
Bayangkan sebuah skenario: Anda meminta tiga asisten AI untuk berkolaborasi menyelesaikan sebuah soal matematika.
Cara tradisionalnya adalah—AI pertama "menulis" ide penyelesaian, AI kedua "membaca" lalu menulis ide baru, AI ketiga "membaca" lagi lalu "menulis" lagi.
Proses ini, seperti tiga orang yang bergantian menyampaikan informasi menggunakan walkie-talkie, setiap kali harus "menerjemahkan" pemikiran di kepala menjadi bahasa, lalu lawan bicara harus "menerjemahkan" kembali bahasa menjadi pemikiran. Lambat tidak? Lambat. Boros tidak? Boros. Yang lebih parah, proses "penerjemahan" ini bisa menghilangkan informasi—apa yang Anda pikirkan di kepala, seringkali tidak sama dengan apa yang Anda ucapkan.
Inilah inti dilema yang dihadapi sistem AI multi-agent saat ini: "Bahasa Pajak".
Dan baru-baru ini, UIUC, Stanford, NVIDIA, MIT bersama-sama mengusulkan pendekatan baru—RecursiveMAS. Ini membuat AI-AI melewatkan langkah "berbicara", dan langsung berkomunikasi menggunakan "pikiran". Dalam pengujian, kecepatan penalaran meningkat 2.4 kali, konsumsi Token berkurang 75%.
(Studi dapat diakses: https://arxiv.org/abs/2604.25917)
Dilema Rapat AI: Efisiensi Terbuang pada "Berbicara"
Dua tahun terakhir, sistem multi-agent telah menjadi arah penelitian paling populer di bidang AI. Dari Swarm milik OpenAI hingga AutoGen milik Microsoft, dari LangGraph hingga CrewAI, berbagai pihak mengeksplorasi bagaimana membuat beberapa AI bekerja sama untuk menyelesaikan tugas kompleks yang tidak dapat diselesaikan oleh model tunggal. Namun, dalam sistem-sistem ini, efisiensi kolaborasi beberapa agent selalu dibatasi oleh satu asumsi dasar—agent harus berkomunikasi melalui teks bahasa alami.
Ketika Anda meminta seorang "ahli matematika" dan seorang "pemeriksa kode" untuk berkolaborasi, alur keseluruhan terlihat "masuk akal", tetapi jika diurai akan ditemukan banyak masalah:
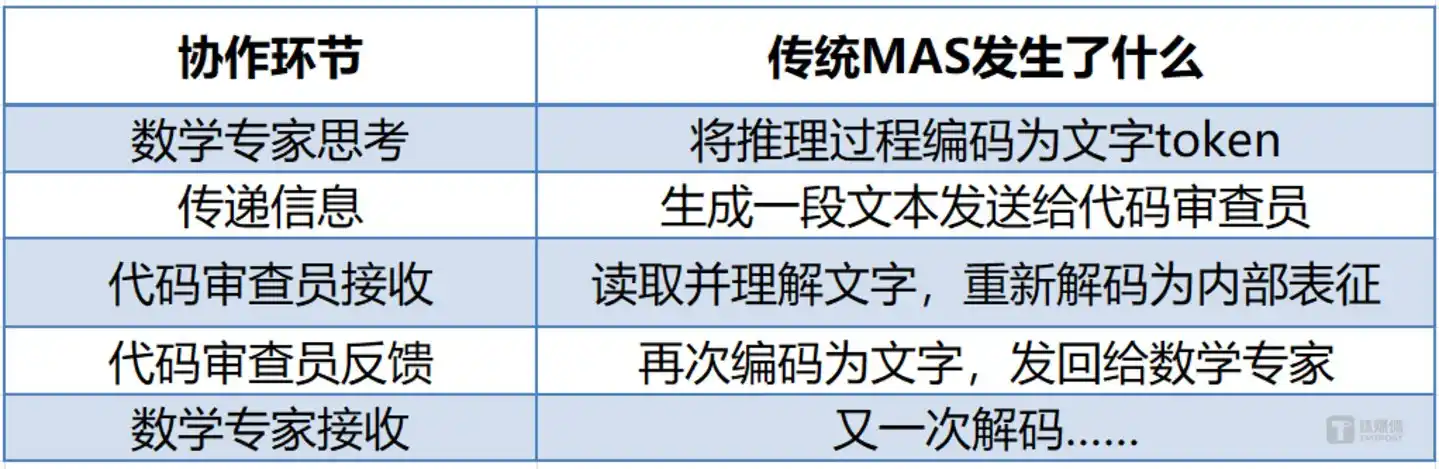
Setiap kali transfer informasi, disertai dengan konversi ganda: pemikiran internal → teks → pemikiran internal. Proses ini tidak hanya mengkonsumsi token yang berarti uang, tetapi juga sumber daya komputasi dan waktu yang berharga. Lebih krusial lagi, proses "menulis lalu membaca" ini menghilangkan informasi—semantik kaya yang dimampatkan ke dalam teks saat dekode model, saat model berikutnya mendekode ulang sudah tidak dapat sepenuhnya mengembalikan. Dalam alur kerja yang melibatkan lima Agent, overhead waktu untuk encoding/decoding teks sering kali mencapai lebih dari 60% dari total latency.
Yang lebih menyulitkan, paradigma ini selalu kekurangan "knob" yang jelas untuk optimasi sistematis—menambah lebih banyak agent? Manfaat marginal menurun, dan overhead komunikasi meledak secara eksponensial. Memperbesar jendela konteks? Biaya Token meledak. Menambah parameter model? Agent tunggal menjadi lebih kuat, tetapi efisiensi kolaborasi tidak meningkat secara fundamental—mirip dengan memberikan walkie-talkie yang lebih baik kepada sekelompok orang, tetapi mereka tetap harus membaca teks satu per satu, cara komunikasi tidak berubah, meskipun setiap orang lebih pintar, efisiensi keseluruhan tidak dapat mengalami terobosan. Solusi di industri, baik rekayasa prompt maupun fine-tuning LoRA, hanya dapat meringankan gejala sampai batas tertentu, tidak dapat menyembuhkan masalah mendasar arsitektur ini.
RecursiveMAS: Ganti "Walkie-Talkie" dengan "Telepati"
Pemikiran inti RecursiveMAS sangat cerdik: karena bahasa adalah hambatan, maka jangan gunakan bahasa.
Ia meminjam pemikiran dari model bahasa rekursif (Recursive Language Model). Dalam model bahasa tradisional, data mengalir dari lapisan pertama ke lapisan terakhir, maju linear, semakin banyak lapisan, semakin banyak parameter; sedangkan model bahasa rekursif berjalan sebaliknya—tidak menambah lapisan, tetapi menggunakan sekelompok lapisan yang sama secara berulang, membiarkan data "berputar" bolak-balik antar lapisan. Setiap kali data melewati kelompok lapisan ini, itu setara dengan satu putaran "berpikir" tambahan, kedalaman penalaran diperdalam, tetapi jumlah parameter tidak perlu ditambah.
RecursiveMAS memperluas pemikiran ini dari "di dalam model tunggal" menjadi "sistem multi-agent":
Setiap agent seperti satu lapisan dalam model bahasa rekursif, mereka tidak lagi menghasilkan teks, tetapi meneruskan "pikiran"—sebuah representasi vektor kontinu yang ada di ruang laten (latent space).
Para peneliti menggunakan metafora puitis: "agents communicating telepathically as a unified whole"—agent-agent berkolaborasi seperti telepati sebagai satu kesatuan utuh.
Secara spesifik, Agent A1 memproses lalu meneruskan representasi latennya ke Agent A2, A2 memproses lalu meneruskan ke A3... hingga Agent terakhir selesai memproses, output latennya langsung dikirim kembali ke A1, memulai iterasi rekursif baru. Seluruh proses berlangsung sepenuhnya di ruang laten, hanya pada Agent terakhir di putaran terakhir, representasi laten akhir didekode menjadi output teks. Ini seperti sekelompok ahli duduk mengelilingi meja, tidak perlu bicara, tidak perlu menulis catatan, setiap orang hanya perlu berpikir diam-diam, lalu langsung meneruskan "hasil pemikiran" di kepalanya ke orang berikutnya—seluruh proses tenang dan efisien.
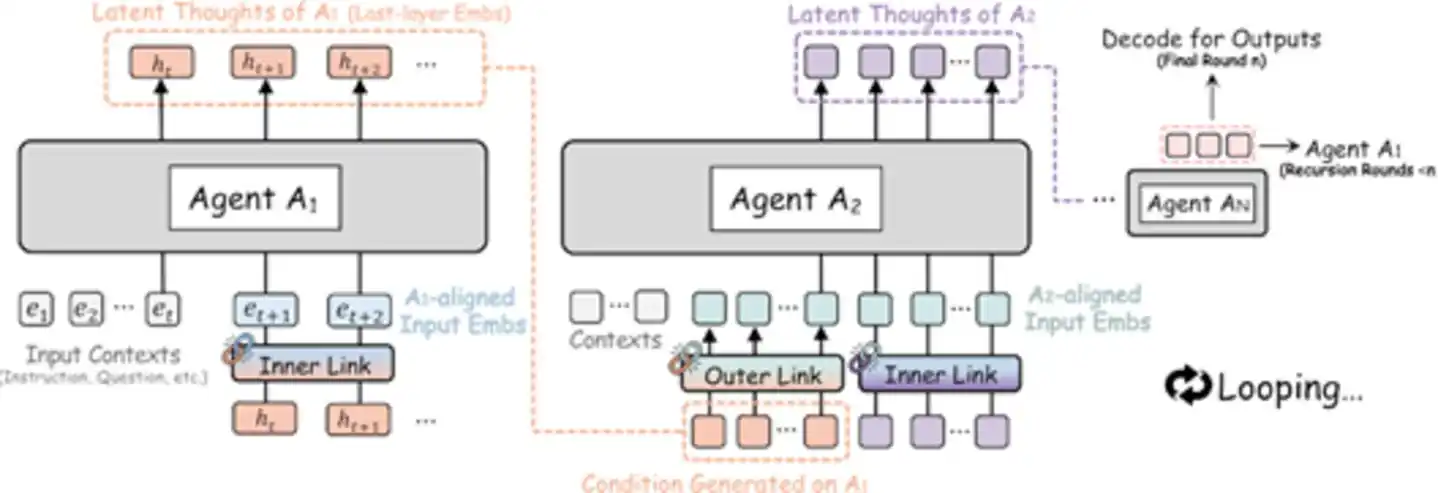
Gambar: Ilustrasi Arsitektur RecursiveMAS—Multi-Agent Mencapai Kolaborasi Rekursif Tertutup Melalui Ruang Embedding (Sumber: arXiv)
Komponen kunci sistem ini disebut RecursiveLink, sebuah modul residual dua lapis ringan, bertanggung jawab untuk mempertahankan dan mengubah representasi lapisan laten satu model, lalu meneruskannya ke ruang embedding model berikutnya. Status laten lapisan terakhir model bahasa sebenarnya telah mengkodekan informasi penalaran semantik yang kaya, tugas RecursiveLink adalah "memindahkan" informasi berdimensi tinggi ini secara utuh, bukan menerjemahkannya ke teks dulu lalu menginterpretasikannya. Ia memiliki dua versi, internal dan eksternal:

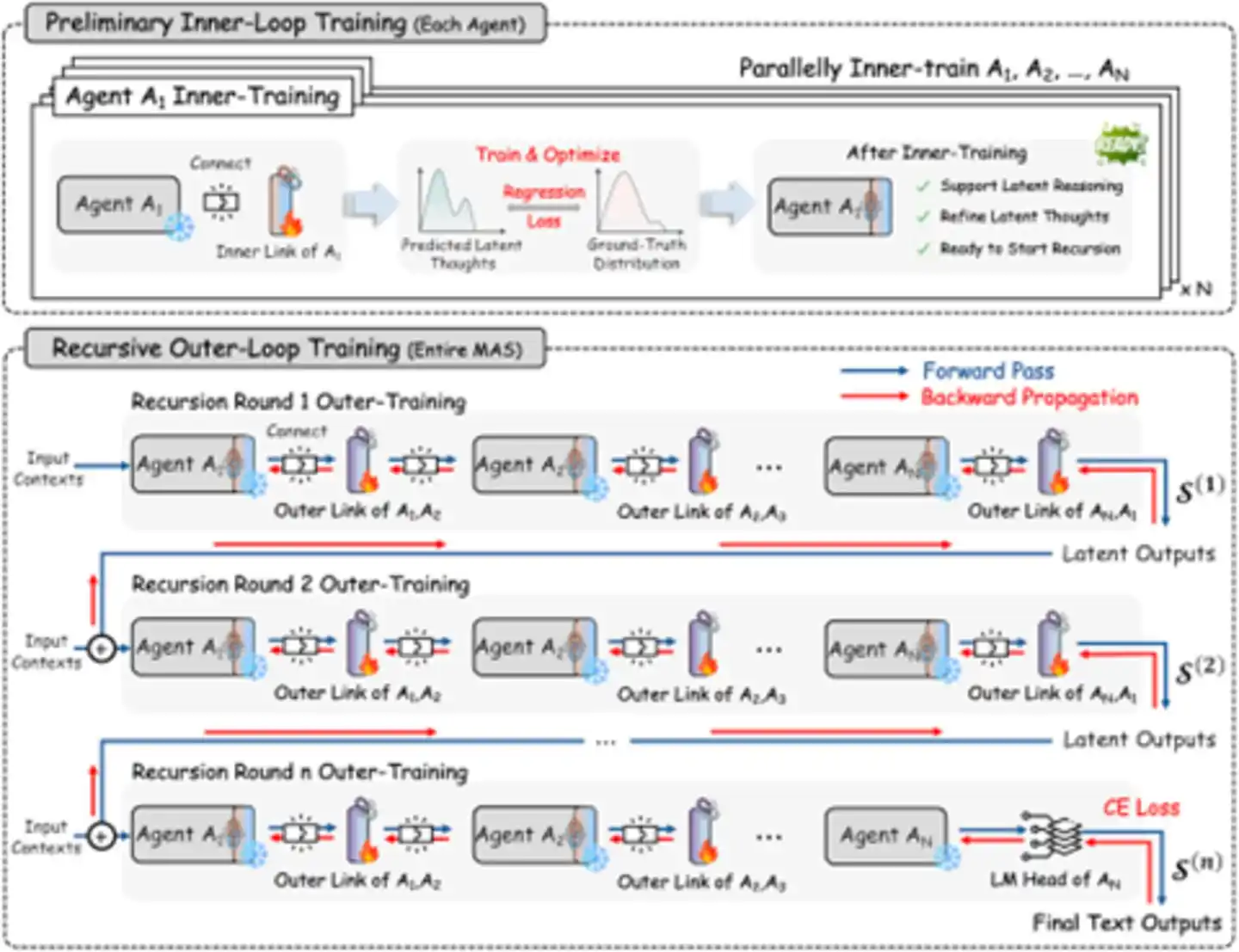
Gambar: Proses Pembelajaran Rekursif—Tautan Internal dan Eksternal Berlatih Bersama (Sumber: arXiv)
Dalam strategi pelatihan, RecursiveMAS memiliki desain yang cerdik: berat model utama sepenuhnya dibekukan, hanya modul RecursiveLink yang perlu dilatih. Ini memiliki semangat yang mirip dengan LoRA (Low-Rank Adaptation), tetapi RecursiveLink lebih ringan: seluruh sistem hanya perlu memperbarui sekitar 13 juta parameter, hanya 0.31% dari total parameter yang dapat dilatih. Kebutuhan memori GPU puncak terendah di antara semua metode perbandingan, biaya pelatihan berkurang lebih dari 50% dibandingkan fine-tuning penuh. Anda dapat memahaminya sebagai "adaptor ringan", langsung disambungkan ke ekosistem Agent yang ada, tanpa perlu melatih model baru dari awal. Jika beberapa Agent didasarkan pada model dasar yang sama (misalnya semua menggunakan Qwen), mereka bahkan dapat berbagi berat model yang sama, lebih menghemat memori.
Pelatihan dilakukan dalam dua tahap:
Pemanasan Loop Internal: Setiap agent secara independen melatih Inner RecursiveLink-nya sendiri, membuat mereka belajar "berpikir masalah" di ruang laten, bukan "menulis masalah". Tahap ini dapat dilakukan secara paralel, seperti meminta setiap orang berlatih "monolog internal" terlebih dahulu.
Pelatihan Loop Eksternal: Menghubungkan semua agent menjadi sirkuit rekursif lengkap, dengan kualitas output teks akhir sebagai tujuan optimasi, mengoptimalkan semua RecursiveLink bersama melalui gradient sharing. Tahap ini menyelesaikan masalah "penugasan kredit"—bagaimana mengaitkan keberhasilan atau kegagalan hasil akhir secara akurat dengan kontribusi setiap Agent. Strategi bertahap ini menghindari masalah ketidakstabilan pelatihan yang mungkin terjadi jika dilakukan "sekali jadi".
Para peneliti secara teoretis membuktikan bahwa gradient pelatihan rekursif dapat tetap stabil, tidak akan muncul masalah gradient exploding atau vanishing seperti yang umum terjadi pada RNN, sekaligus dalam kompleksitas runtime juga lebih unggul daripada MAS berbasis teks tradisional.
Hasil Uji Nyata: Akurasi, Kecepatan, Biaya "Tiga Serangkai"
Teori sebaik apapun, pada akhirnya harus dibuktikan dengan data. Tim penelitian melakukan evaluasi menyeluruh pada 9 tes benchmark utama yang mencakup matematika, sains dan kedokteran, generasi kode, tanya jawab pencarian, dan 4 mode kolaborasi (penalaran berurutan, campuran ahli, distilasi pengetahuan, pemanggilan alat secara negosiasi). Model open-source yang digunakan dalam eksperimen cukup "mewah"—Qwen, Llama-3, Gemma3, Mistral, model-model ini diberi peran berbeda, membentuk berbagai mode kolaborasi.
Barisan baseline perbandingan juga solid: fine-tuning LoRA, fine-tuning penuh (SFT), Mixture-of-Agents, TextGrad, LoopLM, serta Recursive-TextMAS yang menggunakan struktur siklus rekursif sama tetapi memaksa komunikasi teks. Kontrol terakhir ini sangat krusial—membuktikan bahwa keunggulan RecursiveMAS memang berasal dari "melewatkan dekode teks", bukan dari struktur rekursif itu sendiri. Semua perbandingan dilakukan dengan anggaran pelatihan yang sama, adil dan setara.
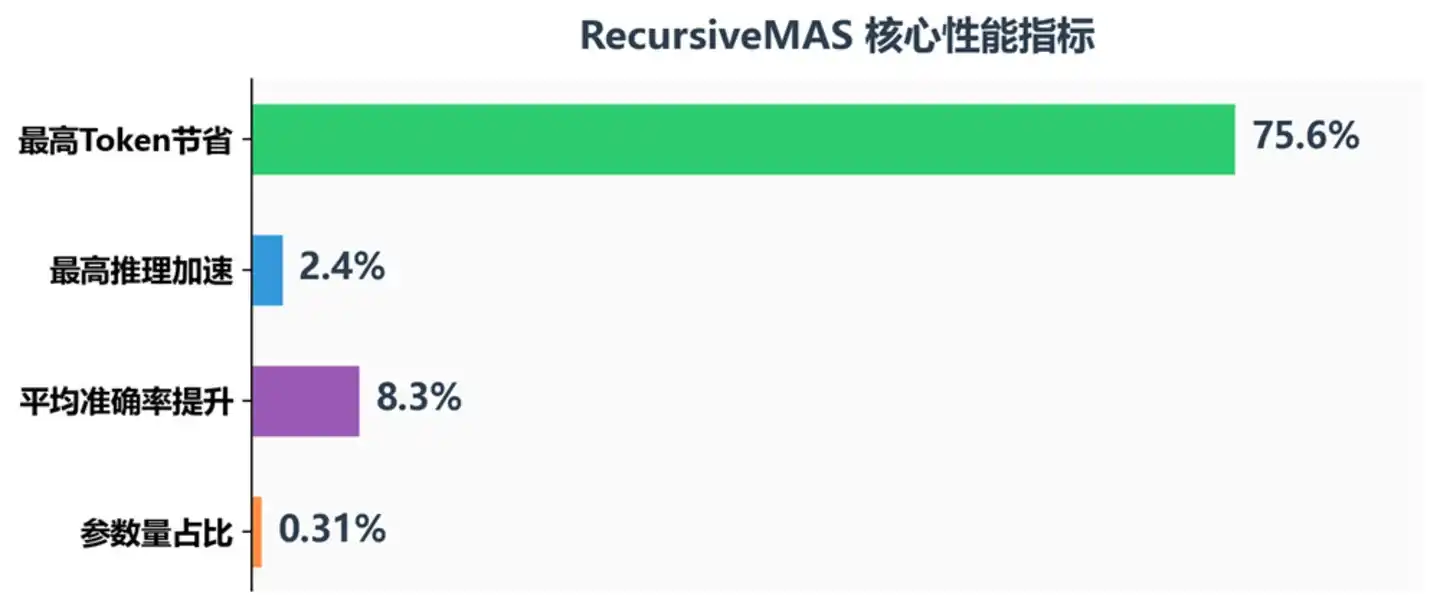
Indikator Kinerja Inti RecursiveMAS
Hasil menunjukkan, RecursiveMAS mencapai peningkatan konsisten di semua indikator:
Akurasi: Akurasi rata-rata meningkat 8.3%, pada kompetisi matematika AIME2025 18.1% lebih tinggi dari TextGrad, pada AIME2026 13% lebih tinggi. Melewatkan dekode teks tidak hanya tidak kehilangan informasi, malah membuat model mempertahankan semantik laten yang lebih kaya—bagaimanapun, kerugian informasi dalam proses memampatkan pemikiran menjadi teks lalu mendekompresi, jauh lebih besar dari yang kita bayangkan.
Kecepatan: Kecepatan inferensi end-to-end meningkat 1.2 kali hingga 2.4 kali, dan terus bertambah seiring peningkatan putaran rekursif. Ini sangat berarti untuk skenario aplikasi nyata: dalam sistem bantuan AI pelanggan atau kode yang memerlukan respons real-time, peningkatan kecepatan lebih dari 2 kali berarti lompatan kualitatif dalam pengalaman pengguna.
Biaya: Dibandingkan Recursive-TextMAS, konsumsi Token berkurang 34.6% hingga 75.6%. Ini bukan hanya penghematan biaya, tetapi juga berarti dalam anggaran token yang sama dapat mencoba penalaran yang lebih dalam.
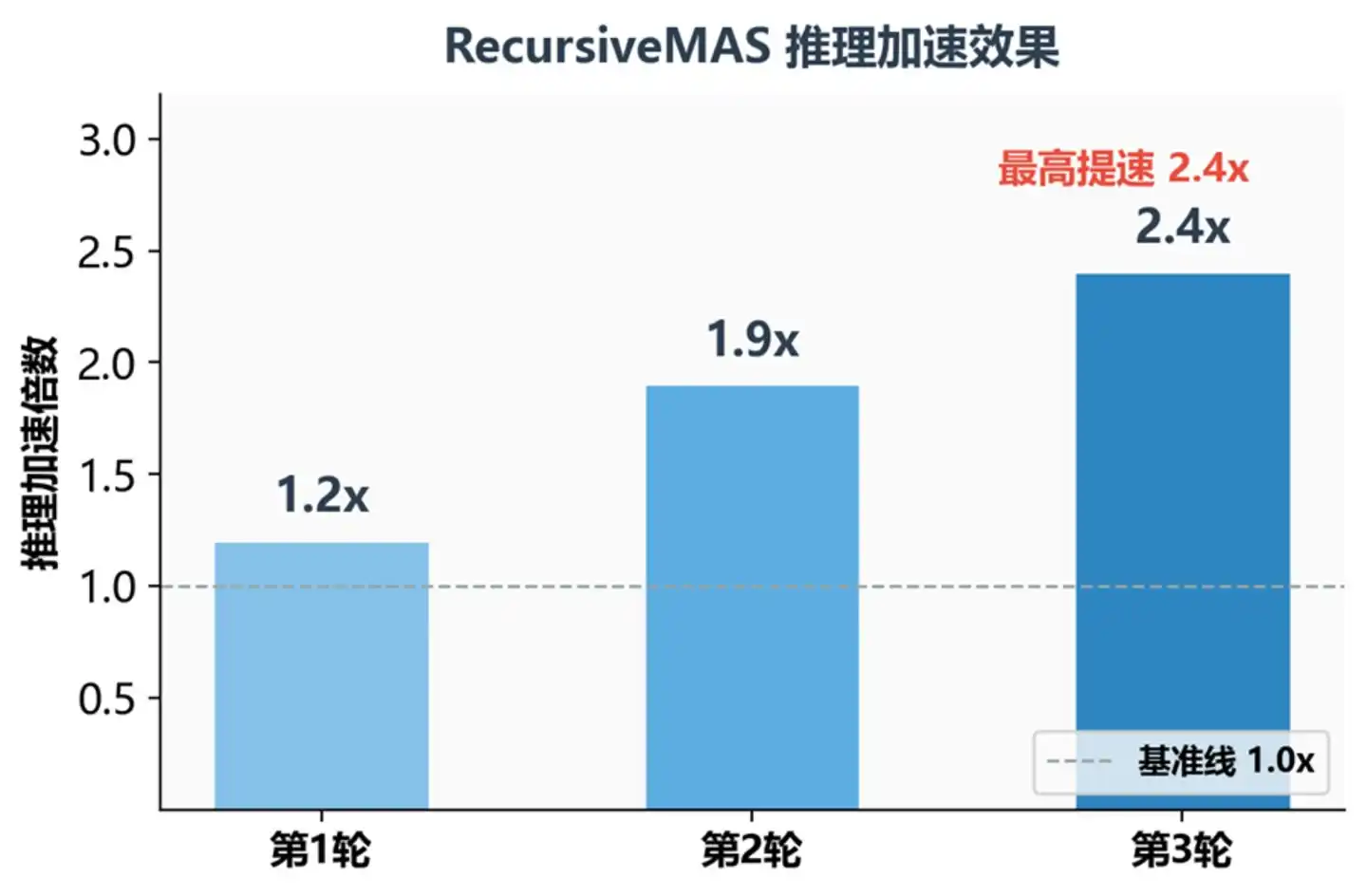
Kelipatan Percepatan Inferensi pada Putaran Rekursif Berbeda
Ada wawasan kunci di sini: semakin dalam rekursi, semakin tinggi keuntungannya. Efek percepatan bertambah seiring pertumbuhan putaran rekursif: putaran ke-1 rata-rata 1.2 kali, putaran ke-2 1.9 kali, putaran ke-3 2.4 kali. Alasannya sederhana—yang dihemat adalah waktu setiap Agent "menuliskan pemikiran menjadi teks", semakin banyak Agent, semakin banyak putaran, semakin banyak waktu yang dihemat.
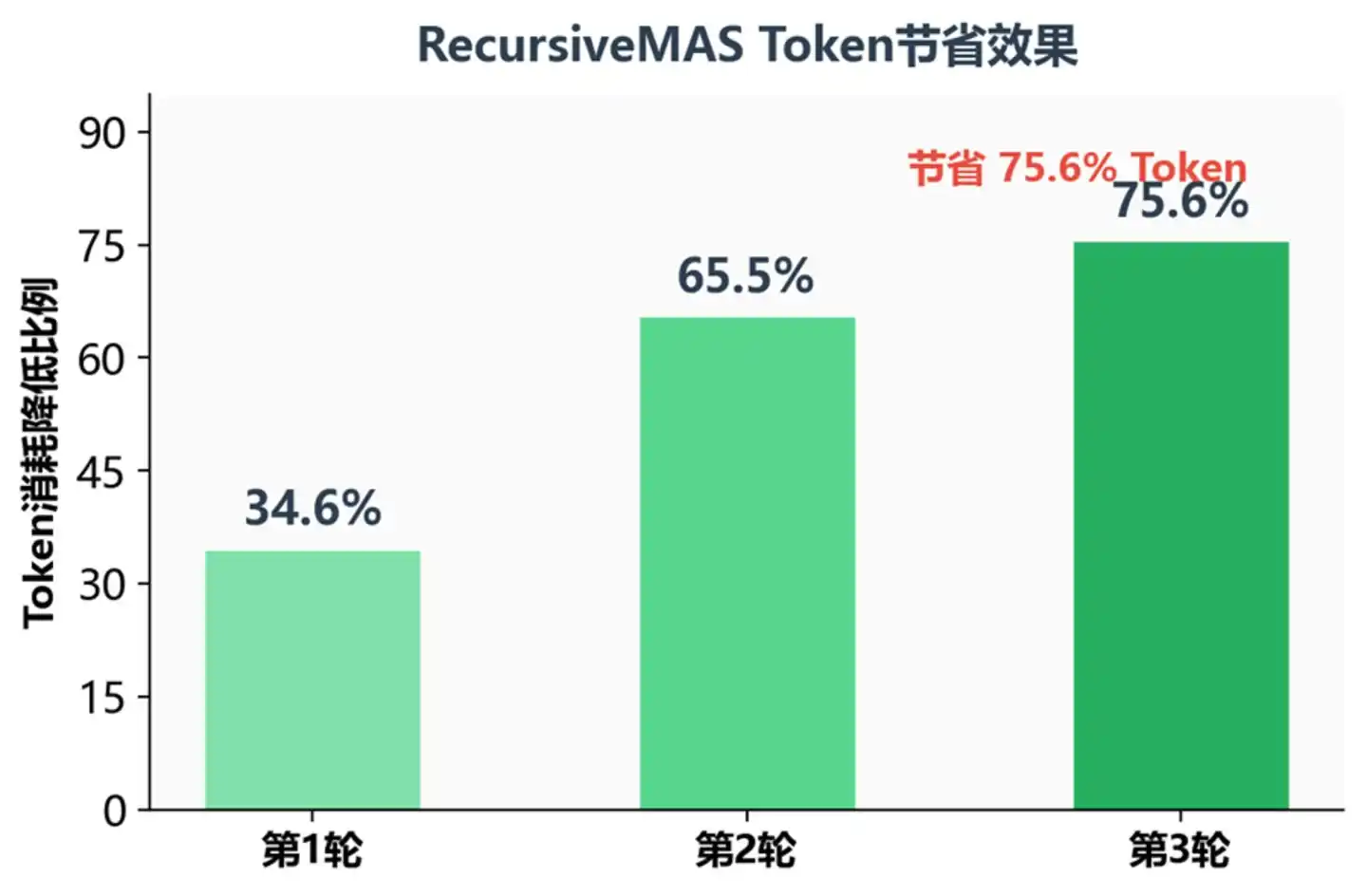
Proporsi Penghematan Token pada Putaran Rekursif Berbeda
Pada putaran rekursif ketiga, konsumsi Token berkurang 75.6%—ini berarti dengan kinerja yang setara, biaya operasi dapat dikompresi menjadi sekitar seperempat dari aslinya. Untuk lingkungan produksi yang memerlukan penalaran multi-langkah kompleks, ini jelas daya tarik yang besar.
Mengapa Penelitian Ini Layak Diperhatikan?
Jika hanya peningkatan angka, makalah ini mungkin tidak cukup menarik perhatian. Apa yang benar-benar membuatnya layak diperhatikan, adalah kemungkinannya mendefinisikan ulang arah Scaling sistem multi-agent.
Beberapa tahun terakhir, upaya Scaling di bidang multi-agent terutama berputar di tiga jalan: menambah jumlah agent, memperbesar jendela konteks, menumpuk model yang lebih besar. Tetapi metode-metode ini menghadapi bottleneck masing-masing—agent bertambah ledakan komunikasi, jendela membesar ledakan biaya, model membesar ledakan pelatihan.
RecursiveMAS menawarkan jalan baru: memperdalam kedalaman rekursi. Ia mengubah "kolaborasi multi-agent" dari paradigma paralel, interaksi teks, menjadi paradigma rekursif ruang laten yang dalam. Seperti model bahasa rekursif yang memperdalam penalaran dengan memproses masalah yang sama berulang kali, RecursiveMAS memungkinkan beberapa agent berulang kali "mempertimbangkan" "pemikiran" satu sama lain, tanpa harus "mengucapkan lalu mendengarkan kembali" setiap kali.
Pertanyaan inti yang diajukan para peneliti dalam makalah adalah: "Dapatkah kolaborasi agent itu sendiri diskalakan melalui rekursi?" Jawabannya tampaknya ya.
Ketika sistem tidak lagi perlu "menerjemahkan" representasi internal menjadi format perantara yang dapat dibaca manusia, batas atas efisiensi kolaborasi berpotensi dibuka lebih jauh.
Latar belakang industri saat ini juga menyediakan skenario implementasi nyata untuk penelitian ini. Baidu Konferensi Pengembang 2026 bertema "Segalanya Menjadi Satu (Agents at Scale)", Anthropic meluncurkan Claude Managed Agents, OpenAI terus memajukan real-time reasoning tingkat GPT-5—seluruh industri mencari cara untuk membawa kolaborasi Agent dari demo ke lingkungan produksi. Dan tiga gunung besar—biaya komputasi, latency inferensi, batasan memori—justru yang coba digerakkan RecursiveMAS dengan overhead parameter 0.31%.
Tentu saja, penelitian ini masih dalam tahap awal, ada beberapa masalah yang perlu diperhatikan:
Keterpercayaan Data Perlu Diverifikasi. Hasil saat ini dilaporkan sendiri oleh penulis, belum ada tim independen yang berhasil mereplikasi. Sikap kalangan akademis terhadap teknologi baru seringkali "berasumsi berani, verifikasi hati-hati". Di era "ledakan makalah" ini, replikasi independen adalah cara terbaik menguji nilai sebenarnya dari sebuah teknologi.
Kompatibilitas Agent Heterogen. Outer RecursiveLink meskipun dirancang untuk menghubungkan model dengan arsitektur berbeda, tetapi makalah tidak mengungkapkan detail transfer representasi laten antar arsitektur. Jika hanya dapat digunakan untuk agent yang sejenis, cakupan aplikasi praktisnya akan sangat berkurang. Bagaimanapun, dalam skenario nyata sering kali kita perlu mencampur penggunaan API tertutup seperti GPT-4o, Claude, dll.
Penurunan Kemampuan Interpretasi. Ketika yang diteruskan antar Agent bukan lagi teks yang dapat dibaca, melainkan sekumpulan representasi vektor, seluruh proses kolaborasi menjadi "kotak hitam". Dalam lingkungan produksi yang perlu mempertanggungjawabkan keputusan AI, ketidaktransparanan ini dapat menimbulkan tantangan kepatuhan dan audit.
Kompleksitas Lingkungan Produksi. Makalah menguji skenario kolaborasi yang relatif bersih, lingkungan produksi nyata sering kali melibatkan pemanggilan alat eksternal, interaksi manusia-mesin, alur kerja dinamis, dan faktor kompleks lainnya.
Pengusulan RecursiveMAS, pada dasarnya adalah memperkenalkan strategi Scaling "rekursi" yang terbukti efektif di era model tunggal, ke era multi-agent, menantang asumsi default bahwa "agent harus menyampaikan informasi melalui bahasa alami". Jika data dapat direplikasi, sumbu Scaling tahap berikutnya di lomba MAS mungkin akan beralih dari "menumpuk jumlah agent" ke "memperdalam kedalaman rekursi".
Tentu saja, penelitian ini masih perlu divalidasi di lebih banyak benchmark independen, perlu menyelesaikan masalah interkoneksi model heterogen, perlu membuktikan dirinya di lingkungan produksi nyata. Tetapi setidaknya, ini memberi kita kemungkinan—
Kolaborasi antar Agent AI, tidak harus selalu "bicara sendiri-sendiri".
((Artikel ini pertama kali diterbitkan di TiMedia APP, penulis | Silicon Valley Tech_news, editor | Jiao Yan))






