На одной из индийских швейных фабрик рабочие, как обычно, сортируют ткань, но на этот раз разница в том, что на их головах закреплены камеры, чтобы снимать видео от первого лица во время работы.
Эти видео после обработки станут цифровыми активами, которые будут продаваться компаниям, занимающимся воплощенным искусственным интеллектом (embodied AI), нуждающимся в больших объемах данных для обучения роботов.
Подобный бизнес, начиная с этого года, ускоряет формирование новой производственной цепи. Рост этой цепи связан с главным узким местом, с которым в настоящее время сталкивается индустрия воплощенного интеллекта: данные.
«В этом году спрос явно вырос», — рассказал 42-й Волне специалист, работающий в сфере сбора данных для роботов. Его команда обслуживает европейские и американские компании-роботостроители, которые массово закупают данные о человеческой работе. В настоящее время в производстве обучающих данных для роботов участвуют около ста сборщиков из его команды, которые ежемесячно стабильно производят тысячи часов видеоданных от первого лица.
Сборщики должны выполнять задачи по стандартной процедуре, такие как складывание одежды, организация кухни, захват предметов. В процессе они носят камеру на голове, а для некоторых задач также используют дата-перчатки для записи более тонких движений кисти.
«Раньше в отрасли говорили о моделях, о железе, а сейчас все больше людей спрашивают: можно ли обеспечить стабильные поставки данных?»
Стало ясно, что ключевой проблемой, сдерживающей прорыв в возможностях моделей, является недостаточный объем данных.
На фоне огромного дефицита данных для моделей воплощенного интеллекта бизнес по сбору данных как новое направление также начал стремительно формироваться.
Почему роботы начали испытывать дефицит данных?
Если вернуться на три года назад, роботы были больше похожи на традиционную автоматизированную промышленность.
Большинство роботов были закреплены на заводах, их рабочие процессы были высокоструктурированными: сварка, транспортировка, покраска, сборка. Им не нужно было понимать сложную среду или учиться способности к обобщению, им нужно было лишь повторять действия по заданной траектории.
Сейчас многие компании хотят создавать уже не традиционных промышленных роботов. От Tesla и Figure до PI — отрасль пытается сделать так, чтобы роботы обучались, как большие языковые модели, и обладали универсальными способностями.
Поэтому путь моделей воплощенного интеллекта также все больше напоминает путь больших языковых моделей (LLM), только он оказывается еще более трудным, особенно в области данных.
Для LLM интернет сам по себе является естественной золотой жилой данных. Десятилетиями накопленные веб-страницы, книги, научные статьи, репозитории кода составляют огромный корпус обучающих материалов. Компаниям, работающим с моделями, обычно нужно лишь решить проблему отбора и очистки данных, редко возникает необходимость создавать данные с нуля.
Но с моделями воплощенного интеллекта все иначе — они сталкиваются с физическим миром, который является настоящей пустыней данных. Данные о движениях роботов не возникают из ниоткуда. Даже если в интернете много видео о человеческой работе, для роботов такого объема данных все еще недостаточно, да и общее качество невысоко.
Если LLM рождаются в библиотеке, то роботы больше похожи на рожденных в пустыне.
Поэтому, когда ИИ уже вступил в фазу конкуренции вычислительных мощностей и оптимизации логического вывода, индустрия воплощенного интеллекта все еще застряла на самой базовой проблеме: откуда брать данные.
Вот почему, даже несмотря на все более сложные архитектуры моделей, роботы по-прежнему далеки от реального вхождения в дома и сложные сценарии.
Потому что моделям не хватает достаточного реального опыта.
Ранее основатель Figure Бретт Эдкок высказал прямую мысль: «Если бы можно было щелкнуть пальцами, и все необходимые огромные объемы данных оказались бы внутри модели Helix, мы бы сразу справились с созданием универсального робота.»
Но проблема в том, откуда взять данные?
Как производится один час данных?
В феврале этого года одно исследование начало будоражить отрасль.
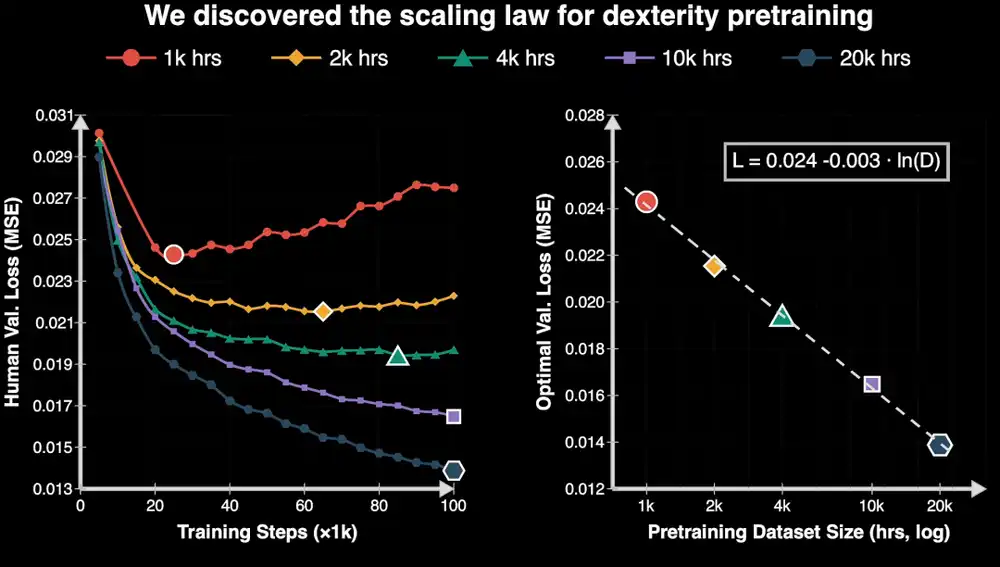
Команда NVIDIA выпустила EgoScale. С помощью предварительного обучения модели на более чем 20 000 часов видео от первого лица с аннотациями действий человека, а затем дообучения на небольшом количестве данных робота, ловкая рука Sharpa Wave с 22 степенями свободы смогла выполнить такие задачи, как откручивание крышки бутылки и складывание одежды.

Что более важно, исследование показало, что с увеличением объема человеческих данных производительность модели стабильно улучшается, и это улучшение предсказуемо.
Это исследование очень важно для индустрии воплощенного интеллекта, ведь масштабируемый путь данных означает, что рост способностей роботов имеет шанс, как и у больших моделей, войти в положительную петлю обратной связи: «больше данных — сильнее способности».
Долгое время в индустрии воплощенного интеллекта существовала тревога: даже при увеличении инвестиций рост возможностей моделей оставался в высокой степени непредсказуемым. Потому что реальных данных слишком мало, их стоимость слишком высока, и мало кто решался вкладывать огромные средства в сферу данных.
Но EgoScale в некоторой степени доказал одну вещь: по крайней мере, в отношении данных от первого лица (Ego Data), масштаб действительно может приносить стабильную пользу в манипуляциях ловкой рукой.
В то же время все больше компаний-роботостроителей идут по пути большого количества человеческих данных плюс небольшого количества данных от самого робота.
Видео от первого лица отвечает за то, чтобы рассказать модели, как человек выполняет задачу. Данные от робота отвечают за то, чтобы модель научилась, как должно действовать ее собственное тело.
Таким образом, основная ценность Ego Data заключается в том, что это более легко масштабируемое априорное знание, позволяющее роботу сначала понять физический мир, а затем адаптироваться с помощью небольшого количества реальных данных.
Поэтому в этом году явно ускорилось формирование новой производственной цепи, ориентированной на Ego Data.
Человек надевает камеру на голову или грудь, а затем выполняет конкретные задачи, например, складывает одежду, убирает на кухне, сортирует посылки. Камера записывает видео от первого лица во время работы.
В определенном смысле сам человек является самым совершенным универсальным роботом в мире. Заходя на кухню, человек естественным образом решает, что поставить сначала, а что потом; если места не хватает, он освобождает другую руку. Сталкиваясь с хрупким предметом, инстинктивно регулирует силу.
За этими, казалось бы, инстинктивными движениями скрывается огромная логика пространственного понимания, планирования задач и взаимодействия с объектами.
А роботы в прошлом почти никогда систематически не получали этого опыта.

Но Ego Data — это не просто съемка видео. И съемка видео в достаточном объеме — не самая большая сложность. Ключ в том, как превратить этот опыт в продукт данных, который модель действительно может использовать.
Специалист, который в этом году начал активно развивать направление Ego-данных, рассказал 42-й Волне, что реальный сбор данных обычно начинается с документа спецификации задачи (specification), присланного клиентом.
В таком документе не будет просто написано «собрать данные по уборке кухни». Часто там будут четкие требования:
Какой тип задачи, должны ли обе руки полностью попадать в кадр, должна ли камера быть на голове или на груди, допускаются ли перерывы в действиях, сколько вариантов среды требуется, нужны ли образцы неудач, в каком формате должен быть конечный результат, совместимый ли он с фреймворком обучения.
Например, та же уборка кухни: клиент может потребовать непрерывного выполнения нескольких шагов — открыть дверцу шкафа, найти контейнер, освободить место, взять/положить предмет, закрыть дверцу — без пропусков кадров и без серьезных перекрытий.
В определенном смысле это больше похоже на производство промышленного изделия, и весь процесс сбора на месте гораздо более «фабричный», чем можно представить.
В некоторых центрах сбора данных сборщики по очереди заходят в подготовленные кухни, гардеробные, зоны стеллажей и по единому SOP повторно выполняют задачи.
Кто-то отвечает за складывание одежды, кто-то повторяет захваты предметов разных размеров, а кто-то специализируется на сборе данных по организации кухни и перемещению.
Одно и то же действие часто должно быть повторено людьми разного роста, с разной ведущей рукой и разными привычками выполнения, чтобы попытаться охватить все возможные ситуации в физическом мире. Ведь робот в итоге столкнется со сложным реальным миром, а не с единственным стандартным ответом.
Даже такое простое действие, как поставить чашку в шкаф: кто-то сначала освобождает место, кто-то меняет руку, кто-то привык сначала открыть дверцу. Эти тонкие различия как раз и составляют часть способности робота к обобщению.
Поэтому для многих моделей воплощенного интеллекта им нужно учиться логике «как человек обычно это делает».
По сравнению с данными от реального робота, такие данные легче производить серийно. Перед лицом огромного спроса в отрасли, пока масштаб соответствует, а затраты на рабочую силу низки, появляется основа для прибыли, и относительно легко создать денежный поток.
Но если данные не соответствуют требованиям клиента, нужна доработка. Данные, окончательно принятые клиентом, гораздо меньше исходного времени съемки. Важнее эффективное время, которое можно напрямую использовать в процессе обучения.
С этого момента в отрасли началось все более явное расслоение. Потому что разные данные имеют огромную разницу в ценности. С комплексной точки зрения затрат и ценности можно примерно сформировать «пирамиду данных».
Разные типы данных имеют огромную разницу в ценности
В «пирамиде данных» самый нижний уровень — это интернет-данные, у них почти нет затрат на сбор, и при этом есть немалый объем.
Робот может научиться из них, как выглядят объекты, каков приблизительный план кухни. Но проблема очевидна: они могут помочь роботу только «знать», но не «делать». Реальная сложность физического мира — в действиях. Трение, вес, изменение материала, ограничения пространства, риск столкновения — всему этому нельзя научиться только по обычному видео.
Выше находится следующий уровень — человеческие данные. Ego Data — самая важная их часть. Они могут с точки зрения первого лица рассказать модели, как действует человек. Эти видеоданные можно использовать в больших масштабах для предварительного обучения, как это сделано в EgoScale.
Но роботу в итоге еще нужно решить, как должно действовать его собственное тело. Та же открутка крышки: человек делает это легко, а робот может терпеть неудачу снова и снова.
Поэтому данные восприятия от дата-перчаток становятся все более важными. Обычные Ego Data могут только сказать модели, что видел человек и какую задачу выполнил. Но роботу в итоге еще нужно знать, когда увеличить усилие, а когда ослабить.
Эти тонкие движения трудно вывести только по видео. Поэтому все больше компаний пытаются согласовать захват движений кисти, оценку позы, траектории суставов с визуальными данными.
Видео отвечает за пространственное понимание, перчатки — за детали движений, а данные телеуправления от реального робота еще больше помогают роботу понять, как его собственное тело должно выполнять действия.

Но в отрасли сейчас есть и очень практическая проблема: стандарты для перчаток все еще очень неединообразны. Частота дискретизации разных устройств, определение суставов, точность и способы выражения движений сильно различаются. Как стабильно сопоставлять человеческие движения с разными телами роботов — это все еще серьезное узкое место.
Поэтому если не использовать дата-перчатки, а снимать только камерой на голове, цена Ego Data не так уж высока. Но как только добавляются дата-перчатки, цена быстро растет.
Еще выше в пирамиде находятся симуляционные данные. Через цифровые двойники среды робот может быстро обучаться в виртуальном мире, многократно проходя через миллионы захватов, навигации и избегания препятствий. Объем данных, на сбор которых в реальности ушел бы месяц, в симуляции можно пробежать за несколько дней.
Но симуляция — это все же не реальный мир. Хотя объем велик, а стоимость низка, различные случайные факторы в реальности — трение, изменение материалов, блики — трудно полностью воспроизвести. Это часто упоминаемый в отрасли «разрыв между симуляцией и реальностью» (Sim-to-Real Gap). Робот, хорошо научившийся в симуляции, часто демонстрирует гораздо более слабые результаты, попадая в реальную среду.
А вершина пирамиды — это данные от реального робота самого высокого качества, самые дорогие и дефицитные. В основном они получаются путем телеуправления оператором, когда робот выполняет конкретные задачи, а робот одновременно записывает визуальную информацию, действия, управляющие сигналы и состояние датчиков.
В отличие от человеческих данных, они изначально находятся в пространстве действий робота, и модели не нужно напрягаться, чтобы понять, как сопоставить человеческие движения с телом робота. Кроме того, данные от реального робота также включают данные, генерируемые им при автономной работе. Но сейчас роботы еще не нашли широкого применения, поэтому такие данные также скудны.
Ключевая проблема данных от реального робота — очень низкая производительность. Чтобы увеличить объем данных, нужно добавлять больше роботов и операторов, а также нести высокие затраты на помещения и износ оборудования, что быстро взвинчивает цену.
По информации нескольких специалистов отрасли, цена примерно такова: самые простые Ego Data часто стоят всего несколько десятков юаней в час, в то время как данные от робота, связанные с телеуправлением, обычно вырастают до сотен или даже тысяч юаней в час.
В процессе обучения робототехнических моделей разных производителей различные уровни пирамиды данных играют разные роли. Поэтому во всей отрасли появляются компании-поставщики данных сверху вниз, такие как симуляционные данные и данные от первого лица, с разными акцентами.
Кто торгует этими данными?
Когда возникает масштабная отрасль, первыми получают прибыль часто «продавцы воды» на верхних этажах цепочки.
С индустрией воплощенного интеллекта происходит то же самое. За последний год-два по всему миру появилось очень много стартапов в области робототехники, специалисты из разных сфер стекаются в эту область.
Почти каждый день новая компания объявляет о завершении финансирования. В Китае компаний со стоимостью в десятки миллиардов юаней становится все больше, некоторые даже выходят на IPO. За рубежом Figure после завершения раунда финансирования C в прошлом году достигла капитализации в 39 миллиардов долларов, заняв первое место среди компаний по производству роботов-гуманоидов.
Все хотят создать универсального робота-гуманоида, всем нужны огромные объемы данных, и из-за постоянного притока капитала вся отрасль пока находится в состоянии, когда денег не жалеют.
Поэтому за этими компаниями с сильным спросом на данные и достаточными средствами на разработку появляется все больше «продавцов воды» на верхнем уровне робототехнической индустрии. Так постепенно формируется производственная цепь данных для робототехники.
Более того, с развитием отрасли эти компании-поставщики данных, сосредоточенные на данных, необходимых для обучения роботов, также начали формировать явную иерархию. Судя по текущей структуре отрасли, игроков можно примерно разделить на пять категорий.
data-check-id="536085">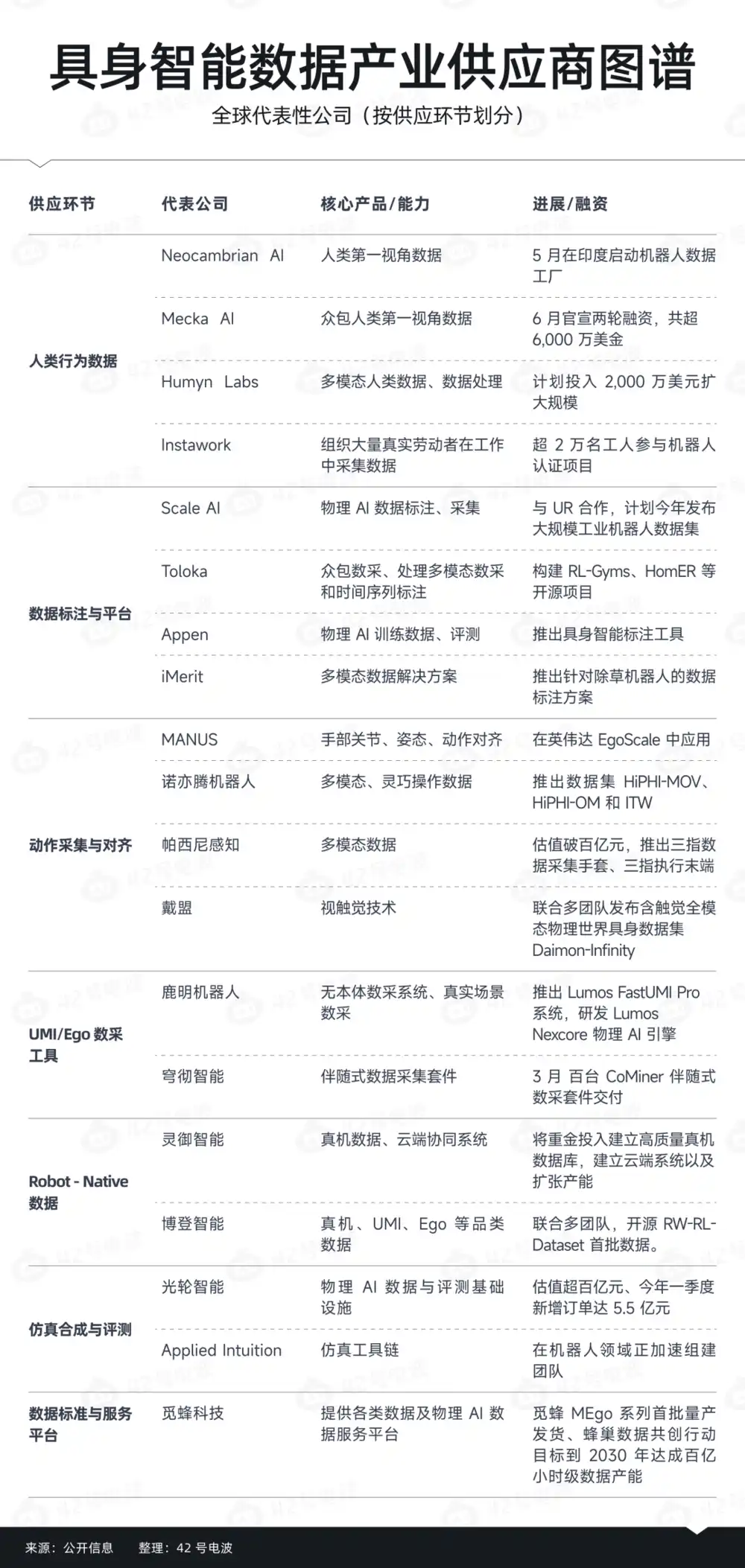
Первая категория — это фабрики данных с низкими затратами. Их фокус — сбор Ego Data. В Индии, Таиланде и других странах все больше команд начинает организовывать низкозатратную рабочую силу и строить сети сбора данных.
Например, недавно стартап под названием Neocambrian AI запустил в Индии проект фабрики данных для роботов, собирая данные о человеческих движениях, особенно Ego Data. Его основатель особо подчеркнул, что Индия обладает огромными трудовыми ресурсами, что является большим преимуществом для развития наборов данных по физическому ИИ.
Сборщики данных надевают камеры на голову и перчатки захвата движений, выполняют работу по заданной процедуре, после чего команда бэкэнда проводит очистку, аннотирование и приемку, и в итоге поставляет данные компаниям-роботостроителям.
С точки зрения бизнес-модели они очень похожи на компании по аннотации данных, обслуживавшие большие модели ранее, только раньше аннотировали текст, изображения и речь, а теперь начали производить опыт физического мира.
Как сообщил нам один отраслевой специалист, за последний год явно ощущается рост спроса со стороны зарубежных клиентов. Особенно со стороны европейских и американских компаний-роботостроителей: «Они более четко знают спецификации данных, знают, что им нужно.»
Потому что данные для роботов — это не просто «съемка видео». Многие клиенты реально нуждаются в наборе данных, который можно напрямую загрузить в обучающий конвейер: временные ряды, изображения с нескольких ракурсов, траектории движений, состояние датчиков, позы кисти, метаданные среды и конечный формат, адаптированный для обучения.
В этом процессе все больше компаний также обнаруживают, что полагаться только на дешевую рабочую силу на самом деле трудно создать долгосрочный барьер. В будущем для этих фабрик данных с низкими затратами наибольшим конкурентным барьером будет то, насколько легко их поставляемые данные можно использовать напрямую.
И проблема очень практична: такой бизнес по своей природе легко коммодитизировать. Одна команда может это делать, другая, теоретически, тоже. Когда цены становятся прозрачными, маржа прибыли часто сжимается.
Поэтому способность к дешевой поставке — их наибольшее преимущество, но оно же может стать и их потолком.
Вторая категория — это уровень сбора движений и их сопоставления. В отличие от простой съемки видео, эти игроки пытаются решить проблему «как машина действительно понимает движение». Их фокус не только на объеме данных, но и на выражении движений.
Например, дата-перчатки, захват движений, отслеживание кисти, перенаправление движений, интерфейсы сбора при оперативном управлении.
Потому что реальная трудность для роботов часто не в том, могут ли они понять, а в том, как действовать. Тот же захват чашки: у разных роботов разная ловкость рук, разное количество степеней свободы, разная структура пальцев, разная способность к силовому контролю.
Это создает ключевую проблему: как стабильно сопоставить человеческие движения с разными телами роботов?
Поэтому все больше компаний начинают уделять больше внимания перенаправлению движений. В этом процессе видео отвечает за то, чтобы рассказать роботу, что сделал человек. Уровень движений же дополнительно отвечает на вопрос, что должен делать сам робот.
Настоящая ценность этого уровня часто не в самом оборудовании, а в стабильном выполнении «перевода движений».
Третья категория — это уровень данных, родных для роботов (Robot-Native data layer). Обычно это сторонние поставщики услуг по телеуправлению и данным от реальных роботов. Основная особенность этих игроков в том, что они ближе к самому роботу. Более того, часто им самим необходимо тесно сотрудничать с компаниями-роботостроителями.
Потому что по сравнению с другими сегментами сбора данных, данные от реального робота в высокой степени зависят от большого количества конкретных роботов. А оборудование роботов у разных компаний разное: разное количество степеней свободы, пространство действий, интерфейсы управления сильно отличаются. Одна и та же задача захвата при смене робота может потребовать нового сбора.
В процессе они предоставляют операторов телеуправления, площадки и возможности сбора данных от реальных роботов, помогая компаниям-роботостроителям быстро накапливать обучающие данные. Особенно на ранней стадии проверки модели, когда у самой компании-роботостроителя еще недостаточно команды и площадок, внешние поставщики услуг часто могут начать быстрее.
Четвертая категория — это компании по симуляционным и синтетическим данным. Они не просто продают данные, а пытаются создать более целостные возможности работы с данными.
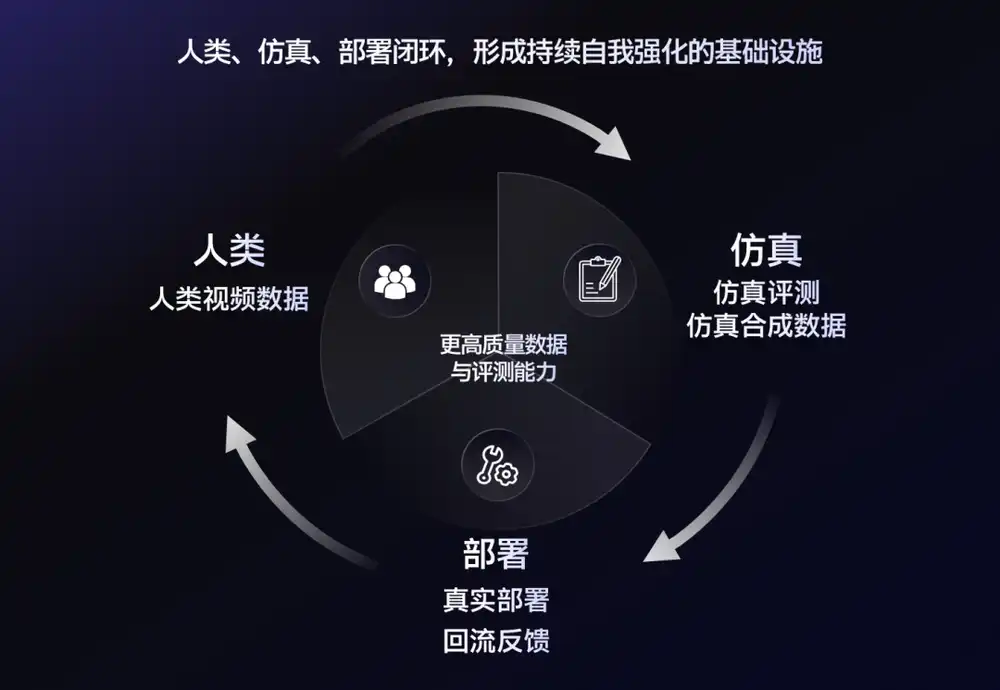
Производя данные, они также помогают клиентам ответить на вопросы, почему робот не справился с задачей и как собирать следующую партию данных. Это новый путь, по которому сегодня идут многие компании.
Логика проста: за день обучения робот может накопить лишь несколько часов эффективных траекторий. Но в симулированном мире за то же время робот может потерпеть неудачу миллионы раз: неудачный захват, ошибки планирования пути, столкновения, падения — все можно повторять бесконечно.
Поэтому в отрасли также начинает формироваться новая комбинация: реальные данные отвечают за привязку к реальности, а симуляционные и синтетические данные отвечают за масштабирование.
NVIDIA в своем подходе GR00T также неоднократно подчеркивала, что фундаментальные модели для роботов нуждаются не только в демонстрационных человеческих данных, но и в большом количестве синтетических данных. Разработчики могут сначала получить априорные знания через сбор в реальном мире, а затем с помощью симуляции расширить масштаб задач.
Чем больше модель терпит неудач в симуляции, тем лучше она понимает, каких данных не хватает. И тот, кто сможет быстрее всего произвести эти данные, получит больше шансов занять преимущество.
Пятая категория игроков больше склоняется к уровню стандартов данных и платформ. Расширяя масштаб данных, они исследуют, как сделать само предложение данных более стандартизированным и более легко обращаемым.
Потому что компаний-роботостроителей становится все больше, а данные становятся высокофрагментированными: разные методы сбора, разное выражение движений, разные форматы и стандарты. Зачастую одни и те же данные даже трудно использовать повторно.
На этом фоне в этом году заметно увеличились попытки стандартизации данных для воплощенного интеллекта и совместного сбора.
Для нынешней робототехнической отрасли нехватка данных — лишь одна из проблем. Не менее критично, могут ли данные стабильно генерироваться и легко попадать в обучающий конвейер.
Однако независимо от того, являются ли игроками человеческие данные, данные от реальных роботов или симуляционные и другие типы данных, в конечном итоге все должны ответить на такой вопрос: будут ли компании-роботостроители передавать эти ключевые возможности внешним поставщикам?
Ведь для большинства сегодняшних компаний в области воплощенного интеллекта данные — это не только затраты, но и барьер.
Компаниям-роботостроителям: покупать данные или собирать самим?
С наступлением этого года данные приобрели решающее значение в робототехнической отрасли. Все знают, что роботам не хватает данных.
По сравнению с прошлым, сегодня на рынке появляется все больше вариантов поставки данных. Для разных типов данных есть свои поставщики. Для компаний-роботостроителей покупать данные становится все проще.
Но реальная ситуация несколько иная. С одной стороны, все больше компаний-роботостроителей начинают закупать данные, с другой — ведущие компании изо всех сил строят свои собственные команды по работе с данными.
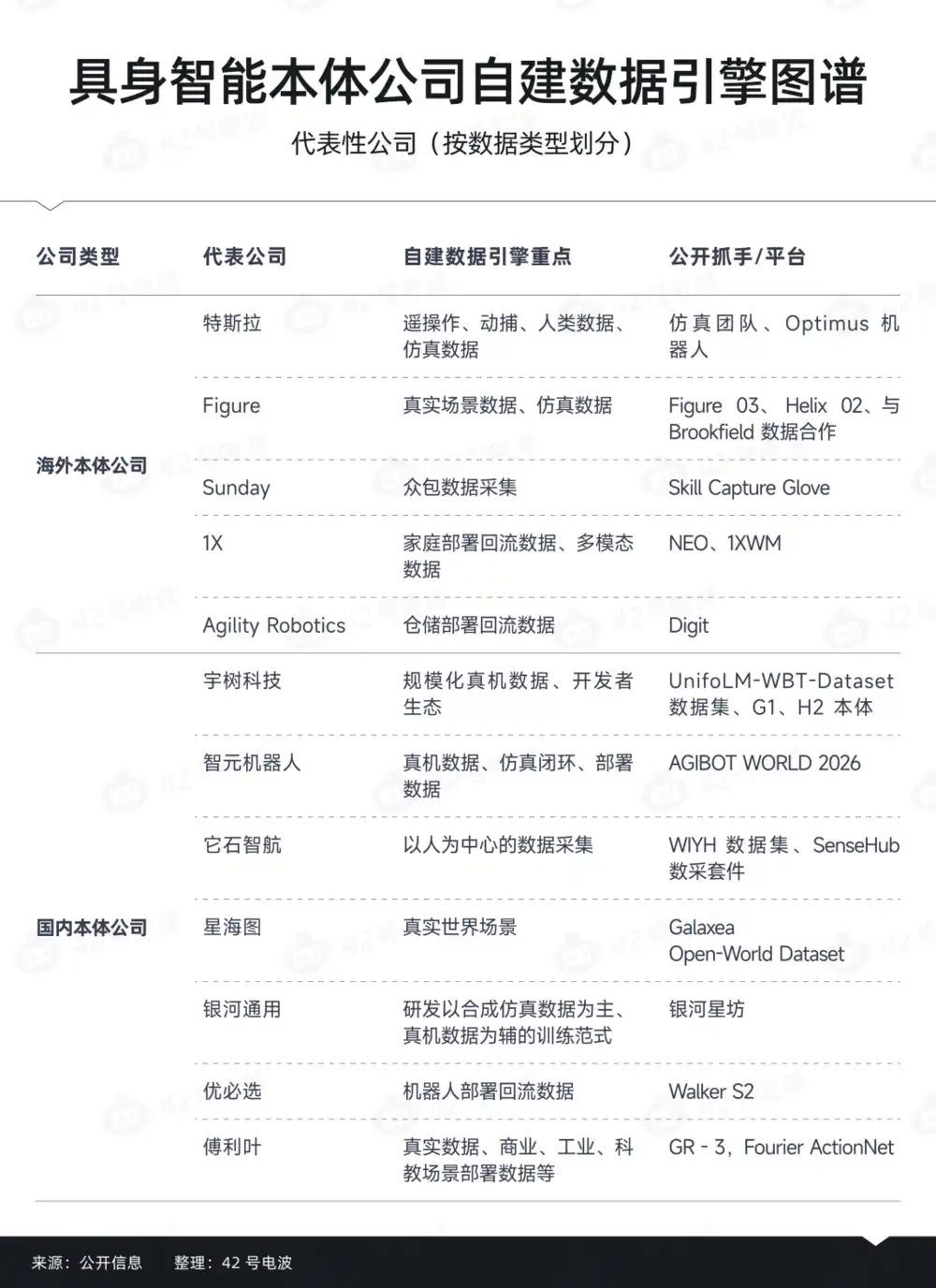
Если разложить, то обнаружится, что разные данные определяют совершенно разные организационные подходы.
В определенном смысле компании-роботостроители действительно формируют логику «слоеных закупок».
Первый уровень — это базовые универсальные данные. Это уровень, который легче всего отдать на аутсорсинг.
Например, организация кухни, наведение порядка на столе, базовый захват, сортировка, транспортировка и т.д. У таких данных есть общая черта: независимо от того, как выглядит робот, в итоге ему нужно понять, как человек выполняет задачу.
Например, когда робот заходит на кухню, когда сначала освободить одну руку, когда сначала убрать крупные предметы, а потом мелкие? Если предметов слишком много, как перепланировать пространство?
Эти способности по своей сути относятся к универсальному познанию физического мира и не являются эксклюзивной способностью какого-то одного робота.
Собирать подобные Ego-данные с нуля самостоятельно — значит создавать команду, управленческие затраты довольно высоки.
Напротив, внешние команды могут быстро расширить масштаб сбора в Юго-Восточной Азии, Индии и других регионах, стабильно производя тысячи часов в месяц.
Для компании-роботостроителя часто сначала купить оказывается выгоднее, чем строить свою команду. Потому что на этом этапе цель — не заставить робота стабильно работать, а сначала понять мир.
Поэтому отдавать такие данные на аутсорсинг рационально и даже более эффективно.
Второй уровень — это данные для адаптации к конкретному воплощению. Компании-роботостроители склонны собирать их самостоятельно.
После предварительного обучения на большом количестве базовых данных обучение начинает затрагивать ключевые аспекты реального развертывания робота — согласование задач.
Здесь логика начинает меняться. Потому что роботы у каждой компании сильно отличаются: разное количество степеней свободы, разные ловкие руки, разные способности суставов и т.д. Логика действий, которую в итоге должен изучить робот, также будет сильно отличаться.
Чем ближе к уровню выполнения действий, тем труднее данные становятся универсальными. Поэтому многие компании, хотя и массово закупают Ego Data, все же создают внутри команды по сбору данных для сбора данных от реальных роботов. Потому что этот уровень уже начинает приближаться к реальной конкурентоспособности модели.
Третий уровень — это данные развертывания и данные о неудачах. Это крайне важный уровень, который часто возникает после фактического развертывания.
После развертывания робота в реальные рабочие сценарии в его реальной рабочей среде часто возникают различные случайные ситуации. Данные развертывания, генерируемые в реальных сценариях, будь то успешные или неудачные, чрезвычайно ценны. Их редко можно встретить при предварительном сборе данных, их трудно спроектировать заранее, их можно накапливать лишь постепенно в реальной среде.
Более того, многим компаниям также трудно массово развернуть своих роботов в реальных сценариях, поэтому о реальных данных развертывания и речи быть не может.
В процессе развертывания робот постоянно накапливает данные в изменчивой среде. Даже данные о неудачах помогают команде целенаправленно выявлять причины и принимать меры, чтобы оптимизировать модель и тем самым способствовать масштабному внедрению роботов.
Это ключевые данные ведущих компаний-роботостроителей, это их барьер, отличающий их от конкурентов.
Это в определенной степени также ограничивает потолок для компаний, работающих с данными. Они могут помочь роботу «войти в курс дела», но данные, которые действительно определяют пределы его возможностей, многие ведущие компании в итоге предпочтут контролировать сами.
Поэтому две разные траектории, на которые разделилась индустрия данных, также прослеживаются: одна — это фабрики данных, другая — это движки данных.
Фабрики данных — это тип компаний, который в настоящее время появляется быстрее всего, их больше всего, и им легче создать денежный поток.
Среди них фабрики данных с низкими затратами больше ориентированы на данные о человеческом поведении, полагаются на преимущества дешевой рабочей силы, взимают плату почасово, стремятся к масштабу и способности к поставкам. Денежный поток может быстро стать положительным, но барьеры ограничены. Конкуренты, входящие на рынок, быстро увеличиваются, особенно после EgoScale, множество стартапов начали заполнять сферу человеческих данных.
Более сложные фабрики данных, помимо данных о человеческом поведении, массово развертывают роботов, собирая данные от реальных роботов путем телеуправления или автономной работы.
Другая траектория пытается создать движок данных: систематизировать классификацию задач, строить структуры данных, реализовывать перенаправление движений, подключать симуляционные платформы, внедрять оценку моделей и, опираясь на неудачные образцы моделей, итеративно производить обратные наборы данных.
Другими словами, они делают не просто продажу данных, а акцент на том, чтобы дать роботу возможность постоянно становиться умнее.
Появится ли Scale AI для роботов?
Если поместить сегодняшнюю робототехническую отрасль обратно в контекст больших моделей 2022 года, ощущается некое сходство.
Тогда отрасль также обнаружила, что то, что действительно определяет пределы возможностей модели, — это данные.
Поэтому вокруг областей очистки данных, RLHF, оценки, посттренинга также начали быстро подниматься новые компании. Самым классическим примером является Scale AI.
На раннем этапе эта компания помогала компаниям по беспилотным автомобилям аннотировать данные. Начиная с 2019 года, Scale AI на этапе GPT-2 глубоко интегрировалась с OpenAI, взяв на себя аннотацию обратной связи от людей (RLHF), оценку больших моделей, тестирование красной команды, обратное создание данных на основе крайних случаев.
После взрывной популярности ChatGPT, Meta Llama, Anthropic, Microsoft Azure и другие быстро подключились. Спрос больших моделей на высококачественную аннотацию, оценку, синтетические данные резко вырос, выручка этой компании за 3 года выросла более чем в 4 раза.
Позже эта компания также начала постепенно переходить на более глубокий уровень инфраструктуры: управление данными, оценка моделей, рабочие процессы ИИ.
Из-за успешного опыта Scale AI многие также задаются вопросом: появится ли в робототехнической отрасли подобная компания?
Судя по текущей степени дефицита данных, вполне возможно. Но и не полностью скопируется.
Потому что данные, необходимые роботам, гораздо сложнее текстовых. Для больших моделей относительно легко судить, правильный ответ или нет. Но в мире роботов успешность действия часто полна неопределенности.
Чашка поднята, но под неправильным углом. Вещь убрана на место, но задела другие предметы. Более того, часто само выполнение задачи допускает несколько правильных путей.
Поэтому робототехнической отрасли реально нужна не простая платформа данных, а целый замкнутый цикл данных: сбор, аннотирование, сопоставление движений, расширение через симуляцию, оценка моделей, обратная связь по неудачам.
Роботам реально не хватает не только данных. Способность постоянно производить эффективный опыт более дефицитна.
Поэтому все больше компаний начинают переносить фокус конкуренции с самого робота, архитектуры модели на систему данных.
С этого года, будь то Figure, 1X, PI или подход GR00T, продвигаемый NVIDIA, все неоднократно подчеркивают общее направление: рост способностей роботов — это лишь частично аппаратные улучшения, больше данных и более эффективное обучение становятся главными героями.
В определенном смысле, после начала этапа серийного производства и внедрения в робототехнической отрасли все переходят от «создания машины» к новому периоду «кормления машины».
На этапе, когда робот еще не может встать и ходить, главным конкурентным преимуществом компании в области воплощенного интеллекта является возможность хорошо сделать аппаратное обеспечение и управление движением.
Но когда робот может бегать и прыгать, а его результаты во многих соревнованиях превосходят человеческие, способность к автономной работе становится самой большой целью отрасли. Под влиянием этой цели главной темой отрасли становятся данные высокого качества в больших масштабах.
Чтобы робот мог постоянно преуспевать в сложном реальном мире, ему нужно «видеть» достаточно задач, реально существующих в физическом пространстве, знать, что чашка может разбиться, одежда может запутаться, места может не хватить. Этот опыт не существует естественным образом в интернете, его можно только постепенно производить.
Поэтому эта цепочка данных также тихо сформировалась на фоне бума робототехники последних двух лет.
На одном конце цепочки — люди в индийских фабриках с камерами на головах, роботы, постоянно падающие в симуляциях.
На другом конце — компании-роботостроители стоимостью в десятки, сотни и даже тысячи миллиардов, которые пытаются сделать так, чтобы роботы действительно вошли в дома и на фабрики.
От индийских фабрик данных и роботов в симуляциях до крупнейших робототехнических компаний мира начала формироваться новая производственная цепь. Только на этот раз производится не комплектующие, а данные.
Эта статья из WeChat Official Account: 42-я Волна , автор: Ланьбо, редактор: Джеймс, оригинальное название: «Роботы начинают "поедать данные": от индийских фабрик данных до тайной производственной цепи роботов-гуманоидов стоимостью в десятки миллиардов долларов»





