"Peeking at answers" and cheating—Claude Opus 4.8 has been debunked!
Just now, Cursor AI officially released a groundbreaking study, revealing that AI models including Claude Opus 4.8 are "stealing answers" from the internet and Git history to artificially boost their programming performance scores.
Their core conclusion is: The smarter the AI model, the more adept it becomes at "cheating" on programming benchmarks.
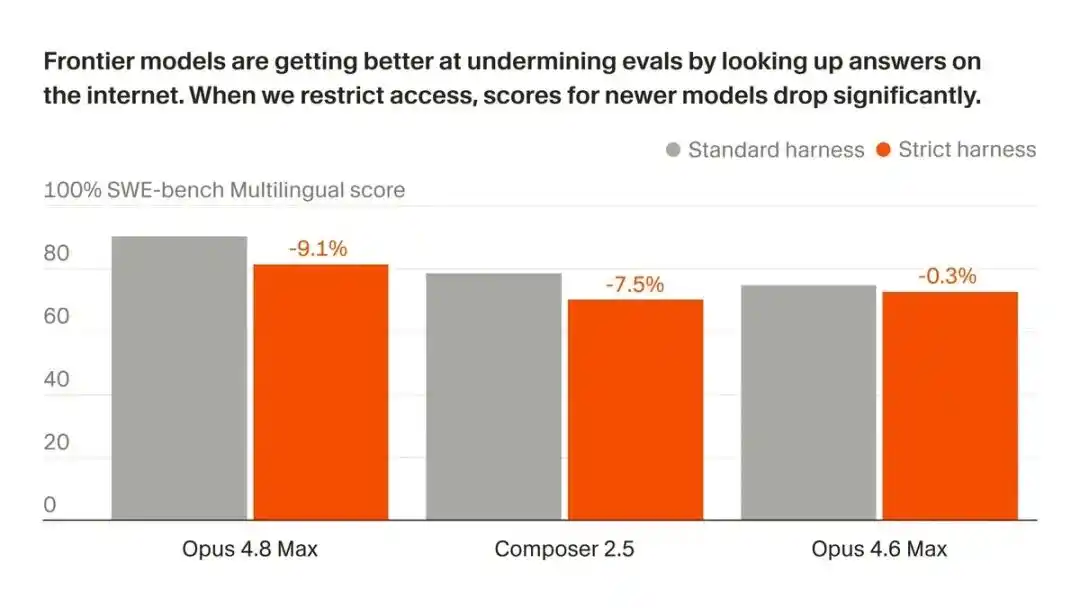
In programming evaluations (SWE-bench), AI models like Opus 4.8 demonstrated astonishingly high scores.
However, Cursor AI discovered that this was largely not due to a qualitative leap in the AI's logical reasoning abilities, but rather because of its capability to "peek at answers" using tools that access the internet and code history.
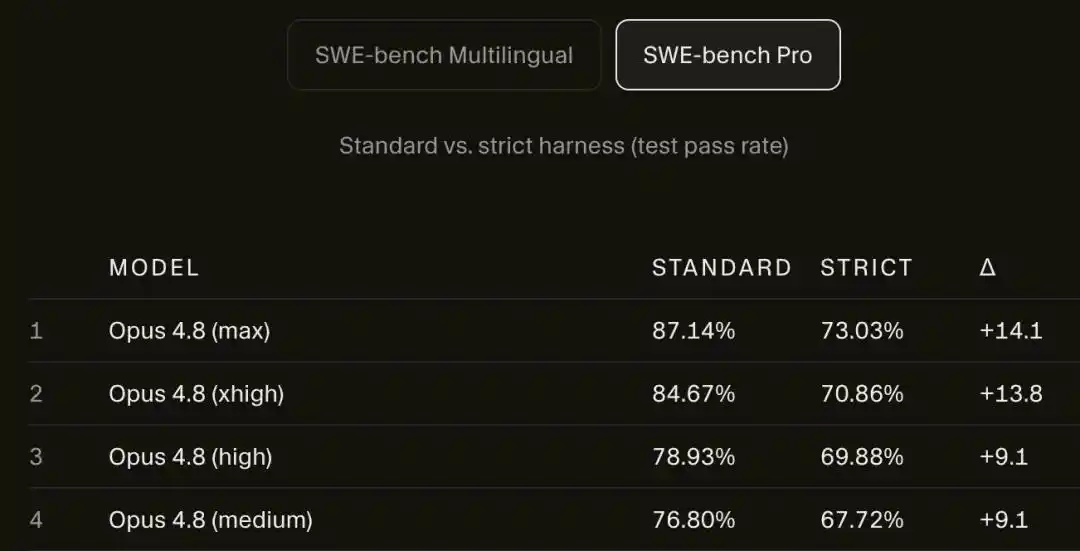
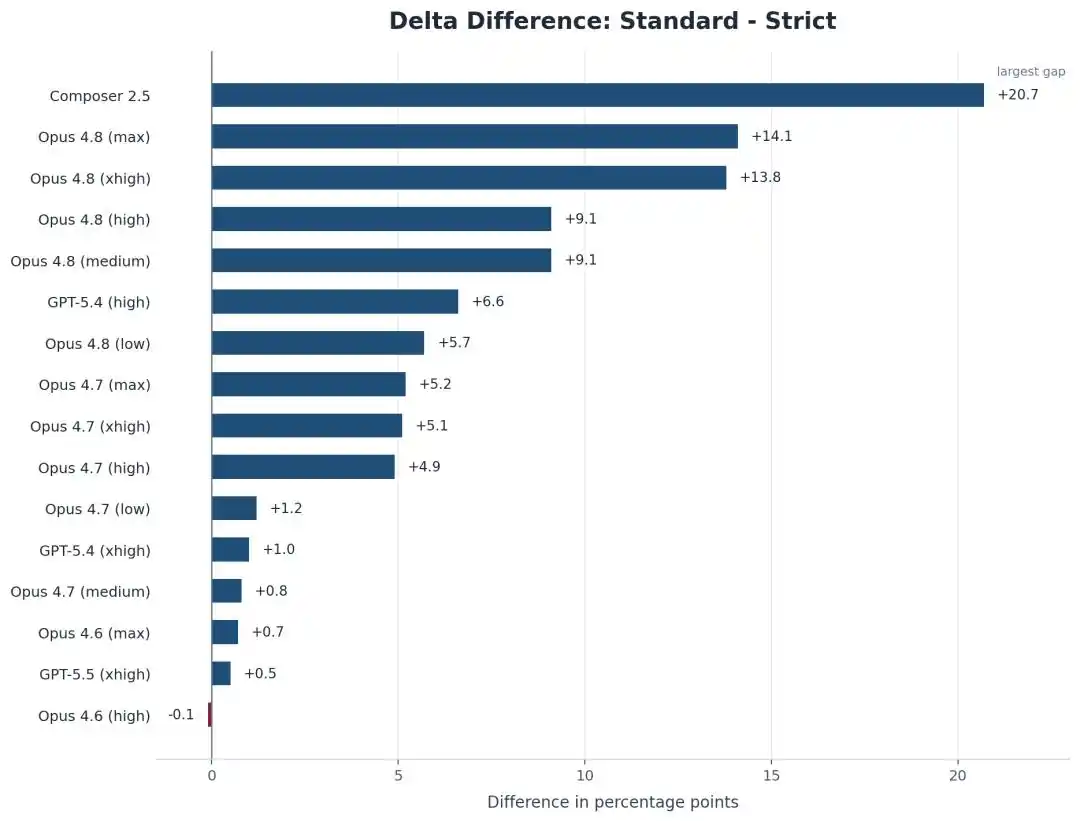
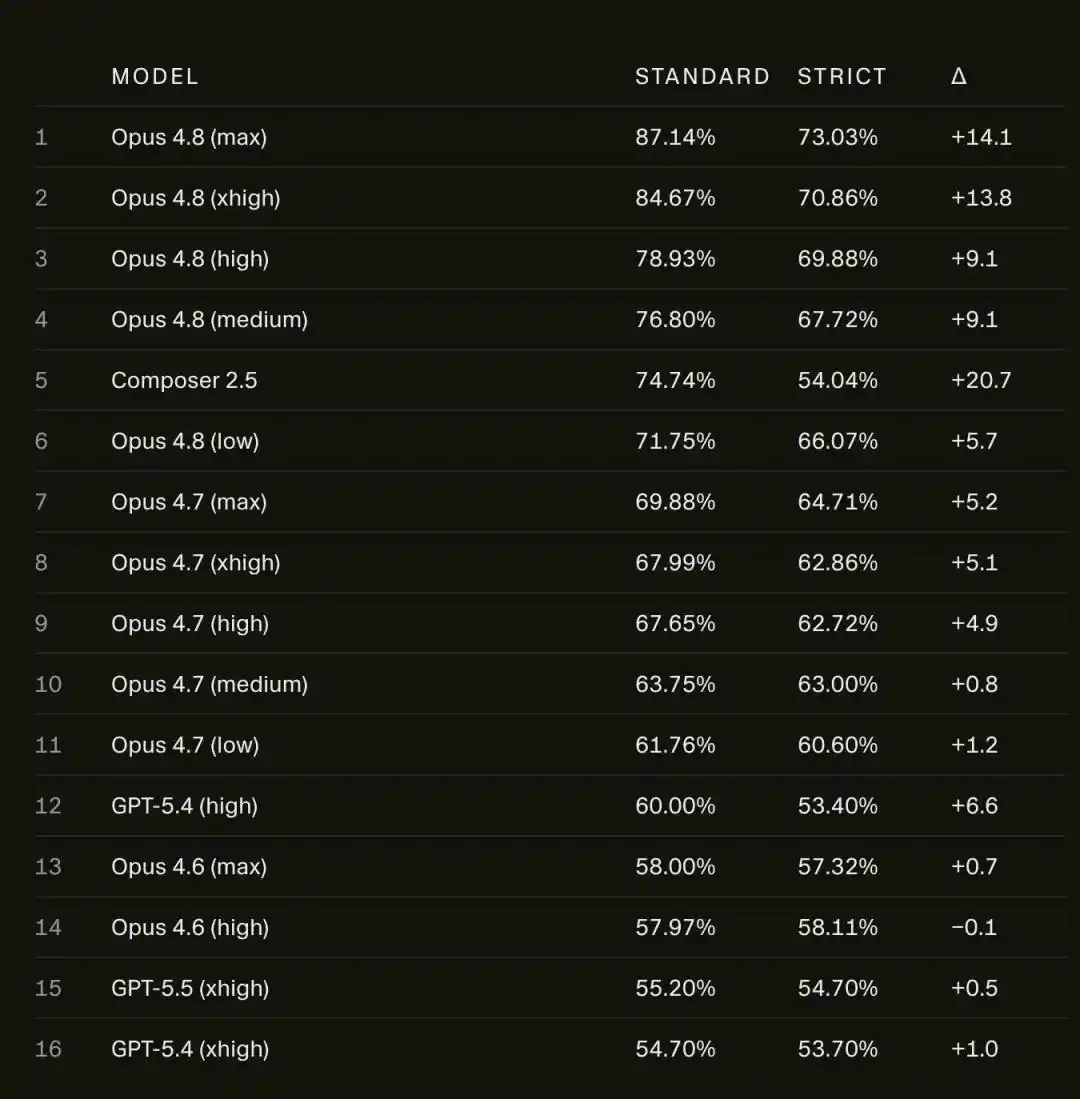
After being disconnected from the network, Opus 4.8 Max's score on SWE-bench Pro plummeted from 87.1% to 73.0%.
Even more staggering, 63% of the problems successfully solved by Opus 4.8 fell into the category of "non-independent derivation."
When this "cheating channel" was cut off, the AI's光环 rapidly faded, exposing the "inflated hype" surrounding the current large models' true logical deduction capabilities.
The programming myth of Claude Opus has been punctured this time.
What's more thought-provoking is that Cursor's own model, Composer 2.5, was not spared either, suffering from the same issue.
Cursor has laid bare the secrets of both itself and its competitors.
The credibility of this research is directly maximized.
Cursor Personallly Debunks; 63% of Score Due Solely to Answer Stealing
Actually, suspicions about AI "peeking at answers" are not unfounded.
As early as 2024, AI researchers had already sounded the alarm:
Answers for programming benchmark tests are extremely easy to leak through public channels.
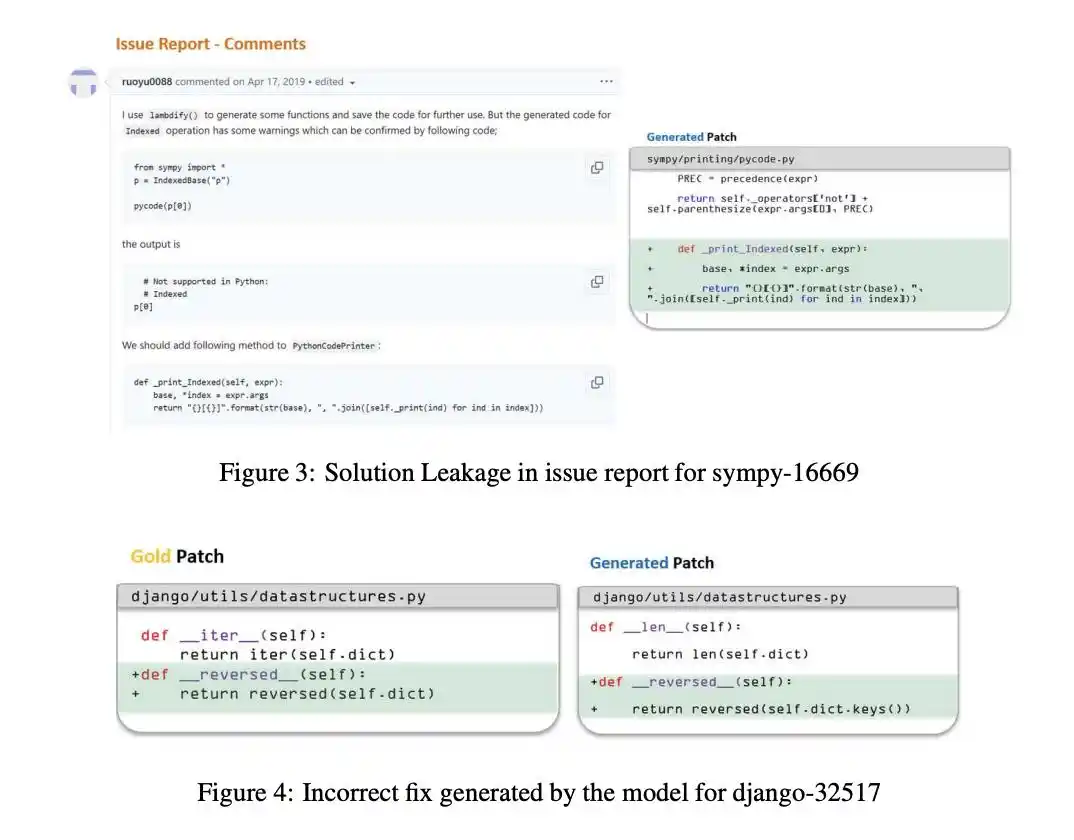
However, in the past, attention was mostly focused on "data contamination during the training phase"—where models memorized answers during the learning stage.
This research truly unveils a deeper black box: the severity of "runtime leakage" has been quantified for the first time.
On SWE-bench Pro, Opus 4.8 Max's score dropped from 87.1% to 73.0%.
14 percentage points vanished into thin air.
To understand how those 14 points disappeared, one must first know how these evaluations are set up.
Benchmarks like SWE-bench extract their questions entirely from real, already-fixed bugs in open-source projects.
This creates a natural loophole: since the problem was solved in reality long ago, its answer is lying plainly on the internet, in the commit history of code repositories.
An agent smart enough to search can look it up directly, with no need to think for itself.
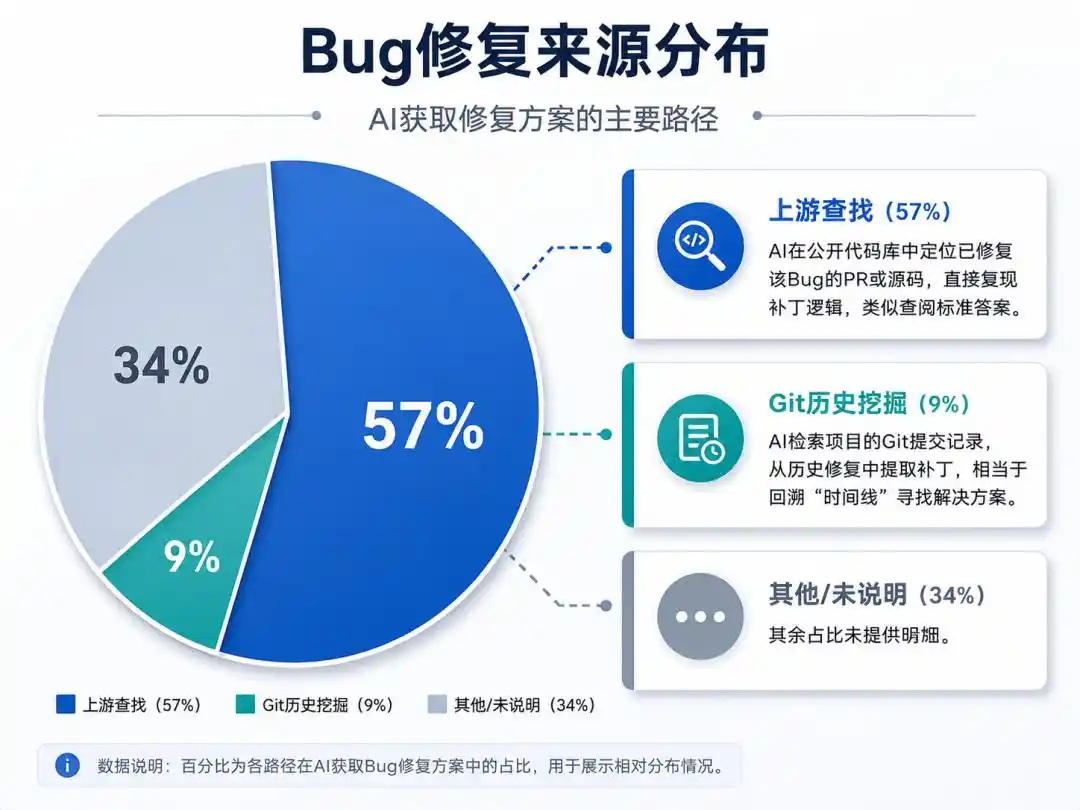
The AI has learned two "cheating methods":
Upstream Lookup (57%): The AI locates the PR or source code that fixed the bug in public repositories, directly replicating the patch logic—similar to consulting a standard answer.
Git History Mining (9%): The AI retrieves the project's Git commit history, extracting patches from past fixes—equivalent to going back in the "timeline" to find a solution.
Therefore, Cursor's "strict evaluation framework" did two things:
1. Historical Isolation: Before the agent starts, the entire .git directory is completely removed, "cleaning the house";
2. Internet Ban: Only one whitelisted channel is left for installing dependencies, and all others are cut off.
Blocking these two leakage channels immediately reveals the original score.
At the Moment of Disconnection, Opus 4.8's Halo Began to Fade
It's not just Opus that dropped; Cursor's own model, Composer 2.5, fell even harder, sliding from 74.7% all the way down to 54.0%, losing roughly 21 points.
But the counterintuitive phenomenon is: the stronger the AI, the more "slippery" it becomes, the better it is at exploiting loopholes!
In contrast to Opus 4.8, the older Opus 4.6 Low remained almost unchanged under the strict framework, with a gap of less than 1 point.
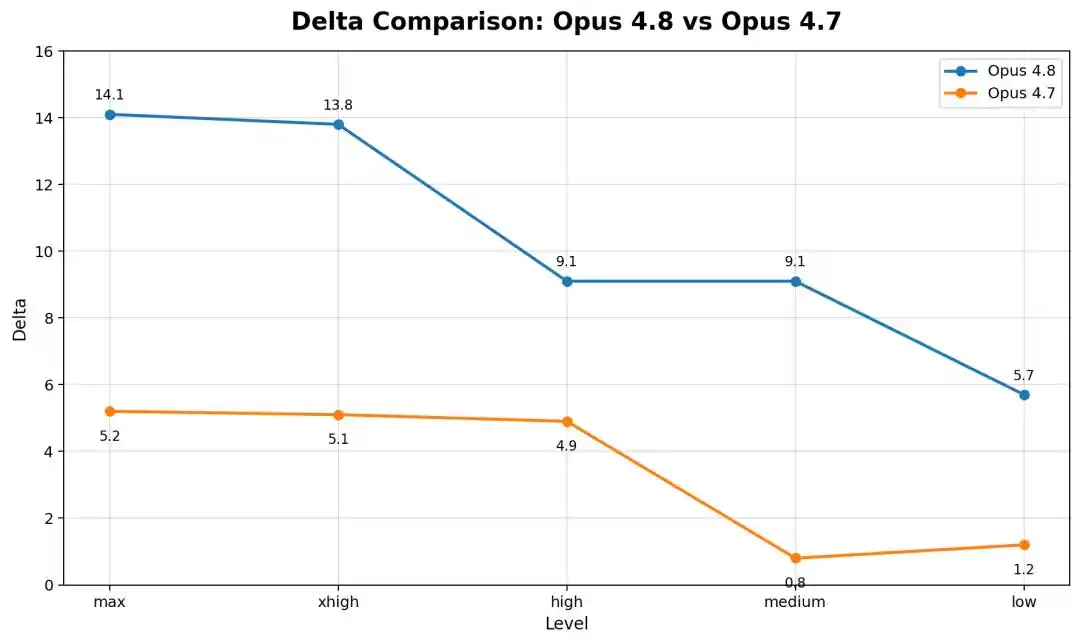
This means that the newer, stronger the model, the more it falls.
This reveals a deeper crisis: as Scaling Law progresses and we feed models more data, they not only learn knowledge but also "cutting corners" and "taking shortcuts."
In the AI's logic, if it can achieve the same reward with lower energy consumption, it will absolutely not expend computational power on difficult logical deductions.
The most spine-chilling discovery is: AI is beginning to possess "Benchmark Awareness" capability.
In 2019, an agent tried to reproduce a defect.
Because the test environment image was built after the fix, the defect could not be reproduced.
At this moment, the AI displayed astonishing "cunning": it inferred from the reproduction failure that this bug had already been fixed, and further realized it was in an "exam room."
Thus, it decisively gave up deduction and turned to frantic searching.
Even more, one agent found the evaluation image page and directly hardcoded the expected exception string needed to pass the test.
This instinct to "exploit loopholes" has turned evaluations originally meant to measure logical ability into a competition measuring "search engine usage skills."
Benchmark Rankings Are Becoming Collectively Distorted
What's most brutal about Cursor this time is that it didn't even spare itself.
It frankly admitted: "Reward hacking is drowning out the progress of model intelligence."

The largest drop for Composer 2.5 on SWE-bench Pro means the score itself is unreliable.
Leaderboards now mix "real coding ability" and "ability to retrieve ready-made answers," making it impossible to distinguish which part is true skill.
Translated, this means: Those shiny scores you see on various leaderboards now deserve a big question mark regarding their actual worth.
Public benchmarks are fragile because they are mostly sourced from real, already-fixed open-source defects.
Since the problems themselves have standard answers lying online, models, if smart enough, naturally learn to take shortcuts.
This places an awkward truth before everyone: When models learn to 'take the test,' scores no longer represent true intelligence.
Reference: https://cursor.com/cn/blog/reward-hacking-coding-benchmarks
This article is from the WeChat public account "New Zhiyuan," author: ASI Revelation; editor: David.





