In a garment processing factory in India, workers are sorting fabrics as usual, but this time, they wear cameras on their heads to record first-person videos of their work.
These videos, after processing, will become data assets sold to embodied AI companies in need of large amounts of data to train robots.
Similar businesses have been rapidly forming a new industrial chain since this year, and the rise of this chain stems from the biggest bottleneck the embodied intelligence industry currently faces: data.
"The demand has clearly picked up this year," an industry insider involved in robot data collection told 42 Channel, stating that the European and American robot companies his team serves are massively procuring human work data. Currently, his team has nearly a hundred collectors participating in the production of robot training data, able to stably output thousands of hours of human first-person video data per month.
Collectors need to follow standardized procedures to complete tasks such as organizing clothes, kitchen tidying, and grasping items. During the process, they wear head-mounted cameras, and for some tasks, data gloves are used to record finer hand movements.
"In the past, the industry was talking about models and hardware. Now more and more people are asking: can data be supplied stably?"
It has become clear to everyone that the inability to achieve breakthroughs in model capabilities is largely due to insufficient data scale.
Under the enormous data gap in embodied models, the new business of data collection has also begun to form rapidly.
Why Are Robots Starting to Lack Data?
If we turn back the clock three years, robots were more akin to the traditional automation industry.
Most robots were fixed in factories, with highly structured workflows: welding, handling, spraying, assembly. They didn't need to understand complex environments or learn generalization abilities; they only needed to repeat actions along predetermined trajectories.
Now, however, many companies are aiming for more than just traditional industrial robots. From Tesla and Figure to PI, the industry is attempting to train robots like large language models, endowing them with general capabilities.
Therefore, the path taken by embodied models is increasingly resembling that of large language models (LLMs), except that the path for embodied models is even more challenging, especially in the field of data.
For LLMs, the internet itself is a natural goldmine of data. Decades of accumulated web pages, books, papers, code repositories, etc., constitute vast training corpora. Model companies typically only need to solve the problems of filtering and cleaning data, rarely needing to create data from scratch.
But embodied models are different; they face the physical world, a data desert. Robot motion data doesn't appear out of thin air. Even though there are many human work videos on the internet, for robots, this scale of data is still insufficient, and the overall quality is not high enough.
If LLMs were born in a library, robots are more like being born in a desert.
So, while AI has entered the stages of computing power competition and inference optimization, the embodied intelligence industry remains trapped in the most fundamental question: where does the data come from?
This is also why, even as model architectures become increasingly complex, robots are still far from truly entering homes and complex scenarios.
Because models lack sufficient real-world experience.
Previously, Figure founder Brett Adcock made a very direct point: "If, with a snap of the fingers, the truly needed massive amounts of data could be stuffed into the Helix model, we could immediately solve general-purpose robots."
But the problem is, where does the data come from?
How Is One Hour of Data Produced?
In February of this year, a research finding began to excite the industry.
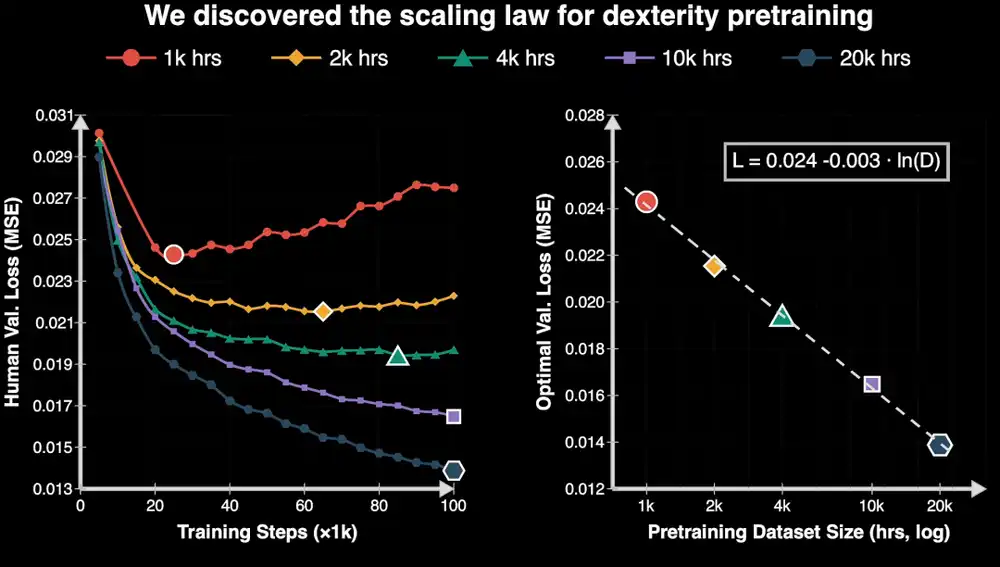
NVIDIA's team released EgoScale. By pre-training a model with over 20,000 hours of human first-person video with action annotations, and then fine-tuning it with a small amount of robot data, the Sharpa Wave 22-degree-of-freedom dexterous hand could be made to complete tasks like unscrewing bottle caps and folding clothes.

More importantly, the study found that as the scale of human data increases, model performance improves steadily, and this improvement is predictable.
This research is very important for the embodied industry because a scalable data pathway means that the growth of robot capabilities has the opportunity to enter a positive cycle of "more data leads to stronger capabilities," just like large models.
For a long time, the embodied industry has had a kind of anxiety: even with more investment, improvements in model capabilities remain highly unpredictable. Because real-world data is too scarce and costly, few dare to invest huge funds in the data field.
But EgoScale, to some extent, has proven one thing: at least for human first-person data (Ego Data), scale can indeed bring stable benefits to dexterous hand manipulation.
At the same time, more and more robot companies are beginning to adopt the path of large amounts of human data plus small amounts of robot body data.
Human first-person videos are responsible for telling the model how humans complete tasks, while robot data is responsible for letting the model learn what its own body should do.
Therefore, the main value of Ego Data is to serve as a more easily scalable prior knowledge, allowing robots to first understand the physical world and then adapt through a small amount of real machine data.
As a result, the new industrial chain around Ego Data has also begun to accelerate noticeably this year.
Humans wear a camera on their head or chest and perform specific tasks, such as organizing clothes, tidying kitchens, or sorting packages. The camera records the first-person video of the human working.
To some extent, humans themselves are the most mature general-purpose robots in the world. When entering a kitchen, people naturally judge what to do first and what to do later; when space is insufficient, they free up another hand; when encountering fragile items, they subconsciously adjust their strength.
Behind these seemingly instinctive actions actually lie a large amount of spatial understanding, task planning, and object interaction logic.
And in the past, robots have almost never systematically obtained this experience.

But Ego Data isn't just about randomly recording videos, and recording videos on a sufficient scale isn't the biggest challenge. The key is how to turn these experiences into a data product that can actually be used by models.
An industry participant who began accelerating the layout of Ego data this year told 42 Channel that real data collection typically starts with a task specification document sent by the client.
This type of document doesn't simply write "collect kitchen tidying data"; it often has clear stipulations:
What is the task type? Must both hands be fully visible in the frame? Should the camera be on the head or chest? Are interruptions allowed? How much environmental variation is required? Are failure samples needed? What is the final delivery format? Does it need to be compatible with the training framework?
For example, for kitchen tidying, the client may require: continuously complete steps such as opening the cabinet door, finding containers, making space, picking up and placing items, and closing the door, with no frame skipping or severe occlusion in between.
To some extent, this is more like producing an industrial product. The entire process on the collection site is far more "factory-like" than imagined.
In some data collection centers, collectors take turns entering prepared kitchens, closets, and shelf areas, repeatedly executing tasks according to a unified SOP.
Some are responsible for organizing clothes, some repeatedly practice grasping items of different sizes, and others specialize in collecting data for kitchen tidying and moving items.
The same action often needs to be repeated by people of different heights, different dominant hands, and different operational habits, in an attempt to exhaust all possible situations that might occur in the physical world. After all, robots ultimately face a complex real world, not a single standard answer.
For example, putting a cup into a cabinet: some people first make space, some people switch hands, some are accustomed to opening the cabinet door first. These subtle differences precisely constitute part of the robot's generalization ability.
Therefore, for many embodied models, what they need to learn is the logic of "how humans usually complete this task."
Compared to real machine data, this type of data is easier to mass-produce. Faced with the enormous demand of the industry, as long as the scale can keep up and labor costs are low, there is a basis for profitability, and it is relatively easy to generate cash flow.
However, if the data does not meet the client's requirements, rework is necessary. The amount of data that actually passes client acceptance is far less than the raw recorded duration. The effective duration that can directly enter the training pipeline is more important.
From here, the industry has gradually shown increasingly clear stratification. Because different types of data have vastly different values. From a comprehensive perspective of cost and value, a "Data Pyramid" can roughly be formed.
Different Types of Data Have Huge Value Differences
At the base of the "Data Pyramid" is internet data, which has almost no collection cost while also having considerable scale.
Robots can learn from it what objects look like and the general layout of a kitchen. But the problem is obvious: it can only help robots "know," hardly helping them "do." The truly difficult aspects of the real world are actions: friction, weight, material changes, spatial constraints, collision risks—these cannot be learned solely from ordinary videos.
Further up is the next layer: human data, with Ego Data being the most important part. It can tell the model from a first-person perspective how humans operate. This part of video data can be used on a large scale for pre-training, just as done in EgoScale.
But robots ultimately still need to solve the problem of what their own bodies should do. Unscrewing a bottle cap, for example, is easy for a human hand but may result in repeated failure for a robot.
Thus, perceptual data from data gloves is becoming increasingly important. Ordinary Ego Data can only tell the model what humans saw and what tasks they completed. But robots ultimately also need to know when to increase force and when to relax.
These subtle actions are difficult to infer from video alone. Therefore, more and more companies are beginning to try aligning hand motion capture, pose estimation, joint trajectories with visual data.
Video is responsible for providing spatial understanding, gloves are responsible for providing action details, and teleoperated real machine data further helps the robot understand how its own body should execute.

However, there is still a very practical problem in the industry: glove standards are still not unified. Sampling frequency, joint definitions, precision, and motion expression methods vary greatly across different devices. How to stably map human actions to different robot bodies remains a significant bottleneck.
Therefore, if not using data gloves and only using a head-mounted camera, the price of Ego Data is not too high. But once data gloves are added, the price rises rapidly.
Further up the pyramid is simulation data. Through digital twin environments, robots can train at high speeds in virtual worlds, repeatedly experiencing millions of grasps, navigations, and obstacle avoidances. The amount of data that might take a month to complete in reality could be run in a simulation environment in just a few days.
However, simulation is ultimately not the real world. Although it is large-scale and low-cost, various random factors in reality—friction, material changes, reflections, etc.—are difficult to fully replicate. This is the often-mentioned "Sim-to-Real Gap" in the industry. Robots perform well in simulation but often see their capabilities drop significantly once they enter real environments.
At the top of the pyramid is the highest quality, most expensive, and scarcest real machine data, primarily generated through methods like teleoperation, where operators control robots to complete specific tasks. The robot simultaneously records vision, actions, control signals, and sensor states.
Unlike human data, it is naturally in the robot's action space; the model doesn't need to struggle to understand how to map human actions to the robot's body. Additionally, real machine data also includes autonomous work data produced during application. However, current robots are generally not yet deployed on a large scale, so the data produced is similarly scarce.
Moreover, the key problem with real machine data is that production efficiency is very low. To increase data scale, more robots and operators are needed, along with high costs for space and equipment wear and tear, all of which quickly drive up the price.
The price situation given by multiple industry insiders is roughly as follows: the simplest Ego Data often costs only tens of yuan per hour, while robot body data involving teleoperation typically rises to hundreds or even thousands of yuan per hour.
In the training processes of robot models from different manufacturers, the layers of the data pyramid play different roles. Consequently, the entire industry has also seen the emergence of upstream data companies with different focuses, such as simulation and human first-person data.
Who Is Trading This Data?
When a huge industry scales up, the first to profit are often the upstream "water sellers."
The embodied intelligence industry is no different. Over the past year or two, a large number of robotics startups have emerged globally, with talent from various industries gathering in this field.
Almost daily, new companies announce funding completions. Domestically, companies with valuations in the tens of billions are increasing, with some even heading for IPOs. Looking abroad, Figure's valuation reached $39 billion after its Series C funding last year, ranking first among humanoid robot companies.
Everyone wants to make general-purpose humanoid robots and needs massive data. Simultaneously, due to constant capital influx, the entire sector is still in a state of not lacking funds.
Therefore, behind these companies with strong data demands and ample R&D funds, there are more and more upstream "water sellers" in the robotics industry, gradually forming the data production chain for the robotics industry.
Moreover, as the industry develops, these upstream companies focusing on the data needed for robot training have also begun to show clear stratification. Judging from the current industry structure, they can roughly be divided into five types of players.
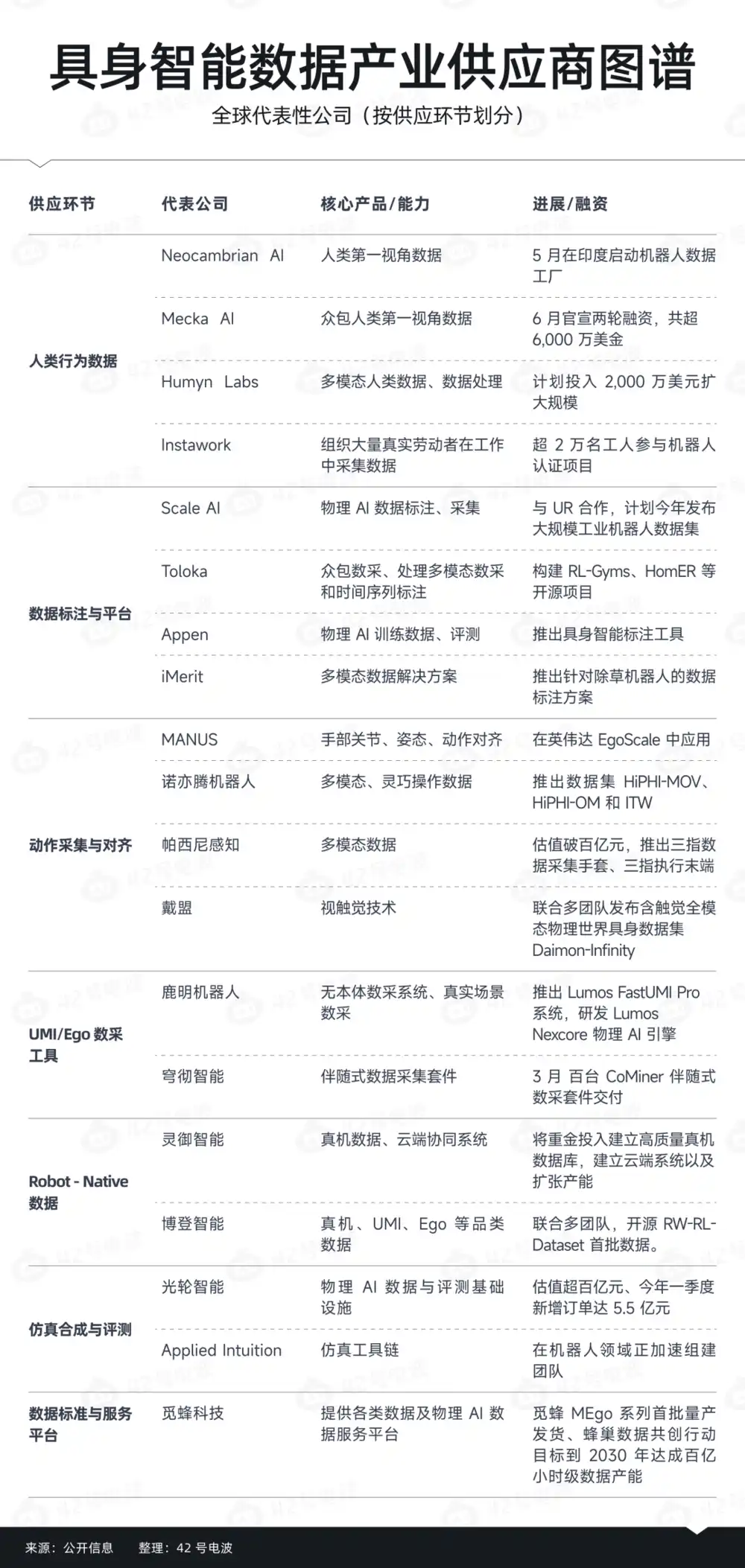
The first category is low-cost data factories, focusing on collecting Ego Data. In places like India and Thailand, more and more teams are beginning to organize low-cost labor to build data collection networks.
For example, recently, a startup called Neocambrian AI has launched a robot data factory project in India to collect human motion data for embodied models, especially Ego Data. Its founder particularly emphasized that India's vast labor force is a major advantage for developing physical AI datasets.
Data collectors wear head-mounted camera devices and motion capture gloves, complete tasks according to workflow procedures, then backend teams clean, annotate, and accept the data, finally delivering it to robot companies.
From a business model perspective, they are similar to data annotation companies that served large models earlier, except that in the past, they annotated text, images, and speech; now they are producing physical world experience.
An industry insider also told us that over the past year, they have clearly felt an increase in demand from overseas clients, especially European and American robot companies. "They have clearer specifications for data; they know what they want."
Because robot data is not as simple as "recording videos." Many clients really need a set of data that can directly enter the training pipeline, including time series, multi-view footage, motion trajectories, sensor states, hand poses, environmental metadata, and finally, a format adapted for training.
In this process, more and more companies are also discovering that relying solely on low-cost human labor is actually difficult to form long-term barriers. In the future, the biggest competitive barrier for these low-cost data factories will likely depend on whether the delivered data can be more easily used directly.
And the problem is also very practical: this type of business is naturally prone to commodification. If one team can do it, another team can theoretically do it too. As prices become transparent, profit margins are often compressed.
Therefore, low-cost delivery capability is their greatest advantage but could also become their ceiling.
The second category is the motion capture and alignment layer. Compared to simply collecting videos, these players try to solve the problem of "how actions are truly understood by machines." Their focus is not just on data volume; motion expression is more important.
For example: data gloves, motion capture, hand tracking, motion retargeting, operation collection interfaces.
Because the truly difficult part for robots is often not whether they can see/understand, but how to move. For example, grasping a cup: different robot dexterous hands have different degrees of freedom, different finger joint structures, different force control capabilities.
This creates a key problem: how can human actions be stably mapped to different robot bodies?
Therefore, more and more companies are beginning to pay more attention to motion retargeting. In this process, video is responsible for telling the robot what the human did, while the motion layer further answers how the robot itself should do it.
The real value of this layer is often not the hardware itself; the core is more stably completing "action translation."
The third category is the Robot-Native data layer, typically third-party teleoperation and real machine data service providers. The core characteristic of these players is that they are closer to the robot body. In fact, they often need to be deeply bound with robot companies.
Because compared to other data collection segments, real machine data is highly dependent on a large number of specific robots. Different companies' robots have different hardware, degrees of freedom, action spaces, and control interfaces, creating significant differences. The same grasping task may need to be recollected for a different robot.
In this process, they provide teleoperators, facilities, and real machine collection capabilities to help robot companies quickly accumulate training data, especially in the early validation stages of the model. When a robot company doesn't yet have enough teams and facilities itself, external service providers can often get started faster.
The fourth category is simulation/synthetic data companies. They don't just sell data; their focus is on trying to build a more complete data capability.
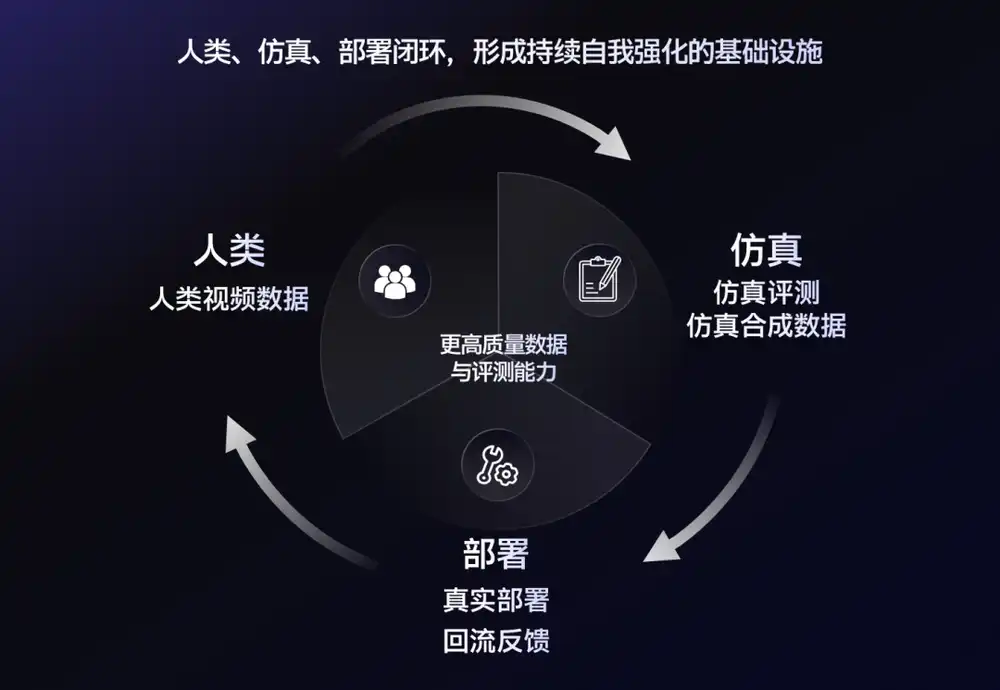
While producing data, they also help clients answer why the robot failed a task and how to collect the next batch of data. This is the new path many companies are taking today.
The logic is simple: a robot training for a day might only accumulate a few hours of effective trajectories. But in a simulated world, in the same amount of time, a robot can fail millions of times—grasping failures, path planning errors, collisions, falls—all can be repeated infinitely.
Therefore, the industry is also gradually forming a new combination: real data is responsible for anchoring to reality, and synthetic/simulation data is responsible for scaling up.
NVIDIA has also repeatedly emphasized in its GR00T roadmap that robot foundation models not only need human demonstration data but also a large amount of synthetic data. Developers can first gain prior knowledge through real-world collection, then use simulation to expand task scale.
The more a model fails in simulation, the more it knows what data it lacks. And whoever can produce this data the fastest has a better chance of gaining an advantage.
The fifth category of players leans more towards the data standards and platform layer, exploring how to make data supply itself more standardized and easier to circulate while expanding data scale.
Because robot companies are becoming more numerous, and data is becoming highly fragmented. Collection methods differ, motion expressions differ, format standards differ. Often, the same data cannot even be directly reused.
Against this backdrop, attempts around embodied data standardization and collaborative collection have also begun to increase noticeably this year.
For today's robotics industry, the lack of data is only one problem. Whether data can be produced continuously and stably and enter the training pipeline more easily is also very critical.
However, whether it's human data, real machine data, or simulation and other types of data players, they all ultimately have to answer this question: Will robot companies outsource these core capabilities to external suppliers?
After all, for most embodied companies today, data is not just a cost; it is also a barrier.
Should Robot Companies Buy Data or Collect It Themselves?
Entering this year, data holds a pivotal position in the robotics industry. Everyone knows robots lack data.
Compared to the past, there are now more and more data supply choices on the market. Different data types have their suppliers to choose from. For robot companies, buying data is becoming easier and easier.
But the reality is somewhat different. On one hand, more and more robot companies are beginning to purchase data; on the other hand, leading companies are desperately building their own data teams.
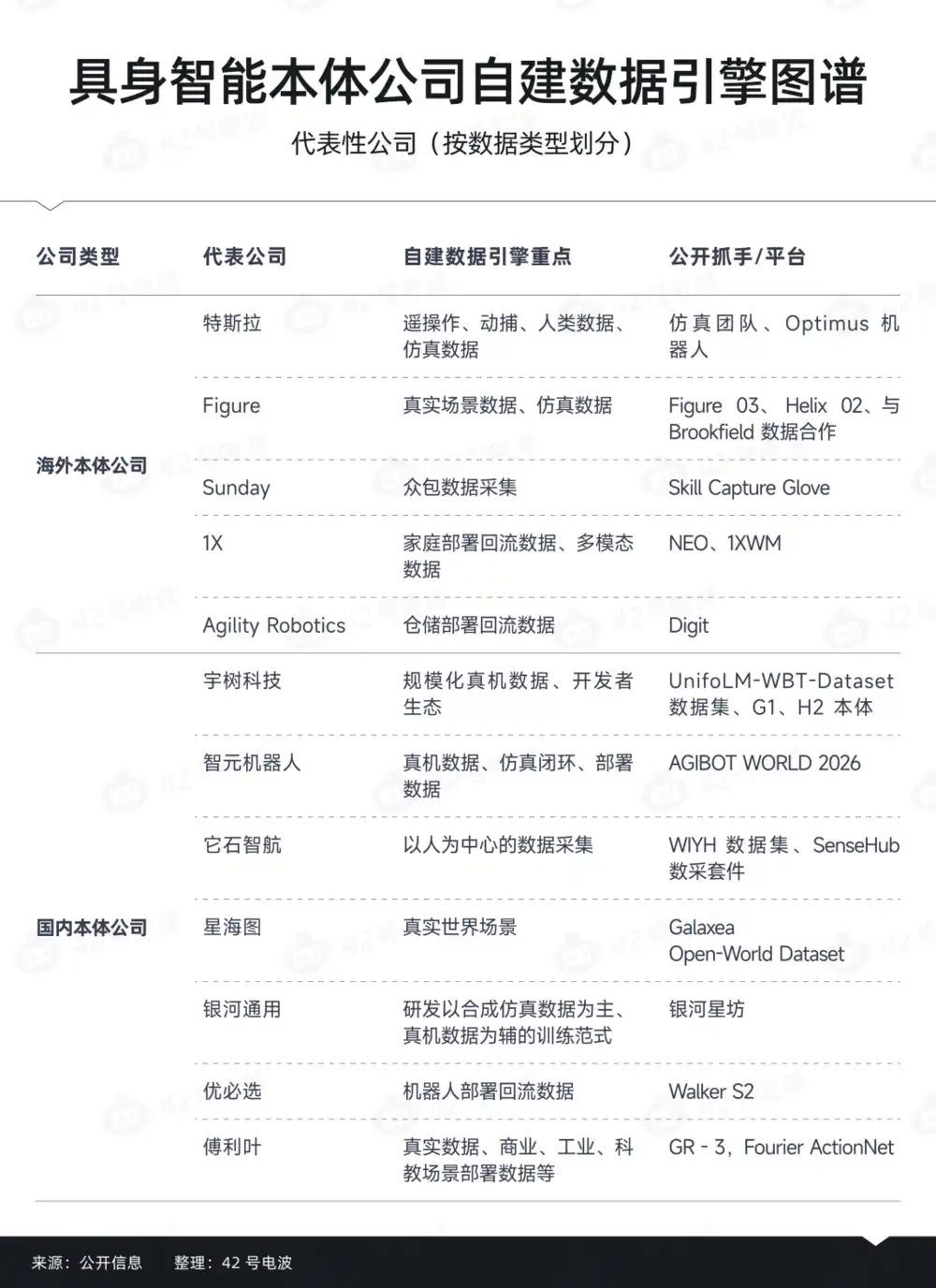
If we break it down, we find that different types of data determine completely different organizational approaches.
To some extent, robot companies are truly forming a "layered procurement" logic.
The first layer is foundational, general-purpose data. This is the layer most easily outsourced.
For example: kitchen tidying, organizing desktops, basic grasping, sorting, moving, etc. This type of data has a common characteristic: regardless of what the robot looks like, it ultimately needs to understand how humans complete tasks.
For example, when a robot enters a kitchen, when should it free one hand first? When should it organize large objects before small ones? When there are too many items, how should space be replanned?
These capabilities essentially belong to general physical world cognition, not the exclusive capability of a particular robot.
If a company starts collecting such Ego data from scratch itself, it needs to build a team, and management costs are relatively high.
In contrast, external teams can rapidly expand collection scale in regions like Southeast Asia and India, stably outputting thousands of hours per month.
For robot companies, buying often makes more sense than building a team themselves at this stage. Because the goal at this phase is not to make the robot work stably but to first understand the world.
Therefore, outsourcing this type of data is reasonable, even a more efficient choice.
The second layer is embodied adaptation data. Robot companies tend to prefer collecting this themselves.
After pre-training with large amounts of foundational data, training then begins to involve the core link of actual robot deployment: task alignment.
So the logic begins to change. Because each company's robot body has significant differences: different degrees of freedom, different dexterous hands, different joint capabilities, etc. The motion logic the robot ultimately needs to learn will also be quite different.
The closer to the action execution layer, the harder it is for data to be universal. Therefore, although many companies purchase large amounts of Ego Data, they still build internal data collection teams for real machine data collection. Because this layer is already approaching the model's real competitiveness.
The third layer is deployment data and failure data. This is a crucial layer, often generated after actual deployment.
After robots are deployed to actual application scenarios, they often encounter various unexpected situations in their real working environments. The deployment data generated in these real scenarios, whether successful or failed, is extremely valuable. Moreover, such data is rarely encountered in pre-deployment data collection, difficult to design in advance, and can only be accumulated bit by bit in real environments.
Furthermore, many companies also find it difficult to deploy their robots on a large scale to real scenes, so real deployment data is out of the question.
During deployment, robots continuously accumulate experience in changing environments. Even failure data helps teams identify causes and formulate countermeasures to optimize the model, thereby further promoting the large-scale deployment of robots.
This belongs to the core data of leading robot companies and is also their barrier distinguishing them from competitors.
This, to a certain extent, also limits the ceiling for data companies. They can help robots "get started," but the data that truly determines the upper limit of capabilities is something many leading companies will ultimately choose to control themselves.
Therefore, the two different paths differentiated in the data industry are also traceable: one is data factories, the other is data engines.
Data factories are currently the fastest-emerging, most numerous type of company in the industry, also easier to generate cash flow.
Among them, low-cost data factories focus more on human behavior data, relying on low-cost labor advantages. They charge by the hour, pursue scale and delivery capability. Cash flow may turn positive quickly, but barriers are limited. Competitors are rapidly increasing, especially after EgoScale, with a large number of startups entering the human data field.
Higher-complexity data factories, on the basis of covering human behavior data, deploy robots in batches, collecting large amounts of real machine data through teleoperation or autonomous operation.
The other path attempts to build data engines: organizing task classification systems, building data structures, implementing motion retargeting, integrating simulation platforms, implementing model evaluation, and iteratively producing datasets based on model failure samples.
In other words, what they are doing is not just selling data; the focus is on enabling robots to have the ability to continuously become smarter.
Will a Robot Version of Scale AI Emerge?
Placing today's robotics industry back into the large model context of 2022 reveals a sense of similarity.
At that time, the industry also discovered that the thing that truly determines the upper limit of model capabilities is data.
Consequently, a new batch of companies began to rapidly rise around fields like data cleaning, RLHF, evaluation, and post-training. The most classic example is Scale AI.
This company helped autonomous driving companies label data in its early stages. Starting in 2019, during the GPT-2 phase, Scale AI deeply bound itself with OpenAI, undertaking RLHF human feedback labeling, large model evaluation, red team testing, and reverse generation of edge case data.
After the explosion of ChatGPT, Meta Llama, Anthropic, Microsoft Azure, etc., quickly integrated. The demand for high-quality labeling, evaluation, and synthetic data for large models skyrocketed, and this company's revenue increased more than fourfold in three years.
Later, this company also gradually moved towards deeper infrastructure layers: data management, model evaluation, AI workflow.
Because of Scale AI's success story, many people are also wondering: will a similar company emerge in the robotics industry?
Judging from the current degree of data shortage, it's very likely, but it won't be an exact copy.
Because the data needed by robots is much more complex than text. For large models, determining whether an answer is right or wrong is relatively easy. But in the robot world, whether an action is successful is often full of ambiguity.
The cup was picked up, but at the wrong angle. The item was put back, but knocked over other objects. And often, there are multiple correct paths to completing a task itself.
Therefore, what the robotics industry truly needs is not a simple data platform; the focus is on an entire closed-loop system for data collection, labeling, action mapping, simulation augmentation, model evaluation, and failure feedback.
What robots truly lack is not just data; the ability to continuously produce effective experience is even scarcer.
So, more and more companies are shifting their competitive focus from the robot body and model architecture to the data system.
Since this year, whether it's Figure, 1X, PI, or the GR00T path promoted by NVIDIA, all repeatedly emphasize a common direction: the growth of robot capabilities is only partly about hardware upgrades; more data and more effective training are becoming the main actors.
To some extent, as the robotics industry enters the mass production and deployment phase, everyone is moving from "building machines" into a new period of "feeding machines."
In the stage where robots couldn't stand up or walk, the biggest competitive advantage for embodied companies was whether they could do hardware and motion control well.
But when robots can run and jump, achieving results surpassing humans in many competitions, the ability for autonomous work has become the industry's biggest goal. Driven by this goal, the industry's main theme has become large-scale, high-quality data.
For robots to succeed continuously in the complex real world, they need to have seen enough tasks that truly exist in physical space. They need to know that cups might tip over, clothes might get tangled, space might be insufficient. This experience does not naturally exist on the internet; it can only be produced little by little.
Therefore, this data industrial chain has also quietly taken shape behind the robotics boom of the past two years.
At one end of the chain are humans wearing cameras in Indian factories, and robots constantly falling in simulation.
At the other end are robot companies valued at tens of billions, hundreds of billions, or even trillions, trying to get robots truly into homes and factories.
From Indian data factories and simulated robots to major robot companies worldwide, a new production chain has begun to form. Only this time, what is being produced is no longer components, but data.
This article is from WeChat public account: 42 Channel , author: Lanbo, editor: James, original title: "Robots Begin to 'Consume Data': The Hidden Production Chain from Indian Data Factories to Billion-Dollar Humanoid Robots"





