【Pembuka】Gila! Data evolusi AI yang baru diukur Meta dan METR ternyata sangat cocok dengan 'Hukum Kepadatan' yang diusulkan tim China dua tahun lalu. Lembah Silikon tersentak, menyadari peneliti China sudah unggul dua tahun di jalur ini!
Tiga lembaga penelitian AI paling serius di dunia bertabrakan dalam seminggu terakhir!
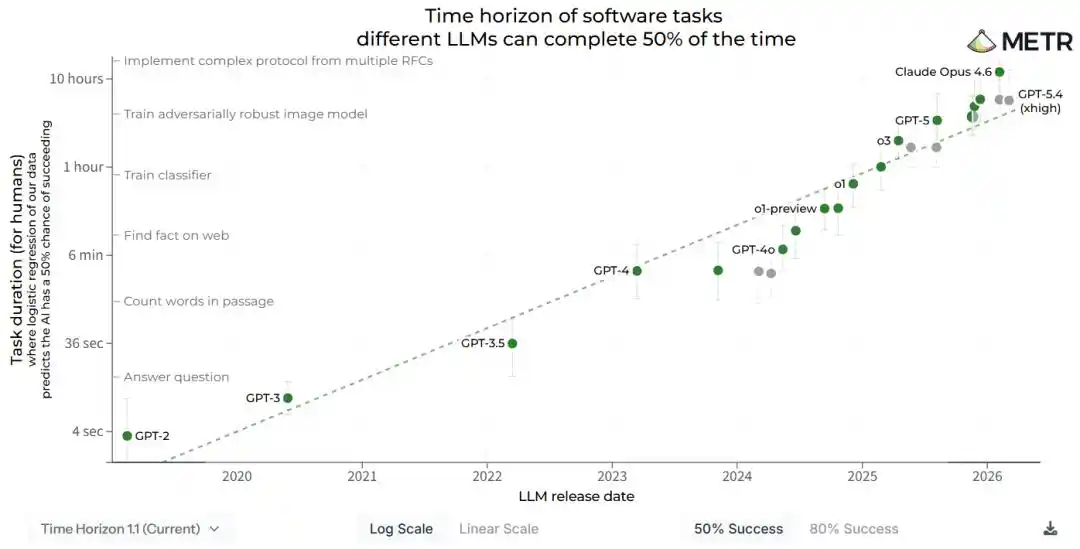
Pada 3 April, lembaga penelitian AS METR diam-diam memperbarui laporan teknis, dengan kesimpulan inti yang dapat diringkas menjadi satu kalimat.
Kemampuan AI berlipat ganda setiap 88,6 hari.
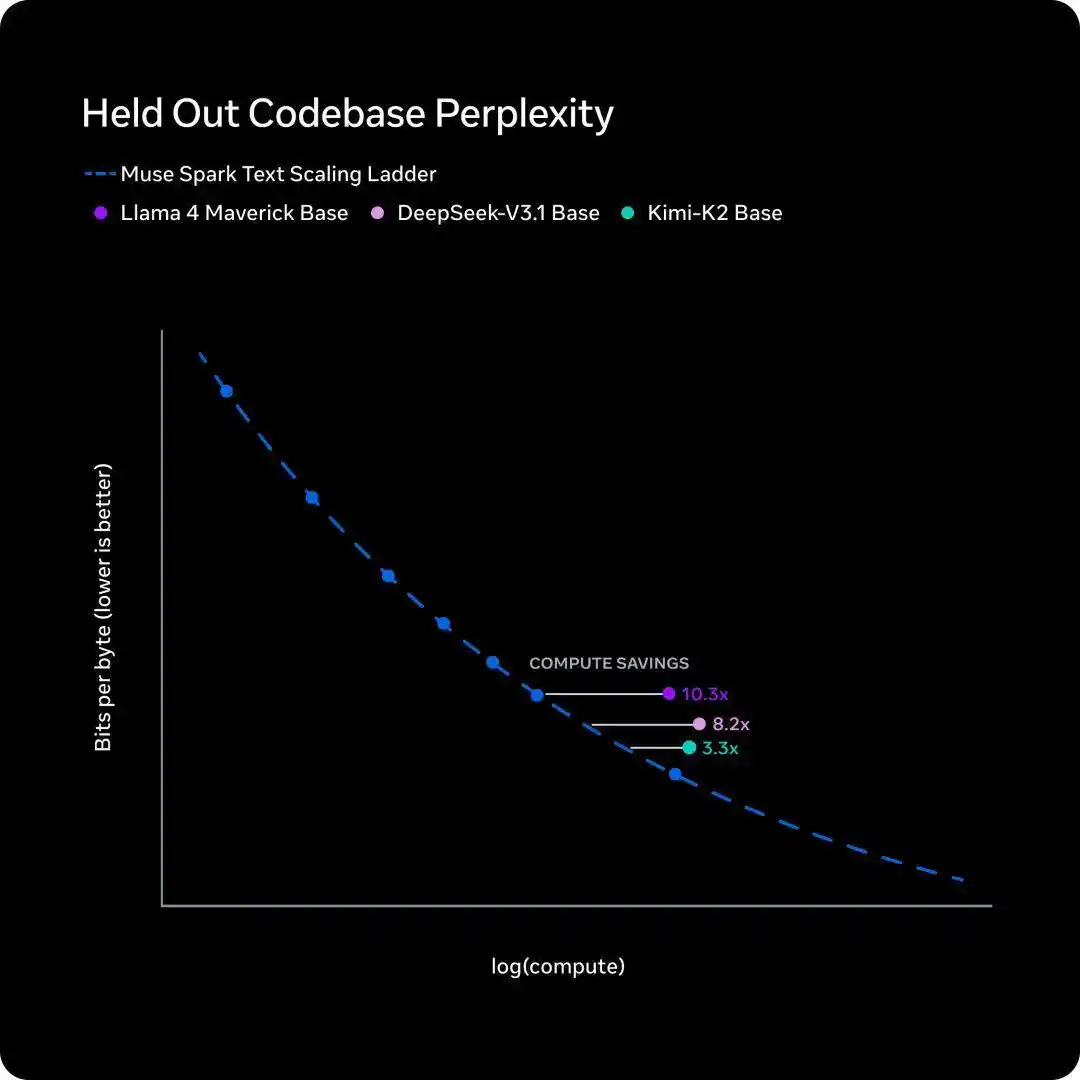
Lima hari kemudian, 8 April, Meta AI SuperLab merilis model baru Muse Spark, mengungkap kurva efisiensi pelatihan internal yang disebut 'scaling ladder', dan kesimpulannya juga satu kalimat.
Untuk mengejar kinerja Llama 4 Maverick setahun yang lalu, model baru hanya membutuhkan kurang dari sepersepuluh daya komputasi pelatihan.
Satu mengukur durasi tugas, satu mengukur daya komputasi pelatihan. Kedua lembaga tidak terkait, metode penelitian sama sekali tidak tumpang tindih.
Tapi ketika kedua kurva dikonversi ke sistem koordinat yang sama, kemiringannya hampir sepenuhnya重合 (bertepatan).
Sampai di sini, hal ini sudah cukup aneh.
Yang lebih aneh lagi, kurva ini telah digambar dengan lengkap oleh sebuah tim China dua tahun lalu, dan bahkan diterbitkan di jurnal Nature sub-jurnal.
Ini disebut Hukum Kepadatan (Density Law).

Dua Tahun Lalu, Seseorang Telah Menggambar Garis Ini Lebih Dulu
Konsep ini pertama kali muncul dalam makalah berjudul 'Densing Law of LLMs'.
Penulisnya adalah tim gabungan dari Facewall Intelligence dan Universitas Tsinghua, dipimpin oleh Profesor Sun Maosong dan Liu Zhiyuan, dengan penulis pertama adalah doktorand Xiao Chaojun.
Makalah ini diunggah ke arXiv pada Desember 2024, dan diterima oleh Nature Machine Intelligence pada November 2025.

Alamat makalah: https://arxiv.org/abs/2412.04315

Alamat makalah: https://www.nature.com/articles/s42256-025-01137-0
Inti dari makalah ini hanya satu kalimat.
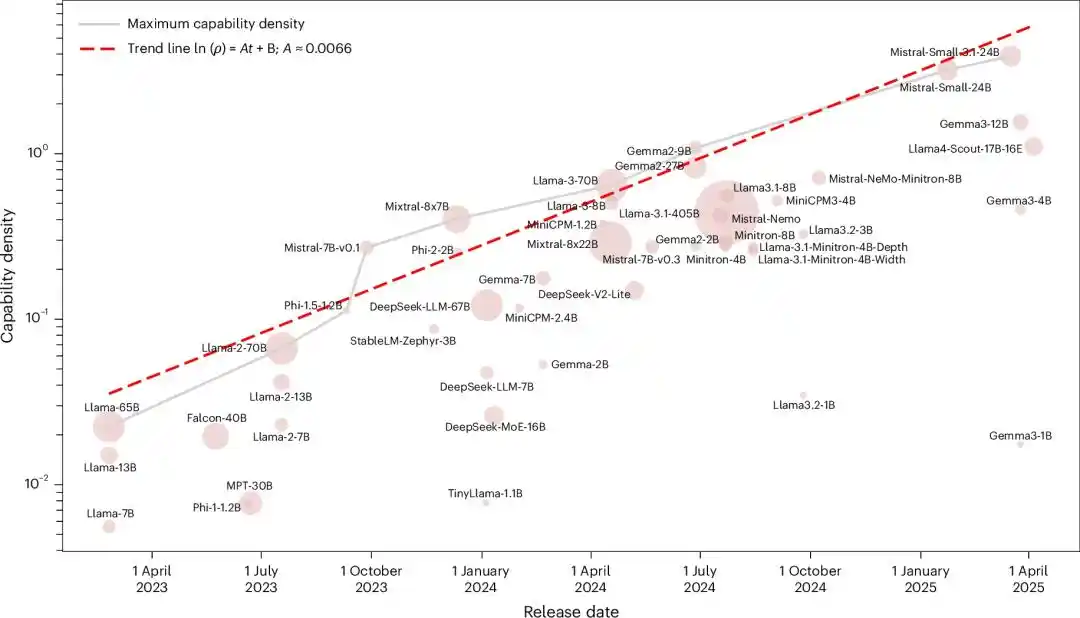
Kepadatan kecerdasan model meningkat secara eksponensial seiring waktu, jumlah parameter yang dibutuhkan untuk mencapai tingkat kecerdasan tertentu, berkurang setengah setiap 3,5 bulan.
Pada akhir 2024, pernyataan ini terdengar agak radikal.
Saat itu seluruh industri memuja scaling law. OpenAI menumpuk model, Anthropic menumpuk model, Meta juga menumpuk model.
Semua orang berpikir semakin besar parameternya semakin cerdas, membakar GPU hingga maksimal adalah jalan yang benar.
Tapi tim peneliti tidak melihatnya seperti itu.
Mereka memasukkan semua model dasar open-source yang berpengaruh pada saat itu, dari Llama-1 hingga Gemma-2, MiniCPM-3, total 51 model, ke dalam pengukur yang sama.
Setelah menjalankan lima tolok ukur, hasilnya adalah hubungan eksponensial yang hampir sempurna, dengan R2 mencapai 0,934.
Mengingat evaluasi model besar mudah terganggu oleh polusi data, mereka menguji ulang dengan kumpulan data penyaringan polusi yang baru dibangun, MMLU-CF. R2=0,953.
Dua kali fitting mendapatkan R2 mendekati 1. Secara statistik, ini hampir tidak mungkin kebetulan.
Dengan kata lain, setiap model open-source utama yang dirilis dalam dua tahun terakhir, tidak peduli dari tim mana, menggunakan arsitektur apa, jatuh pada garis eksponensial 'berlipat ganda setiap 3,5 bulan' yang sama.
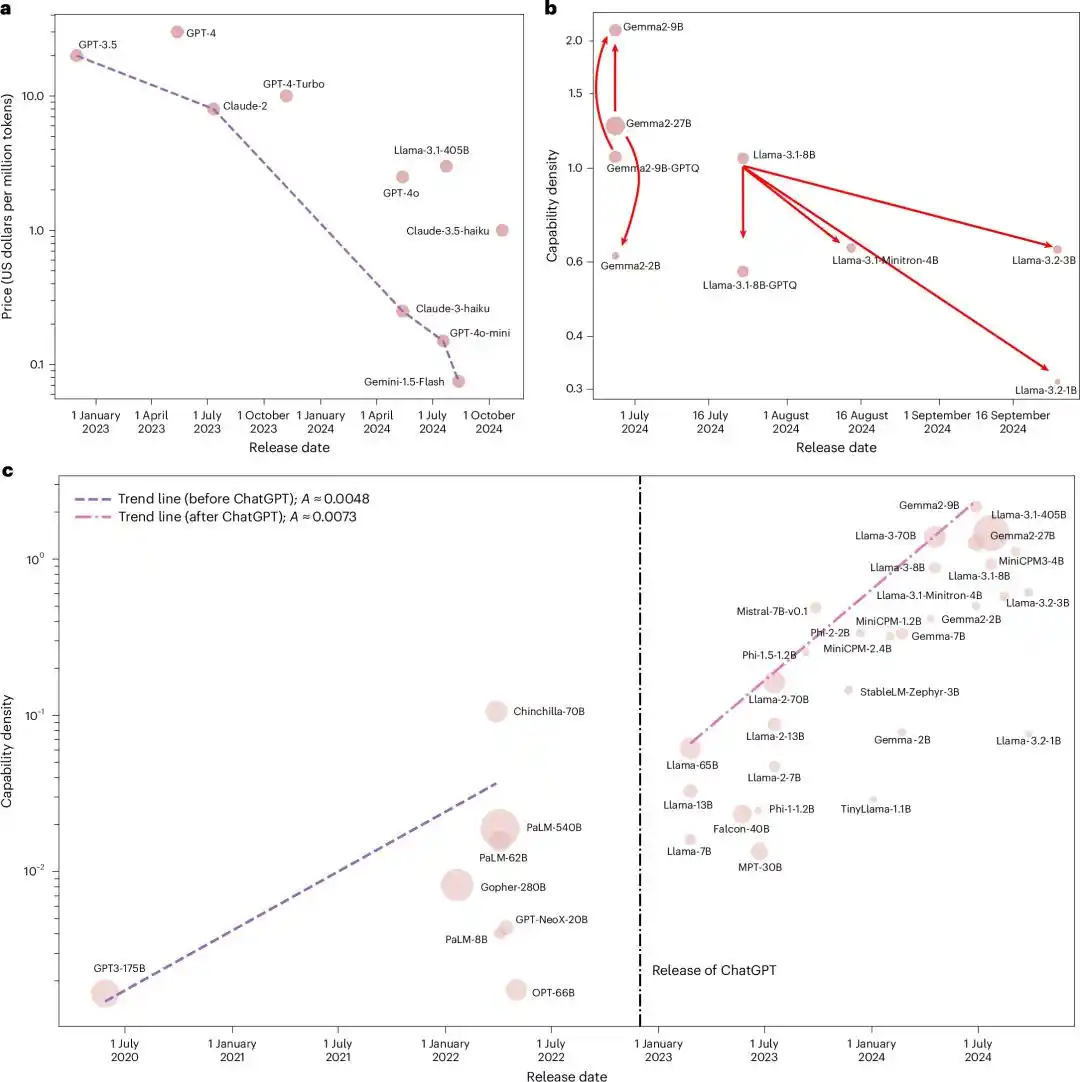
Sampai di sini, ceritanya masih 'sebuah tim China mengusulkan hukum empiris yang tampak radikal'.
Apa yang benar-benar mengubah hal ini menjadi sebuah 'momen', adalah hal-hal yang terjadi dalam setengah tahun berikutnya.
Tiga Lembaga, Tiga Metode, Kemiringan yang Sama
Mari bentangkan kesimpulan dari tiga pihak: Facewall, Meta, METR.
- Hukum Kepadatan Facewall mengukur 'berapa banyak parameter yang dibutuhkan untuk tingkat kecerdasan yang sama'. Kesimpulannya adalah kebutuhan parameter berkurang setengah setiap 3,5 bulan.
- Scaling ladder Meta mengukur 'berapa banyak daya komputasi pelatihan yang dibutuhkan untuk tingkat kecerdasan yang sama'. Kesimpulannya adalah Muse Spark menghemat satu order of magnitude dibandingkan Llama 4 Maverick setahun lalu.
- Laporan rentang waktu METR mengukur 'seberapa lama tugas yang dapat ditangani model yang sama'. Kesimpulannya adalah durasi tugas berlipat ganda setiap 88,6 hari.
Tiga pengukur. Tiga lembaga akademik. Tiga jalur penelitian yang tidak ada tumpang tindih sama sekali.
Tetapi ketika semua angka dikonversi dan dilihat dalam sistem koordinat yang sama, kemiringan kurva mereka hampir sepenuhnya bertepatan.
Hal yang paling mudah diabaikan adalah, Hukum Kepadatan adalah yang paling awal diusulkan di antara ketiganya. Hampir dua tahun lebih awal dari scaling ladder Meta, dan lebih dari setahun lebih awal dari pemodelan lengkap METR.
Dan ketika Meta menggambar scaling ladder itu dalam blog rilis awal April, mereka mungkin sendiri tidak menyadari. Bentuk gambar ini hampir sama dengan kurva pada PPT konferensi akademik di Beijing tahun 2024.
Observasi Seperti Apa, yang Pantas Disebut 'Hukum'
Di dunia ilmiah, ada standar tidak tertulis untuk menilai apakah suatu observasi empiris layak disebut 'hukum'.
Bukan dilihat dari seberapa bagus datanya, tetapi apakah itu dapat berlaku secara bersamaan di beberapa sistem pengukuran yang independen.
Alasan Hukum Moore adalah hukum, karena industri semikonduktor telah memverifikasinya puluhan tahun dari tiga dimensi yang sangat berbeda: akurasi fotolitografi, kepadatan transistor, biaya per unit komputasi.
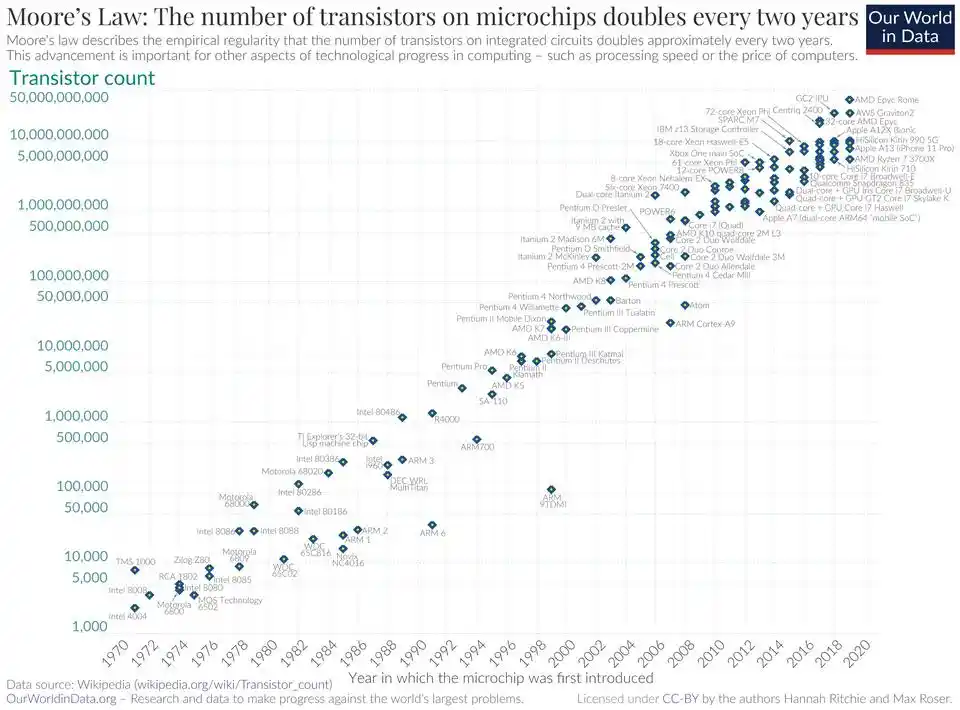
Hukum Kepadatan menempuh jalan yang sama.
Awalnya hanya merupakan kurva fitting dari satu tim. Pada saat diterima oleh Nature sub-jurnal, itu sudah dapat direproduksi pada dataset yang disaring polusi. Sampai bulan ini, itu divalidasi lagi dua kali secara independen dalam data pelatihan Meta dan evaluasi tugas METR.
Dilihat dalam sistem koordinat yang lebih besar, momen ini sangat mirip dengan saat listrik pertama kali masuk New York pada tahun 1880-an.
Saat itu juga beberapa penemu berbeda, insinyur berbeda, kota berbeda, masing-masing mengerjakan jaringan listrik mereka sendiri. Sampai seseorang menggambar kurva perkembangan semua proyek di selembar kertas, orang-orang baru menyadari. Ini bukan beberapa kemajuan teknik yang terpisah, ini adalah era baru yang sedang dibuka diam-diam.
Hanya saja kali ini, dari publikasi makalah hingga divalidasi oleh rekan global, hanya membutuhkan waktu kurang dari setahun.
Tiga Inferensi, Masing-masing Mengubah Asumsi Industri
Jika Hukum Kepadatan dapat dipertahankan, itu akan mengubah banyak hal secara bersamaan.
Pertama, biaya inferensi akan anjlok lebih cepat dari yang diperkirakan semua orang.
Satu inferensi dari Hukum Kepadatan adalah, untuk LLM dengan kinerja yang sama, biaya inferensi kira-kira berkurang setengah setiap 2,6 bulan.
Sekarang, penurunan ini telah terlampaui oleh kenyataan.
Data pelacakan terbaru Epoch AI menunjukkan, untuk LLM dengan tingkat kinerja Claude 3.5 Sonnet, harga token dalam setahun terakhir turun 400 kali lipat. Penurunan tercepat untuk tingkat kinerja yang sama menyentuh 900 kali/tahun.
Tingkat kinerja seperti GPT-3.5 yang dibanderol $20/juta token pada akhir 2022, hari ini Mistral Nemo hanya $0,02, lebih murah 1000 kali, modelnya bahkan lebih kuat.
Melihat ke belakang, prediksi dalam makalah masih konservatif.
Kedua, titik ledakan kecerdasan ujung (edge AI) lebih dekat dari yang dibayangkan semua orang.
Mengalikan Hukum Kepadatan dan Hukum Moore akan menghasilkan angka yang lebih mengejutkan.
Menurut perkiraan saat ini, skala model efektif maksimum yang dapat dijalankan pada chip dengan harga yang sama, kira-kira berlipat ganda setiap 88 hari.
Angka ini hampir sama dengan 88,6 hari yang dihitung METR. Dua jalur perhitungan yang sangat berbeda, bertabrakan di belakang koma.
Tiga hingga lima tahun ke depan, menjalankan model tingkat GPT teratas saat ini di laptop biasa atau bahkan ponsel, mungkin bukan lagi fiksi ilmiah.
Ketiga, strategi optimal industri model besar, sedang berbalik diam-diam.
Tiga tahun terakhir, pemahaman industri tentang scaling law tetap berada pada 'menumpuk parameter dan data'
Tapi Hukum Kepadatan memberikan penilaian yang kontra-intuitif. Dalam kondisi kepadatan yang terus meningkat secara eksponensial, model terkuat dalam keadaan apa pun hanya memiliki jendela optimal beberapa bulan.
Menggunakan semua sumber daya untuk melatih model yang lebih besar, lalu menunggu tiga bulan untuk disalip oleh model baru dengan ukuran setengah, tidaklah hemat dalam perhitungan ekonomi.
Jalan yang benar-benar berkelanjutan, adalah dengan mengalokasikan sumber daya pada peningkatan kepadatan itu sendiri. Arsitektur yang lebih baik, data berkualitas lebih tinggi, algoritma pelatihan yang lebih cerdas.
Facewall, Terus Berjalan Mengikuti Penggaris yang Digambarnya Sendiri
Perlu dikatakan, Hukum Kepadatan bukanlah makalah yang selesai setelah diterbitkan.
Facewall Intelligence yang mengusulkan teori ini, selama dua tahun terakhir terus memverifikasinya dengan model seri 'MiniCPM' mereka sendiri.
Ketika MiniCPM-1-2.4B dirilis pada Februari 2024, skornya dapat menyamai atau melampaui Mistral-7B dari September 2023. Artinya, dalam empat bulan, dengan 35% parameter, mencapai kinerja yang setara.
Angka ini langsung ditulis dalam makalah Nature sub-jurnal, sebagai studi kasus empiris pertama dari Hukum Kepadatan.
Sejak itu, seri MiniCPM terus open-source, mencakup empat arah utama: teks, multimodal, suara, full-modal dengan parameter di bawah 10B. Kelengkapan open-source ini, di dalam negeri selain Alibaba, hanya Facewall yang melakukannya.
Sampai saat ini, jumlah unduhan open-source seri MiniCPM secara global telah突破 (melampaui) 24 juta kali.
Ini bukan model terbesar di industri. Tapi ini adalah tim pertama di industri yang menjalankan 'kepadatan prioritas' sebagai metodologi perusahaan.
Dan ketika Meta dan METR memvalidasi Hukum Kepadatan dengan cara mereka masing-masing pada minggu April 2026 ini, perusahaan China yang telah mulai melatih model dengan metodologi ini sejak 2024, sebenarnya telah memimpin pengalaman teknik selama dua tahun.
Kali Ini, Peneliti China Berada di Titik Awal Kurva
Sebuah kerangka teori yang diusulkan tim peneliti China dua tahun lalu, sedang ditemukan kembali berulang kali oleh lembaga-lembaga paling serius di luar negeri seperti Meta, METR, dengan cara mereka masing-masing.
Bobot hal ini, mungkin butuh waktu untuk sepenuhnya dipahami.
Ini bukan cerita 'kami juga bisa'. Ini adalah cerita 'kami melihat lebih awal sedikit'.
Dalam sejarah sains, momen seperti ini tidak banyak. Sebuah penilaian yang diragukan pada tahun 2024, menjadi kurva yang sama yang ditunjukkan oleh banyak bukti independen pada tahun 2026.
'Kebetulan' lintas wilayah, lintas metode, lintas lembaga seperti ini, terjadi beberapa kali dalam fisika, setiap kali menandai berakhirnya paradigma lama dan dimulainya paradigma baru.
Peneliti AI China kali ini berada di titik awal itu.
Dan kurva itu, masih terus naik dengan kecepatan berlipat ganda setiap 88 hari.
Referensi:
Hukum Kepadatan' yang dipelopori Facewall Intelligence, Diakui Lembaga Top Luar Negeri Seperti Meta
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
Artikel ini berasal dari akun WeChat "新智元", Editor: Haokun Peach (好困 桃子)







