Краткое содержание:
Схема, которая разбивает примерно 20 долларов США ежемесячной платы за Claude Pro на модельную компанию, облачные вычисления, амортизацию GPU, электроэнергию и цепочку поставок, заставляет инвесторов вновь обсуждать, как следует оценивать доходы от AI-приложений.
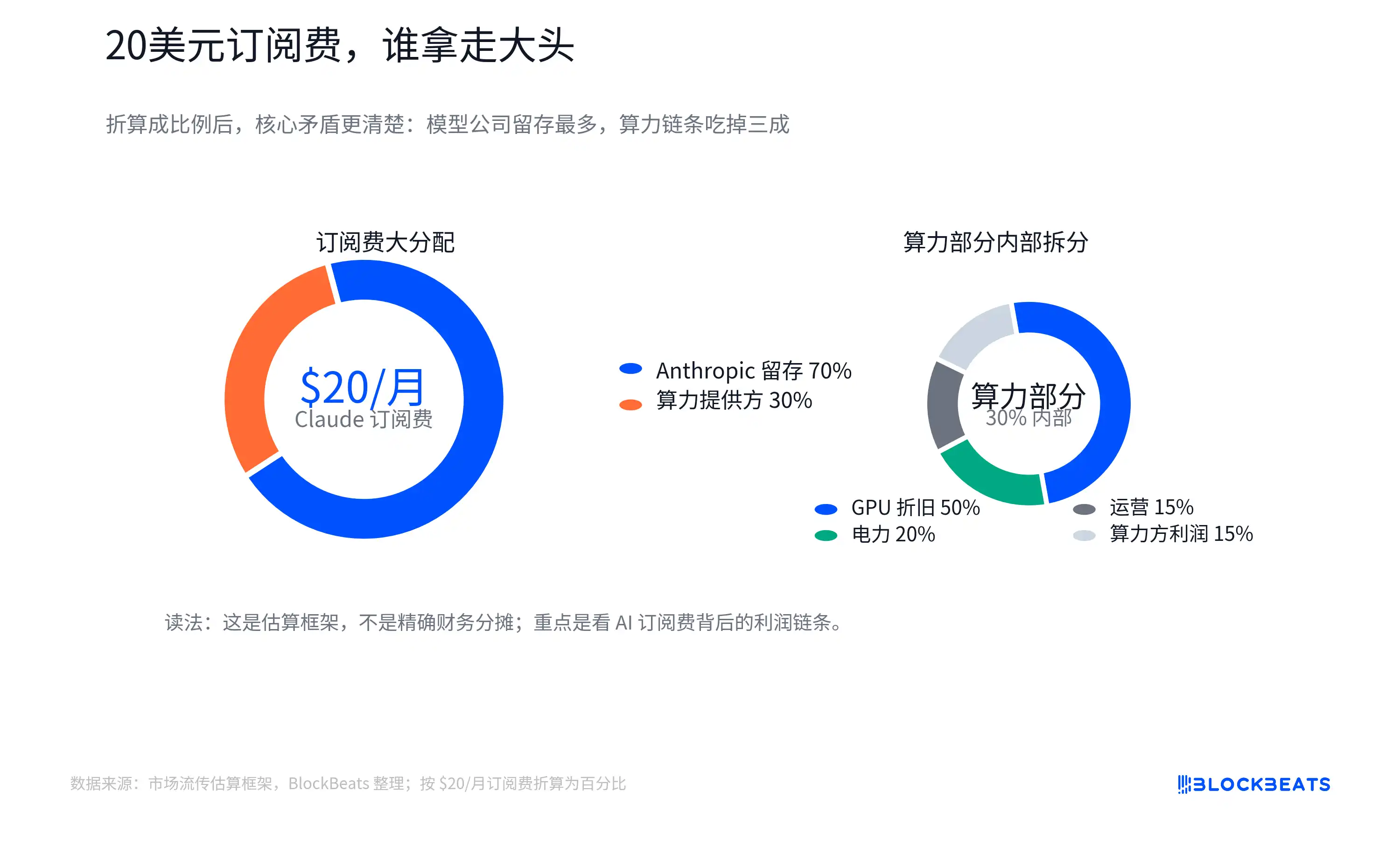
Эта схема не является официальными данными о распределении доходов от Anthropic, Amazon Web Services или NVIDIA и не может рассматриваться как реальный финансовый отчет какой-либо компании. Ее ценность заключается в том, что она поднимает более фундаментальный вопрос: какая часть подписной платы пользователей за AI-приложения может превратиться в валовую прибыль от программного обеспечения, как в традиционном SaaS?
Логика оценки традиционного SaaS ясна. После того как программное обеспечение написано, продажа дополнительной учетной записи обычно несет невысокие дополнительные затраты. Зрелые компании, занимающиеся чистым ПО, часто имеют валовую маржу на уровне 70% или даже выше 80%. Инвесторы готовы давать высокие мультипликаторы, потому что с ростом масштаба доходов рентабельность имеет возможность продолжать расти.
Проблема с AI-приложениями заключается в том, что каждый запрос пользователя, написание кода, анализ файла или вызов агента потребляют время GPU, электроэнергию, пропускную способность памяти и облачные ресурсы. На поверхности – фиксированная ежемесячная плата, в основе же – цепочка затрат, меняющаяся в зависимости от интенсивности использования. Легкие пользователи могут приносить высокую маржу, но при интенсивном использовании в рамках доступного лимита или пакета инструментов, когда задачи выполняются непрерывно, затраты могут быстро возрасти.
Таким образом, схема разбивки 20 долларов бросает вызов не тому, сколько долларов получает конкретная компания, а самому утверждению, что «доход от AI-приложений по своей природе равен доходу от SaaS». Чтобы доказать свою высокую стоимость, AI-компании должны продемонстрировать не только готовность пользователей платить, но и то, что валовая маржа, взвешенная по интенсивности использования, может постоянно улучшаться.
За подписной платой скрывается цепочка затрат на инференс
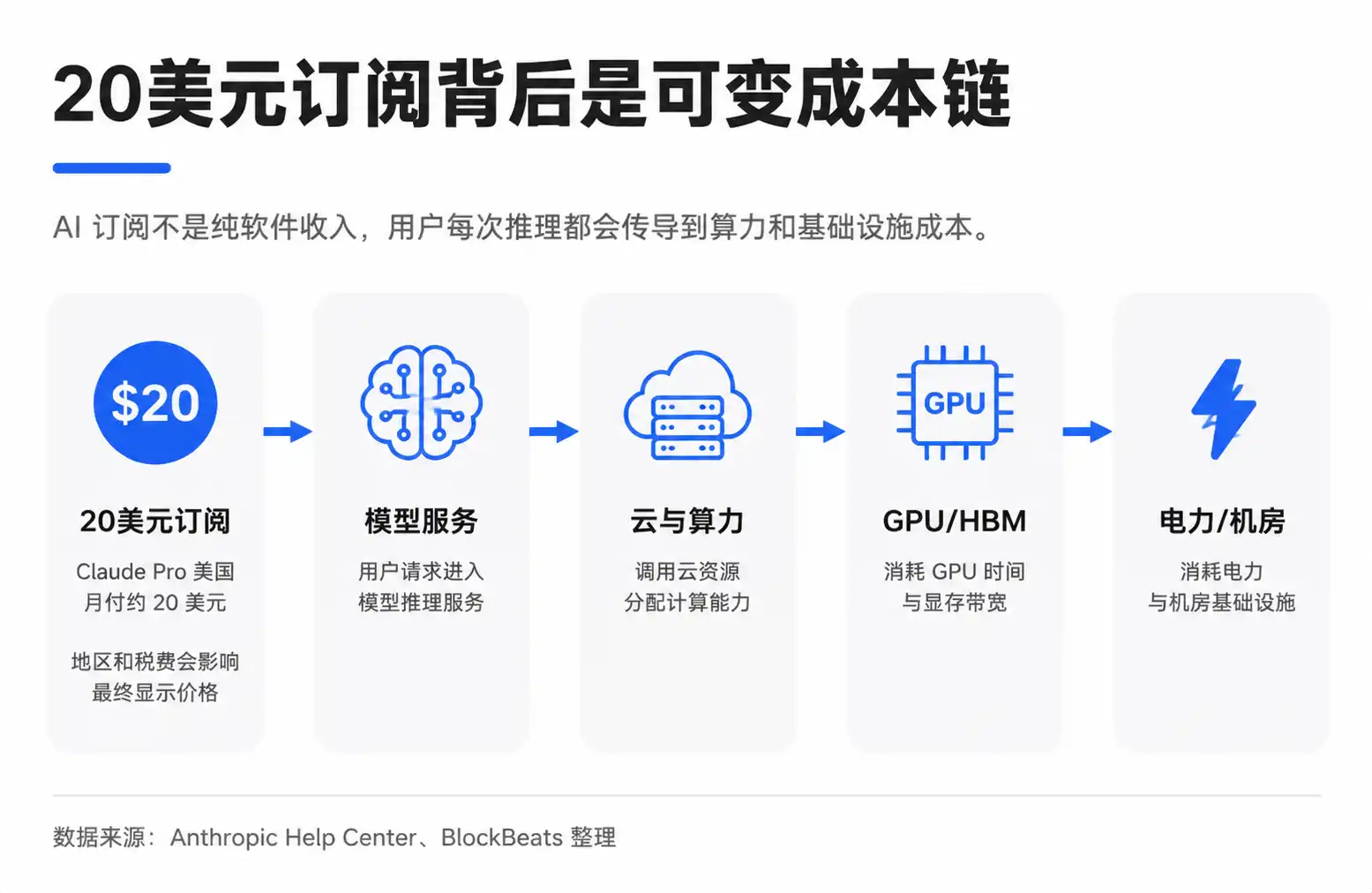
Самое большое отличие AI-подписки от обычной программной подписки заключается в том, что «предельные затраты на одно использование» больше не близки к нулю.
В традиционном SaaS, когда команда открывает дополнительную учетную запись, у поставщика услуг также возникают затраты на серверы, поддержку клиентов и пропускную способность, но эти затраты обычно не растут линейно с каждым кликом. Настоящие дорогие затраты – это первоначальные расходы на разработку, продажи и привлечение клиентов. После масштабирования продукта значительная часть дополнительного дохода может оставаться у компании.
С продуктами на основе больших языковых моделей все иначе. Пользователь вводит вопрос, модель генерирует ответ – этот процесс называется инференсом, т.е. фактическими вычислениями при вызове модели пользователем. Токен – это базовая единица измерения для чтения и записи текста моделью. Чем больше пользователь спрашивает, чем длиннее контекст и сложнее генерируемый контент, тем больше токенов и вычислительных ресурсов потребляется.
Так возникает противоречие между фиксированной подпиской и переменными затратами. Ежемесячная плата за Claude Pro в США составляет примерно 20 долларов (цена может варьироваться в зависимости от региона, налогов и корректировок Anthropic). Пользователь видит фиксированную цену, в то время как модельная компания сталкивается с совершенно разным поведением пользователей: одни просто пишут письма и ищут информацию, другие обрабатывают длинные документы, запускают задачи по коду или используют более сложные автоматизированные процессы.
Схема разбивки, циркулирующая на рынке, пытается визуализировать это: из 20 долларов часть остается у модельной компании, часть идет поставщикам облачных и вычислительных услуг. Затраты на вычисления включают электроэнергию, обслуживание, амортизацию GPU. Закупка GPU, в свою очередь, направляет средства вверх по цепочке к NVIDIA, TSMC, поставщикам HBM (памяти высокой пропускной способности), производителям оптических модулей, ODM-компаниям и предприятиям, связанным с электроэнергией.
Здесь «амортизация GPU» можно понимать как то, что дорогостоящие GPU не списываются единовременно, а постепенно распределяются на стоимость AI-услуг в течение срока службы, интенсивности использования или в соответствии с бухгалтерскими стандартами. Фактическое распределение будет зависеть от лимитов тарифных планов, соотношения легких и активных пользователей, внутренних цен расчетов между облачными провайдерами, скидок на резервированные мощности, коэффициента использования GPU и срока амортизации. Средние затраты также не равны предельным затратам.
Инвесторам на самом деле нужно следить за тенденцией: AI-компаниям на уровне приложений недостаточно раскрывать только рост доходов, они также должны отвечать на вопрос, растут ли пропорционально затраты на вычислительные мощности. Если объем использования растет быстрее, чем эффективность моделей, чем выше доход от подписок, тем более заметным может стать давление на валовую прибыль. Только если повышение эффективности будет достаточно быстрым, у модельных компаний появится шанс вновь приблизиться к структуре прибыли программных компаний.
Инфраструктура получает более определенный доход уже сейчас
На данном этапе рост использования AI более непосредственно направляется в инфраструктуру, а не полностью оседает на уровне приложений.
Независимо от того, используют ли пользователи модель в Claude, ChatGPT, Gemini или корпоративных агентах, инференс в конечном итоге требует вычислительных мощностей, электроэнергии, памяти и сети. На уровне приложений может происходить смена продуктов, в то время как потребление базовых ресурсов более жесткое. Пока использование AI продолжает расти, будут расти и капитальные расходы на облачные сервисы, закупки GPU, спрос на HBM и потребление электроэнергии центрами обработки данных.
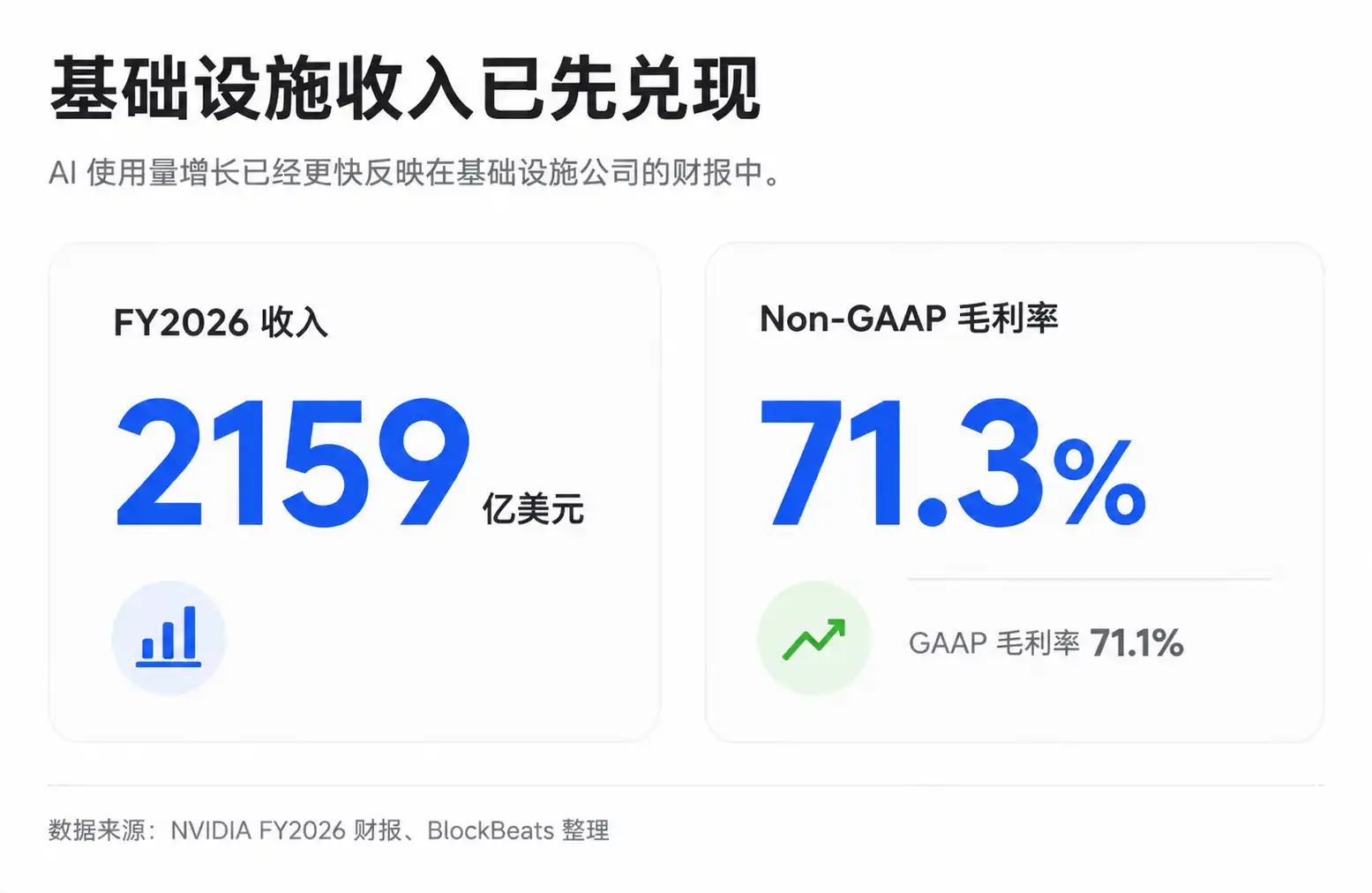
Это также является причиной продолжающейся переоценки рынком цепочки инфраструктуры, включающей NVIDIA, TSMC, SK Hynix и других. Общая валовая маржа NVIDIA в последние годы остается на высоком уровне: по GAAP и non-GAAP за 2026 финансовый год она составила около 71,1% и 71,3% соответственно, прогнозы на последующие кварталы также остаются высокими. Стоит отметить, что отдельные кварталы могут подвергаться влиянию специфических расходов, а открытая финансовая отчетность не всегда позволяет напрямую разложить реальную структуру маржи центров обработки данных AI, но тот факт, что дефицитная инфраструктура обладает ценообразовательной властью, уже отражен в результатах.
HBM является наиболее типичным звеном в этой цепочке. Это не обычная память, а ключевой компонент в AI-ускорителях, поддерживающий вычисления с высокой пропускной способностью. С ростом масштаба моделей, длины контекста и потребности в параллельном инференсе зависимость AI-чипов от памяти с высокой пропускной способностью усиливается. Оценки цепочки поставок показывают, что доля HBM в стоимости AI-чипов нового поколения возрастает, что также является важной причиной переоценки SK Hynix, Samsung, Micron в рамках AI-цикла.
Электроэнергия и центры обработки данных также превратились из фоновых затрат в основное направление инвестиций. Энергопотребление одного обычного текстового запроса может быть не столь значительным, но сложные агенты, длинный контекст, генерация кода и многоуровневые задачи увеличивают объем вычислений. Для облачных провайдеров и операторов ЦОД ключевым моментом является не то, сколько электроэнергии потребляет один запрос, а то, что при непрерывном возникновении огромного количества запросов на инференс, коэффициент использования кластеров, цена на электроэнергию, охлаждение, емкость дата-центра и возможности подключения к электросети становятся факторами затрат и узкими местами.
Преимущество инфраструктурного сегмента заключается в более быстрой верификации результатов. Капитальные расходы на AI облачных провайдеров уже имеют место, доходы и валовая маржа NVIDIA отражены в финансовой отчетности, заказы и цены производителей HBM также относительно быстро попадают в отчеты о прибылях и убытках. На уровне модельных приложений торгуются в основном будущие ожидания: конверсия в подписки, уровень проникновения в корпоративный сектор, доходы от API и высвобождение прибыли после снижения будущей кривой затрат.
Повышение эффективности остается основным аргументом «быков»
У инвесторов в ПО и сторонников AI («быков») тоже есть контраргументы. Основная идея сторонников эффективности заключается в том, что высокая стоимость инференса сегодня – это лишь явление ранней стадии. Оптимизация моделей, кэширование, небольшие модели, собственные чипы и более высокий коэффициент использования кластеров будут постоянно снижать удельную стоимость. Если затраты будут снижаться достаточно быстро, AI-приложения могут вернуться к логике ПО с высокой маржой.
У этого контраргумента есть реальная основа. Стоимость за токен для некоторых основных моделей при сопоставимых или более высоких возможностях уже значительно снизилась. OpenAI сообщала, что стоимость GPT-4o mini за токен снизилась на 99% по сравнению с ранней text-davinci-003. Темпы у разных компаний не полностью совпадают; недавние действия Anthropic больше проявлялись в виде обновлений по той же цене и стратификации моделей, но отраслевой тренд по-прежнему заключается в предоставлении более мощных возможностей по более низкой стоимости.

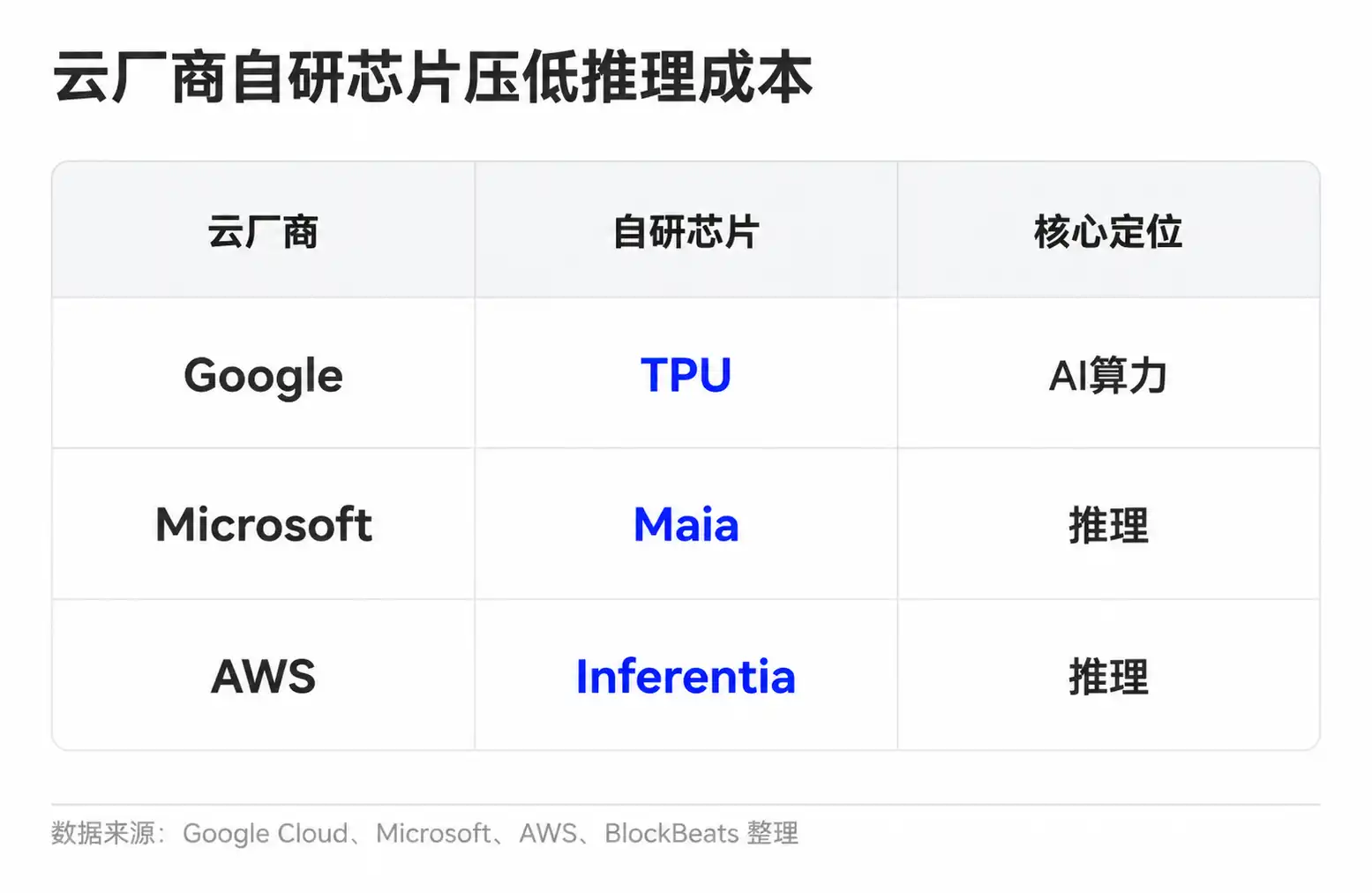
У модельных компаний также есть несколько способов улучшить удельную экономику. Простые задачи можно поручить небольшим моделям, часто встречающиеся запросы можно повторно использовать через кэш, длинный контекст и сложные задачи – более мощным моделям. Облачные провайдеры, в свою очередь, снижают удельную стоимость вычислений за счет собственных чипов и планирования кластеров. У Google есть TPU, Microsoft представила Maia для инференса, Amazon также продвигает Trainium и Inferentia.
Если рассматривать только технологический прогресс, у рентабельности AI-приложений действительно есть потенциал для улучшения. Более дешевый инференс, лучшая маршрутизация моделей, более мощные возможности сжатия – все это может позволить той же подписке за 20 долларов выдерживать больший объем использования. Легкие пользователи, дорогие корпоративные тарифы, многоуровневое ценообразование API и более строгие лимиты использования также могут улучшить общую удельную экономику.
Сложность заключается в том, что снижение затрат – не единственная переменная. AI-приложения переходят от простого чата к более ресурсоемким рабочим нагрузкам. Раньше пользователи могли только задавать вопросы и переписывать текст, сейчас все больше запросов связано с код-агентами, обработкой длинных документов, генерацией видео и мультимодального контента, корпоративными автоматизированными процессами. Эти сценарии имеют более высокую ценность, но и потребляют больше ресурсов. Чем полезнее модель, тем с большей вероятностью пользователи будут поручать ей более сложные и длительные задачи.
Таким образом, расхождения становятся более конкретными: сможет ли скорость снижения затрат на инференс опередить рост объема использования и сложности задач. Если удельная стоимость снижается быстро, но среднее потребление пользователей растет еще быстрее, взвешенная валовая маржа модельных компаний по-прежнему будет испытывать давление. И наоборот, если маршрутизация моделей, кэширование, собственные чипы и ценовое расслоение окажутся достаточно эффективными, AI-подписка может постепенно избавиться от сегодняшних характеристик высоких затрат.
Количество подписчиков – это не валовая маржа
Схему разбивки 20 долларов не следует понимать как конечный результат. Скорее, это напоминание об оценке на текущем этапе: пока рынок не видит достаточно прозрачных данных о валовой марже модельных компаний, инвесторам нужно скидывать с предположения, что «AI-приложения по своей природе равны SaaS».
Для таких непубличных модельных компаний, как OpenAI, Anthropic, внешним инвесторам сложно увидеть полную финансовую картину. Материалы по привлечению финансирования, раскрытие информации партнерами, структура облачных затрат, цены на корпоративные тарифы, доля доходов от API и ограничения использования станут ключами для оценки. Ценными данными являются не количество платящих пользователей, а пропорция легких и активных пользователей, готовность корпоративных клиентов платить более высокую цену за интенсивное использование, снижаются ли затраты на облачные расчеты, а также находит ли снижение удельных затрат на инференс отражение в валовой марже компаний.
Верификация по публичным компаниям в цепочке быстрее появится в финансовой отчетности. Общая валовая маржа NVIDIA и темпы роста доходов от центров обработки данных, спрос на передовые технологические процессы и упаковку TSMC, цены и рентабельность производителей HBM, интенсивность капитальных расходов облачных провайдеров – все это продолжит отражать, передается ли рост использования AI на инфраструктурный уровень. Если эти показатели останутся сильными, а на уровне модельных приложений будет не хватать доказательств улучшения маржи, рынок продолжит давать инфраструктуре более определенную премию к оценке.
В конечном счете, чтобы вернуть более высокую точку привязки оценки, модельным компаниям нужно доказать не только то, что пользователи готовы платить 20 долларов, но и то, что после интенсивного использования от этих подписных платежей остается достаточно высокой валовой прибыли. Следующий раунд разногласий по оценкам, вероятно, будет связан не с громкими цифрами ARR (ежегодного регулярного дохода), а с тем, смогут ли одновременно быть успешными затраты на инференс, ограничения тарифных планов и цены на корпоративные подписки.





