Original | Odaily Planet Daily (@OdailyChina)
Author | DingDang (@XiaMiPP)

Last week, the statement from the founder of OpenClaw advising young people "not to waste time on cryptocurrency" stung the crypto industry. This week, however, the situation took a subtle turn. In the official OpenClaw documentation, an encrypted project with a native token, Venice.ai, was quietly listed as a recommended model provider. Over the past month, the price of Venice's native token VVV has also risen from a low of around $1.5 to a high of around $8.4, with a maximum increase of over 500%.
On one hand, there's discouragement; on the other, integration. Why did OpenClaw specifically push a project with an encrypted token economic structure to the forefront?
Venice's Origins: What Happens When a Crypto OG Does AI?
To understand Venice, one must first understand OpenClaw's positioning. It is an open-source, self-hosted AI agent platform that can integrate into chat software, becoming a user's 24/7 personal assistant, helping with tasks like sending and receiving emails and managing calendars. However, OpenClaw itself does not provide AI large language model (LLM) capabilities; it is merely an "execution and routing layer." The actual intelligence (thinking, planning, generating responses) must come from external model providers.
Venice is a generative AI platform focused on privacy and censorship resistance, positioning itself as a decentralized version of ChatGPT. The project launched in May 2024 but has not undergone any financing rounds, no VC funding, and was entirely personally funded and started by its founder, Erik Voorhees.
Erik Voorhees himself is a crypto old guard (OG), entering the crypto space in 2011. After the collapse of Mt. Gox in 2014, he founded ShapeShift, one of the first trading platforms to emphasize non-custodial and privacy-first principles. In 2021, he chose to transition ShapeShift to DAO governance, completing its decentralization. His career trajectory seems to revolve around "reducing reliance on trust in centralized structures."
Another core team member is Teana Baker-Taylor, with an impressive resume having held executive roles in operations and compliance at HSBC, Circle, Binance, and Crypto.com. Most other members are either anonymous or keep a low profile. According to current public data, the Venice team has approximately 20 members.
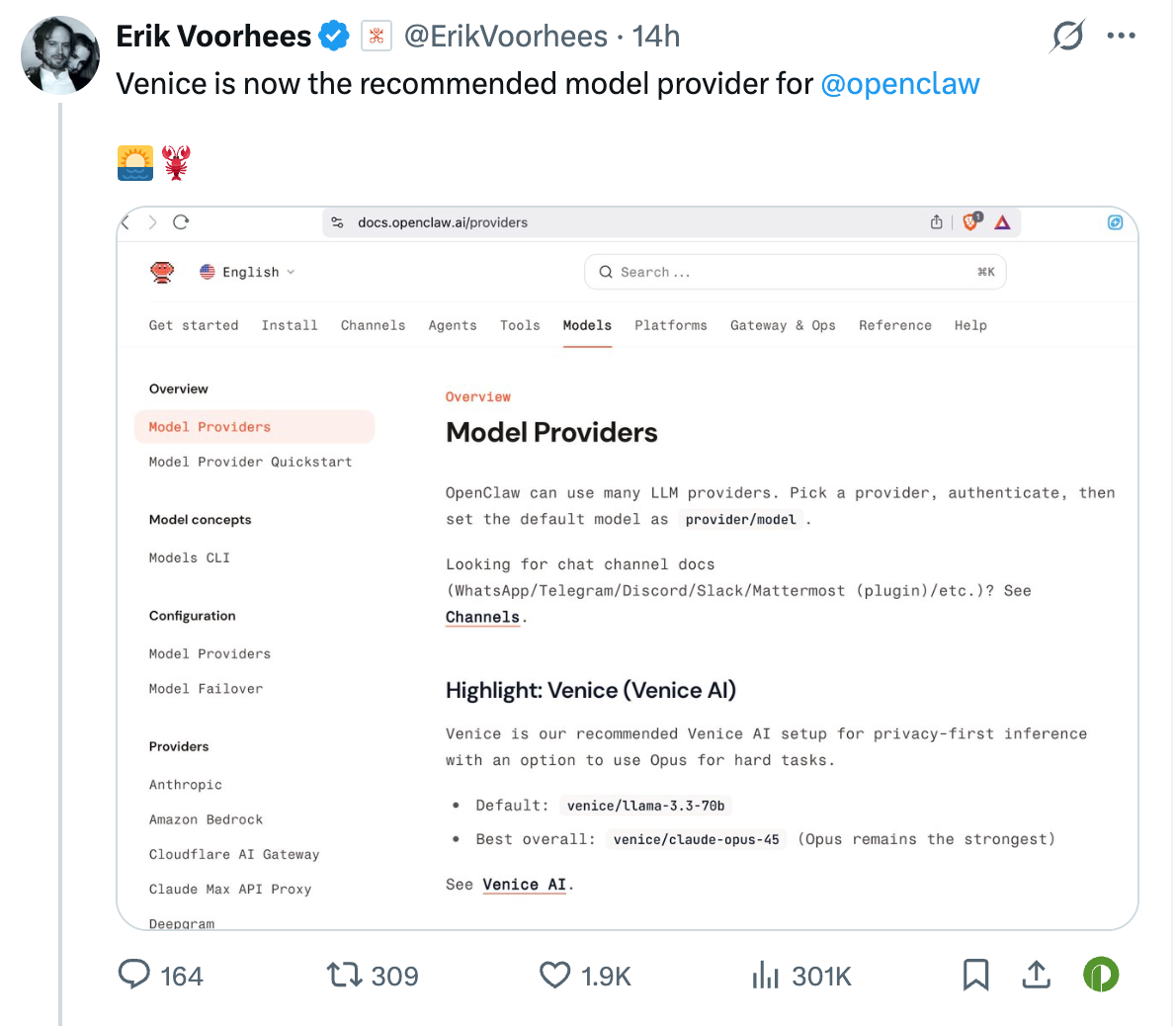
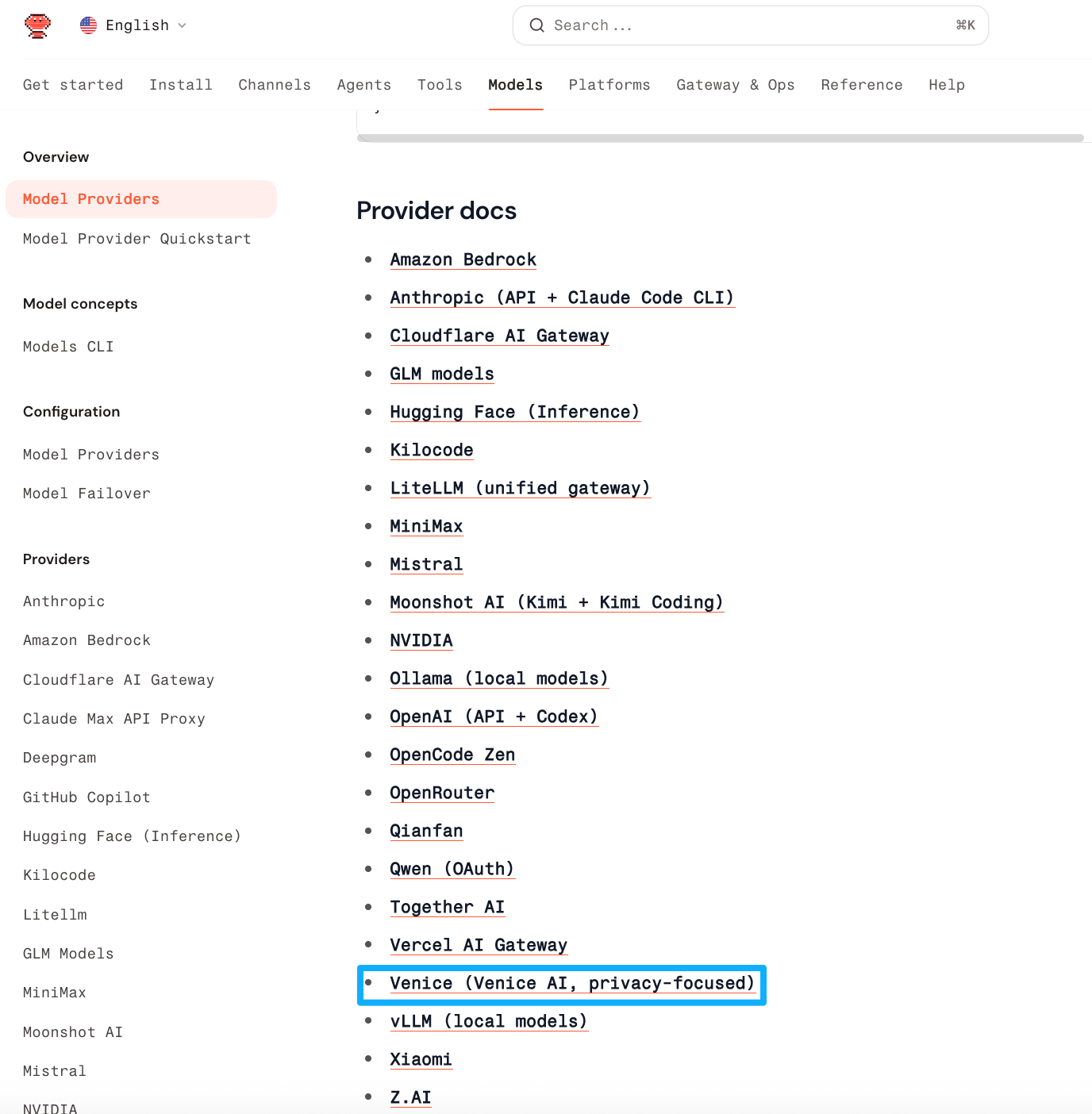
OpenClaw currently lists 22 model providers, including large tech companies like Amazon, Anthropic, and Cloudflare. In terms of size and brand, Venice is clearly not the most prominent one, and could even be considered the most inconspicuous. Yet, it was highlighted and recommended in the official documentation as a model provider with a native token economy. However, this might have been a merge operation error in the docs; the highlight has now been removed, but it had been on OpenClaw's list of model providers for some time.
Even so, why would OpenClaw choose a small, obscure company? The answer is simple: Privacy.
After all, alongside AI's great success, controversies surrounding data leaks and model training disputes continue to accumulate. Users are beginning to realize that the real risk is not whether the model is "smart," but whether data or information "will be leaked."
So, how exactly does Venice achieve its privacy? Its core philosophy is "You don’t have to protect what you do not have." Simply put, Venice does not store any user content—prompts, replies, generated images, uploaded documents—on any Venice servers at all. This data is only encrypted and saved locally in the user's own browser (or device). Once you clear your browser data or manually delete chat history, this content is permanently gone.
Venice also explicitly states that it does not use user data for model training, does not log, and does not analyze behavior. This stands in stark contrast to mainstream platforms (like OpenAI, Anthropic), which often store conversations long-term to improve models or for compliance reviews.
Furthermore, Venice distinguishes between two different levels of privacy modes: Private and Anonymized. The former is the highest privacy level, using open-source models that run on decentralized GPUs. During processing, no identity-related information is attached. The underlying compute nodes might briefly see the plaintext prompt, but Venice itself cannot see or access the user's history. The latter mode means the underlying provider can see the prompt content, but Venice strips all metadata (IP, account fingerprints, historical associations), making it impossible to trace back to the user.
So, although Venice isn't the most prominent name in the provider list, its privacy architecture made it the "privacy-first choice" specially highlighted in OpenClaw's documentation. Currently, OpenClaw's default model is Llama 3.3, but Erik himself suggested in a reply that users switch to the smarter GLM 4.6.
What does this mean for Venice itself?
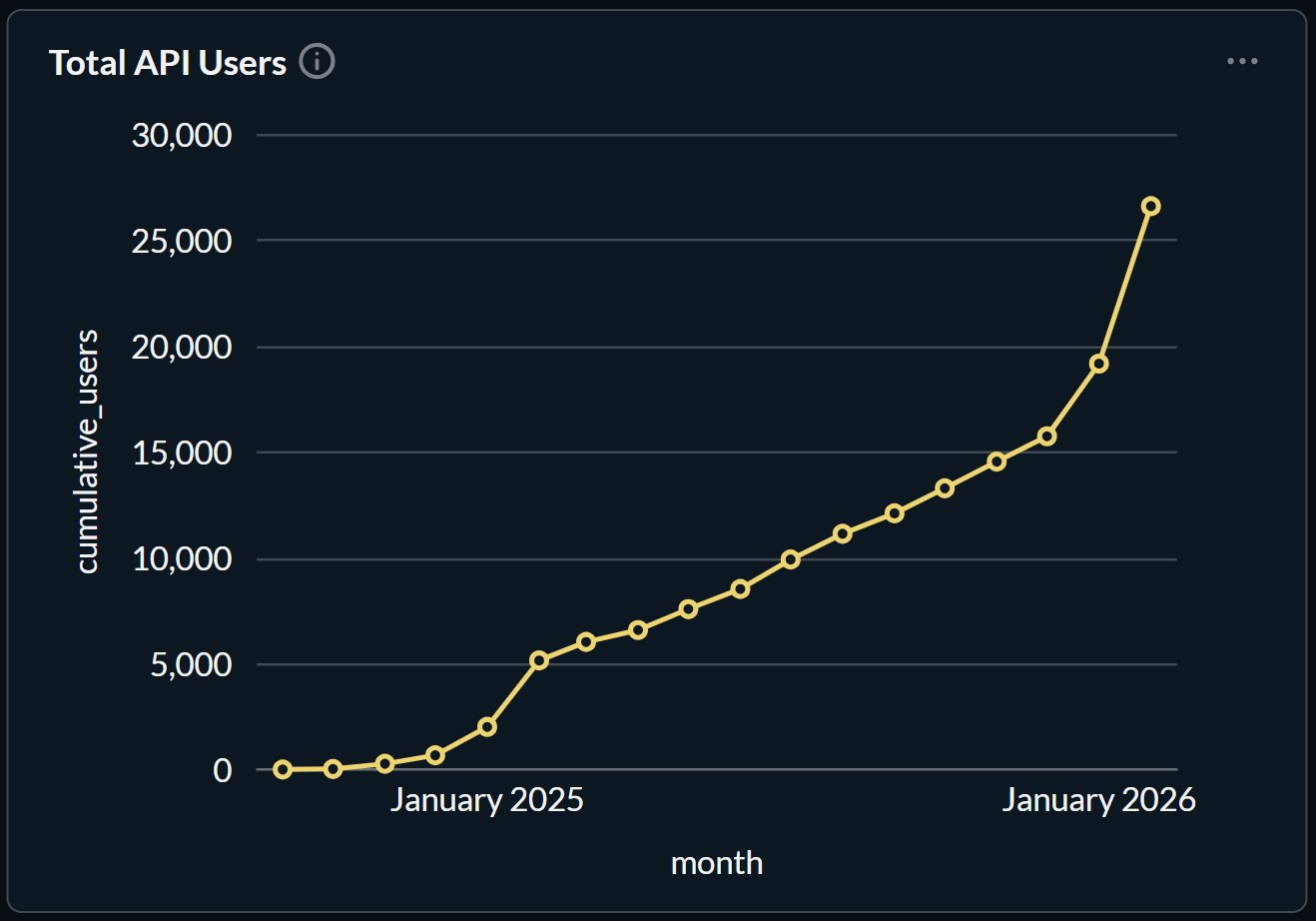
OpenClaw is currently experiencing viral growth, with its call volume entering an exponential growth phase. With OpenClaw's official endorsement, it might pull Venice's inference capacity requirements to a new level. This means Venice is undergoing a qualitative change. It is no longer just "an AI project with a crypto background," but is attempting to become the default privacy backend for the mainstream open-source Agent ecosystem.
According to the latest data Erik released on March 1st, since the beginning of 2026, the number of API users on Venice has begun to grow rapidly, currently exceeding 25,000 users.
Token Model: One-Time Investment, Lifetime Compute Power
As a crypto project, can its token economy handle this level of traffic growth?
Within the Venice ecosystem, there are two core tokens: VVV and DIEM. They are tightly bound through a "one-way minting + reversible redemption" mechanism, forming a two-tier economic structure.
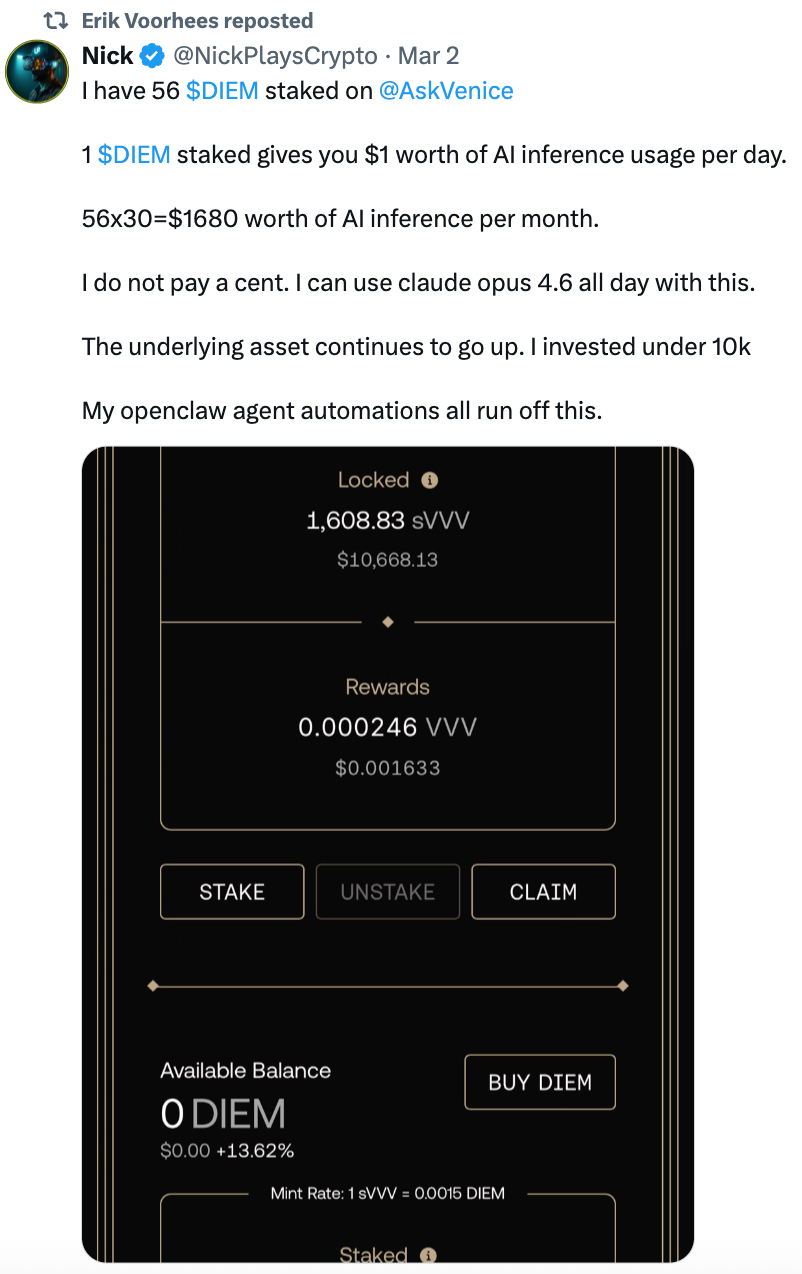
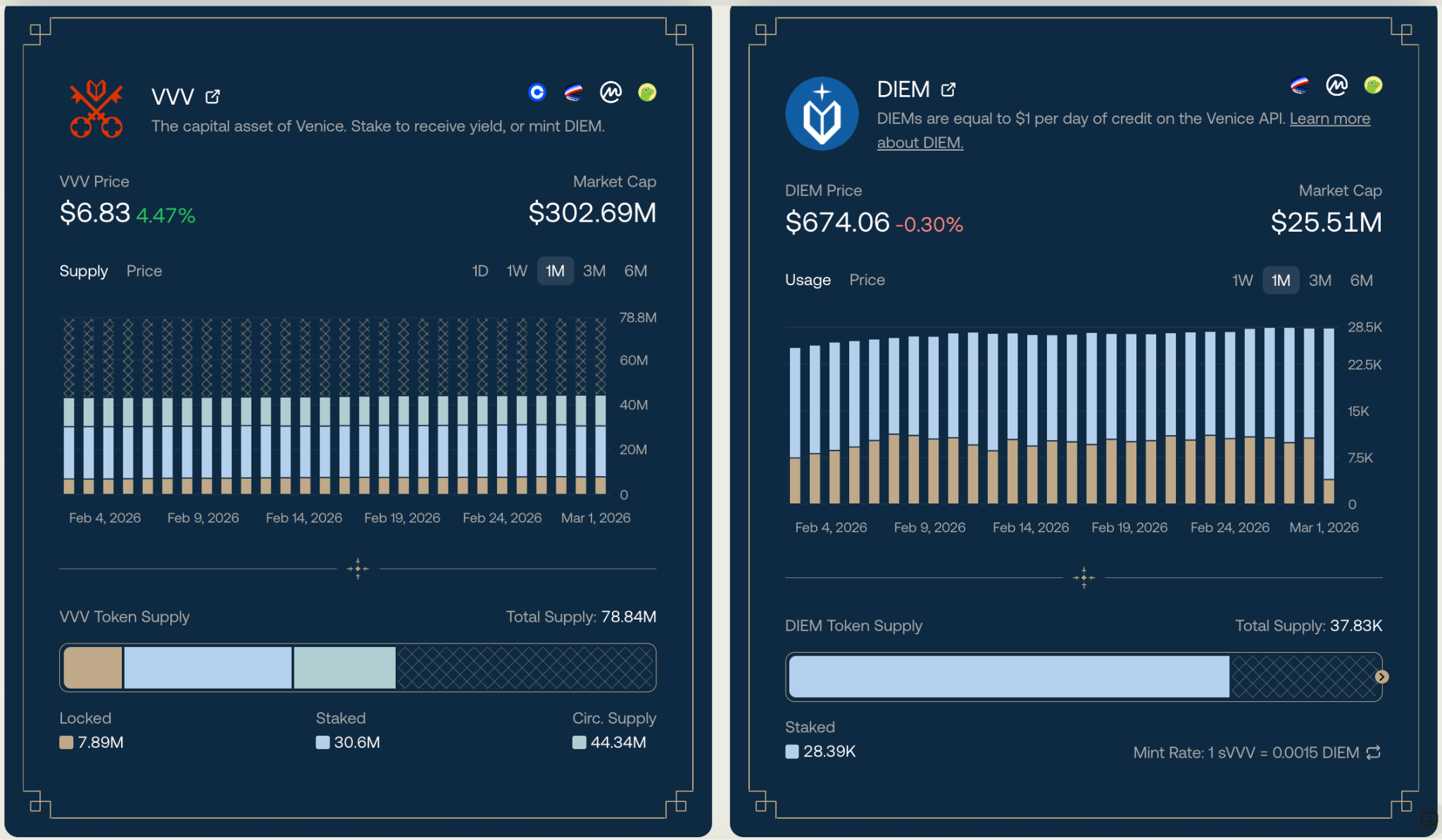
VVV is the capital asset of the entire ecosystem, which can be held directly or staked. Staking VVV yields continuous staking rewards, currently around 19% APY. Another key function of VVV is to mint DIEM, and it is the only way DIEM is generated.
After minting, DIEM can be traded on secondary markets, such as on DEXs like Aerodrome or Uniswap. Or it can be staked to activate spending credit. DIEM represents an ownable, perpetual AI computing asset. 1 DIEM = $1 per day of Venice API credit, used to call all of Venice's models (text generation, image/video generation, code, etc.), including the highest privacy, uncensored models in Private mode. This credit is permanently valid and automatically renewed daily during your staking period, effectively acting as a permanent AI subscription voucher.
The concept of $1 credit is abstract. Within the Venice ecosystem, it's not a fixed "number of tokens" but the ability to consume $1 worth of inference resources. The more expensive the model, the less content you generate; the cheaper the model, the more content you generate. This abstracted pricing makes DIEM a kind of "compute power share voucher." I asked Venice's AI to quantify what 1 DIEM credit can get me:

Because traditional AI APIs are pay-per-use, costs can explode exponentially for high-frequency, long-term, automated tasks (like an AI Agent making hundreds or thousands of calls per day). However, Venice, through DIEM, completely颠覆s this into a one-time investment for long-term fixed quotas. Currently, 1 DIEM is worth approximately $670. Once staked, it automatically grants $1 worth of API credit per day. To easily compare whether buying DIEM is more cost-effective than traditional pay-per-use, I used Grok to generate a rough table:
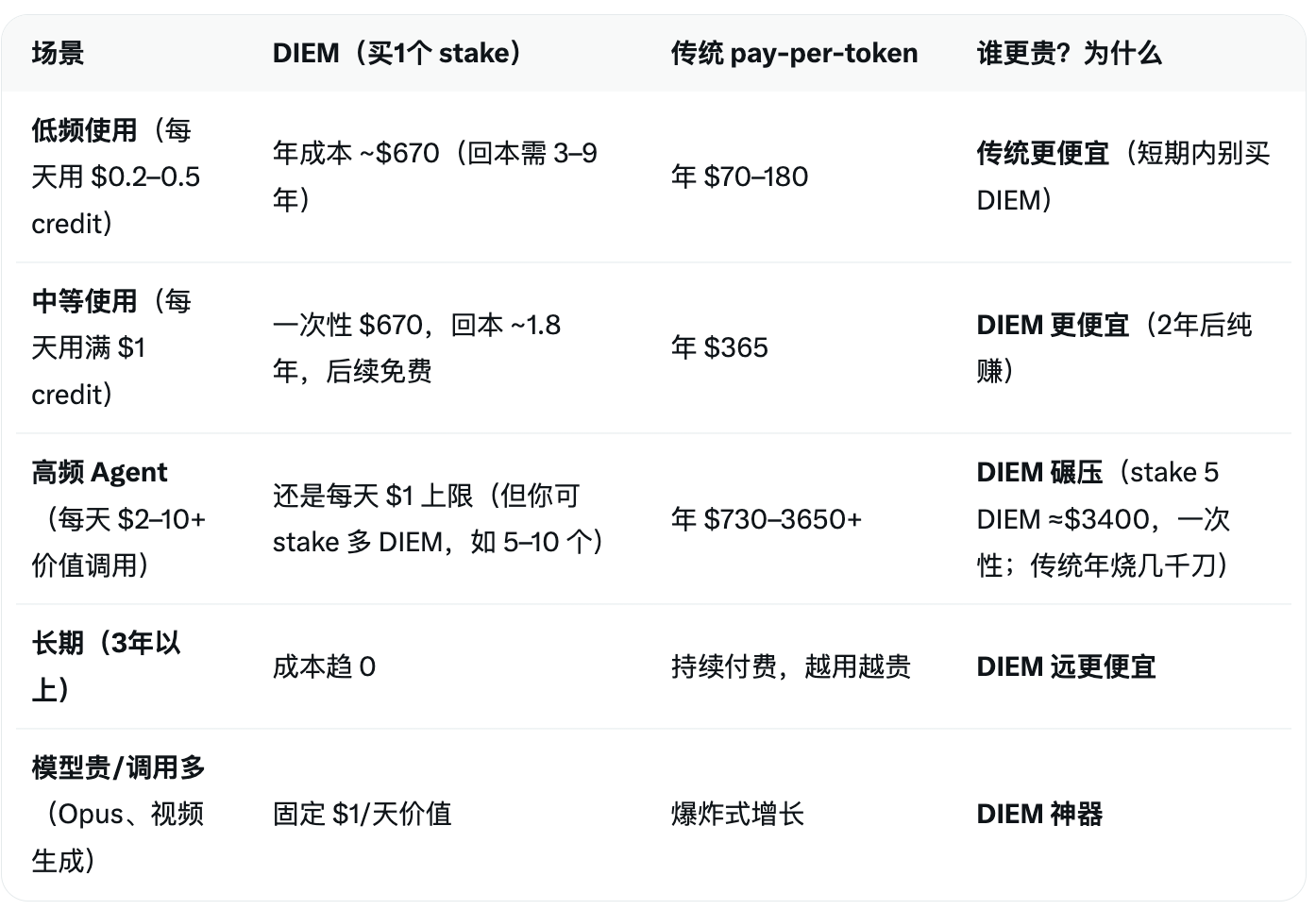
Based on the data above, for low-frequency users, there is no need to purchase DIEM at all. For medium to high-frequency users who need to run Agents daily and generate large amounts of content, the marginal cost decreases continuously with long-term use, giving DIEM a clear advantage.
Some users have already come forward to share their experiences. One user stated that staking 56 DIEM allows them to use the Claude Opus 4.6 model all day, with the principal cost being less than $10,000.
Moreover, community users have already developed a credit rental market (cheaptokens.ai) where unused credit can be sold. An ecosystem market around Venice's compute power is萌芽ing.
Overall, the core of Venice's economic model lies in separating the "growth logic" from the "usage logic". VVV, as a pure growth asset, carries the platform's overall valuation narrative, directly benefiting from user growth, network effects, and ecosystem expansion—positive flywheel effects. DIEM, as a permanent subscription-based utility asset, truly serves product usage and value consumption, handling the consumption logic for daily interactions and task execution.
Based on current data performance, DIEM shows clear advantages in long-term, high-frequency, continuous task scenarios, highly aligned with the current Agent-driven intensive usage模式. This strong genuine demand can, in turn, effectively stimulate users' willingness to stake VVV, forming a positive closed loop from the usage end to the growth end.
Supply and Deflation: The Real Background of the Price Surge
According to data provided on the Venice website, the current total token supply is 78.84 million tokens. Of these, 7.89 million are locked, and the staked amount is 30.60 million, resulting in a staking rate of 38.8%. The circulating supply is only 44.34 million tokens. In the initial economic model, the total VVV token supply was 100 million, with 50% allocated for community airdrops, targeting early Venice users, AI project parties, etc. The airdrop claim window lasted about 45 days. Ultimately, over 40,000 people claimed 17.40 million VVV, accounting for about 35% of the community allocation. The remaining unclaimed portion was approximately 32.68 million tokens, worth about $100 million at the time. The team decided to permanently burn these to reduce circulating supply and enhance scarcity.
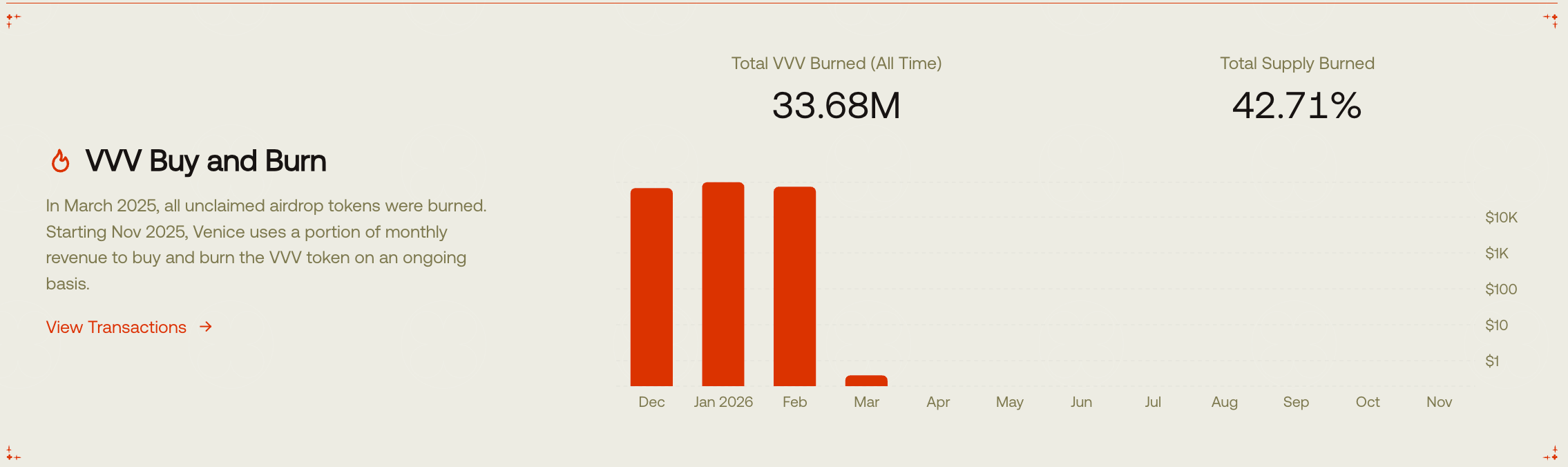
Starting in October 2025, Venice announced a reduction of the original emission plan from 10 million VVV/year to 8 million VVV/year. Simultaneously, it launched a monthly revenue buyback + burn mechanism. The current monthly burn capacity is 30,000 to 50,000 tokens, worth approximately $60,000 to $90,000. Currently, 42.71% of the token supply has been burned. Then, in early February 2026, the official announced another emission reduction plan, cutting from 8 million VVV/year to 6 million VVV/year. This series of adjustments directly changed the supply expectations. Looking at the token price performance, this was also the starting point for VVV's rise.
Therefore, the rise of VVV is not solely driven by narrative, but rather a combination of changed supply structure and growing demand.
Conclusion
As AI becomes the central narrative of the era, is Crypto really bowing out? Venice is trying to provide its own answer. If future intelligent agent systems require a privacy backend, if Agents need long-term stable compute structures, then perhaps the crypto logic hasn't disappeared after all.






