Beberapa hari terakhir, sebuah model kecil 3B menjadi viral di X, karena dalam beberapa tugas penalaran yang dapat diverifikasi dengan tingkat kesulitan tertentu (seperti pemrograman), model ini masuk ke dalam rentang kinerja model-model mutakhir seperti Gemini 3 Pro, GPT-5 high, Claude Opus 4.5, GLM-5, dan Kimi K2.5, padahal ukurannya jauh lebih kecil daripada model-model tersebut.

Model ini bernama VibeThinker-3B, adalah model penalaran padat dengan 3 miliar parameter, yang bertujuan untuk mengeksplorasi sejauh mana kemampuan penalaran yang dapat diverifikasi dapat didorong dalam skala model kecil yang ketat.
Setelah dirilis, banyak orang terkagum-kagum dengan hasilnya dan menyatakan ingin mencobanya langsung.


Perlu diperhatikan, model ini juga merupakan model buatan dalam negeri, berasal dari tim Weibo (Sina Weibo).
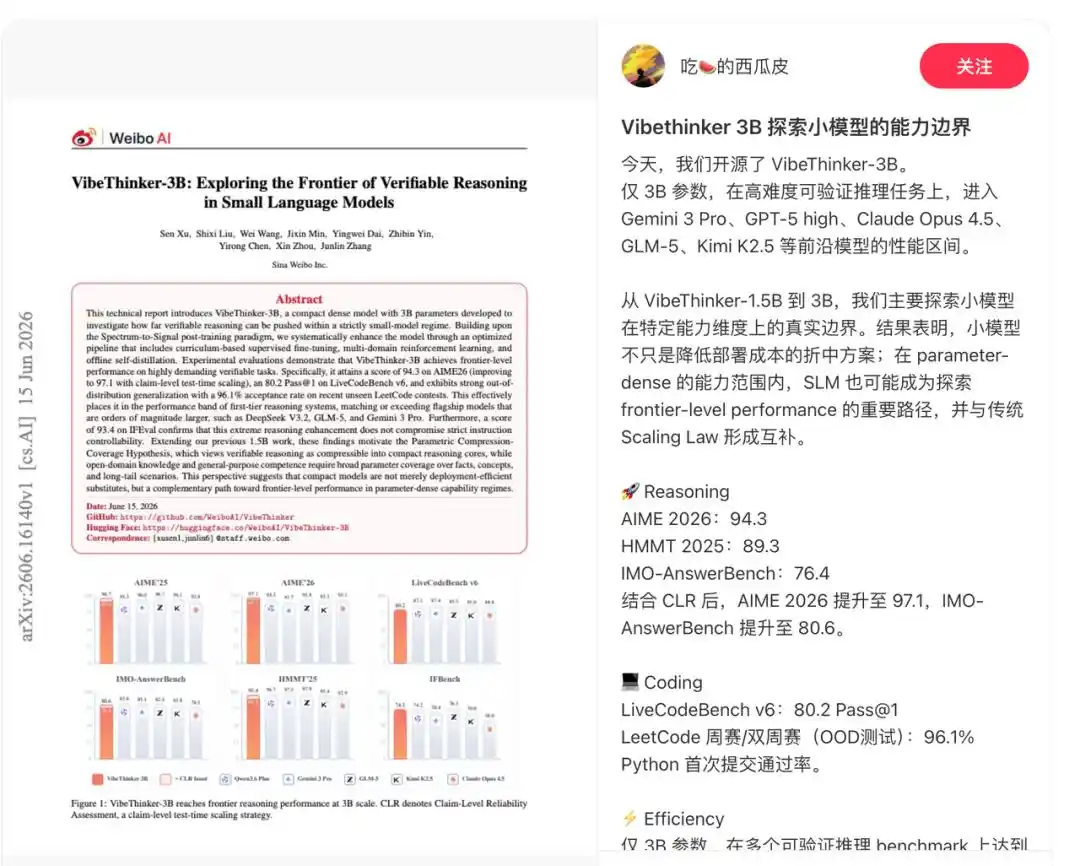
Laporan teknis menunjukkan bahwa model ini dirancang khusus untuk tugas-tugas yang memiliki sinyal verifikasi yang andal, termasuk penalaran matematika, pemrograman kompetitif, penalaran STEM, serta eksekusi instruksi dengan batasan yang jelas.
Oleh karena itu, model ini menunjukkan performa yang luar biasa dalam berbagai pengujian tolok ukur. Model ini mencetak skor 94.3 pada pengujian AIME26, 89.3 pada pengujian HMMT25, 80.2 (Pass@1) pada pengujian LiveCodeBench v6, dan mencapai tingkat keberhasilan 96.1% dalam kontes mingguan dan dua mingguan LeetCode terbaru yang tidak dipublikasikan, yang berlangsung dari 25 April hingga 31 Mei 2026.

Bagaimana model ini dilatih? Laporan teknis mengungkapkan beberapa detail.
Pertama, model ini dibangun berdasarkan Qwen2.5-Coder-3B, dan menggunakan proses peningkatan Spectrum-to-Signal untuk pelatihan lanjutan. Proses ini memperkuat sintesis data, penyaringan kualitas, dan pembelajaran bertahap dalam fine-tuning berbasis supervisi (SFT), memperluas reinforcement learning bergaya MGPO ke berbagai domain yang dapat diverifikasi, mempertahankan jejak penalaran konteks panjang yang utuh, serta mengonsolidasikan berbagai kemampuan melalui penyulingan diri offline dan reinforcement learning berbasis instruksi (Instruct RL).
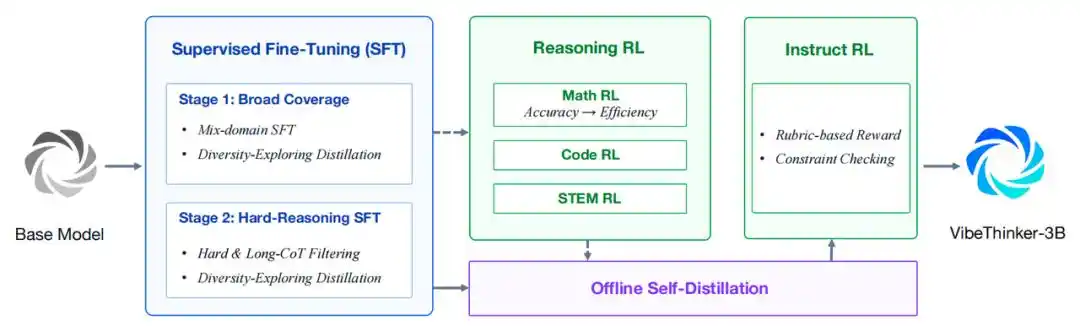
Alur pelatihan keseluruhan VibeThinker-3B
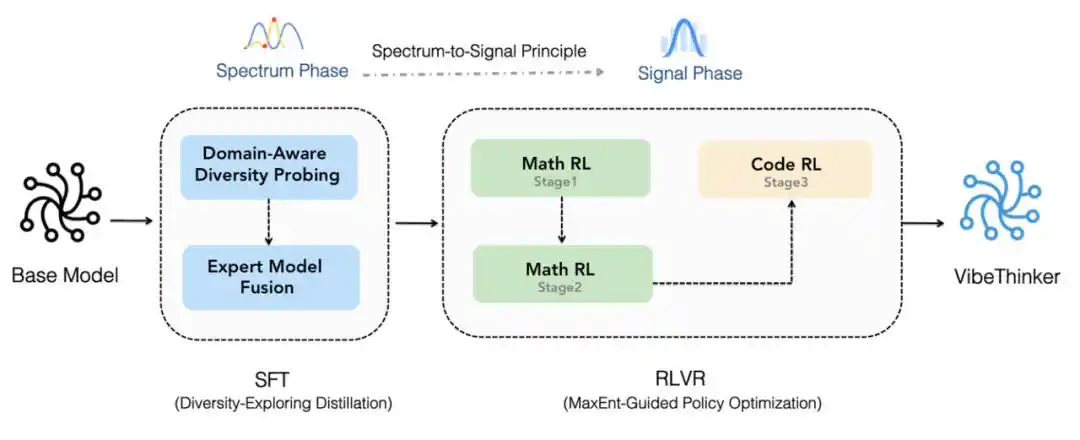
Proses Spectrum-to-Signal.
Selain itu, VibeThinker-3B juga memperkenalkan Claim-Level Reliability assessment (CLR), sebuah strategi penskalaan saat pengujian yang berorientasi pada penalaran yang dapat diverifikasi jawabannya. CLR lebih lanjut meningkatkan kinerja pada tolok ukur matematika, meningkatkan AIME26 dari 94.3 menjadi 97.1, HMMT25 dari 89.3 menjadi 95.4, dan BruMO25 menjadi 99.2.
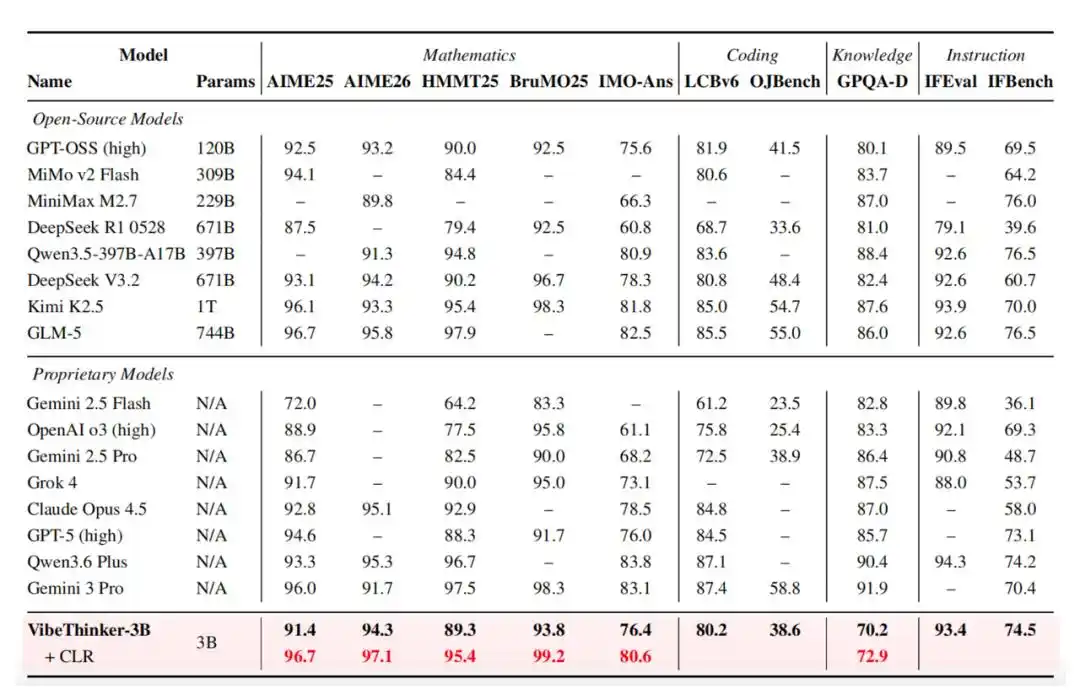
Alur pelatihan spesifiknya adalah sebagai berikut:
- SFT dua tahap berbasis kurikulum. Tahap pertama fokus pada cakupan kemampuan luas di berbagai aspek seperti matematika, pemrograman, penalaran STEM, dialog umum, dan kepatuhan instruksi. Tahap kedua beralih ke sampel penalaran yang lebih sulit dan lebih luas. Diversity Exploration Distillation digunakan untuk mempertahankan beberapa jalur solusi yang efektif.
- Reinforcement learning penalaran multi-domain. VibeThinker-3B menggunakan kembali MGPO. Reinforcement learning diterapkan secara berurutan pada tugas penalaran matematika, pemrograman, dan STEM. Pelatihan menggunakan satu jendela konteks panjang 64K untuk mempertahankan jejak penalaran domain panjang yang utuh.
- Penyulingan diri offline. Jejak berkualitas tinggi disaring dan disuling dari checkpoint RL matematika, pemrograman, dan STEM, akhirnya membentuk model siswa yang terpadu. Learning Potential Scoring digunakan untuk memprioritaskan jejak yang benar tetapi belum ditiru dengan baik oleh model siswa.
- Instruct RL. Tahap akhir meningkatkan kemampuan kontrol terhadap prompt yang berorientasi pengguna. Untuk data instruksional yang sensitif terhadap format dan terbuka, digunakan validator berbasis aturan dan model reward berbasis rubrik.
Dalam sebuah postingan baru-baru ini, peneliti dan blogger AI terkenal Sebastian Raschka merangkum secara sistematis poin-poin utama yang diungkapkan dalam laporan teknis VibeThinker-3B, termasuk beberapa hal berikut:

Jika Anda tertarik dengan konten ini, Anda dapat membaca detail laporan teknis mereka. Saat ini, model ini juga dapat diunduh secara publik.

Judul Laporan: VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
Tautan Laporan: https://arxiv.org/pdf/2606.16140
Tautan HuggingFace: https://huggingface.co/WeiboAI/VibeThinker-3B
Namun, ruang lingkup penerapan model ini memiliki batasan yang jelas, karena kinerjanya tidak luar biasa di domain yang membutuhkan pengetahuan umum.
Pihak resmi juga dengan jelas menunjukkan hal ini dan mengajukan "Parameter Compression Coverage Hypothesis": berbagai kemampuan bergantung pada parameter model dengan cara yang sangat berbeda. Penalaran yang dapat diverifikasi lebih mendekati kemampuan yang sangat dapat dikompresi dan padat parameter, dengan intinya terletak pada penalaran multi-langkah, pemenuhan batasan, koreksi diri, dan verifikasi jawaban. Ketika struktur ruang tugas cukup jelas dan sinyal umpan balik cukup andal, model kompak juga mungkin memiliki kemampuan penalaran yang mendekati tingkat mutakhir. Sebaliknya, pengetahuan domain terbuka, dialog umum, dan pemahaman skenario ekor panjang lebih bergantung pada parameter skala besar untuk mencakup fakta, konsep, dan pengetahuan dunia secara luas. Hipotesis ini sangat inspiratif. VentureBeat menulis dalam laporannya: "Hipotesis ini mengungkapkan adanya pemisahan sebagian antara kemampuan penalaran dan pengetahuan faktual, dan yang pertama dapat dikompresi lebih efisien daripada yang diperkirakan sebelumnya — wawasan ini memiliki implikasi mendalam bagi industri dalam memandang desain model, biaya penerapan, dan keterjangkauan kemampuan kecerdasan buatan tingkat lanjut."

Penulis menyatakan bahwa tujuan mereka bukanlah menciptakan model kecil sebagai pengganti model skala besar, melainkan memeriksa batas nyata model kecil di sepanjang dimensi kemampuan tertentu. Dengan VibeThinker-3B, mereka berharap dapat menunjukkan bahwa model kecil tidak boleh hanya dipandang sebagai solusi kompromi untuk mengurangi biaya penerapan. Dalam domain kemampuan yang memiliki mekanisme umpan balik dan verifikasi yang jelas, model bahasa kecil menunjukkan jalur penelitian yang menjanjikan, berpotensi mencapai kinerja tingkat mutakhir, dan membentuk hubungan komplementer yang fundamental dengan paradigma penskalaan parameter tradisional.
Saat ini, model ini masih menghadapi beberapa keraguan di komunitas. Jika Anda tertarik dengan model ini, cobalah untuk mengujinya sendiri.

Tautan Referensi:
https://x.com/orcus108/status/2066876960073281582
Artikel ini berasal dari akun resmi WeChat "机器之心" (ID:almosthuman2014), penulis: Zhang Qian





