At the end of 2024, a paper titled "Streaming Deep Reinforcement Learning Finally Works" (arXiv:2410.14606) sparked widespread discussion in the academic community. The authors, from Mahmood's team at the University of Alberta, spent considerable effort describing an embarrassing reality: reinforcement learning, a method that is inherently "learn-as-you-go," has almost become incapable of doing so in the era of deep neural networks. If you simply remove the replay buffer and set the batch size to 1, training collapses. They called this the "stream barrier".
That paper proposed the StreamX series of algorithms, which barely scaled this wall through meticulous tuning of hyperparameters, sparse initialization, and various stabilization techniques.
However, less than a year and a half later, a member of the same research group, along with collaborators from the Openmind Institute, provided a distinctly different answer: the root cause of the stream barrier is not "insufficient data," but "the step size having the wrong unit."

Paper title: Intentional Updates for Streaming Reinforcement Learning
Paper link: https://arxiv.org/pdf/2604.19033v1
Code repository: https://github.com/sharifnassab/Intentional_RL
Stepping on the Gas, How Big a Hole Does It Dig?
Imagine you're learning to parallel park a car. The instructor tells you to "press the gas pedal for 0.1 seconds" each time. The problem is, pressing for the same 0.1 seconds can result in vastly different distances traveled depending on whether you're going uphill, downhill, empty, or fully loaded. Sometimes you're off by a centimeter and park perfectly, other times you're off by 30 centimeters and hit the wall.
Traditional gradient learning step sizes do precisely this: they dictate how much the parameters should move, but exert no control over how much the function's output actually changes. In batch training, the errors of hundreds or thousands of samples are averaged, diluting extreme cases, so the problem isn't obvious. But in a "streaming" environment, where each step involves only one sample, there is no averaging. Once the gradient direction becomes unstable, the magnitude of updates can swing wildly—moving forward 30 cm today, backward 50 cm tomorrow—causing the learning process to collapse amid violent oscillations.
This phenomenon of "overshooting and undershooting" is particularly severe in reinforcement learning because the gradient at each timestep not only varies in magnitude but also changes direction rapidly.
Redefining "How Much a Step Should Do"
In a recent paper, Arsalan Sharifnassab from the Openmind Institute, along with Mohamed Elsayed, A. Rupam Mahmood, and Richard Sutton from the University of Alberta, proposed a solution from a different angle: Instead of specifying how much the parameters should move, directly specify how much the function's output should change.
This idea is not entirely new. In 1967, Japanese scholars Nagumo and Noda, in their paper "A learning method for system identification," proposed the "Normalized Least Mean Squares" (NLMS) algorithm in the field of adaptive filtering; its essence is also using the desired output change to deduce the step size, not the other way around. However, that algorithm was only suitable for simple linear scenarios.
The researchers extended this idea to deep reinforcement learning. They call it "Intentional Updates": before each update, first clarify "what I hope to achieve with this step," then deduce the step size that should be used.
For value learning (i.e., predicting future rewards), their defined intention is: after each update, the prediction error for the current state's value should shrink by a fixed proportion—for example, by 5%, no more, no less. For policy learning (i.e., optimizing decision-making actions), their defined intention is: the probability of selecting the current action is only allowed to change by a "moderate" amount each step.
Using the driving metaphor: this is like the driver deciding before each operation, "I want the car to move forward 20 cm," then automatically calculating how deep to press the gas pedal based on current road conditions (gradient, load), instead of pressing the same depth each time and leaving it to fate.
The Turing Award Laureate and His Puzzle
One of the paper's signatories is Richard S. Sutton—the 2024 Turing Award laureate, widely regarded as the "father of modern reinforcement learning."
Sutton's stature in academia is roughly equivalent to that of Feynman in physics: he not only proposed the Temporal Difference (TD learning) and Policy Gradient frameworks, the foundations of modern reinforcement learning, but also co-authored, with Andrew Barto, the field's most authoritative textbook, "Reinforcement Learning: An Introduction" (now in its second edition, available online for free). He shared the 2024 Turing Award with Barto, with the award citation reading, "for laying the conceptual and algorithmic foundations of reinforcement learning."
After receiving the award, Sutton did not retire but instead invested the prize money into the Openmind Institute he founded, specifically funding young researchers willing to "explore fundamental problems in an environment free from commercial pressure." This new paper emerged from this non-profit institution.
And the paper's first author, Sharifnassab, had recently published the MetaOptimize framework at ICML 2025, researching how to automatically tune learning rates online. The focus of both topics is highly consistent: how to make the step size itself more intelligent.
Algorithm Details: Simpler Than Imagined
The mathematical derivation of "Intentional Updates" is not complex; its core formula can be described in one sentence: the step size equals the "desired output change" divided by the "actual influence of the gradient direction on the output."
In value learning, this "actual influence" is the norm of the gradient vector (essentially measuring how "steep" the current parameter region is): step sizes are smaller in steeper areas and larger in flatter areas, ensuring the impact of each update on the value function remains consistent.
In policy learning, the "desired change" is defined to be proportional to the advantage function: how much better the current action is compared to the average determines how much the policy moves in that direction—normalized in magnitude through a running average, ensuring that over the long term, the magnitude of policy changes remains stable within an interpretable range.
The researchers also combined this core idea with two engineering practices: RMSProp-style diagonal scaling (handling differences in magnitude across parameter dimensions) and eligibility traces (helping reward signals propagate to past timesteps).
This ultimately forms three complete algorithms: Intentional TD (λ) for value prediction, Intentional Q (λ) for discrete action control, and Intentional Policy Gradient for continuous control.



Experimental Results: Matching SAC Even Without GPUs
The paper evaluated this approach on multiple standard benchmarks, with impressive results.
On MuJoCo continuous control tasks (including complex simulated robots like Ant, Humanoid, HalfCheetah), the new method, Intentional AC, in a streaming setup (batch size = 1, no replay buffer), achieved final performance that repeatedly came close to or even matched SAC—an algorithm that uses large-batch replay buffers and is almost the gold standard for current continuous control tasks. In terms of computational cost, each Intentional AC update required only about 1/140th of the floating-point operations of a single SAC update.
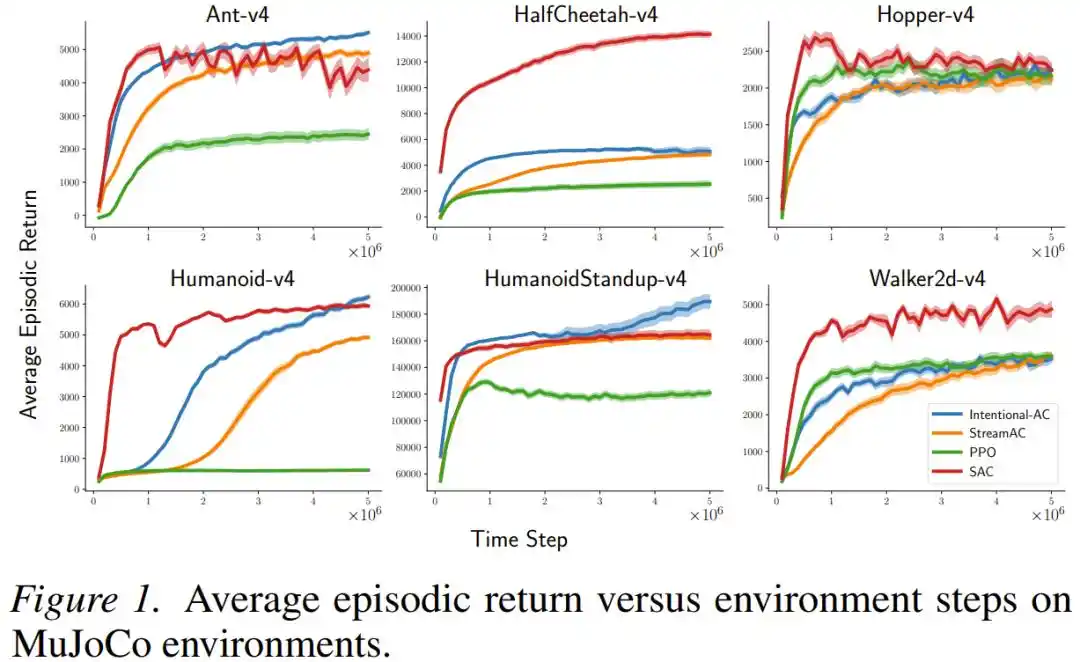
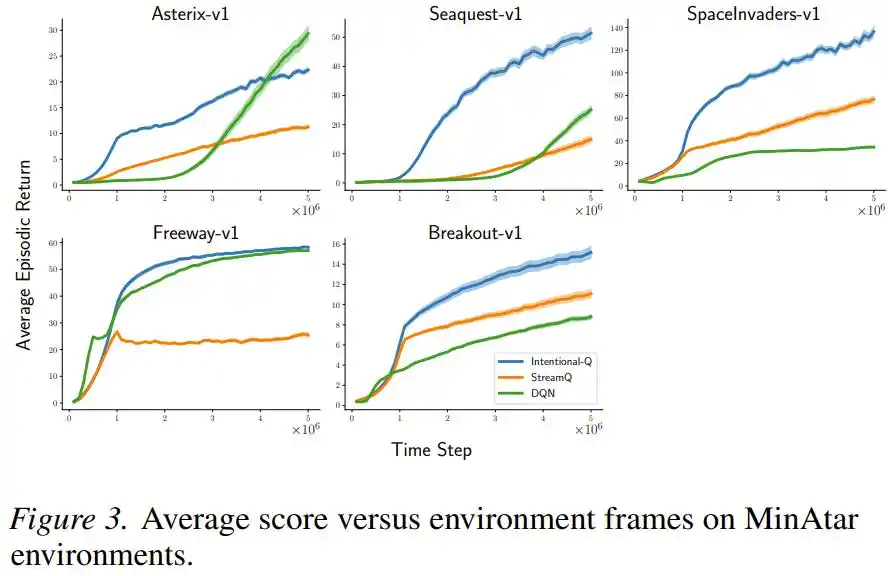
On Atari and MinAtar discrete-action games, Intentional Q-learning performed comparably to DQN, which uses a replay buffer, and successfully ran all tasks with the same set of hyperparameters, without requiring per-task tuning.
The researchers also specifically verified whether the "intention" was truly realized: they measured the ratio of actual update magnitude to intended update magnitude. In a simplified setting with eligibility traces disabled, the standard deviation of this ratio was only 0.016 to 0.029, with the 99th percentile all within 1.07; meaning that in the vast majority of cases, the updates indeed achieved "exactly what they were supposed to do."
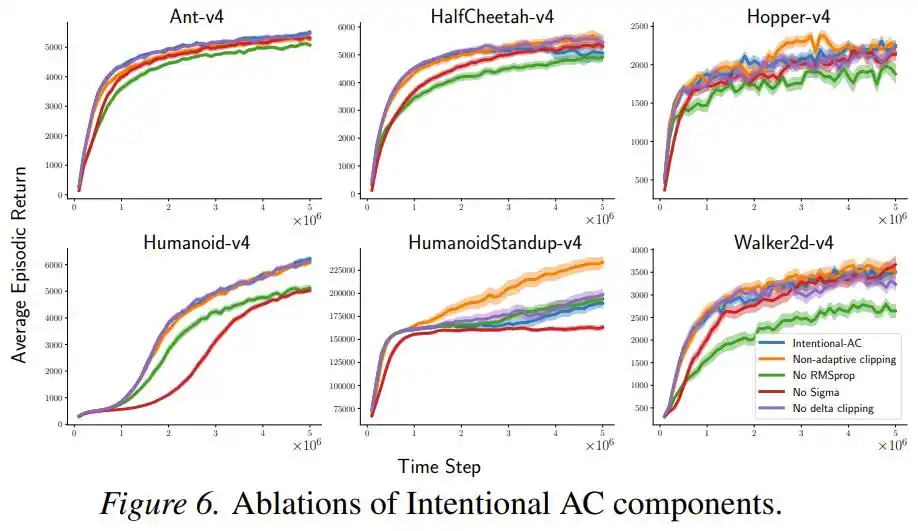
Furthermore, an ablation study showed that performance declined somewhat but remained competitive after removing RMSProp normalization or the σ term, with this "intentional scaling" itself being the primary contributor, while other components were auxiliary.
Problems Remain
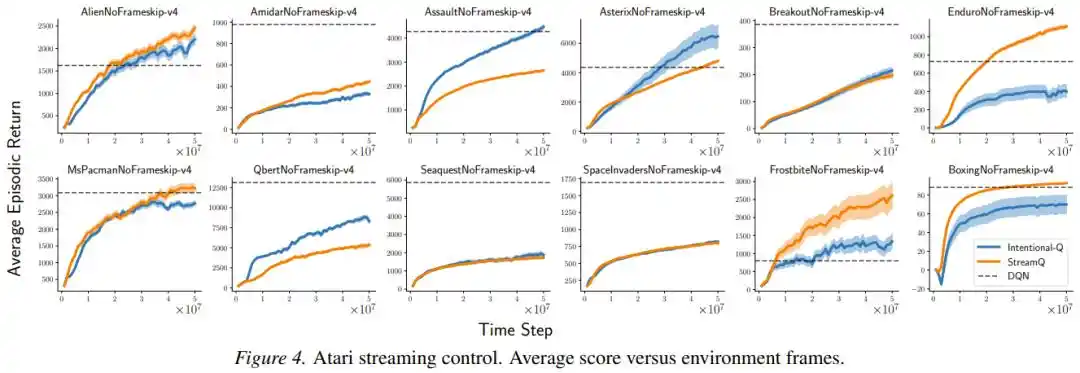
The "Intentional Update" framework also demonstrated significant advantages in robustness. When the researchers removed, one by one, the various stabilizing auxiliary techniques (sparse initialization, reward scaling, input normalization, LayerNorm) that the StreamX method relied on, Intentional AC's performance degradation was significantly less than that of the original StreamAC, indicating that intentional scaling reduces reliance on external "crutches" at the root.
However, the paper also candidly addresses a not-yet-fully-resolved issue: in policy learning, the step size depends on the currently sampled action, which implicitly assigns different "weights" to different actions and may alter the expected direction of the policy gradient. In Humanoid and HumanoidStandup tasks, by measuring the cosine similarity of expected update directions, the researchers found this bias was close to 0.96 (almost negligible) during critical learning phases; but in Ant-v4, the alignment dropped to a median of 0.63, indicating the problem cannot always be ignored.
The authors point out that future research should seek step-size selection strategies independent of the action, keeping the "intention" unbiased in expectation as well. This is a clear assignment left for future researchers in this direction.
Conclusion: Enabling AI to Learn Like Humans, On the Job
The current mainstream paradigm for training large models relies on batch digestion of massive data: feeding in all the text and code from the internet, repeatedly iterating until astonishing capabilities emerge. This path has proven effective, but it is fundamentally "learn first, use later": once training is complete, the model is frozen, unable to continuously update from subsequent real-world interactions.
What streaming reinforcement learning pursues is another, completely different learning mode: not relying on massive replay, not relying on huge GPU clusters, converting every single experience immediately into a parameter update, continuously, cheaply, and adaptively. This is closer to how humans and animals actually learn.
From the initial breakthrough of "finally working" by Elsayed et al. in 2024, to the "Intentional Update" principle proposed in this paper, streaming deep reinforcement learning is maturing at a surprisingly rapid pace. It will not replace batch-trained large models, but for applications requiring long-term online adaptation—like robots, edge devices, and any scenario that cannot afford large replay buffers and GPU clusters—this path is becoming increasingly compelling.
The step size is not just a hyperparameter; it is the AI's commitment to "how much it intends to do" with each step. When this commitment finally becomes controllable, learning itself stabilizes.
This article is from the WeChat public account "Almost Human" (ID: almosthuman2014), author: someone interested in RL.





