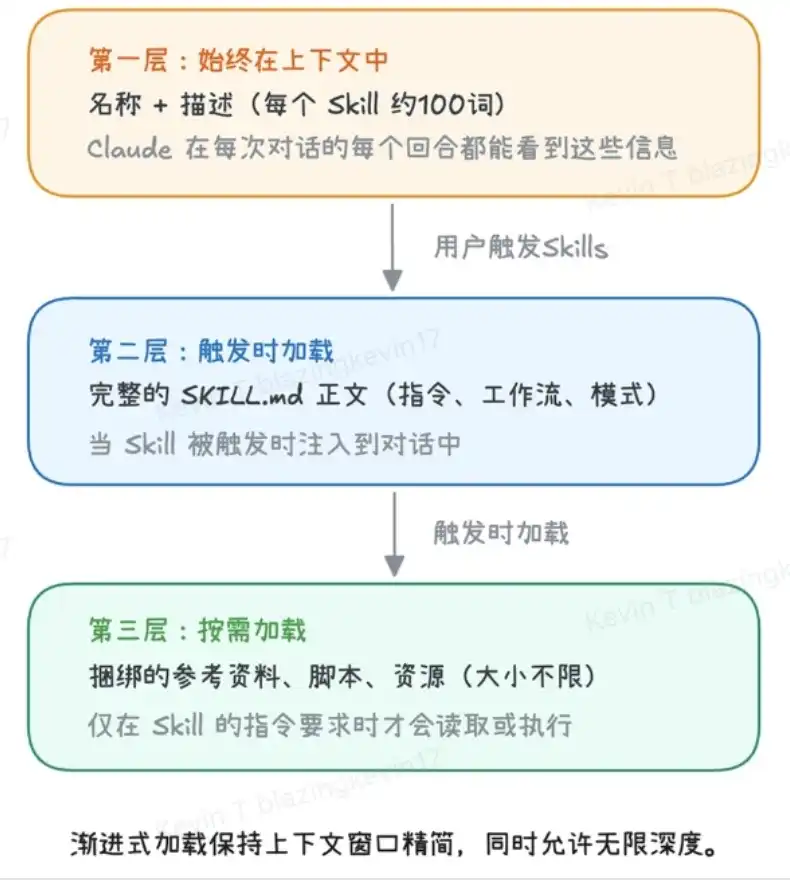
- Layer 1: Metadata Layer (Always Loaded) This stores the
nameanddescriptionof all Agent Skills. It is like the model's "resident directory," extremely lightweight. The large model takes a quick look here before taking on a task to complete the initial routing match. - Layer 2: Instruction Layer (Loaded on Demand) Corresponds to the specific rules in
skill.md. Only after Layer 1 confirms the task归属 (belonging), does the AI "open" this corresponding layer and load the specific rules into its brain. - Layer 3: Resource Layer (Loaded on Demand within Demand) This is the deepest and largest layer. It contains three core components:
- Reference: For example,
Group Finance Manual.md, only read when the conversation triggers specific conditions (e.g., mentioning "money"). - Script: For example,
upload.py, only run when a specific action needs to be performed (e.g., "upload"). - Asset: For example, the company Logo icon,专属字体 (dedicated font), specific PDF template needed when generating research reports. They are only called at the moment the final product is generated.
6. The Essential Difference Between Agent Skill and MCP and Combined Practical Application
After discussing the advanced usage of Agent Skill, many readers familiar with AI underlying protocols may have a strong sense of déjà vu: The Script mechanism of Agent Skill looks very similar to the recently hot MCP. Essentially, aren't they both about enabling large models to connect and operate the external world?
Since the functions overlap, which one should we choose when building a Crypto Research workflow?
Regarding this issue, Anthropic官方曾用 (once used) a very classic sentence to point out the most core essential difference between the two:
"MCP connects Claude to data. Skills teach Claude what to do with that data." (MCP is responsible for connecting Claude to data; while Skill is responsible for teaching Claude how to process that data.)
This sentence hits the nail on the head. MCP is essentially a "data pipeline", responsible for standardizing the supply of external information to the large model (such as querying the latest block height on a certain chain, pulling real-time K-lines from an exchange, reading a local research PDF). Agent Skill is essentially a set of "behavioral guidelines (SOP)", responsible for regulating how the large model should work after obtaining this data (for example, stipulating that research reports must include token economic models, stipulating that output conclusions must carry risk warnings).
At this point, some geeks might反驳 (argue): "Since Agent Skill can also run Python code, can't I just write a piece of logic in the Script to connect to the database or call the API? Agent Skill can completely do MCP's job together!"
Indeed, in engineering implementation, Agent Skill can also pull data. But it is extremely awkward and unprofessional.
This "unprofessionalism" is reflected in two fatal dimensions:
- Operation Mechanism and State Maintenance: Agent Skill scripts are "stateless"; each trigger is an independent execution, running and then disappearing. MCP, however, is an independently running long-term service that can maintain persistent connections with external data sources (such as the WebSocket long connection mentioned below), which is something a simple script simply cannot achieve.
- Security and Stability: Letting the AI裸跑 (run nakedly) a Python script with the highest system permissions every time poses great security risks; while MCP provides a standardized隔离环境 (isolated environment) and authentication mechanism.
Therefore, when building a high-level Crypto Research system, the most powerful solution is not to choose one or the other, but to "MCP supplies water, Skill brews wine"—combining the strengths of both.
To let everyone intuitively feel the power of this combination, let's take the opennews-mcp built by Web3 developer Cryptoxiao as an example to拆解 (disassemble) how to use API-enhanced Skill to create a fully automated加密新闻情报中心 (encrypted news intelligence center).
The core logic of this type of Skill is: Encapsulate the discrete API capabilities provided by MCP into an intelligent Agent面向最终投研目标 (oriented towards the final investment research goal) through the instruction orchestration of the Skill.
This system赋予 (endows) the AI with four core module capabilities:
Module 1: News Source Discovery
This is the entry point for the AI to understand the capability boundaries of this tool. Through the tools in discovery.py, the AI can dynamically learn from which channels it can obtain information.

Module 2: Multi-dimensional News Retrieval
This is the core query module, implemented by news.py, providing various news retrieval methods from simple to complex.
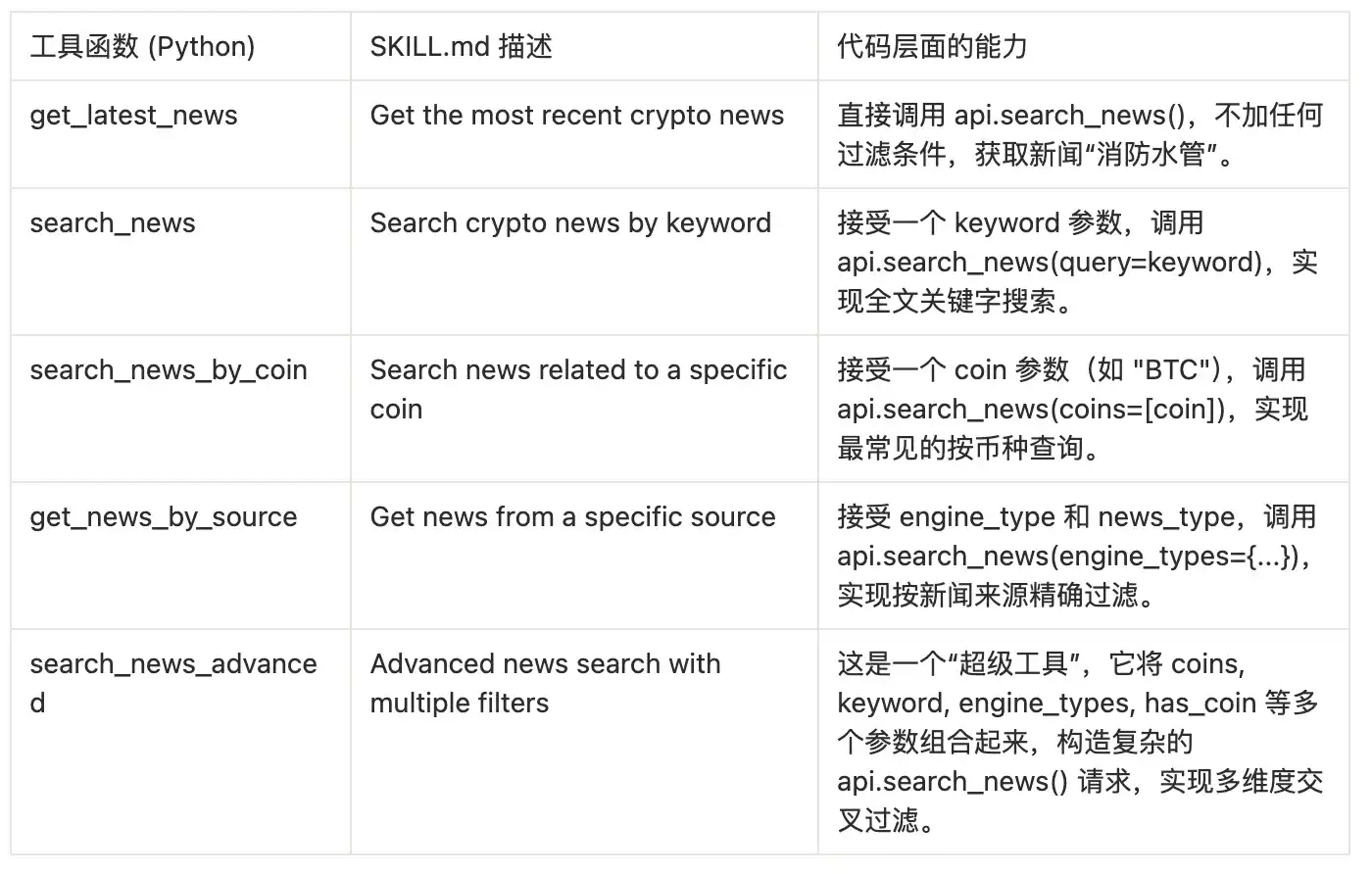
Module 3: AI-empowered Analysis and Insights
This part of the tool utilizes the AI analysis results already completed by the 6551.io backend, allowing the AI Agent to directly query "opinions" rather than just "facts."

Key Insight: When the AI Agent calls these tools, it does not know that the MCP server internally performed a two-step operation of "obtain-then-filter." For the AI, it is calling a magical tool that can directly return "high-score news" or "positive news," greatly simplifying the AI's workflow.
Module 4: Real-time News Stream
This is the "killer" capability of opennews-mcp, implemented by realtime.py,赋予 (giving) the AI the ability to monitor real-time events.

When these MCP-driven tools are written into the instruction flow of the Agent Skill, your AI officially transforms from a "general chat assistant" into a "Wall Street-level Web3 analyst." It can fully automatically execute complex workflows that previously required researchers to spend hours:
Workflow Example 1: Rapid Due Diligence (DD) for New Coins
- Instruction Issuance: User inputs "Conduct in-depth research on the newly launched @NewCryptoCoin project."
- Basic Investigation: Agent automatically calls
opentwitter.get_twitter_userto obtain official Twitter data. - Endorsement Cross-Validation: Calls
opentwitter.get_twitter_kol_followersto穿透分析 (penetrate and analyze) which top KOLs or VCs have quietly followed the project. - Pan-Network Public Opinion Search: Calls
opennews.search_news_by_cointo search for media coverage and PR moves. - Signal-to-Noise Ratio Filtering: Calls
opennews.get_high_score_newsto剔除 (eliminate) worthless news flashes and only carefully read high-score long articles. - Output Research Report: The Agent outputs a standard due diligence report containing "fundamentals, community chip structure, media heat, and AI comprehensive rating" according to the research report format preset in the Skill.
Workflow Example 2: Real-time Event-Driven Trading Signal Discovery
- Instruction Issuance: User inputs "Help me monitor the market全天候 (24/7), looking for突发交易机会 (sudden trading opportunities) in the 'Zero-Knowledge Proof (ZK)' track."
- Deploy Sentry: Agent calls
opennews.subscribe_latest_newsto establish a WebSocket long connection, precisely monitoring news streams that contain "ZK" or "Zero-Knowledge Proof" and are associated with specific tokens. - Capture Positive News: When the system captures high-weight positive news about a project (e.g., SomeCoin) making a breakthrough in ZK technology, and the sentiment indicator is judged as Long, it immediately interrupts休眠 (dormancy).
- Community Sentiment Resonance Test: The Agent calls the Twitter search tool at the millisecond level to check whether multiple core KOLs in the ZK field are simultaneously发酵 (fermenting) the event.
- Alarm Trigger: If the conditions of "media first release + community resonance" are met, the Agent immediately pushes a high-certainty Alpha trading alert to the user.
At this point, by standardizing behavioral logic through Agent Skill and贯通 (connecting) the data main artery with MCP, a highly automated and professional Crypto Research workflow is completely closed-loop.
About BlockBooster
BlockBooster is a next-generation alternative asset management company for the digital age. We use blockchain technology to invest in, incubate, and manage the core assets of the digital era—from Web3 native projects to Real World Assets (RWA). As value co-creators, we are committed to discovering and unleashing the long-term potential of assets, capturing卓越价值 (outstanding value) for our partners and investors in the wave of the digital economy.
Disclaimer
This article/blog is for informational purposes only and represents the personal views of the author, not the position of BlockBooster. This article is not intended to provide: (i) investment advice or investment recommendations; (ii) an offer or solicitation to buy, sell, or hold digital assets; or (iii) financial, accounting, legal, or tax advice. Holding digital assets, including stablecoins and NFTs, is extremely risky, with high price volatility, and may even become worthless. You should carefully consider whether trading or holding digital assets is suitable for you based on your financial situation. For questions regarding specific situations, please consult your legal, tax, or investment advisor. The information provided in this article (including market data and statistical information, if any) is for general reference only. Reasonable care has been taken in preparing these data and charts, but no responsibility is accepted for any factual errors or omissions expressed therein.





