Author: Oluwapelumi Adejumo
Compiled by: Luffy, Foresight News
TL;DR:
- Total trading volume for Polymarket's World Cup event contracts surpassed $3.3 billion, far exceeding this year's Super Bowl prediction market volume.
- France and Argentina lead the markets for champion and finalist, with traders betting on a repeat of the 2022 final.
- About $1.6 billion in trading capital was bet on long-shot teams with less than a 1% chance of winning.
The World Cup has brought one of the largest influxes of sports-related volume in prediction market history, but behind the high trading figures, industry data reveals an unconventional market structure.
Contracts related to the World Cup on the Polymarket platform have accumulated over $3.3 billion in trading volume, significantly outpacing this year's $1.4 billion Super Bowl prediction market volume. This gap vividly illustrates the rapid penetration of event trading into mainstream sports: soccer's global market coverage, longer tournament cycles, and the extended trading window platforms receive compared to single championship games.
It's not just Polymarket experiencing a boom; trading volumes for soccer-related contracts, including match outcomes and World Cup winner predictions, have also surged on other prediction trading platforms like Kalshi.
However, capital hasn't concentrated solely on the highest-probability favorites. As the tournament entered the Round of 32, the prediction market displayed a polarized structure: fierce competition among top contenders alongside substantial capital still being bet on long-shot teams with very low win probabilities.
France, Argentina Lead the Market, Betting on a Repeat of the Last Final
France emerged as the top favorite to win the 2026 World Cup, with Argentina close behind. Polymarket data shows France's implied probability of winning is 23%, Argentina's is 21%, firmly placing the two finalists from the 2022 Qatar World Cup at the top of the list. Spain ranks third at 11%, England fourth at 10%, and Brazil fifth at 6%.
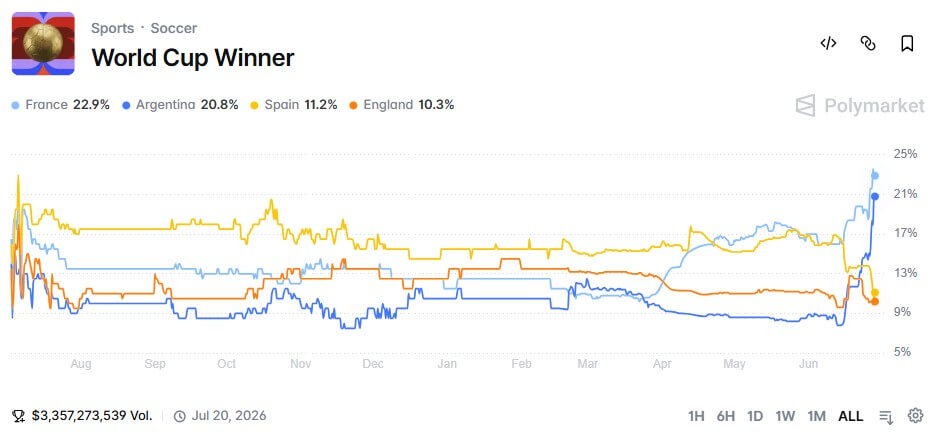
The trends for contracts predicting finalists are highly similar. France leads with an implied 39% probability of reaching the final, followed closely by Argentina at 38%, with Spain in third at 23%. The market pricing reflects a widespread belief among traders that the 2022 final script, where Messi led Argentina to victory, might replay itself.
The capital volume for popular teams clearly demonstrates market focus: Argentina's champion contract saw $81 million in volume, France $77 million, Portugal $76 million, Spain $68 million, and England $61 million. While this data proves strong demand for trading popular assets, it cannot explain the market's imbalanced capital structure.
$1.6 Billion Flows into Long-Shot Teams
Approximately $1.6 billion in trading capital was bet on teams with a 1% or lower implied probability of winning. This capital accounts for two-thirds of the total champion contract volume, even though these teams are theoretically almost certain not to win.
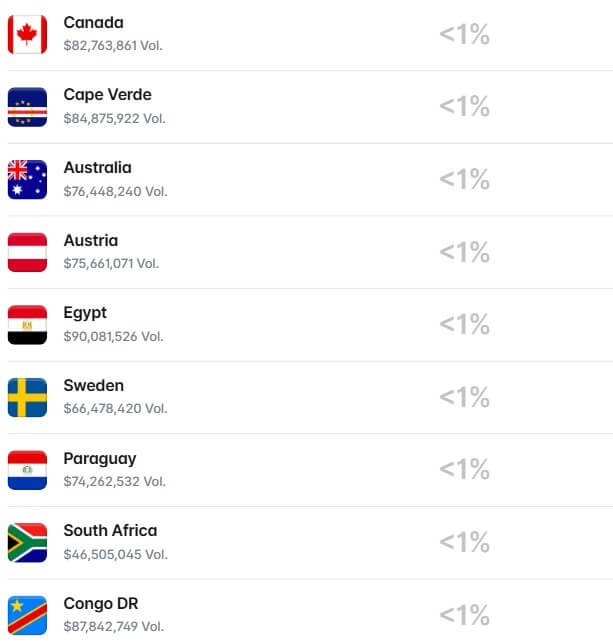
Several long-shot teams boast surprisingly high historical trading volumes: Ivory Coast at $101 million, Mexico at $97 million, Egypt at $90 million, Cape Verde at $87 million, and Morocco at $82 million.
This disconnect between trading volume and win probability exposes unique characteristics of prediction markets. High trading volume for a contract does not necessarily indicate that current traders broadly favor that outcome; it may simply reflect significant trading that occurred earlier in the tournament when odds hadn't shifted drastically.
Additionally, some positions stem from pure long-shot speculation, fan-driven emotional buying, hedging/arbitrage strategies, parlay bets, or historical positions left open by users. This can make some assets appear actively traded while being completely disconnected from current market sentiment.
Traditional sports betting resets odds as events unfold, while prediction market contracts continue trading until settlement or user closing, allowing capital to remain locked in positions for long-shot teams the market has long written off. This feature is particularly pronounced in this World Cup cycle.
Comparing top favorites highlights the market's polarization. A portfolio buying the five favorite teams—France, Argentina, Spain, England, and Portugal—currently costs only $0.72, paying out $1 if any of them wins. This trade reflects highly concentrated market confidence, yet tens of billions remain distributed across other long-shot assets.
From this perspective, World Cup trading leaderboards are not just win probability rankings but also a complete record of traders' full-cycle actions: entry timing, long-dormant positions, and liquidity that wasn't fully unwound.
Prediction Markets Experience Broad-Based Boom
The World Cup sports wave is driving accelerated institutionalization and user scaling across the entire prediction market sector. Wall Street investment bank Bernstein predicts total platform betting volume related to the tournament could surpass $10 billion before the final on July 19.
The sports frenzy is also spilling over into non-sports contracts. Latest data from venture firm a16z shows that combined trading volume for non-sports contracts—covering geopolitics, macro data, elections, etc.—on the Kalshi and Polymarket platforms has reached $3.6 billion.
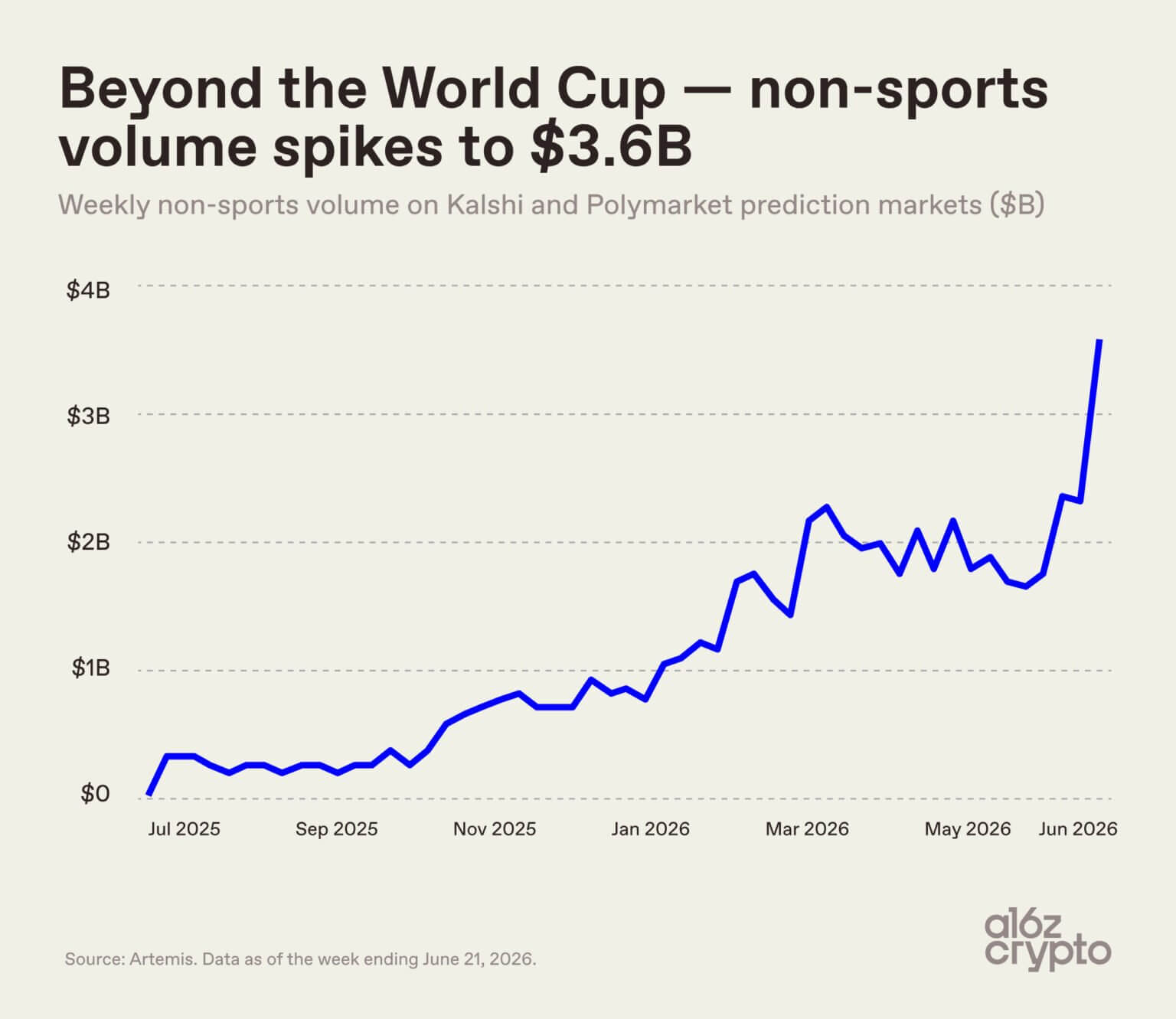
a16z notes that the current trading volume for the non-sports sector alone already exceeds the total size of the entire prediction market industry a year ago. In July 2025, weekly non-sports volume was just $200 million, representing an 18-fold increase over 12 months.
According to a16z statistics, total weekly prediction market volume hit a record $14.5 billion last week, with open interest remaining at a record $1.6 billion for three consecutive weeks.
Regulatory Scrutiny Continues to Tighten
As the commercial scale of World Cup trading markets reaches new heights, the industry is facing a new wave of legal and regulatory scrutiny. According to *The Wall Street Journal*, the U.S. Commodity Futures Trading Commission (CFTC) has launched an investigation into Polymarket.
Consumer protection agencies and regulators in multiple U.S. states continue to call for stricter oversight of prediction platforms. The rapid expansion of businesses like Polymarket and Kalshi, where users can bet on a wide range of events from sports and elections to cryptocurrency prices and financial market trends, has drawn attention.
This investigation brings significant uncertainty for Polymarket. The platform was penalized by regulators in 2022 and subsequently banned U.S. users, only partially resuming U.S. operations last year.
The timing of increased regulatory scrutiny is particularly sensitive as prediction market volumes repeatedly break records. Regulators are now closely examining platform operating models, consumer protection mechanisms, and clarifying the regulatory boundary between compliant event contracts and illegal gambling.





