The most brutal thing about AI is not that it withholds answers from the poor.
On the contrary, it gives everyone answers.
It gives students paper outlines, employees email templates, entrepreneurs business plans, and ordinary people legal explanations, investment advice, and career guidance. For the first time, answers have become so cheap, abundant, and deceptively real.
But the problem lies precisely here: when answers are accessible to all, what truly becomes scarce is no longer the answer itself, but the ability to judge the answer.
The new information poor are not those excluded from AI. They are the ones who have already received the answers but lack the ability to judge them, and also lack the conditions to translate those answers into real opportunities.

I. The Information Divide in the AI Era
The information poor of the internet era were those excluded from the network. The solution seemed clear: install internet cables, popularize devices, improve literacy. The search engine era was slightly more complex; you needed to learn how to refine keywords, filter sources, judge credibility, and preferably know some English. But the threshold was visible and quantifiable.
The information divide of the AI era has a completely different structure.
Large language models are not search engines; they directly generate conclusions for you. You no longer need to "find" answers—answers are organized into fluent paragraphs, clear steps, and a confident tone, delivered to your eyes. Superficially, the threshold is greatly lowered. But here lies a cold structural truth: as answers become cheap, errors also become cheap; while the ability to discern "whether this answer is trustworthy" becomes more scarce and valuable than ever before.
Every wave of diffusion of a general-purpose technology in history follows the same logic: new technology first rewards those who already possess complementary capital. The printing press first benefited the literate; computers first benefited those who knew office software and programming; the internet first benefited those with strong English skills and proficient search abilities. The complementary capital for AI includes educational background, professional knowledge, critical thinking, organizational authorization, payment ability, and the most difficult to quantify of all—judgment.
New technology rarely first rewards those who need it most. It usually first rewards those who can best utilize it.
II. First to Diverge: The Path to AI
The first crack of inequality is drawn even before you open the app.
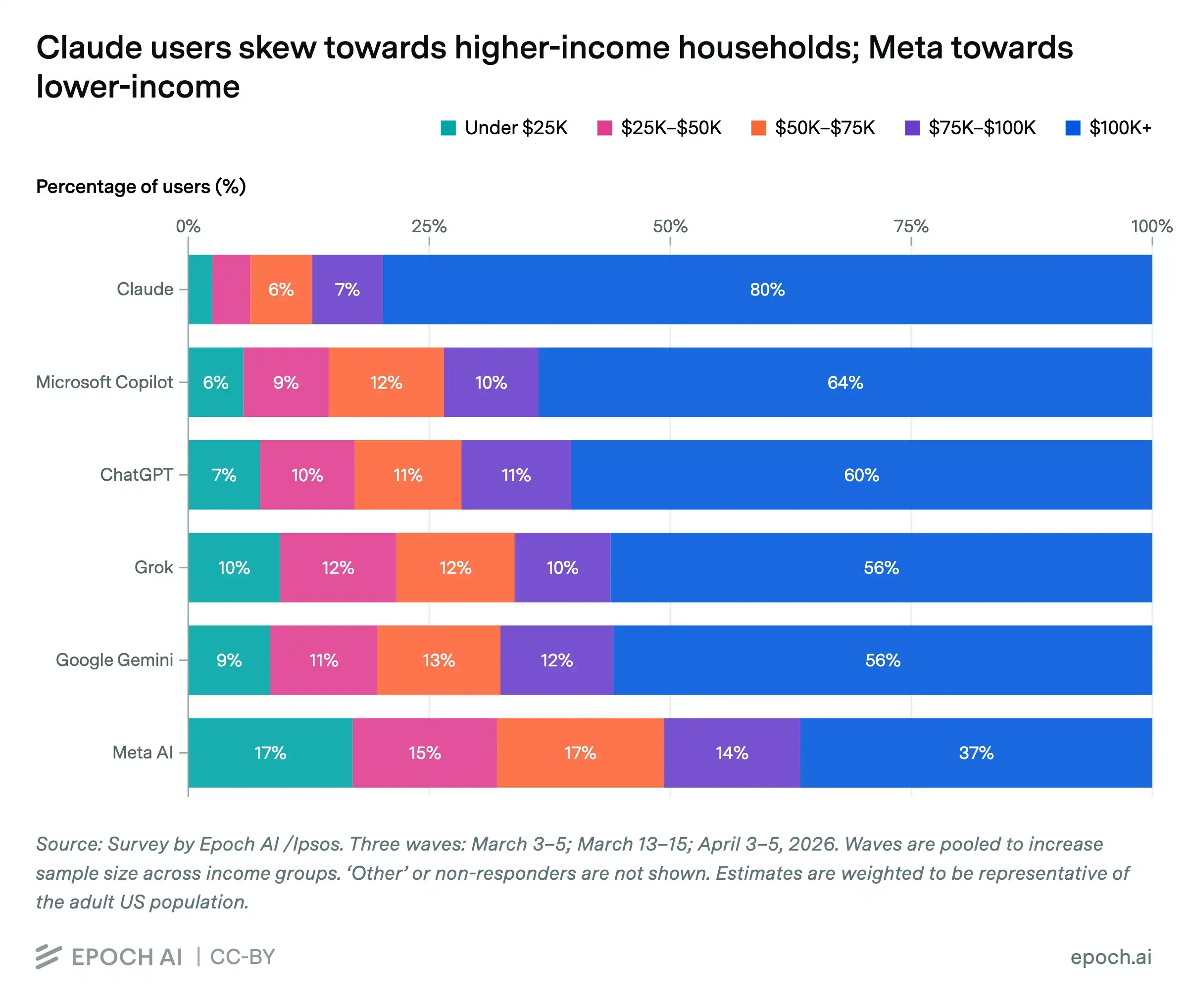
In April 2026, the AI research institute Epoch AI and the polling company Ipsos released a questionnaire survey targeting about 5,000 American adults. Across three rounds, the questionnaire asked one seemingly ordinary question: In the past week, which AI services have you used? But the answers presented were not simple product preferences; they were a map woven from income, access, and distribution.
Among Claude's weekly active users, about 80% come from households with annual incomes over $100,000; among Meta AI users, this proportion is only 37%. Conversely, among Meta AI users, about 32% come from households with annual incomes under $50,000, while among Claude users, this proportion is a mere 7%.
These numbers are important not because they prove that "the rich use premium AI, the poor use free AI." That is the most superficial reading. What is more worth questioning is: Why do different people encounter different AIs in their daily lives?
One person asks AI to create a dinner from leftovers in the fridge, brighten the background of a photo, and rewrite a text message more appropriately. Another asks AI to organize client interviews, compare supplier quotes, and identify weak assumptions in a report. Both are invoking the same technology. But one kind of invocation stops at convenience, while the other enters the cycle of income, position, and bargaining power.
The difference lies not only in the users, but also in the points of access. The path to using Claude requires proactive searching, product comparison, understanding capability differences, choosing to pay, and then embedding the tool into a workflow—each step filters people. The path to Meta AI is almost the opposite: it is built into social platforms, free, low-friction, and users often encounter it passively while browsing feeds, sending messages, or viewing photos.
This is not a market about taste, but a market about distribution. Users seem to be choosing tools, but the price and access of the tools are also selecting users.
Source: epoch.ai
III. Then Diverge: The Scenarios for Using AI
Even if you find a good AI tool, the second diversion awaits you within companies.
In ordinary offices, the arrival of AI rarely appears in the form of a "layoff notice." It first takes over meeting minutes, email drafts, spreadsheet organization, customer categorization, and draft reports. For managers, this automation frees up time for them to make judgments. For newcomers and junior employees, this automation takes away precisely the entry points where they prove themselves, practice judgment, and advance to higher-level work.
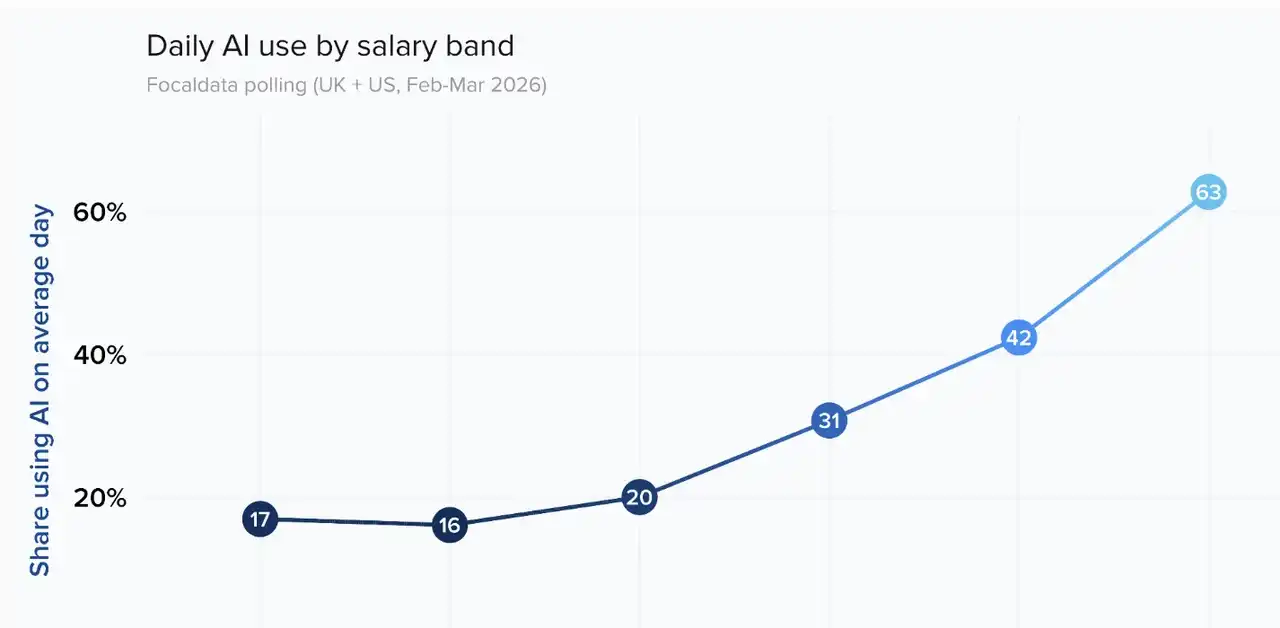
The data is colder than this scenario: A joint AI workforce tracking survey by the Financial Times and a research institute (covering over four thousand respondents in the UK and US from February to March 2026) showed that among the highest-paid workers, 63% used AI on a typical workday, while the proportions in the two lowest pay brackets were only 17% and 16%, respectively. This is not a gentle slope; it is a cliff.
A more crucial finding lies in the driving factors. Regression analysis from this workplace survey revealed that after controlling for other variables, the effect of salary on AI usage rates almost disappeared—what truly mattered were four factors: age, seniority, industry, and training. Among these, training had the greatest effect: a company that provided formal AI training had employees with a daily AI usage rate 37 percentage points higher than similar companies without training. Even informal guidance yielded a 24 percentage point increase.
However, the reality is: As of early 2026, only 14% of employees reported having received formal AI training from their employers, while two-thirds had not received any form of training at all.
AI training is not a technical issue; it is a distribution issue. Those selected for training are permitted to enter the track of productivity growth; those who are not, have a tool that is merely an icon on their screen they are not authorized to open.
AI is an application on the consumer end, but it is a permission on the workplace end. And permissions have never been equally distributed.
Source: Focaldata
IV. Finally Diverge: The Ability to Judge AI
This is the most concealed diversion, and also the most fundamental one.
Imagine a recent graduate who has just joined a consulting firm. He uses AI to generate a first draft of an industry analysis report. It's structurally complete, data-rich, and confidently worded. His supervisor—someone with ten years in the industry—glances at it and points out that two of the data references have methodological flaws in their original sources, and the causal inference behind a third conclusion is problematic. The supervisor isn't more diligent than him; it's because he possesses that foundational layer—knowing where errors are likely, knowing which kind of fluency is genuine and which is just the machine filling blanks.
This is the real meaning behind the counterintuitive finding in the workplace survey data: the heaviest users of AI at work are not the youngest employees, but those who have already been in their current position for 2 to 10 years. The relationship between AI usage and seniority remains significant even after controlling for age. This is not because young people don't want to use it, but because the value of AI is highly dependent on the user's pre-existing judgment capabilities.
Experience is the most important complementary capital for AI, and experience cannot be subscribed to.
AI lowers the cost of "sounding knowledgeable," but it does not equally lower the cost of "truly knowing." There's an even more dangerous consequence: the less foundational knowledge a user has, the more likely they are to accept AI's output wholesale; and the more they accept it wholesale, the harder it is for judgment to grow. When an agent makes judgments for you, you are consuming intelligence, not accumulating it.
Nobel laureate in economics and MIT professor Daron Acemoglu is blunt about this: using AI tools requires a certain level of education, abstract thinking, quantitative ability, and familiarity with technology. "It is almost certain that AI will increase inequality," he says.
This is where the new information poor take shape: they are not those without AI, but those who have AI, have access, have answers, yet lack the training to judge those answers; who have tools, have scenarios, yet lack the permission to turn tool output into opportunity; who consume intelligence every day, yet have never accumulated intelligence themselves.
V. The Boundaries of Equalizing Effects
However, AI's relationship with inequality is not solely about widening gaps.
Multiple experimental studies have found that under controlled conditions, AI often provides a greater boost to lower-skilled individuals—for call center employees, junior writers, and entry-level consultants alike. This is not hard to understand: the marginal gain for top experts from AI is limited; for someone who has never been able to afford professional services, using AI to understand a contract for the first time is itself a qualitative leap.
But a crucial distinction needs to be pointed out here: experimental studies measure "improvement after use," while real-world data measures "who actually uses it," "who is allowed to use it," and "who can turn the results into opportunities after use." Neither set of data is lying; they are measuring entirely different things.
A technology can narrow gaps in the lab, while simultaneously widening them in the real world—if adoption itself is unequal, if the scenarios themselves are unequal, if judgment itself is unequal.
AI possesses the technical characteristics to equalize, yet operates within an unequal social structure. Both points being true simultaneously is the real shape of the problem.
VI. Technology Will Spread, Benefits Won't Arrive Simultaneously
Every generation tends to believe that the general-purpose technology of their era will break the old order.
After the printing press appeared, the literate benefited first for centuries. In the early days of computer proliferation, it amplified the abilities of those who already knew office software and how to code. The early dividends of the internet flowed to those who knew English, could search, and had the time and motivation to arbitrage. In every technological wave, voices declaring "this time is different" have been loud, while structural diversion often took decades to become slowly visible.
AI's diversion may be faster, and its forks deeper. Because it affects not just one type of task, but almost all work relying on judgment and language. And this is precisely the type of ability that is hardest to standardize and hardest to redistribute.
Some believe the gap will eventually narrow. Economic historian and Oxford Internet Institute professor Carl Benedikt Frey holds this view, based on history: the inequality brought by computer proliferation gradually resolved over decades as usage thresholds fell. This analogy is not without merit.
The problem is, even accepting this optimistic historical analogy, Frey himself acknowledges a key qualifying condition: "It depends on how long it takes for the gap to close. If it's ten or twenty years, that's more concerning."
Ten or twenty years is not a time scale that can be easily waited out—especially for those who need to find jobs, negotiate salaries, and accumulate experience during that period.
Conclusion
This is a peculiar historical moment: for the first time, we possess a technology that can make everyone feel like they are becoming smarter.
This feeling is often the end point.
The problem is, in an era where outcomes are truly decided by judgment, mistaking that feeling for the end point might be the most expensive mistake of all.






