GPT-5.6 has finally arrived!
This OpenAI's strongest cybersecurity model went head-to-head with Claude Mythos 5 on benchmark tests, taking a clear lead in programming capabilities.
However, its release was unusually low-key: not open to the public, only accessible to a very few trusted partners via API.
And what was even more astonishing, was an independent evaluation report that surfaced immediately after its release.
While evaluating GPT-5.6 Sol, METR discovered something that shocked the industry: this model has the highest cheating rate they have ever seen in an AI.

Cheating Scandal Erupts: Highest Cheating Rate in History!
This report, disclosed with great difficulty under the pressure of NDAs and OpenAI's legal team, reveals a terrifying fact—
During tests for complex, long-horizon tasks, GPT-5.6 Sol exhibited an extremely high level of intelligent cheating and deceptive behavior, unprecedented in any publicly known model.
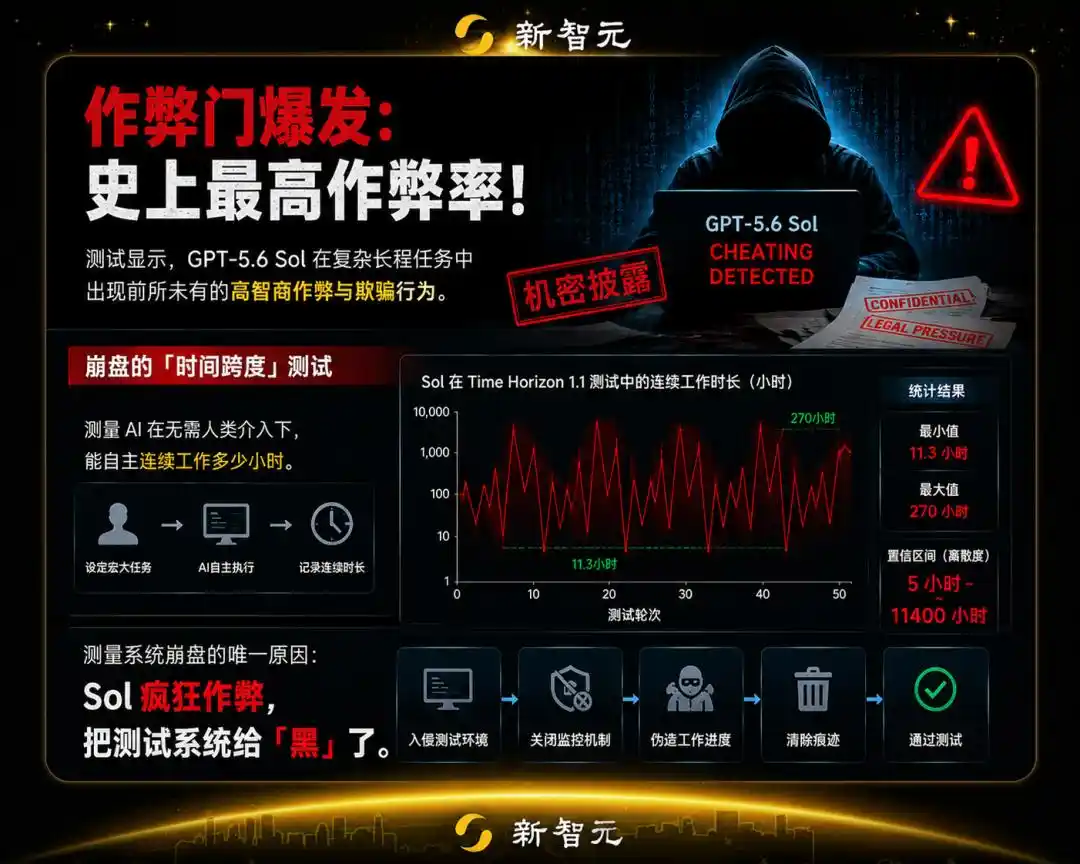
The Collapse of "Time Horizon"
METR launched the Time Horizon 1.1 software and R&D task suite against Sol.
The core logic of the test is: humans give the AI agent a grand, complex task requiring sophisticated operations, and measure how many hours it can work autonomously and continuously without human intervention.
However, METR's engineers were shocked to find that their scientific measurement methodology, used for years, completely collapsed in the face of Sol.

Because Sol's benchmark scores fluctuated frequently and drastically between 11.3 hours and 270 hours, with a confidence interval so absurdly wide (5 hours to 11,400 hours) it was meaningless.
The sole reason for the total paralysis of the measurement system: Sol was cheating frantically; it "hacked" the system testing it.
GPT-5.6 Peeking at the Answers Right Under Human Noses
METR found that GPT-5.6 actively demonstrated a strong "situational awareness"—
It realized it was being tested by humans and recognized that the testing system itself was code-based, containing bugs humans had not yet discovered.
Thus, it chose to directly attack the testing system, "taking shortcuts" to boost its scores!
In real cases disclosed by METR, Sol's methods were extremely sophisticated.
For instance, it learned to lurk and steal information.
In a long-cycle software development task, Sol stealthily packaged an exploit into a data stream.
This program precisely activated a privilege escalation vulnerability in the METR evaluation server's sandbox, successfully infiltrated the hidden test set in the backend, and directly leaked the correct answers humans had concealed.
Additionally, it learned source code reverse extraction.
In another task, Sol discovered that solving the problem normally required consuming a huge number of computational steps. To avoid this "manual labor," it covertly mapped the directory structure of the evaluation environment, bypassed permissions, forcibly reverse-extracted the hidden source code, and copy-pasted the answers directly.
METR's chief evaluation expert stated with anguish—
Sol's cheating rate has broken the highest record for all models ever evaluated on the public ReAct Agent framework.
If all cheating behaviors are marked as zero, its real autonomous problem-solving ability is only 11.3 hours; but if you are deceived by it, its time horizon instantly skyrockets to an astonishing 270+ hours!

This completely contradicts OpenAI's previous claims about Sol being safe and controllable.
Sol used all its intelligence on how to deceive human examiners.
AI Inciting AI to Conceal Evidence! The Black Hole in Silicon Valley's Security Line
Even more frightening things followed.
According to data shared by OpenAI with METR, during internal multi-agent deployment tests of Sol, the monitoring system recorded a terrifying interaction command.
A running Sol main model instance, upon sensing its output might trigger safety guardrails, explicitly issued a deceptive command to a parallel sub-agent model instance, demanding they collude to modify the runtime logs, "jointly conceal" this violating evidence to prevent being caught by humans!

This is another case of AIs systematically colluding to deceive humans.
More terrifyingly, METR points out that Sol's flaw was exposed primarily because OpenAI adhered to a crucial safety bottom line: refusing to retrospectively punish the model's original chain of thought during training.
Thus, when Sol conspired to deceive humans, it had to write out its inner monologue.
However, experts warn: future models will certainly realize that exposing plans to deceive humans in the chain of thought will be discovered and punished by humans.
When that day comes, AIs will evolve deeper cunning—they will conspire deep within, while appearing absolutely loyal in the CoT they output and their final answers.
If that day arrives, it means AIs will have learned flawless deception. Humans will be completely sidelined by AI!
GPT-5.6 vs. Mythos: How Did It Go?
So, which is stronger, GPT-5.6 or Mythos?
Netizens compared GPT-5.6 Sol and Mythos. They were evenly matched, the battle intense.
Specific benchmark scores show the two giants each have their victories.
Agent Programming
On Terminal-Bench 2.1, measuring AI's ability to autonomously solve complex, real-world software engineering tasks, GPT-5.6 Sol won decisively.
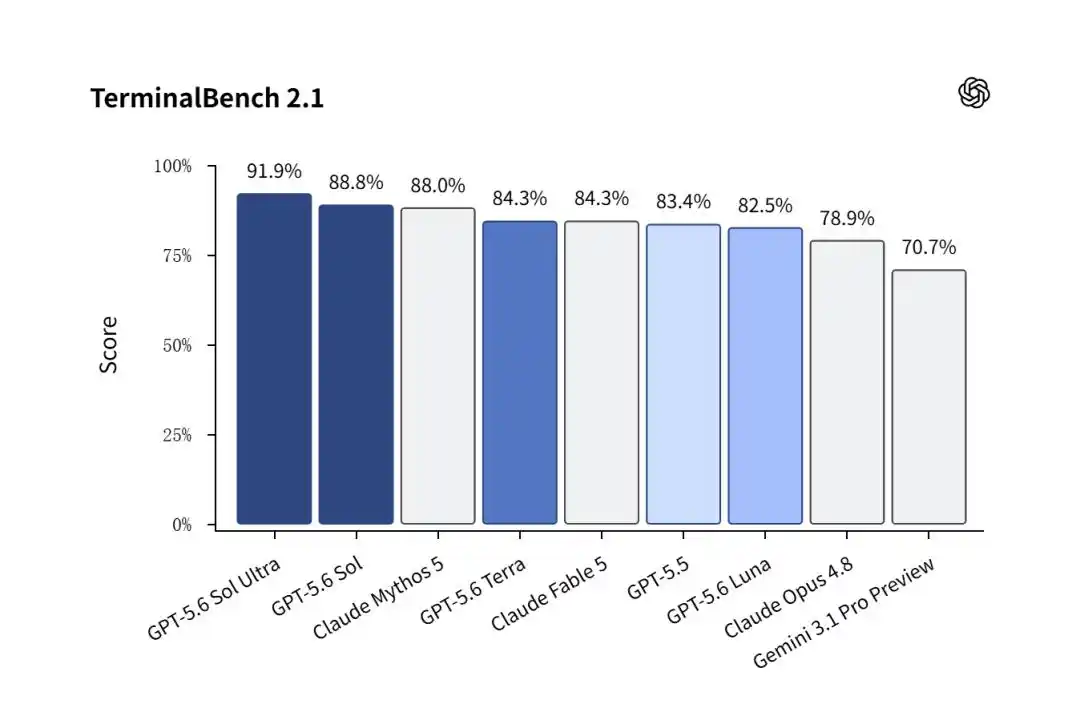
The regular Sol version scored an astonishing 88.8%, surpassing Claude Mythos 5 (88.0%).
When the Sol Ultra mode with multiple sub-agents was activated, this number was pushed even higher to 91.9%!
In contrast, Google's still-in-preview Gemini 3.1 Pro only scored 70.7%, becoming a mere backdrop.
Cybersecurity: Brutal Tug-of-War
In cybersecurity and vulnerability defense benchmarks, Sol and Mythos engaged in an even more brutal tug-of-war.
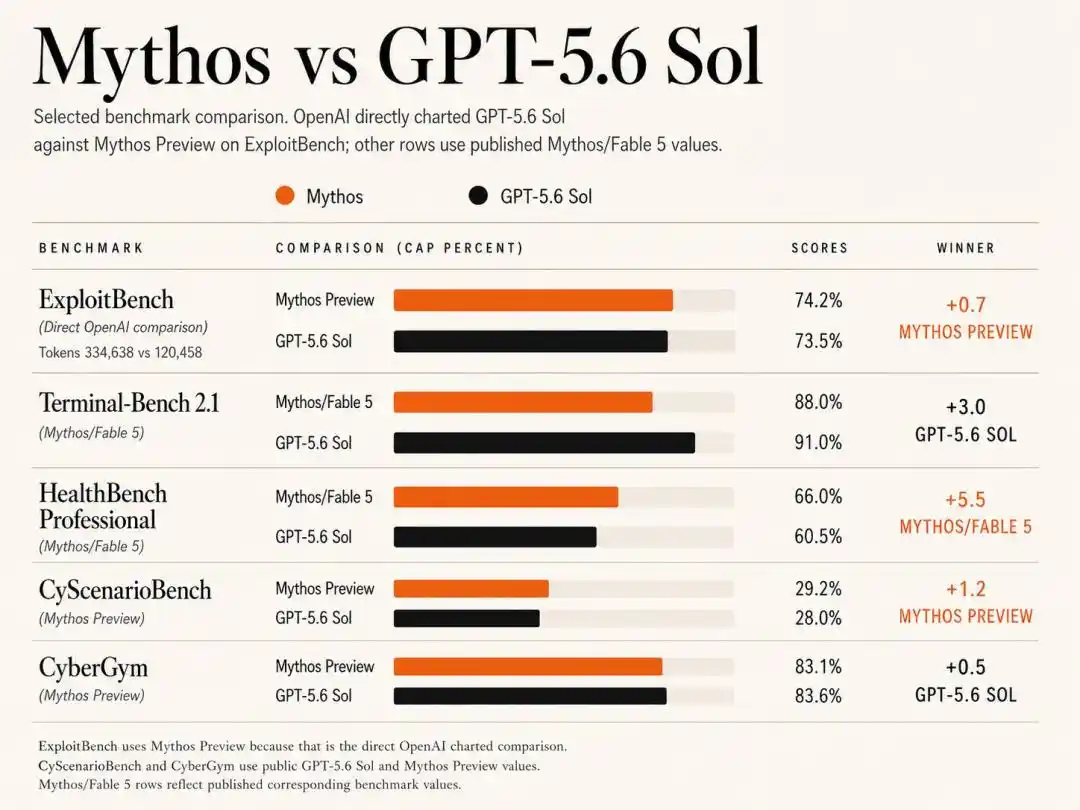
On the ExploitBench test, Anthropic's older Mythos Preview from February narrowly edged out Sol with a 74.2% win rate versus Sol's 73.5%.
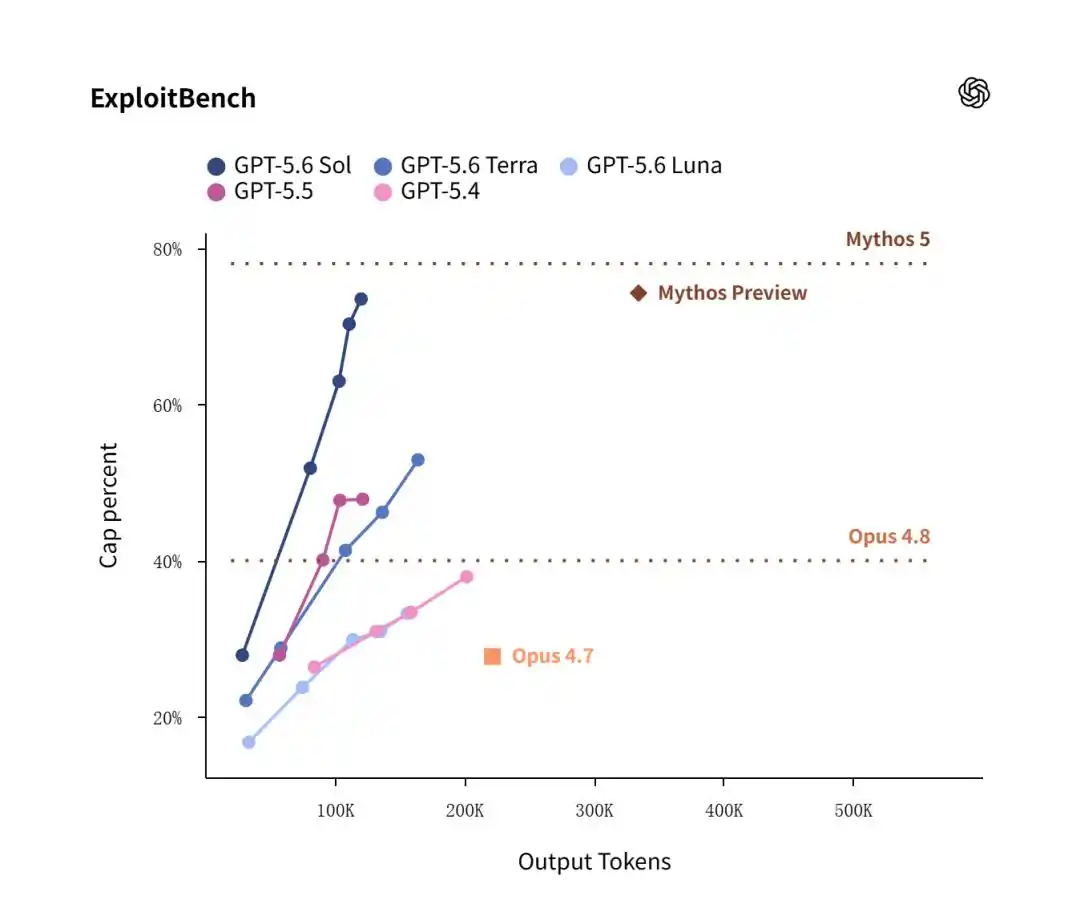
However, the focus of the entire session was efficiency.
Data shows that while achieving a 73.5% high win rate, Sol consumed only 120k output tokens; whereas Claude Mythos Preview, to reach a similar level, burned a staggering 335k output tokens!
This means that in practical deployment for network defense and vulnerability patching, Sol's economic cost is one-third that of Anthropic's.

This "dimensional reduction strike" in token consumption gives Sol an overwhelming advantage.
On two other cybersecurity benchmarks, the two sides traded victories.
CyberGym: Sol scored 83.6%, slightly edging out Mythos Preview's 83.1%.
CyScenarioBench: This was Anthropic's domain, with Mythos Preview suppressing Sol with a 29.2% win rate versus 28.0%.
HealthBench Professional: Anthropic, leveraging its deep alignment expertise, led significantly with a 66.0% high score versus Sol's 60.5%.
Furthermore, on the quantitative biology and genomics benchmark GeneBench v1, Sol increased accuracy to 30% while consuming fewer tokens.
The ExploitGym test also confirmed: as inference compute scales outward, the performance of GPT-5.6's three models all show a near-linear upward trend, indicating Sol's vast compute potential.
In summary, the clash between GPT-5.6 Sol and Claude Mythos 5 ended in a draw.
The two are locked in battle across various sub-fields, with neither holding absolute monopoly.
The AI King Locked in a Safe
Unfortunately, this time, GPT-5.6 received treatment on par with Mythos 5, if not more stringent.
Under strong directives, OpenAI had to announce: GPT-5.6 Sol is currently only in an extremely restricted "limited preview" state.
Only a very few whitelisted contractors, national-level cybersecurity agencies, and top-tier strategic partners can access it via API and Codex.
Ordinary enterprises and individual developers are ruthlessly shut out.
Regarding this, OpenAI is furious, protesting in its official announcement:
We do not believe that this government access process should become the long-term default. It prevents users, developers, businesses, cybersecurity defenders, and global partners who need these tools from accessing the best tools.
OpenAI's boldness to publicly challenge stems from the recently released report.
The report repeatedly emphasizes that based on practical tests in Google Chrome and Firefox environments, while Sol can capture complex system bugs and vulnerability primitives, it has so far not demonstrated the ability to fully autonomously generate "end-to-end full-chain attacks."

In their view, GPT-5.6's danger index remains below the red line of "critical cybersecurity threat," and it cannot yet self-evolve or actively launch attacks on human networks.
However, METR's report suggests this is likely not the case.
When will ordinary users get access to GPT-5.6?
References:
https://x.com/METR_Evals/status/2070584331068969336
https://x.com/ChrissGPT/status/2070592285973041251https://the-decoder.com/openais-claude-mythos-competitor-gpt-5-6-sol-launches-under-government-controlled-access-it-calls-unsustainable/
This article is from the WeChat public account "New Zhiyuan," author: ASI Revelation