В последние дни небольшая модель на 3B стала хитом в X, потому что на некоторых сложных, но проверяемых задачах на рассуждение (например, программирование) она вошла в диапазон производительности передовых моделей, таких как Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, Kimi K2.5, при этом её размер значительно меньше, чем у этих моделей.

Эта модель называется VibeThinker-3B. Это плотная модель для рассуждений с 3 миллиардами параметров, цель которой — исследовать, насколько можно продвинуть проверяемую способность к рассуждению при строго ограниченном небольшом размере модели.
После публикации модели многие были поражены её результатами и выразили желание попробовать её в деле.


Стоит отметить, что это также отечественная модель от команды Weibo (Сина Вэйбо).
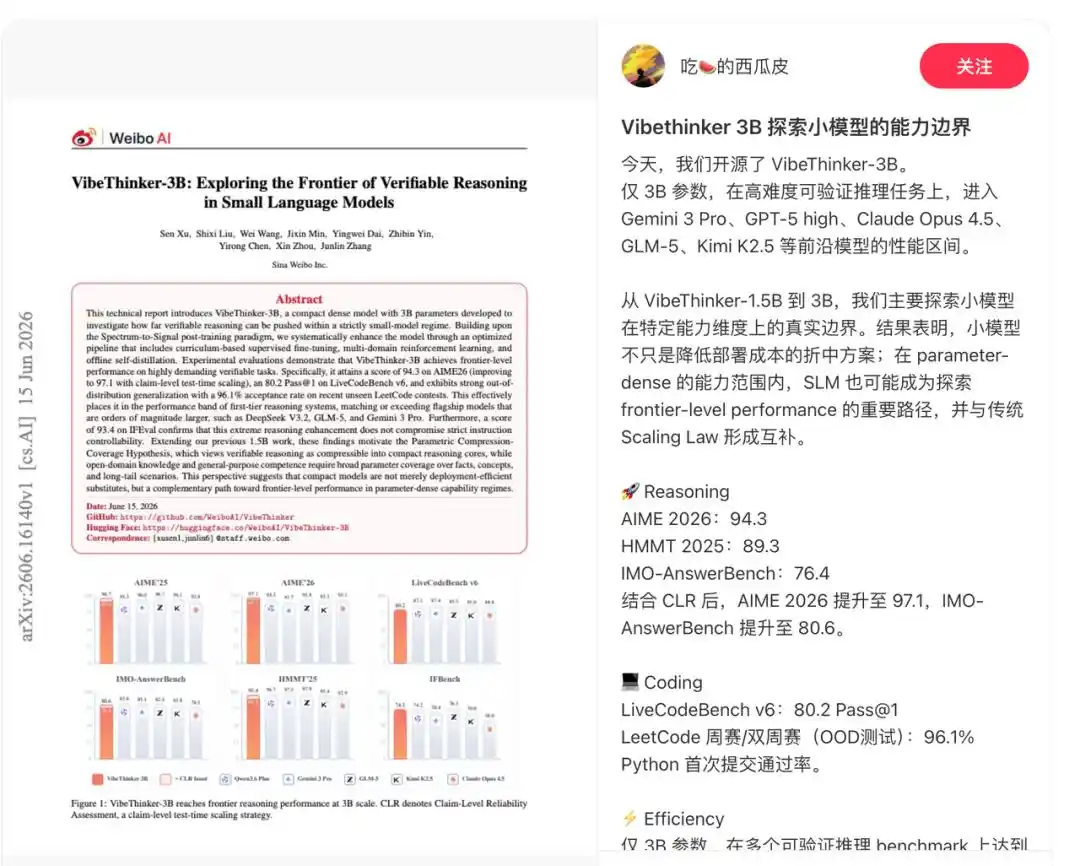
Технический отчёт показывает, что модель специально разработана для задач с надёжными сигналами верификации, включая математические рассуждения, спортивное программирование, STEM-рассуждения, а также выполнение инструкций с чёткими ограничениями.
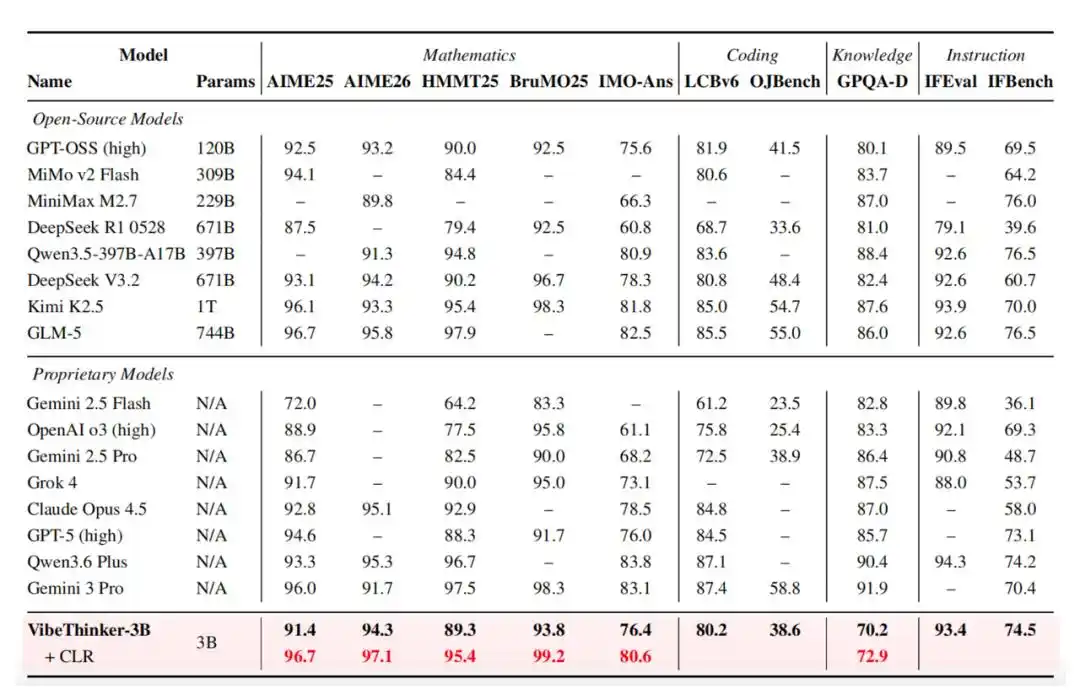
Поэтому она показывает выдающиеся результаты по всем контрольным тестам. В тесте AIME26 она набрала 94,3 балла, в тесте HMMT25 — 89,3 балла, в тесте LiveCodeBench v6 — 80,2 балла (Pass@1), а в самых свежих непубличных еженедельных и двухнедельных соревнованиях LeetCode с 25 апреля по 31 мая 2026 года достигла процента успешных решений 96,1%.

Как обучалась эта модель? Технический отчёт раскрывает некоторые детали.
Во-первых, она построена на основе Qwen2.5-Coder-3B и проходит последующее обучение по усовершенствованному процессу Spectrum-to-Signal. Этот процесс усиливает синтез данных, фильтрацию качества и поурочное обучение при контролируемом тонком обучении (SFT), расширяет обучение с подкреплением в стиле MGPO на несколько проверяемых областей, сохраняет полные траектории рассуждений в длинном контексте и укрепляет все способности с помощью авто-дистилляции вне сети и обучения с подкреплением на инструкциях (Instruct RL).
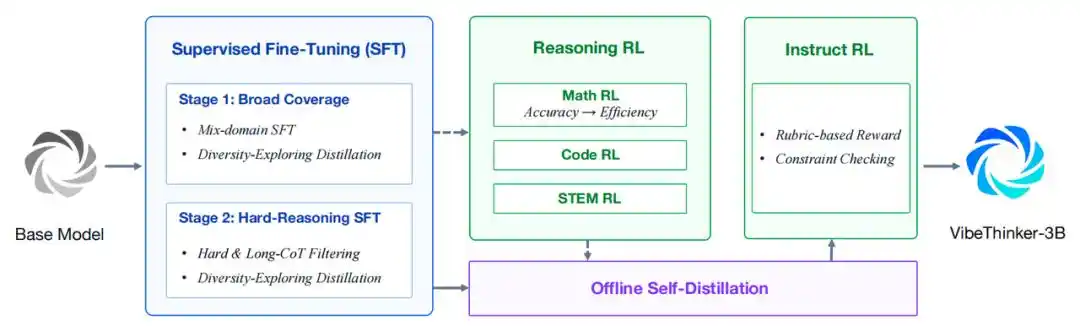
Общий процесс обучения VibeThinker-3B.
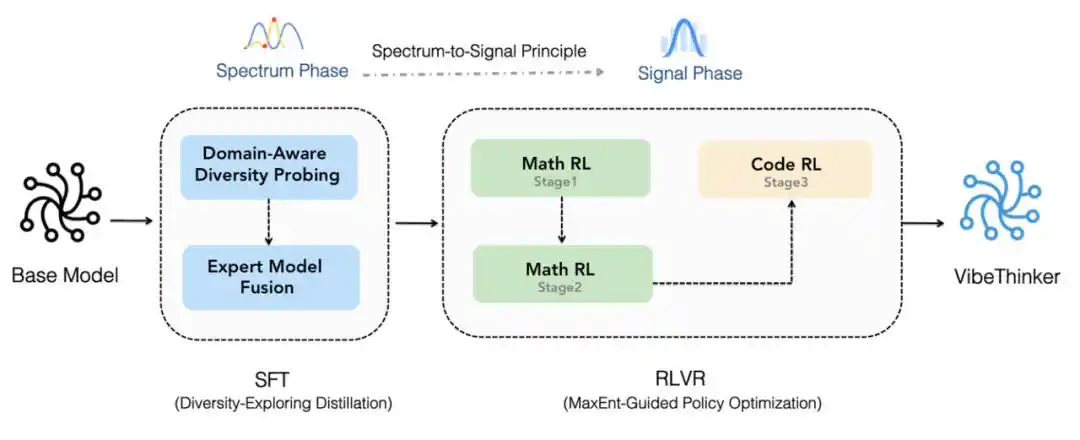
Процесс Spectrum-to-Signal.
Кроме того, VibeThinker-3B внедряет оценку надёжности на уровне утверждений (Claim-Level Reliability, CLR) — это стратегия масштабирования во время тестирования, ориентированная на проверяемые рассуждения с ответами. CLR дополнительно повышает производительность на математических тестах, увеличивая результат AIME26 с 94,3 до 97,1, HMMT25 с 89,3 до 95,4 и поднимая BruMO25 до 99,2.
Конкретный процесс обучения выглядит следующим образом:
- Двухэтапное SFT на основе учебного плана. Первый этап сосредоточен на широком охвате способностей, включая математику, программирование, STEM-рассуждения, общий диалог и следование инструкциям. Второй этап переходит к более сложным и широким по охвату выборкам для рассуждений. Дистилляция с исследованием разнообразия используется для сохранения нескольких эффективных путей решения.
- Обучение с подкреплением для рассуждений в нескольких областях. VibeThinker-3B повторно использует MGPO. Обучение с подкреплением последовательно применяется к математическим, программистским и STEM-задачам на рассуждение. Для обучения используется одно окно длинного контекста на 64K токенов, чтобы сохранить полные траектории длинных рассуждений.
- Авто-дистилляция вне сети. Высококачественные траектории отбираются и очищаются из контрольных точек обучения с подкреплением по математике, программированию и STEM, в конечном итоге формируя единую студенческую модель. Оценка потенциала обучения используется для приоритизации тех траекторий, которые правильны, но ещё не были хорошо усвоены студенческой моделью.
- Instruct RL. Финальный этап повышает управляемость для пользовательских промптов. Для учебных данных, чувствительных к формату и открытых, используются основанные на правилах валидаторы и модели вознаграждения на основе критериев оценки.
В недавнем посте известный исследователь ИИ и блогер Себастьян Рашка систематически обобщил ключевые моменты, раскрытые в техническом отчёте VibeThinker-3B, включая следующие:

Если вас заинтересовало это содержание, вы можете подробно изучить их технический отчёт. В настоящее время модель также доступна для публичного скачивания.

Название отчёта: VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Ссылка на отчёт: https://arxiv.org/pdf/2606.16140
Ссылка на HuggingFace: https://huggingface.co/WeiboAI/VibeThinker-3B
Однако область применения этой модели чётко ограничена, поскольку в областях, требующих общих знаний, она не показывает выдающихся результатов.
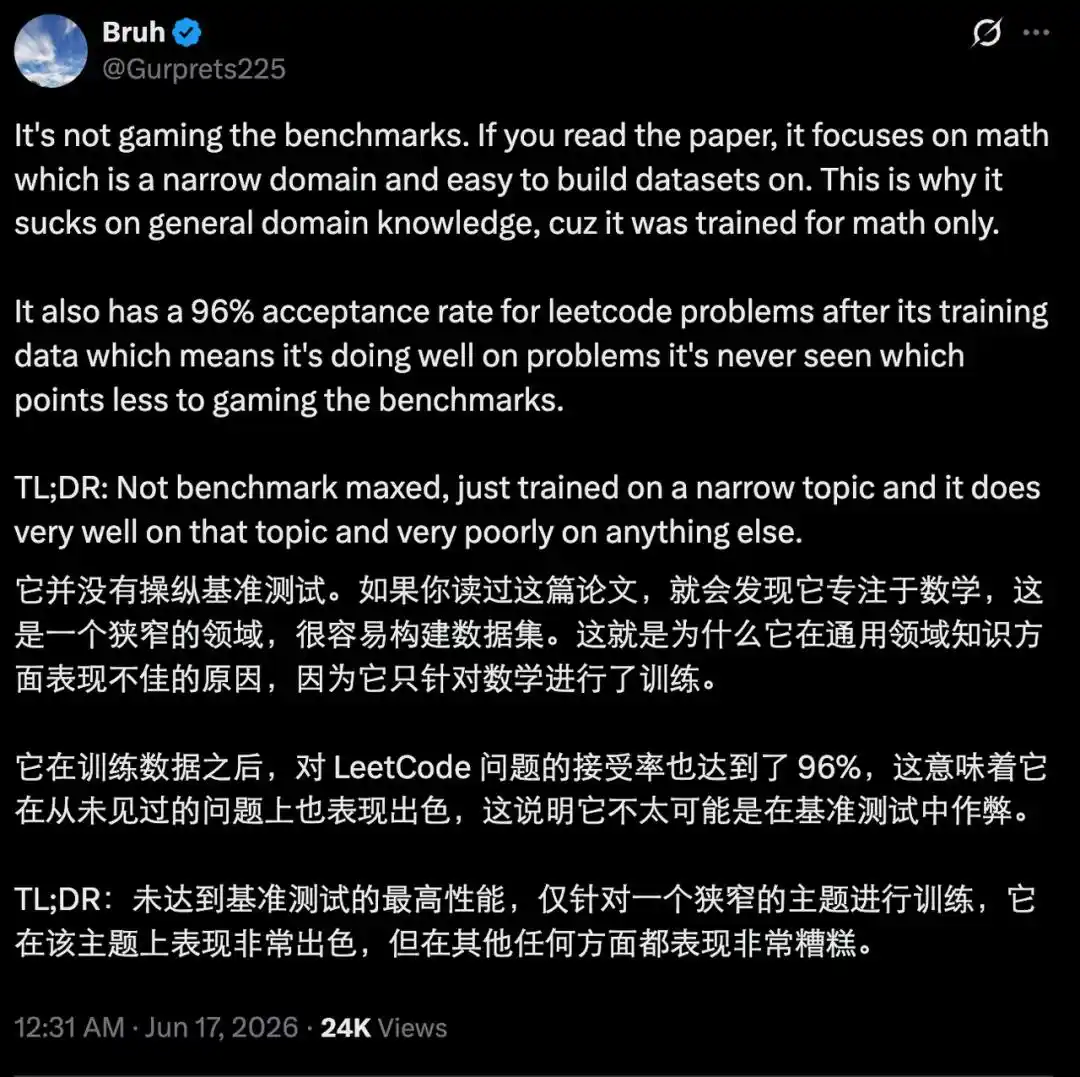
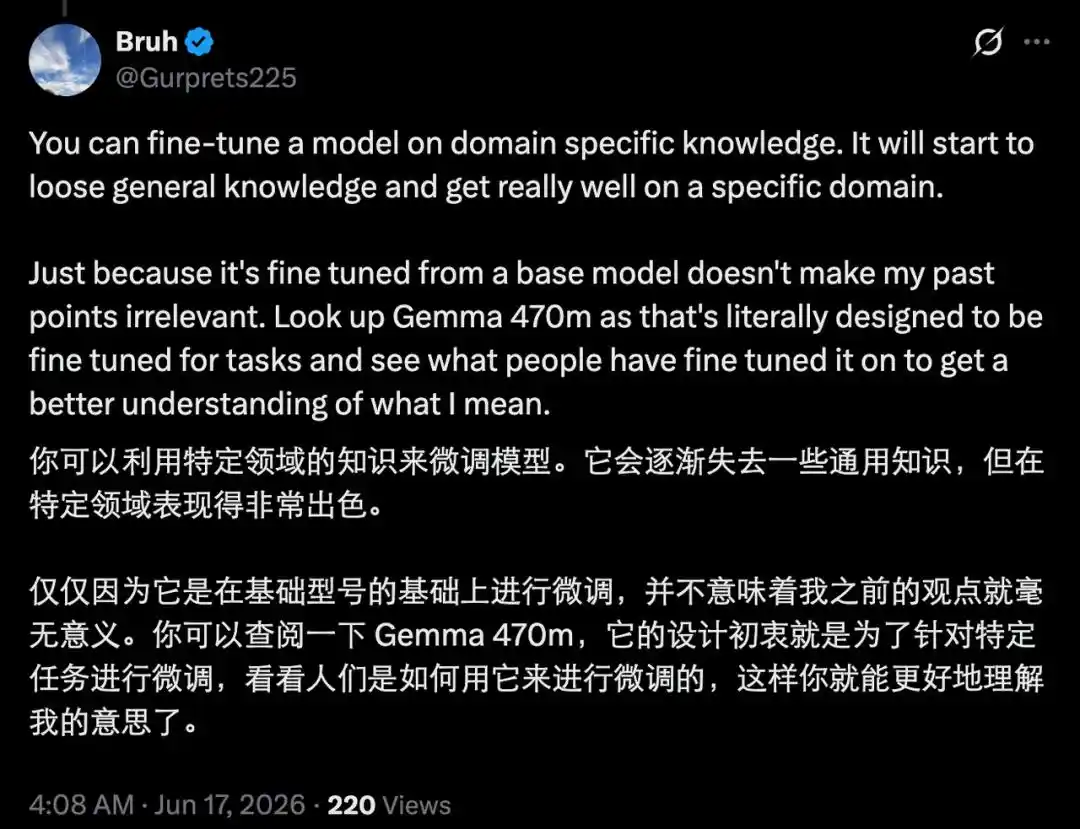
Разработчики также чётко указали на это и выдвинули «гипотезу сжатия параметров для покрытия»: разные способности по-разному зависят от параметров модели. Проверяемое рассуждение ближе к высокосжимаемой, параметрически плотной способности, ядро которой заключается в многошаговом рассуждении, удовлетворении ограничений, самокоррекции и проверке ответов. Когда пространство задач имеет достаточно чёткую структуру и сигналы обратной связи достаточно надёжны, компактная модель также может обладать способностью к рассуждениям, близкой к передовому уровню. В отличие от этого, знания в открытой области, общий диалог и понимание длинных хвостов сценариев в большей степени зависят от масштаба параметров для широкого покрытия фактов, концепций и знаний о мире. Эта гипотеза очень вдохновляет. VentureBeat в своём репортаже написали: «Она раскрывает частичное разделение между способностью к рассуждению и фактическими знаниями, и первая может быть сжата более эффективно, чем предполагалось ранее — это понимание имеет далеко идущие последствия для того, как индустрия рассматривает дизайн моделей, стоимость развёртывания и доступность продвинутых функций искусственного интеллекта.»

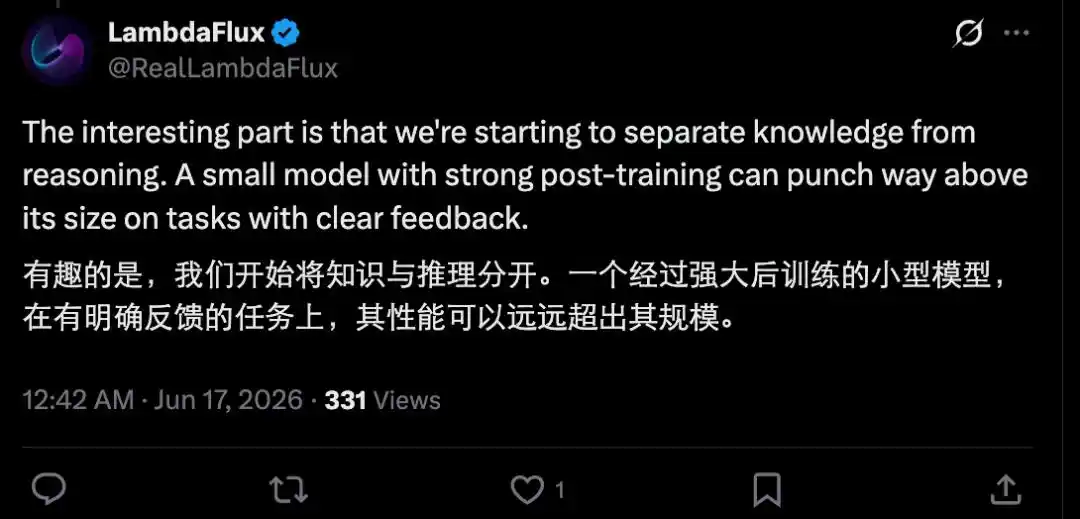
Авторы заявляют, что их цель — не создать небольшую модель как замену крупным моделям, а изучить истинные границы небольших моделей вдоль определённых измерений способностей. С помощью VibeThinker-3B они хотят показать, что небольшие модели не должны рассматриваться лишь как компромисс для снижения стоимости развёртывания. В областях способностей с чёткими механизмами обратной связи и проверки небольшие языковые модели открывают перспективный исследовательский путь, потенциально позволяющий достичь передового уровня производительности и создать фундаментально дополняющие отношения с традиционной парадигмой масштабирования по параметрам.
В настоящее время в сообществе к этой модели всё ещё есть некоторые сомнения. Если вам интересна эта модель,不妨 попробуйте её сами.

Ссылки:
https://x.com/orcus108/status/2066876960073281582
Эта статья взята с официального аккаунта WeChat «Машинный разум» (ID: almosthuman2014), автор: Чжан Цянь.





