回顾整个过程,很可能是因为 Mt. Gox 用户被盗 2.5 万 BTC 后,科技媒体增加了对比特币的关注,然后我又在这个过程中关注到了这个事件并创建了第一个比特币钱包。
Google Reader & Dropbox:我的数据宝库
你可能听过很多关于「在某年买了某些比特币,但后来私钥丢了」的故事。但幸运的是,我很喜欢备份和存档数据,所以凭借着之前存档的数据,我把当年第一次创建比特币钱包、领取比特币的过程给还原了出来,甚至我还翻出了一些当时媒体报道的比特币的文章,包括科技媒体、果壳网、CoolShell。
对于一个发生在十多年前的事情,要复原它其实并不是这么简单。毕竟在这十几年中,我的笔记本电脑都换了很多台,就算我有经常备份数据的习惯,也可能会丢失很多数据,甚至连备份介质都不一定可靠(比如硬盘和光盘也都有其寿命)。
而这次得以恢复数据,主要靠的是 Google Reader 和 Dropbox。Google Reader 是一个 RSS 阅读工具,当时我主要用它订阅一些科技媒体、设计和生活类的博客等。对于优质的内容我经常会用收藏功能,方便之后查阅。后来 Google Reader 在 2013 年 7 月停止运营,不过他们提供了数据导出功能,我就把我所有收藏的内容导出了,然后存在了 Dropbox 中。
之前还没想过这个数据会有什么价值,但是没想到被十多年后翻出来还是能找到一些蛛丝马迹的。
数据挖掘:追溯报道比特币新闻的足迹
我从个人的 Google Reader 存档文件中检索了所有与「BTC」、「比特币」、「Bitcoin」相关的数据,找到了近 10 篇相关的文章,目前仍有 5 篇可以访问。
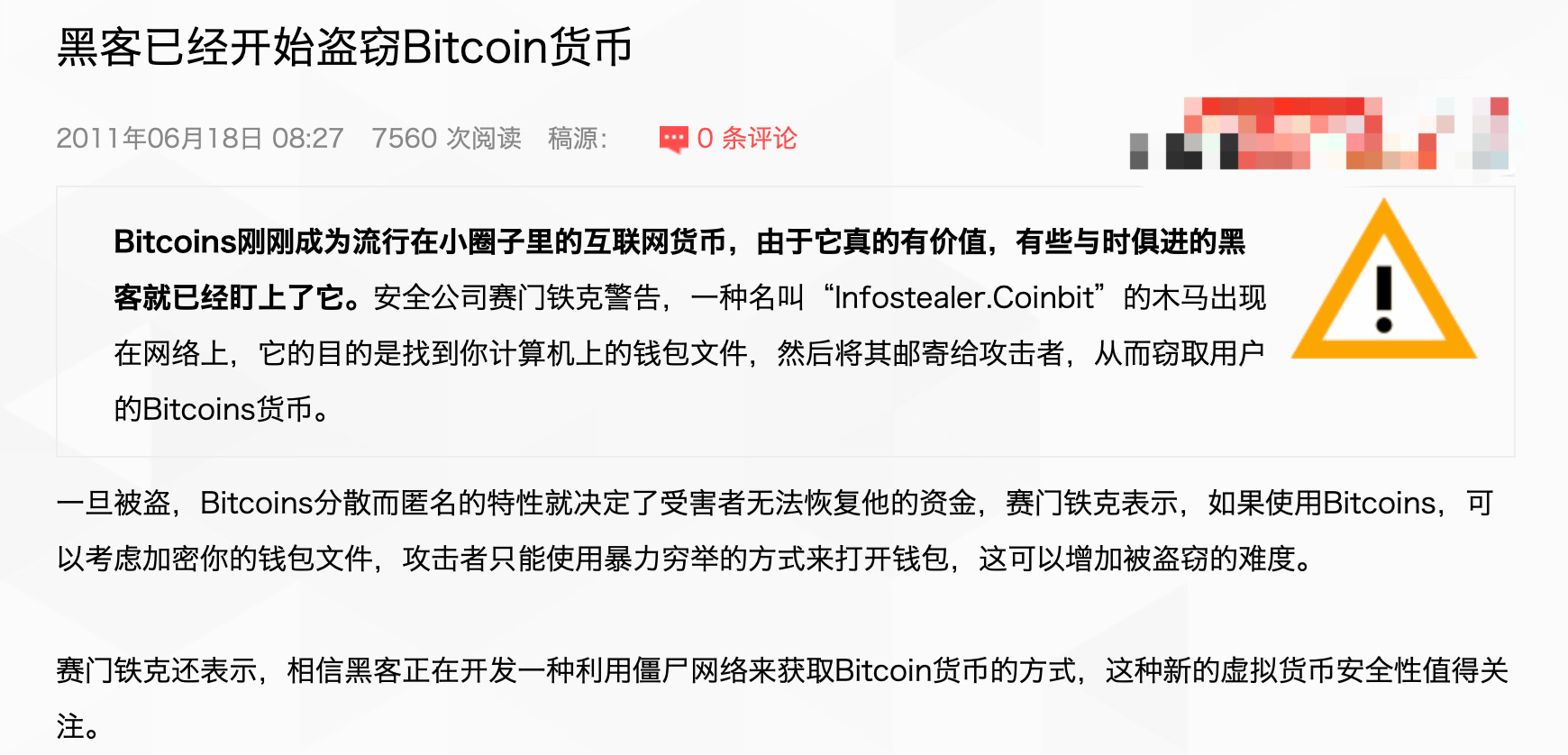
最早的一篇: 2011 年 6 月 18 日
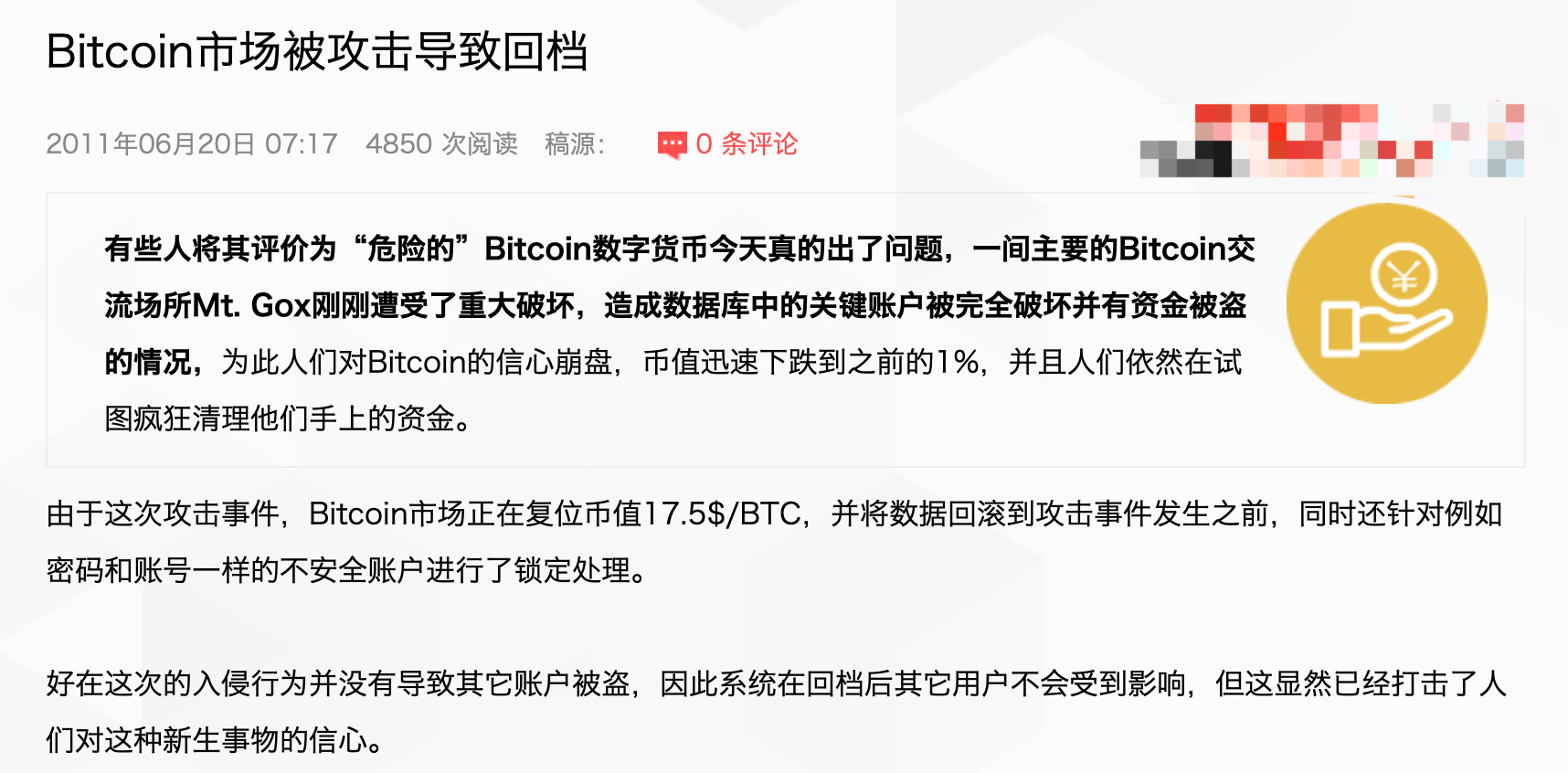
两天后,还有两篇类似的: 2011 年 6 月 20 日
酷壳: 2011 年 8 月 11 日
酷壳 CoolShell 的陈皓(又名左耳朵耗子,也就是今年 5 月意外去世的技术专家,他时常批评比特币)在一篇文章中提及比特币和其分叉项目 Namecoin。
果壳网: 2011 年 12 月
果壳编译发布 WIRED 的文章《比特币兴衰史》。
https://www.guokr.com/article/76729/(果壳编译的中文版)

为何创建比特币钱包
比特币在 2011 年时并没什么交易价值。当时,一些比特币爱好者为了推广和扩大比特币的影响力,创建了各种「水龙头(faucet)」网站,好奇的用户可以通过简单的操作,如填写验证码(抗女巫),免费领取一定数量的比特币(约 0.01 BTC)。
于是我当时也在寻找和浏览了一些水龙头网站后,成功领取了 0.01 BTC。 又因为备份数据的习惯,我也保存了这个比特币钱包的私钥文件至今。
后来当我把这个文件从硬盘中翻出,找出公钥和私钥,并通过区块浏览器搜索后发现,领取水龙头的时间是正好是 2011 年 6 月 18 日,也就是我收藏的那篇《黑客已经开始盗窃 Bitcoin 货币》文章的同一天。
其实 2011 年 6 月是一个很特殊的时间,正好是著名交易所 Mt. Gox 失窃的时间。
On 13 June 2011, the Mt. Gox bitcoin exchange reported some BTC 25, 000 (US$ 400, 000 at the time) had been stolen from 478 accounts. (Wikipedia)
包括上面 cnbeta 网站的文章中也提及了这次事件,所以很可能是因为 6 月 13 日的被盗事件让科技媒体增加了对比特币的报道,因此被更多人关注到。而我也因为这个负面事件,最终创建了比特币钱包并领取了比特币「空投」。
结局
虽然持有着这个地址的私钥,但我依然一无所有。哪怕至今持有这 0.01 BTC,也并不算什么。
根据区块浏览器来看,我这个比特币钱包中的 0.01 BTC 在 2013 年 11 月转出了,至于当时为什么要转出,以及转到哪里了,我暂时也没找到确切的线索。但我的确记得当年好像做过什么操作,可能是换钱包,或转去了交易所。
所以这其实是一个悲伤的故事,从 2011 年接触到比特币,到 2017 年再次关注和进入这个行业,已经过去了 6 年的时间。这件事对于我自己的启发是,或许我们现在还能有机会接触或瞥见一些极具潜力的新技术,但它可能真的需要更多的时间,才能被社会接受和理解,而我最适合做的就是继续保持好奇心,加上一点耐心。





