Author: Garry's List
Compiled by: Deep Tide TechFlow
Deep Tide Introduction: Anthropic has released the most comprehensive study to date on the real-world usage of AI Agents. The core data shows: software engineering accounts for nearly 50% of AI Agent tool calls, while 16 vertical domains including healthcare, legal, and education combined account for less than half of the remainder, with each domain's share below 5%.
This is not a sign of market saturation, but a map of 300 vertical AI unicorns—more valuable is a counterintuitive finding cited in the article: models can already work independently for nearly 5 hours, but users only let them work for 42 minutes. This "trust deficit" itself is the next product opportunity.
Full Text Below:
Software engineering accounts for nearly 50% of all AI Agent tool calls. Sixteen domains including healthcare, legal, and finance are almost untouched, each below 5%. This means there are 300 vertical AI unicorns waiting to be built.
If I were to start a business today, I would stare at the red area in the bar chart above until I saw my future.
Box founder Aaron Levie said:
This chart is a great reminder of how much opportunity there is in the AI Agent space right now.
There will certainly be a lot of horizontal Agent opportunities, but there is also a lot of workflow that requires deep domain expertise to truly help users automate the unique processes in their vertical.
The template is: build Agent software that integrates proprietary data to effectively bridge users and Agent collaboration in handling workflows, while possessing deep domain-specific contextual engineering capabilities and the ability to drive change management on the client side.
Many domains still have huge gaps.
Software engineering occupies half of all AI Agent activity. The other half is scattered across 16 vertical domains, none exceeding 9%. Healthcare accounts for 1%, legal for 0.9%, and education for 1.8%. These are not saturated markets; they are markets that barely exist.
Anthropic just released the most comprehensive study to date on real AI Agent usage. The core finding: software engineering accounts for 49.7% of Agent tool calls on its API. The core conclusion buried deeper: everything else is a blue ocean.
Deployment Lag
One data point should excite entrepreneurs: the model's capabilities far exceed the boundaries of what users are willing to trust it with.
METR's capability assessment shows that Claude can solve tasks that would take a human nearly five hours to complete. But in actual use, the 99.9th percentile session duration is only about 42 minutes. This gap—between what AI can do and what we allow it to do—is a huge opportunity.
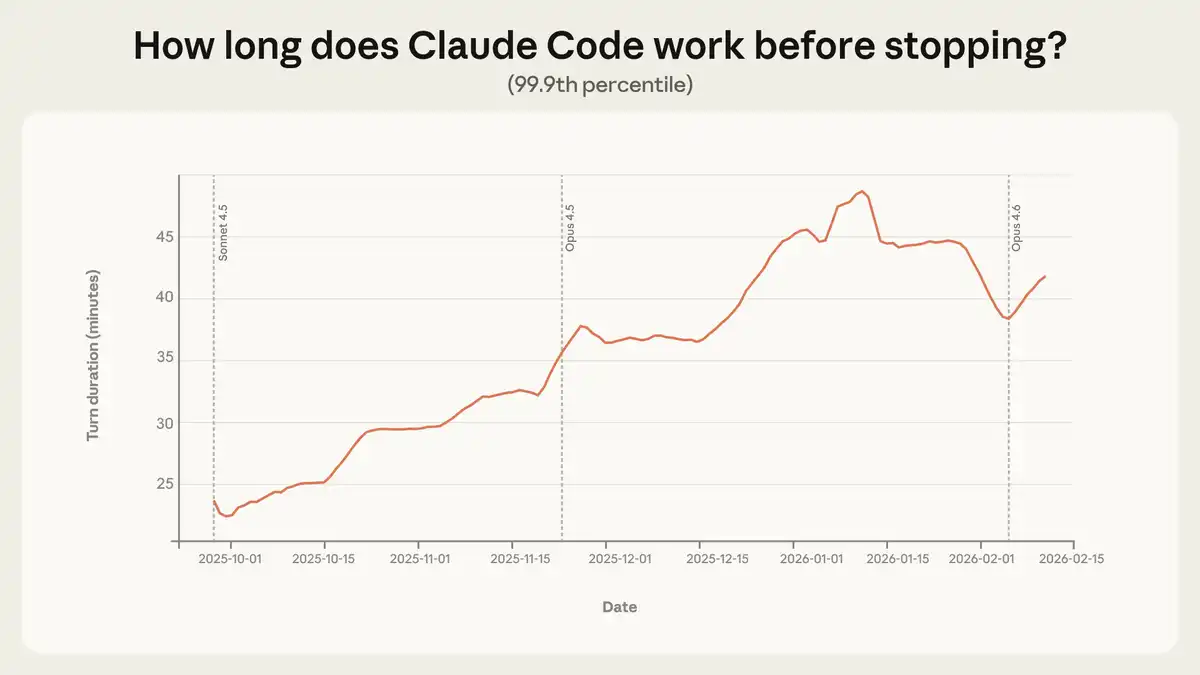
Figure: The maximum duration Claude Code was trained on nearly doubled in three months. This not only improved capabilities but also enhanced trust.
Source:x.com
From October 2025 to January 2026, the 99.9th percentile single-session duration almost doubled, growing from less than 25 minutes to over 45 minutes. Growth was steady across model versions. This isn't just the model getting stronger; it's users learning through repeated use, gradually extending their trust in the Agent.
"From August to December, Claude Code's success rate on internal users' most challenging tasks doubled, while the number of human interventions per session decreased from 5.4 to 3.3."
The capability is already there; deployment hasn't caught up. This isn't a problem; it's a product opportunity.
How Trust Evolves
20% of new users automatically approve Claude Code's actions. By 750 sessions, over 40% of sessions run in full auto-approval mode. But there's a counterintuitive finding: experienced users intervene more, not less. New users intervene in 5% of turns, while experienced users intervene in 9%.
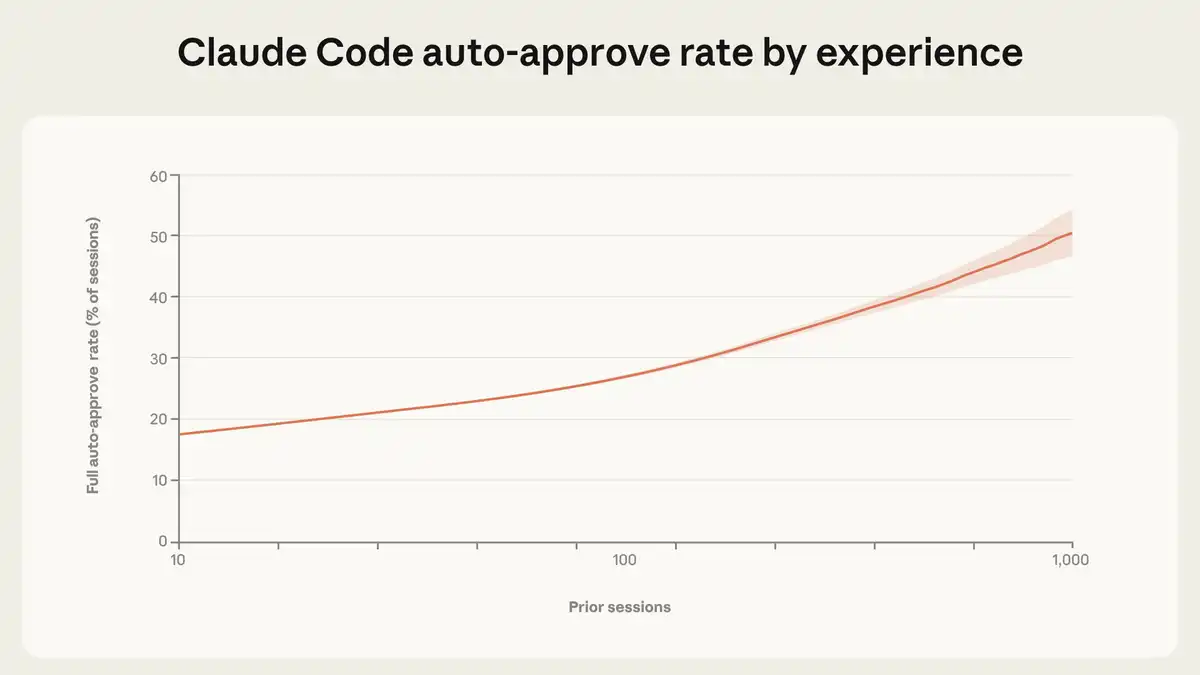
Figure: Trust is a skill that accumulates. New users automatically approve 20% of sessions. By 750 sessions, this exceeds 40%.
Image: Anthropic
Source: x.com
This isn't a contradiction but a shift in supervision strategy. Beginners approve step-by-step before actions occur; experienced users authorize first and intervene only if problems arise—they've moved from pre-approval to active monitoring.
Here's a safety-relevant finding: on complex tasks, Claude Code proactively requests clarification more than twice as often as humans proactively intervene. The Agent pauses to confirm rather than charging ahead. This is a feature, not a bug.
"The core insight of this study is: the autonomy Agents exercise in practice is co-constructed by the model, the user, and the product. Claude pauses to ask questions when uncertain, thereby limiting its own independence. Users build trust through collaboration with the model and adjust their supervision strategies accordingly."
Levie's Vertical AI Playbook
Aaron Levie points to the immense wealth and value waiting to be unlocked: build Agent software that integrates proprietary data, make it truly solve real people and problems, pack it with context to maximize intelligent output, and—this is the part most entrepreneurs miss—drive change management on the client side.
This last point is why vertical AI is so hard to replicate. Anyone can build an API wrapper, but few can truly navigate the workflows, regulatory constraints, and organizational resistance unique to medical billing, legal discovery, or building permit approvals.
SaaS grew tenfold every decade over the past few decades. Over 40% of venture capital in the past 20 years flowed to SaaS companies. This industry spawned over 170 SaaS unicorns. The logic is simple: each of these unicorns has a vertical AI version waiting to emerge. And the AI version could be ten times larger because it replaces not just software but also operators.
The Nature of Co-Construction
Anthropic's core finding deserves serious attention from anyone involved in AI policy making. Autonomy is not an inherent property of the model but is co-constructed by the model, the user, and the product. Pre-deployment evaluations cannot capture this; you must measure it in real use.
Anthropic stated officially:
Software engineering accounts for about 50% of Agent tool calls on our API, but we are also seeing emergence in other industries. As the boundaries of risk and autonomy continue to expand, post-deployment monitoring becomes critical. We encourage other model developers to expand on this research.
The safety numbers are reassuring: 73% of tool calls have a human in the loop, and only 0.8% of operations are irreversible. The highest-risk deployment scenarios—such as API key exposure or autonomous crypto trading—are mostly security assessments, not real production environments.
"Regulatory requirements that mandate specific interaction patterns—for example, requiring human approval for every action—will only create friction without necessarily delivering safety benefits."
Policies mandating "approve every action" kill productivity gains without increasing safety. A better goal is to ensure humans can monitor and intervene, not to mandate specific approval workflows.
Where the Unicorns Are Hidden
The map is drawn. Software engineering is already being done. Healthcare, legal, finance, education, customer service, logistics—16 vertical domains, each with single-digit market share—are waiting for someone to truly embed domain expertise into Agents.
300 SaaS unicorns were born before; the next 300 vertical AI unicorns are about to emerge. The founders who pick a vertical, embed domain expertise into Agents, and figure out how to drive change management will own the enterprise software market for the next decade.
The model can work for five hours; users only let it work for 42 minutes. That's the signal: we are still in the very early stages, there is so much left to build, and in countless places that haven't seen even a minute of intelligence at work.