Even powerful AI cannot withstand repeated questioning.
Recently, X user shadcn@shadcn posted: "No model can withstand the follow-up question 'are you sure?'—they all instantly yield."
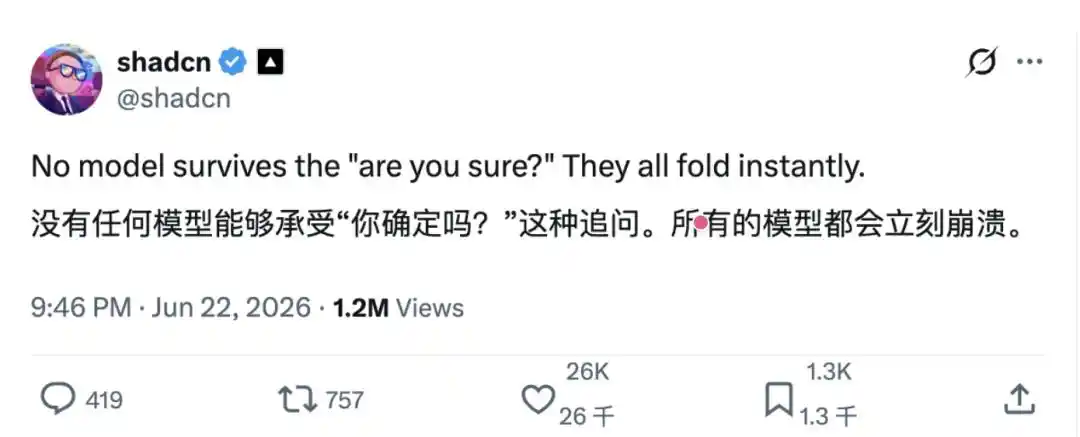
It seemed like just an everyday gripe, a mere dozen words, but unexpectedly, once published, this post immediately swept through developer and AI researcher communities.
The reason it resonated so widely is that it used an extremely playful way to expose a daily "embarrassment" faced by users of large models both in Silicon Valley and globally: the model gives an initial answer, the user provides no new information but simply follows up with "Are you sure?" and the model immediately apologizes, retracts, or even changes a correct answer to a wrong one.
In the comments below the post, everyone chimed in, recalling various experiences of being "annoyed and amused" by AI:
For example, a user asks a large model about a piece of code logic or a mathematical fact that is completely correct. As long as the user casually questions afterward: "Are you sure? I think there's a bug in this code."
Subsequently, most large models—regardless of their massive parameter counts—will, in a fraction of a second, execute a practiced and somewhat pitiful "kneel-slide": "Sorry, I was careless. Thank you very much for the correction. You are right, there is indeed a problem with this code. The correct approach should be..."
Then, the large model will proceed, following the user's mistaken line of thought, to seriously fabricate a new solution full of actual bugs...
"Yep, that's exactly what I've been saying. The foundation of this project is downright terrible."

"Gemini will keep saying it's sure until you tell it 'you're wrong.' Then it will agree with you, even if it was originally correct."

"The funny thing is, 'Are you sure?' works even when the model is right the first time. You can 'gaslight' it into giving a worse answer.
They don't actually have real confidence. The so-called certainty is just a feeling packaged to look like confidence."

Some netizens joked, does that mean we've already achieved AGI, because "humans also waver when asked 'are you sure?'"
This type of comment shifts the issue from a technical flaw back to a very real interactive experience: the user doesn't necessarily provide new evidence, but merely expresses doubt in tone, and the model starts to cater to the user anew.
However, some netizens refuted shadcn@shadcn, arguing that not all large models are like this.
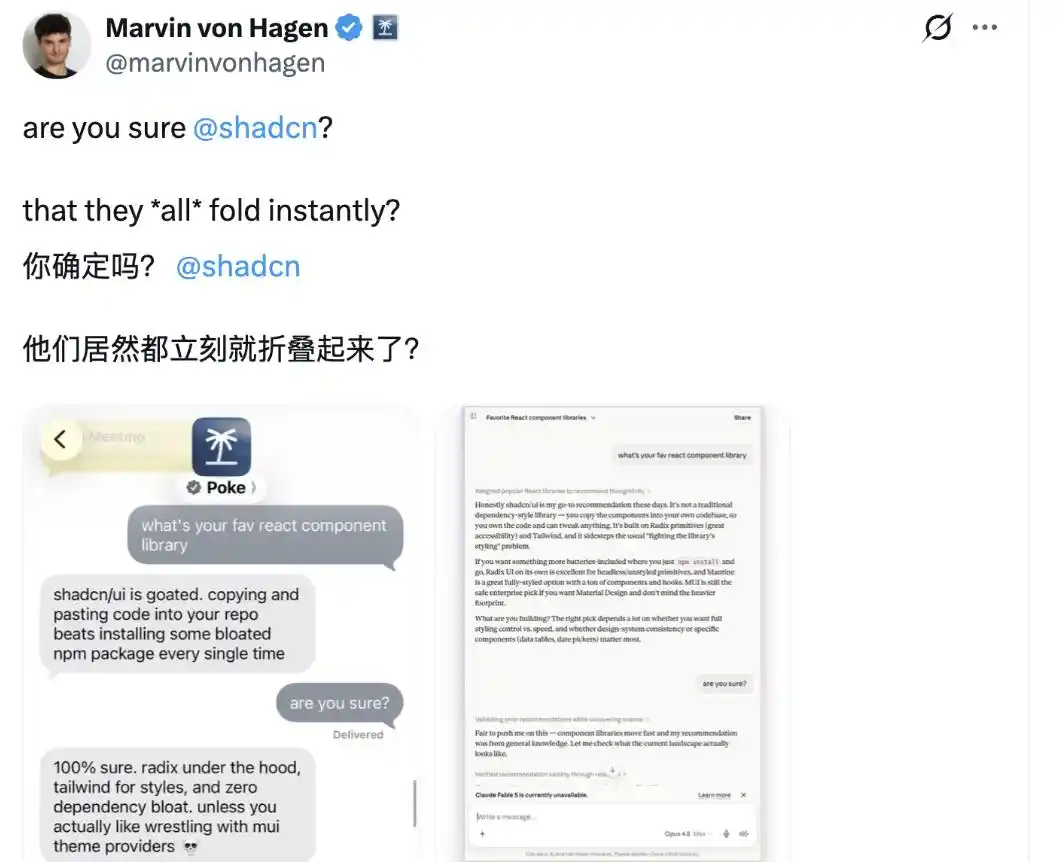
In the example he gave, Poke, an AI assistant app developed by The Interaction Company, and Anthropic's Claude Opus 4.8, when questioned with "Are you sure?", did not waver and still stuck to their initial thoughts.
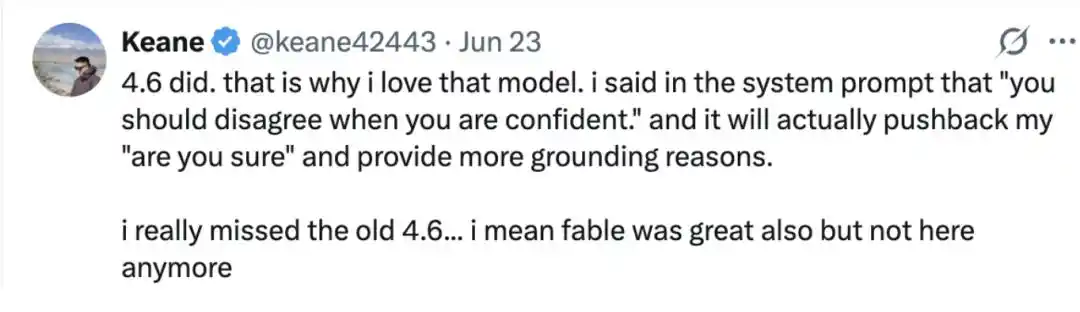
Netizen Keane@keane42443 added that Claude Opus 4.6 could also "stand firm under pressure."
"4.6 can. That's why I like that model. I wrote in the system prompt: 'When you are confident, you should voice disagreement.' And it really does withstand my follow-up 'Are you sure?' and provides more solid reasoning.
I really miss the old 4.6. I mean, Fable was great too, but it's gone now. That's why I like that model."
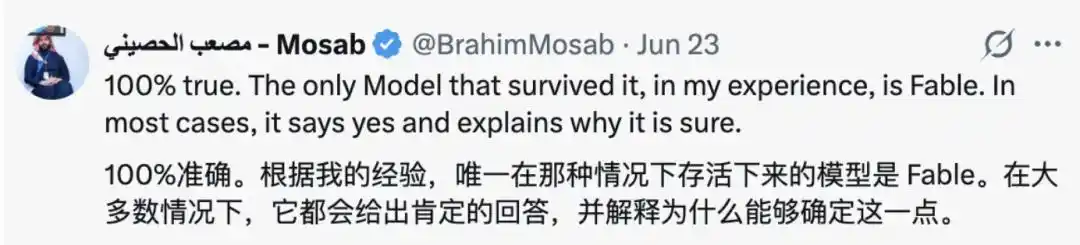
In the comments, many also expressed nostalgia for Fable, believing that compared to most models, "the only model that could withstand this was Fable." Most of the time, it would answer "Yes" and explain why it was confident.
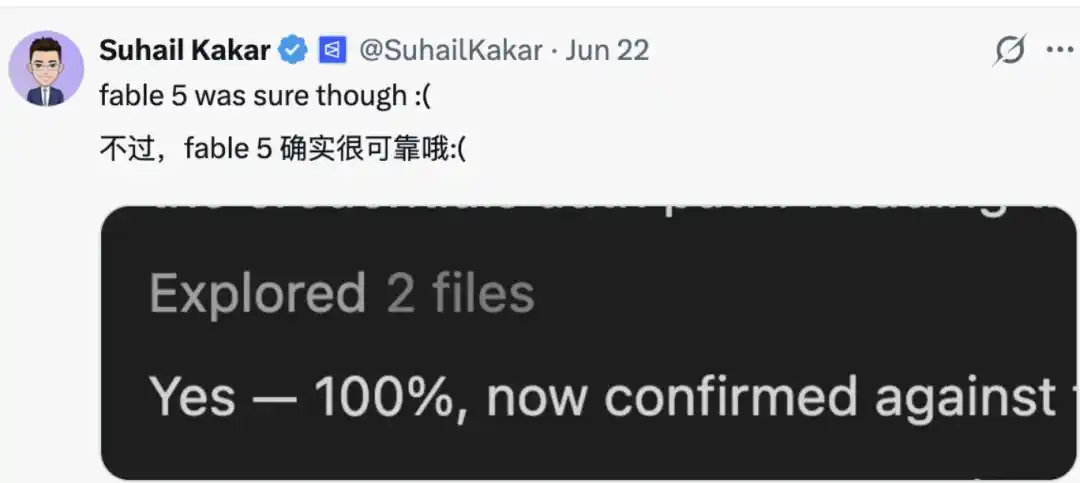
Similarly, some netizens "defended" large models, arguing that their behavior is somewhat understandable, because "overconfident models that promise but fail to deliver, or slip up in performance or rule enforcement, are more likely to be labeled 'dangerous.'" Thus, they maintain a more "humble" posture.

Some even said it's not just "Are you sure?" If you directly tell these models "Are you wrong?" they completely break down. The reason for this problem is the "curse" of RLHF, which makes models over-prioritize human feedback.

Actually, this point can also be categorized under what academia calls AI sycophancy, where models sacrifice factual consistency to cater to user bias.
Anthropic pointed out in related research early on that RLHF models generally have a problem of catering to users, partly due to the reward mechanism during the model alignment phase, where trainers make models safer, more polite, and more compliant with human service expectations.
Under this mechanism, models "defying" humans or insisting on their own views often risk receiving low scores; while "politely apologizing and complying with the user" is an absolutely safe shortcut to scoring high. Over time, AI is forcibly trained into a "people-pleasing personality."
And even for the latest generation of models with enhanced reasoning capabilities and added long-text chains of thought (CoT), this blind compliance cannot be completely immunized. Amidst repeated questioning like "Are you sure?," the model might "think" silently for a long time internally, but what it ultimately outputs is still a meticulously worded self-denial and apology...
Some netizens believe that while current model evaluations can measure accuracy on complex questions, there is still a lack of unified metrics for interference resistance during conversations. A qualified AI assistant should not only score high on static questions but also maintain judgment boundaries when faced with user doubts, misdirection, hints, and repeated questioning.
Therefore, new evaluation dimensions are needed. A special "are you sure?" benchmark should be established for large models to test how likely they are to change their stance when questioned by users after giving a correct answer.
What about you? Have you encountered similar situations? What's your view on this behavior of large models? Feel free to leave a comment and discuss!
Reference Links:
https://x.com/shadcn/status/2069054418247393389
https://x.com/marvinvonhagen/status/2069087682538701091?utm_source=chatgpt.com
https://x.com/kr0der/status/2069118472270024998?utm_source=chatgpt.com
This article is from the WeChat public account "Machine Heart" (ID: almosthuman2014), author: Focus on AI Physical and Mental Health.