特朗普对加密产业的托举,堪称尽心尽力。
就在上周,特朗普又祭出大杀器,签署一项行政令,允许401(k) 退休储蓄计划投资更多元化的资产,包括私募股权、房地产以及首次引入的加密资产。这意味着,高达8.7万亿美元的退休金将有可能触达到加密资产。而这一事件,无论是对于加密领域还是养老金本身而言,都有着相当深远的意义。
有趣的是,该种放在以往分分钟拉盘的大利好,在如今的加密市场,体现得却并不多。在信息公布的当天,BTC表现仍然非常稳定,但与之相反的是,ETH却罕见迎来了迅速上扬。
要论及行政令对于加密市场的影响,要先从美国的养老金体系聊起。纵观美国的养老金体系,主要由三部分组成,一是以政府为主体管理的全民计划,通过社会保障税筹集资金;二是由个人自愿参与的个人退休金计划,类似我国现行的个人养老金计划;第三,就是本篇的主角,以企业为主体进行管理的401(k)计划。在三大主体的覆盖下,美国基本形成了以社会保障税为基础、以401(k)为重点、以个人养老金为补充的多层次养老金体系。
具体解释401(k),其指根据1978年《国内税收法》第401条K项设立的私人企业退休福利计划,由雇主与雇员共同缴费,雇员可自主选择投资组合并享受税收递延优惠,退休后灵活支取账户资金。
从条款本身来看,401(k)和我国的企业年金制度类似,由企业和员工双方共同缴纳,但值得一提的是,与我国通常纳入统一管理的模式不同,企业通常会有固定合作的基金公司,而员工可以自行控制个人账户,并选择将其养老金投资于指定基金中的各类产品中,但需自负盈亏。
尽管401(k)并非全民政策,且显然难以覆盖完整的退休资金需求,但考虑到将近6成美国家庭拥有401(k),这一计划已然成为了美国养老制度的核心所在。这笔资金,自然也相当可观。发展至如今,根据公开数据显示,截至2025年3月31 日,所有雇主主导的缴费确定型(DC)退休计划总资产已高达 12.2 万亿美元。其中,401(k) 计划持有8.7万亿美元。
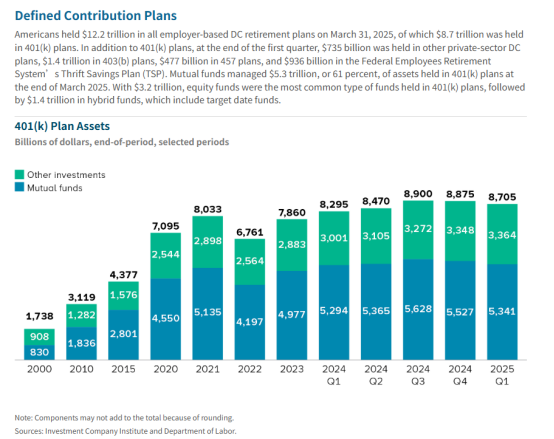
问题也来了,8.7万亿美金流入何方?
从目前资金流向来看,股票基金是401(k)中最常见的基金类型,总计有5.3万亿美元由共同基金管理,其中股票基金占据3.2万亿美元,混合型基金拥有1.4万亿美元。股票囊括其中,可以看出,基金可投资的范围并不局限于传统的保守型标的。
实际上,鉴于养老金的特殊性质,养老金体系投资的标的也经历了从绝对保守到收益导向型的多次变化。在大萧条前,养老金被限定于投资诸如政府债券、优质公司债券和市政债券等低风险资产。随后在大萧条的腥风血雨后,养老金体系受到毁灭性打击,且回报率日益走低,部分私人信托提出“谨慎人规则”,允许多元化资产追求更高回报,并由此开始影响至各州,股票投资开始兴起,最终1974 年《雇员退休收入保障法》将谨慎投资者标准应用于公共养老金,正式放开了养老金在股权市场的限制。
来到2025年,这一限制被进一步打破。就在当地时间8月7日,特朗普签署了一项行政命令,允许美国人的401(k)计划投资私募股权基金、比特币等加密货币以及其他所谓的另类资产。特朗普还要求劳工部长Lori Chavez-DeRemer与财政部、证券交易委员会(SEC)及其他联邦监管机构的对口官员合作,确定是否应修改规则来协助这项工作,并指示SEC为参与者自主投资的养老金计划提供纳入另类资产的便利。

仅从政策角度而言,无论是对于养老金抑或是对于加密市场,该指令都将带来深远的影响。从养老金角度,此举将加密货币、私募股权等另类资产纳入投资范围,在拓宽养老金多元投资渠道的同时,也引入了更大的风险与波动,意味着养老金投资体系由相对保守向高度开放的进一步转换,流动性差且结构复杂的产品也将被涵盖其中,这已然是养老金制度上的一次激进式改革。
对于加密市场而言,意义则更为重大,这是加密资产主流化的跨越式发展,在养老金可接受的前提下,加密资产毫无疑问的收获了更高层级的“国家级”背书。从产品角度,以ETF为壳包装的加密资产产品可预见式井喷,而更值得注意的是,加密资产持有者的结构式变化。鉴于养老金通常换手率较低且持有周期较长,Vanguard报告显示,2024年401(k) 平均交易频率为0.5次/月,这意味着当该笔资金进入加密市场后,资产底部的价格支撑将被进一步夯实,换而言之,若该类资金大量进入以BTC与ETH为主的ETF中,主流币种的波动率反而会显著降低,上述资产的性质反而会从风险资产向避险资产转变。中长期来看,这一行政令将会推高市场规模,毕竟高达9万亿的资金,即便仅仅5%,也有0.45万亿的骇人数字。
然而,带来的影响越大,市场上的声音自然也更大。传统金融参与者就表示,另类资产收费高且流动性差,对于资产管理公司而言的确蕴含巨大机会,也将更有动力将其纳入投资组合中,而该类资产也伴随着更低的信息披露要求,但对于远离市场的个人投资者,其甚至难以了解透彻资产属性与风险就将资金投入其中,两者间的信息不对称,极有可能大幅损害投资者的利益,进而增加一系列法律风险。此外,值得一提的是,尽管行政命令已下,付诸实践也还需一定时间,对于负责产品开发的资产管理公司而言,新产品普及通常也需要数年的时间。
或许正是出于上述原因,在这一重大行政令发布后,市场并未如预期般激动,反而存在一定滞后效应。BTC仅在24小时内上涨2%,但从资金流入来看,无论是现货成交量还是BTCETF,都未在此消息下出现24小时内的明显提升,但时间来到8月11日后,BTC反而上涨突破了12.2万美元。
有趣的是,以太坊却有着截然相反的趋势。在养老金信息公布后的24小时内,ETH现货成交量显著提升,同时价格迅速上涨,从3600美元一路飙升,并在8月8日突破4000美元,而来到如今,ETH已然来到了4299美元,这一轮的涨幅,再度超过了BTC。ETF也有增持现象,ETH ETF在两日中资金净流入增加6.8亿美元。
可以看出,虽然两者出现同步上涨,但ETH涨幅要更为灵敏且迅速,对此,市场也有声音表示资金似乎正在从比特币流入到以太坊中。衍生品市场也有类似趋势。芝加哥商品交易所(CME)的以太坊期货相对于现货的年化溢价已超过 10%,高于比特币的水平,这促使部分交易员将头寸从比特币转向以太坊。
仅从ETH/BTC交易对来看,尽管在近日有所提升,但量能尚未显著高出平均水平,吸血论暂且难以有足够论据。至于为何ETH更为灵敏,或许也有着多方面的原因。
一是机构屯币潮的增长贡献,以ETH为核心的加密财库企业已然储备了价值约130亿美元的以太坊,相对价格更低的ETH,资金的流入带来的增长也更为明显。二是大型ETF机构的支持,ETH ETF在今年吸引了超过67亿美元的净流入,且有了资管巨头贝莱德这一强力靠山,而强庄的核心所在,恰巧是SEC所构建的“金融市场全部上链”蓝图,在这一方针下,作为公链龙头的以太坊是直接受益者;三则是场外的喊单之声,例如上周Bitmine董事会主席Tom Lee的激情喊单就是典型案例,其在播客中畅谈以太坊的未来发展,并认为ETH能达到1.5万美元,这一18万次播放的视频似乎在吸引散户上表现亮眼。
相比于蒸蒸日上的BTC与ETH,山寨市场走向却仍不显乐观。从市值而言,ETH突破久违的4000美元,山寨币也有跟涨趋势,市值相比上周上涨超过15%,但细究其中,除了为数不多的蓝筹山寨有所上扬外,超过70%甚至80%的山寨币仍然非常低迷。
原因也显而易见,ETH的涨幅源自机构的真金白银而非加密市场的自有资金,而在现下流动性并不充裕的背景下,机构投资标的选择也更为稳健,更倾向于风险可控的币种,这带来的影响是资金难以溢出至山寨市场,换而言之,资金驱动的以太坊上涨难以传导到山寨币。实际上,市场上已有“当前的ETH是去年的BTC”论调,此言确有一定道理。当然,全面山寨或许难以再现,结构性山寨牛市还是存在机会,而这,则要依靠投资者自身的嗅觉。
幸运的是,另一值得期待事件即将来临。美国劳工部发布的7月非农就业人数增长大幅低于预期,且失业率小幅上升,使得降息的可能性大幅度提升。当地时间8月9日,美联储监管副主席米歇尔·鲍曼(Michelle Bowman)在最新的讲话中释放两条关键信息, 她支持今年进行三次降息,并将在10月9日主持一次社区银行会议。
而CME“美联储观察”数据披露,美联储9月维持利率不变概率为11.6%,降息25个基点概率达88.4%。
Twitter:https://twitter.com/BitpushNewsCN
比推 TG 交流群:https://t.me/BitPushCommunity
比推 TG 订阅: https://t.me/bitpush





