Judul Asli: A shallow dive into formal verification
Penulis Asli: Vitalik
Kompilasi Asli: Peggy, BlockBeats
Catatan Editor: Dengan kemampuan pemrograman AI yang meningkat pesat, keamanan perangkat lunak sedang menghadapi sebuah paradoks baru: AI dapat menghasilkan kode dengan lebih efisien, tetapi juga dapat menemukan kerentanan dengan lebih efisien. Bagi industri kripto, masalah ini sangat krusial. Begitu ada cacat dalam kontrak pintar, bukti ZK, algoritma konsensus, atau sistem aset on-chain, konsekuensinya sering kali bukan sekadar kesalahan perangkat lunak biasa, melainkan kerugian dana yang tidak dapat diubah dan keruntuhan kepercayaan.
Apa yang dibahas Vitalik dalam artikel ini adalah justru jalan lain untuk keamanan kode di era AI: verifikasi formal. Sederhananya, ini bukan bergantung pada auditor manusia yang memeriksa kode baris demi baris, tetapi menulis sifat-sifat yang harus dipenuhi program sebagai proposisi matematika, lalu menggunakan bukti yang dapat diperiksa mesin untuk memverifikasi apakah sifat-sifat tersebut benar-benar berlaku. Di masa lalu, verifikasi formal sering kali terbatas pada bidang penelitian dan rekayasa yang relatif kecil karena hambatan tinggi dan proses yang rumit; namun, dengan AI yang dapat membantu menulis kode dan bukti, metode ini kini kembali memperoleh relevansi praktis.
Inti artikel ini bukanlah "verifikasi formal dapat menyelesaikan semua masalah keamanan". Sebaliknya, Vitalik berulang kali mengingatkan bahwa "keamanan yang dapat dibuktikan" tidak sama dengan keamanan absolut: bukti mungkin melewatkan asumsi kunci, spesifikasi itu sendiri mungkin salah, kode yang tidak diverifikasi, batasan perangkat keras, dan serangan saluran samping juga dapat menjadi sumber risiko baru. Namun, metode ini tetap menawarkan paradigma keamanan yang lebih andal: mengekspresikan maksud pengembang dalam berbagai cara, lalu meminta sistem memeriksa secara otomatis apakah ekspresi-ekspresi ini saling kompatibel.
Ini sangat penting bagi Ethereum. Ethereum masa depan akan semakin bergantung pada komponen-komponen dasar yang kompleks, termasuk STARK, ZK-EVM, tanda tangan anti-kuantum, algoritma konsensus, dan implementasi EVM berkinerja tinggi. Implementasi sistem-sistem ini sangat rumit, tetapi tujuan keamanan intinya sering kali dapat diformalkan dengan relatif jelas. Justru dalam skenario seperti inilah verifikasi formal berbantuan AI berpotensi memberikan nilai terbesar: membiarkan AI menulis kode dan bukti yang efisien, sementara manusia bertugas memeriksa apakah proposisi akhir yang terbukti benar-benar sesuai dengan tujuan keamanan yang diinginkan.
Dari perspektif yang lebih makro, artikel ini juga merupakan respons Vitalik terhadap keamanan jaringan di era AI. Menghadapi penyerang AI yang lebih kuat, jawabannya bukan meninggalkan sumber terbuka, meninggalkan kontrak pintar, atau kembali bergantung pada segelintir lembaga terpusat, tetapi menekan sistem kunci menjadi "inti keamanan" yang lebih kecil, lebih dapat diverifikasi, dan lebih terpercaya. AI akan meningkatkan jumlah kode yang kasar, tetapi juga dapat membuat kode yang benar-benar penting menjadi lebih aman daripada sebelumnya.
Berikut adalah teks asli:
Ucapan terima kasih khusus untuk Yoichi Hirai, Justin Drake, Nadim Kobeissi, dan Alex Hicks atas umpan balik dan tinjauan mereka terhadap artikel ini.
Selama beberapa bulan terakhir, paradigma pemrograman baru dengan cepat muncul di lingkaran riset terdepan Ethereum dan banyak sudut lainnya di bidang komputasi: pengembang menulis kode langsung menggunakan bahasa yang sangat rendah, seperti bytecode EVM, bahasa rakitan, atau menulis kode menggunakan Lean, dan memverifikasi kebenarannya dengan menulis bukti matematika yang dapat diperiksa secara otomatis dalam Lean.
Jika diterapkan dengan benar, metode ini berpotensi menghasilkan kode yang sangat efisien dan jauh lebih aman daripada cara pengembangan perangkat lunak sebelumnya. Yoichi Hirai menyebutnya sebagai "bentuk akhir pengembangan perangkat lunak". Artikel ini akan mencoba menjelaskan logika dasar di balik metode ini: apa yang sebenarnya dapat dilakukan verifikasi formal perangkat lunak, dan di mana batasan serta kelemahannya—baik dalam konteks Ethereum maupun di bidang pengembangan perangkat lunak yang lebih luas.
Apa Itu Verifikasi Formal?
Verifikasi formal mengacu pada penulisan bukti teorema matematika dengan cara yang dapat diperiksa secara otomatis oleh mesin.
Untuk memberikan contoh yang relatif sederhana namun tetap menarik, kita dapat melihat teorema dasar tentang deret Fibonacci: setiap tiga angka, satu adalah genap, dan dua lainnya ganjil.

Salah satu metode pembuktian sederhana adalah menggunakan induksi matematika, maju tiga angka setiap langkah.
Pertama, lihat kasus dasar. Misalkan F1 = F2 = 1, F3 = 2. Dengan pengamatan langsung, terlihat bahwa proposisi ini—"Ketika i adalah kelipatan 3, Fi genap; dalam kasus lain, Fi ganjil"—benar hingga x = 3.
Selanjutnya adalah langkah induksi. Asumsikan proposisi ini benar hingga 3k+3, artinya kita sudah tahu paritas F3k+1, F3k+2, F3k+3 adalah ganjil, ganjil, genap. Kemudian, kita dapat menghitung paritas dari tiga angka berikutnya:
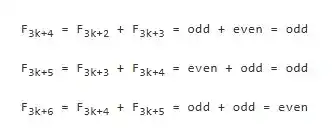
Dengan demikian, kita telah menyelesaikan derivasi dari "mengetahui proposisi benar hingga 3k+3" ke "mengonfirmasi proposisi juga benar hingga 3k+6". Selama penalaran ini diulang, kita dapat yakin pola ini berlaku untuk semua bilangan bulat.
Argumen ini meyakinkan bagi manusia. Namun, bagaimana jika yang ingin Anda buktikan seratus kali lebih kompleks, dan Anda benar-benar ingin memastikan tidak melakukan kesalahan? Di sinilah Anda dapat membangun bukti yang juga dapat meyakinkan komputer.
Buktinya kira-kira akan terlihat seperti ini:

Ini adalah penalaran yang sama, hanya diekspresikan dalam Lean. Lean adalah bahasa pemrograman yang sering digunakan untuk menulis dan memverifikasi bukti matematika.
Tampilannya sangat berbeda dengan bukti "versi manusia" yang saya berikan di atas, dan ada alasan bagus untuk itu: apa yang intuitif bagi komputer berbeda dengan apa yang intuitif bagi manusia. Komputer di sini adalah "komputer" dalam arti lama—program "deterministik" yang terdiri dari pernyataan if/then, bukan model bahasa besar (LLM).
Dalam bukti di atas, Anda tidak menekankan fakta bahwa fib(3k+4) = fib(3k+3) + fib(3k+2); Anda menekankan bahwa fib(3k+3) + fib(3k+2) adalah ganjil, dan taktik bernama cukup megah "omega" dalam Lean secara otomatis menggabungkan hal ini dengan pemahamannya tentang definisi fib(3k+4).
Dalam bukti yang lebih kompleks, terkadang Anda harus secara eksplisit menyatakan pada setiap langkah: hukum matematika mana yang memungkinkan Anda melangkah, dan hukum-hukum ini terkadang memiliki nama yang membingungkan, seperti Prod.mk.inj. Namun di sisi lain, Anda juga dapat memperluas ekspresi polinomial besar dalam satu langkah dan hanya perlu menulis satu baris ekspresi seperti omega atau ring untuk menyelesaikan argumen.
Ketidakintuitifan dan kerumitan inilah yang menjadi alasan utama mengapa bukti yang dapat diverifikasi mesin telah ada selama hampir 60 tahun tetapi tetap terbatas pada bidang-bidang kecil. Namun pada saat yang sama, banyak hal yang sebelumnya hampir mustahil kini dengan cepat menjadi mungkin berkat kemajuan pesat AI.
Memverifikasi Program Komputer
Pada titik ini, Anda mungkin berpikir: Oke, jadi kita bisa membuat komputer memverifikasi bukti teorema matematika, sehingga kita akhirnya bisa memastikan penemuan-penemuan gila baru tentang bilangan prima mana yang benar dan mana yang hanya kesalahan tersembunyi dalam makalah PDF ratusan halaman. Mungkin kita bahkan bisa mengetahui apakah bukti Shinichi Mochizuki tentang konjektur ABC benar! Tapi apa gunanya ini selain memuaskan rasa ingin tahu?
Ada banyak jawaban. Dan bagi saya, salah satu jawaban yang sangat penting adalah: memverifikasi kebenaran program komputer, terutama yang melibatkan kriptografi atau keamanan. Bagaimanapun, program komputer itu sendiri adalah objek matematika. Jadi, membuktikan bahwa sebuah program komputer berjalan dengan cara tertentu pada dasarnya adalah membuktikan sebuah teorema matematika.
Misalnya, katakanlah Anda ingin membuktikan apakah perangkat lunak komunikasi terenkripsi seperti Signal benar-benar aman. Pertama, Anda dapat menulis secara matematis apa arti "aman" dalam konteks ini. Secara umum, Anda ingin membuktikan: asumsi kriptografi tertentu berlaku, hanya orang dengan kunci privat yang dapat mengetahui informasi apa pun tentang konten pesan. Tentu saja, ada banyak properti keamanan yang benar-benar penting dalam kenyataan.
Dan ternyata, memang ada tim yang mencoba mencari tahu hal ini. Salah satu teorema keamanan yang mereka ajukan kira-kira terlihat seperti ini:

Berikut adalah ringkasan Leanstral tentang arti teorema ini:
Teorema passive_secrecy_le_ddh adalah reduksi ketat yang menunjukkan bahwa, dalam model Oracle Acak (Random Oracle Model), kerahasiaan pesan pasif X3DH setidaknya sama sulitnya untuk ditembus dengan asumsi DDH.
Dengan kata lain, jika penyerang dapat menembus kerahasiaan pesan pasif X3DH, maka mereka juga dapat menembus DDH. Karena DDH umumnya dianggap sulit, X3DH juga dapat dianggap tahan terhadap serangan pasif.
Teorema ini membuktikan bahwa jika penyerang hanya dapat mengamati secara pasif pesan pertukaran kunci Signal, mereka tidak dapat membedakan kunci sesi yang dihasilkan akhir dari kunci acak dengan keunggulan yang lebih dari probabilitas yang dapat diabaikan.
Jika dikombinasikan dengan bukti bahwa enkripsi AES diimplementasikan dengan benar, Anda akan mendapatkan bukti bahwa mekanisme enkripsi protokol Signal tahan terhadap penyerang pasif.
Proyek verifikasi serupa juga ada untuk membuktikan keamanan implementasi TLS dan komponen kriptografi lainnya di dalam browser.
Jika Anda dapat melakukan verifikasi formal ujung ke ujung, yang Anda buktikan bukan hanya bahwa deskripsi protokol tertentu secara teori aman, tetapi juga kode spesifik yang dijalankan pengguna dalam praktiknya aman. Dari perspektif pengguna, ini secara signifikan meningkatkan tingkat "tanpa kepercayaan" (trustlessness): untuk sepenuhnya mempercayai kode ini, Anda tidak perlu memeriksa seluruh basis kode baris demi baris, Anda hanya perlu memeriksa pernyataan-pernyataan yang telah terbukti benar.
Tentu saja, ada beberapa tanda bintang yang sangat penting untuk dipertahankan, terutama tentang apa sebenarnya arti kata "aman". Sangat mudah melupakan untuk membuktikan klaim yang benar-benar penting; juga sangat mudah terjebak dalam situasi di mana klaim yang perlu dibuktikan tidak memiliki deskripsi yang lebih ringkas daripada kode itu sendiri; juga sangat mudah menyelinapkan asumsi ke dalam bukti yang pada akhirnya tidak benar. Anda juga mudah menyimpulkan bahwa hanya sebagian dari sistem yang benar-benar membutuhkan bukti formal, tetapi akhirnya terkena kerentanan kritis di bagian lain, atau bahkan di tingkat perangkat keras. Bahkan implementasi Lean itu sendiri mungkin memiliki bug. Tetapi sebelum membahas detail-detail yang menyakitkan ini, mari kita lihat lebih jauh: jika verifikasi formal dapat diselesaikan dengan ideal dan benar, seperti apa prospek yang hampir utopis yang mungkin dihasilkannya.
Verifikasi Formal untuk Keamanan
Bug dalam kode komputer memang mengkhawatirkan.
Saat Anda memasukkan cryptocurrency ke dalam kontrak pintar on-chain yang tidak dapat diubah, bug kode menjadi lebih menakutkan. Karena begitu kode salah, peretas Korea Utara dapat secara otomatis mentransfer semua uang Anda, dan Anda hampir tidak memiliki cara untuk menuntut.
Ketika semua ini dibungkus dengan bukti nol pengetahuan (zero-knowledge proof), bug kode menjadi semakin menakutkan. Karena jika seseorang berhasil menembus sistem bukti nol pengetahuan, mereka dapat menarik semua dana, dan kita mungkin sama sekali tidak tahu apa yang salah—atau lebih buruk lagi, kita mungkin bahkan tidak tahu masalah itu telah terjadi.
Ketika kita memiliki model AI yang kuat, bug kode akan menjadi lebih menakutkan. Misalnya, model seperti Claude Mythos, setelah dua tahun penyempurnaan, mungkin dapat secara otomatis menemukan kerentanan ini.

Beberapa orang, menghadapi realitas ini, mulai menganjurkan meninggalkan ide dasar kontrak pintar, atau bahkan berpikir bahwa ruang siber tidak mungkin menjadi domain di mana pihak bertahan memiliki keunggulan asimetris dibandingkan penyerang.
Berikut adalah beberapa kutipan:
Untuk mengamankan sebuah sistem, Anda perlu menghabiskan lebih banyak token untuk menemukan kerentanan daripada yang dihabiskan penyerang untuk mengeksploitasinya.
Dan:
Industri kami dibangun di sekitar kode deterministik. Menulis kode, menguji, meluncurkan, dan tahu bahwa itu akan berjalan—tetapi menurut pengalaman saya, kontrak ini mulai gagal. Di antara operator puncak perusahaan asli AI yang sebenarnya, basis kode mulai menjadi sesuatu yang "Anda percayai akan berjalan", dan probabilitas yang sesuai dengan kepercayaan ini tidak dapat lagi dinyatakan secara tepat.
Lebih buruk lagi, beberapa orang berpendapat satu-satunya solusi adalah meninggalkan sumber terbuka.
Ini akan menjadi masa depan yang suram untuk keamanan siber. Terutama bagi mereka yang peduli dengan desentralisasi dan kebebasan internet, ini akan menjadi masa depan yang sangat suram. Semangat cypherpunk pada dasarnya dibangun di atas keyakinan bahwa di internet, pihak bertahan memiliki keunggulan. Membangun "kastil" digital—baik itu enkripsi, tanda tangan, atau bukti—lebih mudah daripada menghancurkannya. Jika kita kehilangan ini, maka keamanan internet hanya dapat berasal dari ekonomi skala, dari memburu calon penyerang di seluruh dunia, dan lebih luas lagi, dari pilihan biner: mendominasi segalanya atau binasa.
Saya tidak setuju dengan penilaian ini. Saya memiliki visi yang jauh lebih optimis tentang masa depan keamanan siber.
Saya pikir tantangan yang ditimbulkan oleh kemampuan penemuan kerentanan AI yang kuat memang berat, tetapi itu adalah tantangan transisi. Setelah debu mengendap dan kita memasuki keseimbangan baru, kita akan mencapai keadaan yang lebih menguntungkan pihak bertahan daripada sebelumnya.
Mozilla juga setuju dengan ini. Mengutip kata-kata mereka:
Anda mungkin perlu mengatur ulang prioritas semua hal lain, dan mengabdikan diri pada tugas ini dengan cara yang berkelanjutan dan fokus. Tetapi ada cahaya di ujung terowongan. Kami sangat bangga melihat bagaimana tim maju menghadapi tantangan ini, dan orang lain juga akan melakukannya. Pekerjaan kami belum selesai, tetapi kami telah melewati titik belok dan mulai melihat masa depan yang lebih baik yang lebih dari sekadar "hanya bertahan". Pihak bertahan akhirnya memiliki kesempatan untuk meraih kemenangan yang menentukan.
......
Jumlah cacat itu terbatas, dan kita sedang memasuki dunia di mana kita akhirnya dapat menemukan semuanya.
Sekarang, jika Anda melakukan Ctrl+F di artikel Mozilla ini untuk mencari "formal" dan "verification", Anda akan menemukan bahwa kedua kata itu tidak muncul. Masa depan keamanan siber yang positif tidak sepenuhnya bergantung pada verifikasi formal, atau teknologi tunggal lainnya.
Lalu bergantung pada apa? Pada dasarnya, pada gambar ini:
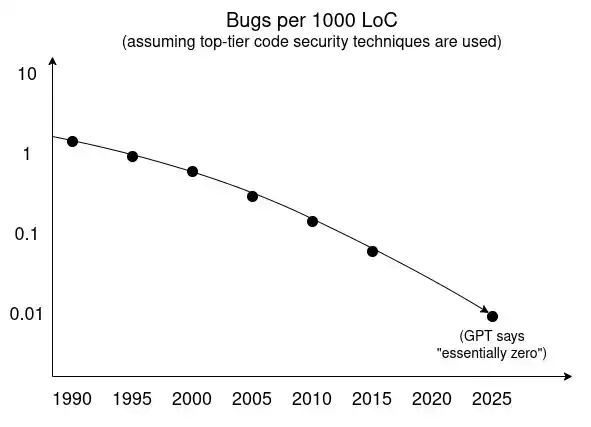
Selama beberapa dekade terakhir, banyak teknologi yang mendorong tren "penurunan jumlah kerentanan":
Sistem tipe;
Bahasa yang aman memori;
Peningkatan arsitektur perangkat lunak, termasuk sandboxing, mekanisme izin, dan secara lebih umum membedakan dengan jelas antara "basis komputasi tepercaya" (trusted computing base) dan "kode lainnya";
Metode pengujian yang lebih baik;
Akumulasi pengetahuan tentang pola pengkodean yang aman dan tidak aman;
Semakin banyak pustaka perangkat lunak yang telah ditulis sebelumnya dan diaudit.
Verifikasi formal berbantuan AI tidak boleh dilihat sebagai paradigma yang sama sekali baru, melainkan sebagai akselerator yang kuat: ia mempercepat tren dan paradigma yang sudah bergerak maju.
Verifikasi formal bukan obat ajaib. Tetapi ada skenario tertentu di mana ia sangat cocok: yaitu ketika tujuannya jauh lebih sederhana daripada implementasinya. Ini sangat jelas dalam beberapa teknologi paling sulit yang perlu diterapkan dalam iterasi besar Ethereum berikutnya, seperti tanda tangan anti-kuantum, STARK, algoritma konsensus, dan ZK-EVM.
STARK adalah perangkat lunak yang sangat kompleks. Tetapi properti keamanan inti yang diimplementasikannya mudah dipahami dan diformalkan: jika Anda melihat bukti yang merujuk pada program P, input x, dan hash output y H, maka baik algoritma hash yang digunakan STARK telah ditembus, atau P(x) = y. Oleh karena itu, kami memiliki proyek Arklib, yang mencoba membuat implementasi STARK yang diverifikasi secara formal secara lengkap. Proyek terkait lainnya adalah VCV-io, yang menyediakan infrastruktur komputasi oracle dasar yang dapat digunakan untuk verifikasi formal berbagai protokol kriptografi, banyak di antaranya juga merupakan komponen dependensi STARK.
Yang lebih ambisius adalah evm-asm: sebuah proyek yang mencoba membangun implementasi EVM lengkap dan memverifikasinya secara formal. Di sini, properti keamanannya tidak terlalu jelas. Singkatnya, tujuannya adalah membuktikan bahwa implementasi ini setara dengan implementasi EVM lain yang ditulis dalam Lean; yang terakhir dapat dirancang untuk kejelasan dan keterbacaan maksimal tanpa mempertimbangkan efisiensi eksekusi.
Tentu saja, secara teori masih mungkin terjadi situasi di mana kita memiliki sepuluh implementasi EVM, semuanya terbukti setara satu sama lain, tetapi semuanya berbagi cacat fatal yang sama, yang entah bagaimana memungkinkan penyerang mentransfer semua ETH dari alamat yang tidak mereka kendalikan. Tetapi kemungkinan hal ini terjadi jauh lebih rendah daripada kemungkinan salah satu implementasi EVM saat ini memiliki cacat seperti itu secara terpisah. Properti keamanan penting lainnya yang baru kita sadari betapa pentingnya setelah pengalaman pahit—ketahanan DoS—relatif mudah untuk ditentukan secara eksplisit.
Dua arah penting lainnya adalah:
Konsensus toleransi kesalahan Bizantium. Di sini, mendefinisikan secara formal semua properti keamanan yang diinginkan juga tidak mudah. Tetapi mengingat bug terkait sangat umum, tetap layak untuk mencoba verifikasi formal. Oleh karena itu, sekarang sudah ada pekerjaan yang sedang berjalan tentang implementasi konsensus Lean dan buktinya.
Bahasa pemrograman kontrak pintar. Contoh terkait termasuk pekerjaan verifikasi formal di Vyper dan Verity.
Dalam semua kasus ini, salah satu nilai tambah besar dari verifikasi formal adalah: bukti-bukti ini benar-benar ujung ke ujung. Banyak bug paling rumit adalah bug interaksi, yang muncul di batas antara dua subsistem yang dipertimbangkan secara terpisah. Bagi manusia, terlalu sulit untuk bernalar tentang seluruh sistem dari ujung ke ujung; tetapi sistem pemeriksaan aturan otomatis dapat melakukannya.
Verifikasi Formal untuk Efisiensi
Mari kita lihat evm-asm lagi. Ini adalah implementasi EVM.
Tetapi ini adalah implementasi EVM yang ditulis langsung dalam bahasa rakitan RISC-V.
Benar-benar rakitan harfiah.
Berikut adalah opcode ADD:
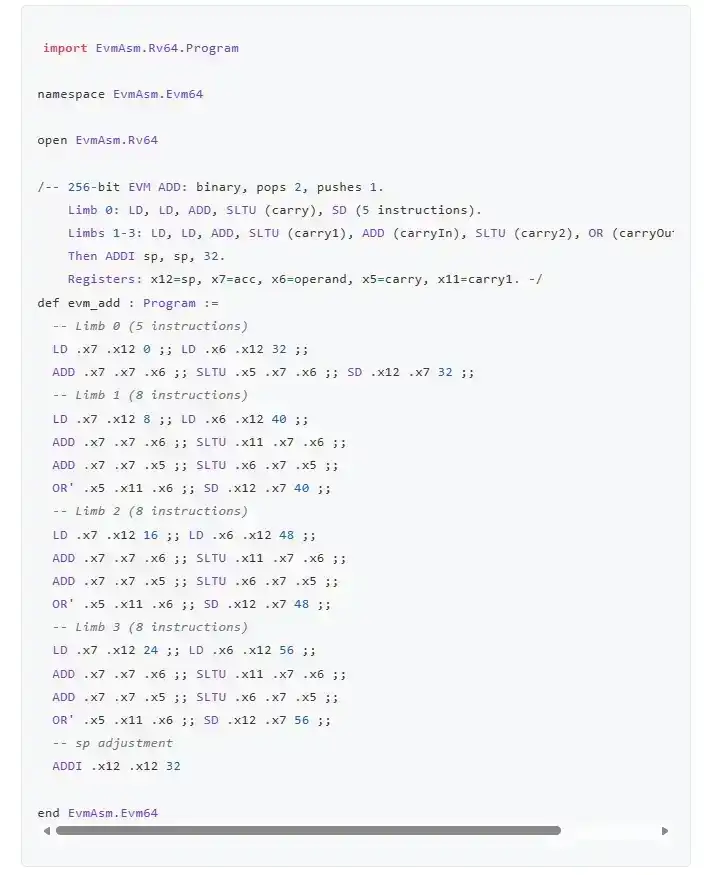
Alasan memilih RISC-V adalah karena pembuktian ZK-EVM yang sedang dibangun saat ini biasanya bekerja dengan membuktikan RISC-V dan mengkompilasi klien Ethereum ke RISC-V. Oleh karena itu, jika Anda menulis implementasi EVM langsung dalam RISC-V, secara teori itu seharusnya menjadi implementasi tercepat yang bisa Anda dapatkan. RISC-V juga dapat disimulasikan dengan sangat efisien di komputer biasa, dan laptop RISC-V sudah ada. Tentu saja, untuk benar-benar ujung ke ujung, Anda juga harus memverifikasi secara formal implementasi RISC-V itu sendiri, atau representasi aritmatisasi dari pembuktian. Tapi jangan khawatir—pekerjaan semacam ini juga sudah ada.
Menulis kode langsung dalam rakitan adalah hal yang biasa kita lakukan lima puluh tahun lalu. Sejak itu, kita beralih ke menulis kode dalam bahasa tingkat tinggi. Bahasa tingkat tinggi mengorbankan efisiensi tertentu, tetapi sebagai gantinya, membuat penulisan kode jauh lebih cepat, dan yang lebih penting, juga membuat memahami kode orang lain jauh lebih cepat—yang merupakan prasyarat untuk keamanan.
Dengan kombinasi verifikasi formal dan AI, kita memiliki kesempatan untuk "kembali ke masa depan". Secara khusus, dengan membiarkan AI menulis kode rakitan, lalu menulis bukti formal yang memverifikasi bahwa kode rakitan ini memiliki properti yang kita inginkan. Setidaknya, properti target ini bisa berupa: ia setara sepenuhnya dengan implementasi yang dioptimalkan untuk keterbacaan dan ditulis dalam bahasa tingkat tinggi yang ramah manusia.
Dengan demikian, tidak lagi membutuhkan satu objek kode yang menyeimbangkan keterbacaan dan efisiensi. Kami akan memiliki dua objek yang terpisah: satu adalah implementasi rakitan, dioptimalkan hanya untuk efisiensi, dan disesuaikan dengan kebutuhan lingkungan eksekusi tertentu; yang lainnya adalah klaim keamanan, atau implementasi bahasa tingkat tinggi, dioptimalkan hanya untuk keterbacaan. Kemudian, kami menggunakan bukti matematika untuk membuktikan kesetaraan di antara keduanya. Pengguna dapat memverifikasi bukti ini secara otomatis satu kali; setelah itu, mereka hanya perlu menjalankan versi cepatnya.
Ini sangat kuat. Tidak mengherankan Yoichi Hirai menyebutnya "bentuk akhir pengembangan perangkat lunak".
Verifikasi Formal Bukan Obat Ajaib
Dalam kriptografi dan ilmu komputer, ada tradisi yang hampir sama tuanya dengan metode formal itu sendiri: mengkritik metode formal, atau lebih luas lagi, mengkritik ketergantungan pada "bukti". Ada banyak contoh praktis dalam literatur. Mari kita mulai dengan bukti tulisan tangan yang lebih sederhana di awal kriptografi. Menezes dan Koblitz mengkritiknya pada tahun 2004:
Pada tahun 1979, Rabin mengusulkan fungsi enkripsi yang dalam arti tertentu "terbukti" aman, artinya ia memiliki properti keamanan reduktif.
Klaim keamanan reduktif adalah: siapa pun yang dapat menemukan pesan m dari ciphertext y, juga harus dapat memfaktorkan n.
Segera setelah Rabin mengusulkan skema enkripsinya, Rivest menunjukkan bahwa ironisnya, fitur yang memberinya keamanan ekstra juga menyebabkan sistem benar-benar rusak di hadapan penyerang jenis lain. Penyerang ini disebut penyerang "ciphertext terpilih". Secara khusus, anggaplah penyerang dapat dengan cara tertentu memancing Alice untuk mendekripsi ciphertext pilihan penyerang sendiri. Maka, penyerang dapat memfaktorkan n dengan proses yang sama seperti yang digunakan Sam di paragraf sebelumnya.
Menezes dan Koblitz kemudian memberikan beberapa contoh lagi. Bersama-sama, mereka menunjukkan pola: merancang protokol kriptografi di sekitar "lebih mudah dibuktikan" sering kali membuat protokol kurang "alami" dan lebih rentan runtuh dalam skenario yang bahkan tidak dipertimbangkan oleh perancang.
Sekarang, mari kembali ke bukti yang dapat diverifikasi mesin dan kode. Berikut adalah contoh dari makalah tahun 2011, di mana penulis menemukan bug dalam kompiler C yang diverifikasi secara formal:
Masalah CompCert kedua yang kami temukan dimanifestasikan dalam dua bug. Kedua bug ini menghasilkan kode seperti ini: stwu r1, -44432(r1)
Di sini, frame stack PowerPC yang sangat besar sedang dialokasikan. Masalahnya adalah bahwa bidang perpindahan 16-bit meluap. Semantik PPC CompCert tidak menentukan batasan pada lebar nilai segera ini, karena mengasumsikan assembler akan menangkap nilai di luar jangkauan.
Lihat lagi makalah tahun 2022:
Di CompCert-KVX, commit e2618b31 memperbaiki bug: instruksi "nand" akan dicetak sebagai "and"; dan "nand" hanya akan dipilih dalam mode ~(a & b) yang jarang terjadi. Bug ini ditemukan dengan mengkompilasi program yang dihasilkan secara acak.
Sampai hari ini, tahun 2026, Nadim Kobeissi menulis tentang kerentanan dalam perangkat lunak yang diverifikasi secara formal di Cryspen:
Pada November 2025, Filippo Valsorda melaporkan secara independen bahwa libcrux-ml-dsa v0.0.3 menghasilkan kunci publik dan tanda tangan yang berbeda pada platform yang berbeda dengan input deterministik yang sama. Bug ini terletak di wrapper fungsi bawaan _vxarq_u64, yang mengimplementasikan operasi XAR yang digunakan dalam permutasi Keccak-f SHA-3. Jalur fallback memberikan parameter yang salah ke operasi pergeseran, menyebabkan digest SHA-3 rusak pada platform ARM64 tanpa dukungan perangkat keras SHA-3. Ini adalah kegagalan Tipe I: fungsi bawaan ini ditandai sebagai terverifikasi, sementara backend NEON seluruhnya tidak memiliki bukti keamanan atau kebenaran waktu proses.
Dan juga:
Krat libcrux-psq mengimplementasikan protokol kunci pra-berbagi pasca-kuantum. Dalam metode decrypt_out, jalur dekripsi AES-GCM 128 akan memanggil .unwrap() pada hasil dekripsi, daripada meneruskan kesalahan. Satu ciphertext cacat dapat menghentikan proses.
Keempat masalah di atas dapat dikategorikan ke dalam dua jenis:
Jenis pertama, hanya sebagian kode yang diverifikasi, karena memverifikasi sisanya terlalu sulit; dan ternyata, kode yang tidak diverifikasi lebih mudah mengalami bug daripada yang diperkirakan penulis, dan bug-bug ini sering kali lebih kritis.
Jenis kedua, penulis lupa menentukan secara eksplisit properti kunci tertentu yang seharusnya dibuktikan.
Artikel Nadim mengkategorikan mode kegagalan verifikasi formal; dia juga mencantumkan jenis kegagalan lainnya. Misalnya, jenis utama lainnya adalah: spesifikasi formal itu sendiri salah, atau bukti mengandung klaim yang salah, tetapi diterima diam-diam oleh sistem build.
Akhirnya, kita juga dapat melihat kegagalan verifikasi formal yang terjadi di batas antara perangkat lunak dan perangkat keras. Masalah umum di sini adalah memverifikasi apakah sistem dapat menahan serangan saluran samping. Bahkan jika Anda melindungi pesan dengan enkripsi yang secara teori sepenuhnya aman, jika seseorang beberapa meter jauhnya dapat menangkap fluktuasi listrik dan mengekstrak kunci privat Anda setelah ratusan ribu enkripsi, Anda tetap tidak aman.
"Analisis daya diferensial" (differential power analysis) adalah contoh teknik semacam ini yang kini telah dipahami dengan baik.
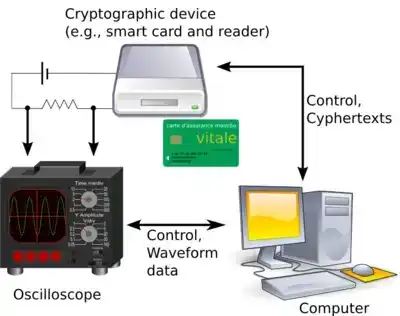
Analisis daya diferensial adalah serangan saluran samping yang umum. Sumber: Wikipedia
Di masa lalu, ada upaya untuk membuktikan bahwa sistem dapat menahan penyerang semacam ini. Namun, bukti apa pun memerlukan semacam model matematika tentang penyerang, baru kemudian Anda dapat membuktikan keamanan dalam model itu. Terkadang, orang menggunakan "model d-probing": yaitu mengasumsikan ada batas atas yang diketahui pada jumlah lokasi di sirkuit yang dapat diselidiki penyerang. Tetapi masalahnya, beberapa bentuk kebocoran tidak tertangkap oleh model ini.
Satu masalah umum yang diamati dalam artikel ini adalah kebocoran transisi: jika sinyal yang Anda amati tidak bergantung pada nilai spesifik di suatu lokasi, tetapi pada perubahan nilai itu, maka sering kali Anda dapat memulihkan informasi yang dibutuhkan dari dua nilai—nilai lama dan baru—daripada hanya mengandalkan satu nilai. Artikel tersebut juga mengkategorikan bentuk-bentuk kebocoran lainnya.
Selama beberapa dekade, kritik terhadap verifikasi formal ini, pada gilirannya, membantu verifikasi formal menjadi lebih baik. Dibandingkan masa lalu, kita sekarang lebih waspada terhadap masalah semacam ini. Tetapi bahkan sampai hari ini, itu masih tidak sempurna.
Jika dilihat dari perspektif yang lebih luas, sebenarnya ada benang merah bersama: verifikasi formal itu kuat. Tetapi terlepas dari bagaimana pemasaran mengemasnya sebagai memberikan "kebenaran yang dapat dibuktikan", "kebenaran yang dapat dibuktikan" pada dasarnya tidak membuktikan bahwa perangkat lunak, atau perangkat keras, "benar" dalam arti sebenarnya.
Bagi kebanyakan orang, "benar" kira-kira berarti: benda ini berperilaku sesuai dengan pemahaman pengguna tentang maksud pengembang.
Dan "aman" kira-kira berarti: benda ini tidak akan berperilaku menyimpang dari harapan pengguna dengan cara yang merugikan pengguna.
Dalam kedua kasus ini, kebenaran dan keamanan pada akhirnya bermuara pada perbandingan: di satu sisi adalah objek matematika, di sisi lain adalah maksud atau harapan manusia. Secara teknis, maksud dan harapan manusia itu sendiri adalah objek matematika—bagaimanapun, otak manusia adalah bagian dari alam semesta, dan alam semesta mengikuti hukum fisika; selama Anda memiliki daya komputasi yang cukup, Anda dapat mensimulasikannya secara teori. Tetapi mereka adalah objek matematika yang sangat kompleks yang tidak dapat benar-benar dipahami oleh komputer atau diri kita sendiri, atau bahkan dibaca. Untuk tujuan praktis, kita dapat menganggapnya sebagai kotak hitam. Alasan kita masih dapat memahami maksud dan harapan kita sendiri hanyalah karena setiap orang memiliki pengalaman bertahun-tahun mengamati pikiran mereka sendiri dan menyimpulkan pikiran orang lain.
Dan karena kita tidak dapat memasukkan maksud manusia mentah langsung ke dalam komputer, verifikasi formal tidak memiliki cara untuk membuktikan perbandingan antara suatu sistem dan maksud manusia. Oleh karena itu, "kebenaran yang dapat dibuktikan" dan "keamanan yang dapat dibuktikan" sebenarnya tidak membuktikan "kebenaran" dan "keamanan" seperti yang dipahami manusia—tidak ada metode yang dapat benar-benar melakukan ini sampai kita dapat mensimulasikan otak manusia.
Lalu, Di Mana Verifikasi Formal Benar-Benar Berguna?
Saya cenderung melihat rangkaian pengujian, sistem tipe, dan verifikasi formal sebagai implementasi berbeda dari metode keamanan bahasa pemrograman dasar yang sama—mungkin satu-satunya metode yang benar-benar masuk akal. Kesamaan mereka adalah: menyatakan maksud kita secara berlebihan dengan cara yang berbeda, lalu secara otomatis memeriksa apakah pernyataan-pernyataan yang berbeda ini saling kompatibel.
Misalnya, lihat kode Python ini:

Di sini, Anda menyatakan maksud Anda dengan tiga cara berbeda:
Pertama, ekspresi langsung: melalui kode yang mengimplementasikan rumus Fibonacci.
Kedua, ekspresi tidak langsung: melalui sistem tipe yang menyatakan bahwa input, output, dan langkah perantara dalam rekursi adalah bilangan bulat.
Ketiga, menggunakan pendekatan "paket kasus": yaitu kasus uji.
Saat menjalankan file ini, sistem akan menggunakan contoh-contoh ini untuk memeriksa apakah rumus berlaku. Pemeriksa tipe kemudian dapat memverifikasi apakah tipe-tipe tersebut kompatibel: menambahkan dua bilangan bulat adalah operasi yang valid, dan akan menghasilkan bilangan bulat lain. Sistem tipe sering kali juga berguna dalam komputasi fisik: jika Anda menghitung percepatan tetapi mendapatkan hasil dengan satuan m/s, bukan m/s2, Anda tahu ada yang salah dalam perhitungan. Dan definisi gaya "paket kasus", di mana kasus uji adalah salah satu contohnya, sering kali lebih sesuai dengan cara manusia memproses konsep daripada definisi langsung dan eksplisit.
Semakin banyak cara berbeda yang dapat Anda gunakan untuk mengekspresikan maksud Anda, semakin baik; idealnya, cara-cara ini harus cukup berbeda satu sama lain sehingga memaksa Anda memikirkan masalah yang sama dengan cara berpikir yang berbeda. Dengan demikian, jika semua ekspresi ini akhirnya saling kompatibel, probabilitas bahwa Anda benar-benar mengekspresikan apa yang ingin Anda ekspresikan juga lebih tinggi.
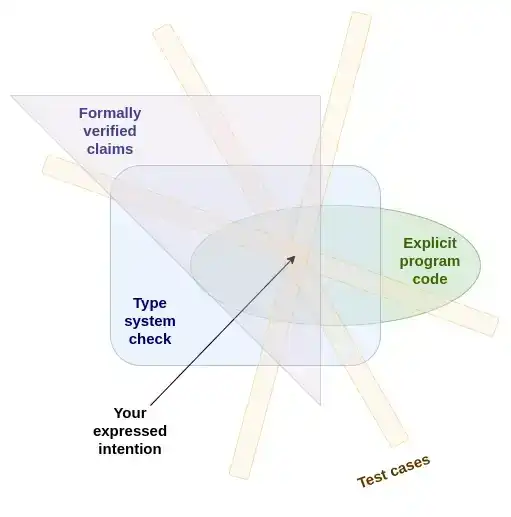
Inti pemrograman yang aman adalah mengekspresikan maksud Anda dalam berbagai cara yang berbeda, lalu secara otomatis memverifikasi apakah ekspresi-ekspresi ini saling kompatibel.
Verifikasi formal dapat mendorong metode ini lebih jauh. Dengan verifikasi formal, Anda hampir dapat menggambarkan maksud Anda dalam banyak cara berlebihan; program hanya akan lulus verifikasi jika semua deskripsi ini saling kompatibel.
Anda dapat menulis implementasi yang dioptimalkan dan implementasi yang tidak efisien tetapi mudah dibaca manusia secara bersamaan, lalu memverifikasi apakah keduanya konsisten. Anda juga dapat meminta sepuluh teman masing-masing membuat daftar properti matematika yang menurut mereka harus dipenuhi program, lalu memeriksa apakah program memenuhi semuanya; jika tidak lulus, putuskan lebih lanjut apakah programnya yang salah atau properti matematika itu sendiri yang bermasalah. Dan AI dapat membuat semua pekerjaan di atas menjadi sangat efisien.
Lalu Bagaimana Saya Memulai?
Secara realistis, kemungkinan besar Anda tidak akan menulis bukti sendiri. Alasan mendasar mengapa metode formal tidak pernah benar-benar meluas adalah: kebanyakan orang sulit memahami bagaimana menulis bukti-bukti sialan ini.
Bisakah Anda memberi tahu saya apa arti kode ini?
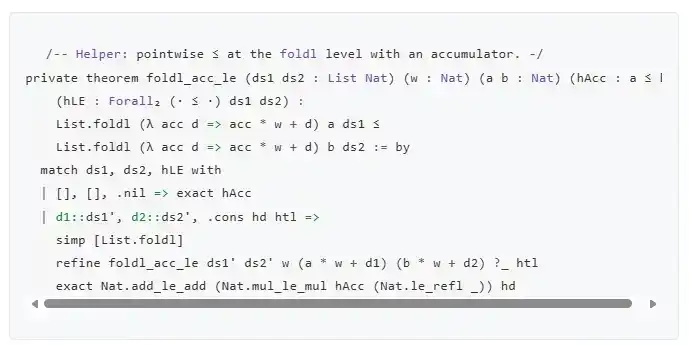
(Jika Anda penasaran, ini adalah salah satu dari banyak sub-lemma dalam sebuah bukti. Bukti ini ditujukan untuk klaim keamanan spesifik dari varian tertentu tanda tangan SPHINCS: yaitu, kecuali terjadi tabrakan hash, menghasilkan tanda tangan untuk satu pesan membutuhkan penggunaan nilai yang lebih tinggi di setidaknya satu rantai hash dibandingkan dengan tanda tangan untuk pesan lain mana pun. Oleh karena itu, informasi yang dibutuhkan tidak dapat dihitung dari tanda tangan lain.)
Anda tidak perlu menulis kode dan bukti secara manual, melainkan meminta AI menulis program untuk Anda—langsung di Lean jika Anda mau; atau dalam rakitan jika Anda ingin kecepatan—dan dalam prosesnya membuktikan berbagai properti yang Anda inginkan.
Salah satu keuntungan dari tugas ini adalah pada dasarnya ia memverifikasi dirinya sendiri, jadi Anda tidak perlu terus-menerus mengawasinya. Anda dapat membiarkan AI berjalan sendiri selama berjam-jam. Kasus terburuknya adalah ia berputar-putar tanpa kemajuan; atau seperti yang pernah dilakukan Leanstral saya sekali, untuk membuat pekerjaannya lebih mudah, langsung mengganti pernyataan yang diminta untuk dibuktikan.
Apa yang akhirnya perlu Anda periksa adalah: apakah proposisi yang terbukti memang hal yang ingin Anda buktikan.
Dalam varian tanda tangan SPHINCS ini, pernyataan akhirnya adalah sebagai berikut:

Ini sebenarnya sudah mendekati ambang "dapat dibaca":
Jika angka yang dihasilkan dari satu hash digest (dig1) tidak sama dengan angka yang dihasilkan dari hash digest lain (dig2), maka pernyataan berikut tidak benar:
Untuk semua angka, setiap bit dig1 kurang dari atau sama dengan bit yang sesuai di dig2;
Untuk semua angka, setiap bit dig2 kurang dari atau sama dengan bit yang sesuai di dig1.
Di sini yang dibandingkan adalah "angka yang diperluas" (wotsFullDigits) yang dihasilkan setelah menambahkan checksum. Artinya, tidak dapat dihindari, di beberapa posisi, angka yang diperluas dig1 akan lebih tinggi; dan di posisi lain, angka yang diperluas dig2 akan lebih tinggi.
Dalam hal menulis bukti dengan model bahasa besar, saya menemukan Claude sudah cukup baik, DeepSeek 4 Pro juga cukup kompeten. Leanstral adalah alternatif yang menjanjikan: ini adalah model berbobot sumber terbuka yang lebih kecil, disetel khusus untuk penulisan Lean. Ia memiliki 119 miliar parameter, tetapi hanya mengaktifkan 6 miliar parameter per token, sehingga dapat dijalankan secara lokal, meskipun agak lambat—di laptop saya, sekitar 15 token per detik.
Menurut pengujian patokan, Leanstral mengungguli banyak model umum yang jauh lebih besar:
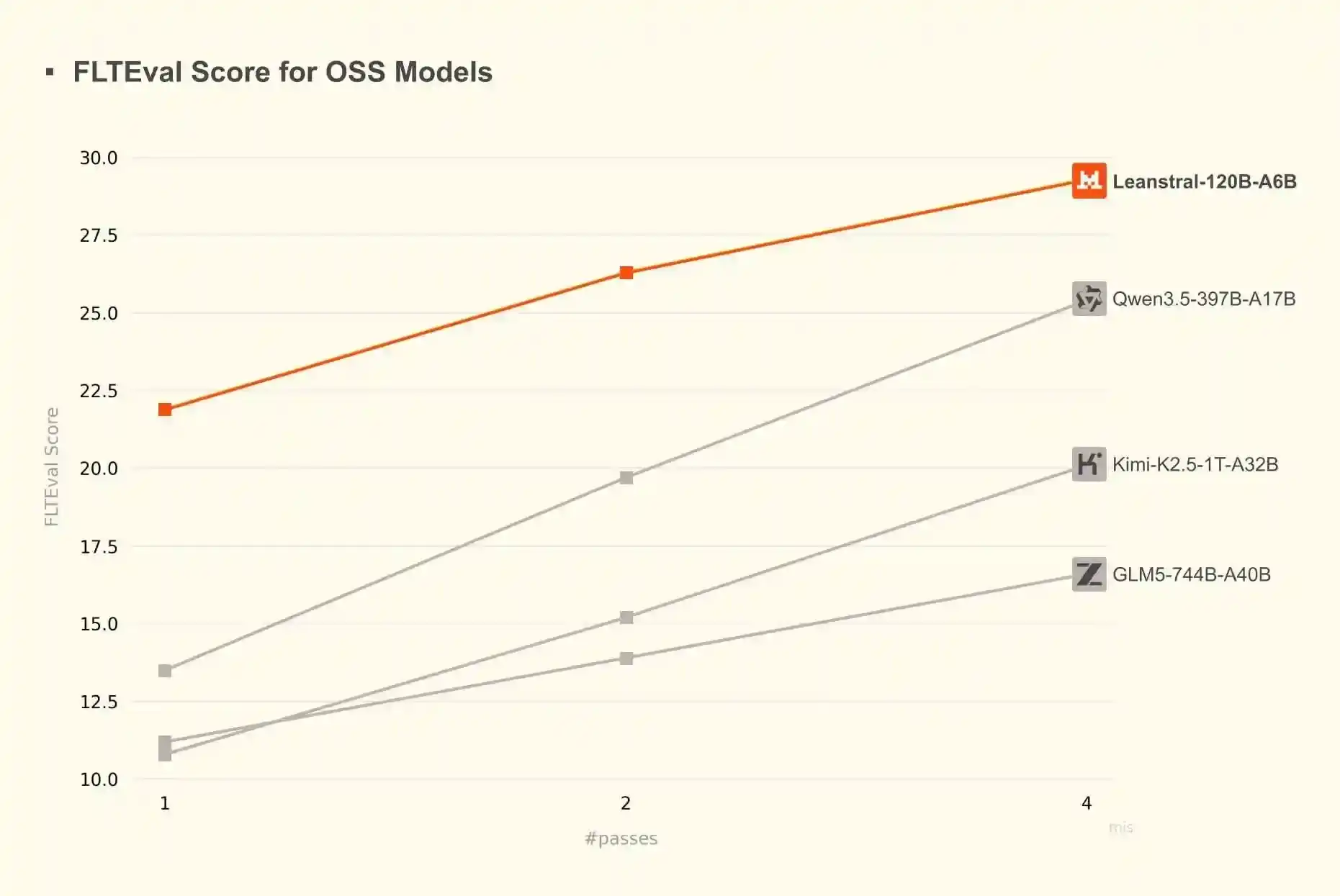
Berdasarkan pengalaman pribadi saya sejauh ini, ia sedikit lebih lemah daripada DeepSeek 4 Pro, tetapi tetap efektif.
Verifikasi formal tidak akan menyelesaikan semua masalah kita. Tetapi jika kita ingin membangun model keamanan internet yang tidak mengharuskan semua orang mempercayai segelintir organisasi kuat, maka kita perlu dapat mempercayai kode—termasuk tetap mempercayai kode saat menghadapi lawan AI yang kuat. Verifikasi formal berbantuan AI dapat membuat kita mengambil langkah penting ke arah itu.
Sama seperti blockchain dan ZK-SNARKs, AI dan verifikasi formal juga adalah teknologi yang sangat saling melengkapi.
Blockchain membawa verifabilitas terbuka dan ketahanan sensor dengan mengorbankan privasi dan skalabilitas; dan ZK-SNARKs mengembalikan privasi dan skalabilitas—bahkan, lebih kuat dari sebelumnya.
AI memungkinkan Anda menulis kode dalam skala besar, tetapi dengan mengorbankan akurasi; dan verifikasi formal mengembalikan akurasi—bahkan, lebih kuat dari sebelumnya.
Secara default, AI akan menghasilkan banyak kode yang sangat kasar, dan jumlah bug juga akan meningkat. Memang, dalam beberapa skenario, membiarkan bug meningkat bahkan merupakan pertukaran yang tepat: jika dampak bug-bug ini ringan, maka perangkat lunak yang cacat lebih baik daripada tidak memiliki perangkat lunak semacam itu. Tetapi di sini, masih ada masa depan yang optimis untuk keamanan siber: perangkat lunak akan terus terbagi menjadi "komponen tepi yang tidak aman" di sekitar "inti aman".
Komponen tepi yang tidak aman ini akan berjalan di sandbox, dan hanya diberikan izin minimum yang diperlukan untuk menyelesaikan tugasnya. Inti aman akan mengelola segalanya. Jika inti aman runtuh, semuanya akan runtuh—data pribadi Anda, uang Anda, dan banyak lagi akan terpengaruh. Tetapi jika komponen tepi yang tidak aman mengalami masalah, inti aman masih dapat melindungi Anda.
Saat menyangkut inti aman, kita tidak akan membiarkan kode yang penuh bug menyebar tanpa kendali. Kita akan secara aktif mengontrol ukuran inti aman, menjaganya tetap cukup kecil, atau bahkan menyusutkannya lebih lanjut. Sebaliknya, kita akan mengarahkan semua kemampuan tambahan yang dibawa AI untuk meningkatkan keamanan inti aman itu sendiri, memungkinkannya menanggung beban kepercayaan yang sangat tinggi dalam masyarakat yang sangat terdigitalisasi.
Kernel sistem operasi Anda, atau setidaknya sebagian darinya, akan menjadi salah satu inti aman ini. Ethereum akan menjadi yang lain. Idealnya, setidaknya dalam semua komputasi non-intensif kinerja tinggi, perangkat keras yang Anda gunakan akan menjadi inti aman ketiga. Beberapa sistem terkait IoT akan menjadi yang keempat.
Setidaknya dalam inti aman ini, pepatah lama—bug tidak dapat dihindari, Anda hanya bisa berusaha menemukannya sebelum penyerang—tidak akan berlaku lagi. Itu akan digantikan oleh dunia yang lebih penuh harap: di sana, kita dapat memperoleh keamanan yang sebenarnya.
Tentu saja, jika Anda ingin menyerahkan aset dan data Anda kepada perangkat lunak yang ditulis dengan buruk, atau bahkan mungkin secara tidak sengaja mengirim semuanya ke lubang hitam, Anda tetap akan memiliki kebebasan itu.
Tautan asli







