Penulis:0xSammy(Khala Research)
Kompilasi: AIdidiaoJP, Foresight News
Pasar inferensi AI saat ini tidak lagi seperti pasar layanan cloud tunggal, melainkan lebih mirip permainan 'Risk'. Setiap penyedia berebut wilayah yang berbeda: penyedia cloud hyperscaler menguasai benua korporat, router mengendalikan jalur perdagangan, dan jaringan terdesentralisasi berjuang keras di garis depan yang terbuka.
Inti dari siklus AI sebelumnya adalah pelatihan model, namun sekarang semakin jelas bahwa tahap inferensi mengandung nilai ekonomi yang sangat besar. Banyak orang mungkin pertama kali mendengar kata 'inference' (inferensi), lalu apa sebenarnya itu?
Pelatihan menciptakan model AI, sedangkan inferensi adalah proses ketika model menghasilkan jawaban saat seseorang mengajukan pertanyaan atau memberikan tugas padanya.
Gambaran Umum Pasar Inferensi AI
Alasan tahap pelatihan mendominasi berita utama adalah karena tahap itu mendukung output yang menakjubkan. Namun kenyataannya, inferensi saat ini mengambil sebagian besar manfaat ekonomi — setiap perintah, siklus agen, pembuatan gambar, eksekusi perdagangan, pemanggilan alat, dan penyuntingan kode, semuanya harus dijalankan di suatu tempat.
Router adalah Hambatan Sebenarnya
Dalam permainan 'Risk', wilayah yang paling berharga seringkali adalah hambatan sempit yang menentukan bagaimana pasukan bergerak selanjutnya. Di pasar inferensi, router memainkan peran yang persis sama. Mereka berada di antara permintaan dan penawaran, menentukan ke mana setiap permintaan dialirkan, penyedia mana yang akan mendapatkan pembayaran.
Salah satu contoh tipikal adalah OpenRouter, yang protokolnya memproses 4700 triliun token minggu lalu.
Aktivitas ekonomi ini sama sekali tidak menunjukkan tanda-tanda melambat, terutama dengan triliunan agen yang akan segera aktif.
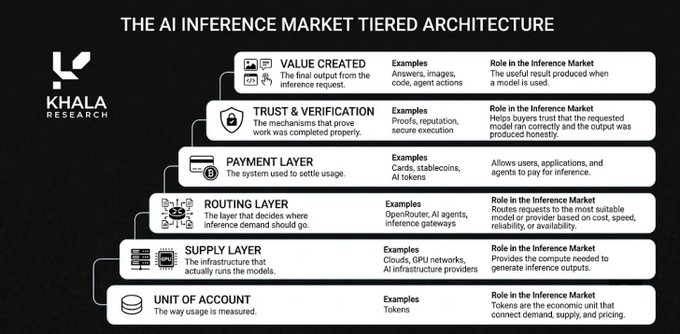
Jadi, apa yang dibutuhkan pasar inferensi yang lengkap? Elemen intinya meliputi:
- Token telah menjadi unit perhitungan
- OpenRouter dengan cepat menjadi lapisan bursa inti, dengan volume token yang digunakan melalui pasar LLM-nya mencapai 4700 triliun minggu lalu.
- Sisi penawaran khusus: Fireworks, Together, Replicate, Baseten, Groq, dan penyedia cloud hyperscaler besar.
- Jaringan AI kripto: Proyek-proyek seperti Chutes, Akash, io.net, Nosana, Targon, Venice, NuNet, yang sedang membangun versi tanpa izin di lapisan dasar.
Jangan anggap semua penyedia ini bersaing di pasar yang sama — mereka sama sekali tidak.
Penyedia tradisional menjual keandalan, pengalaman pengembang, dan proses pengadaan tingkat perusahaan.
Jaringan AI kripto menjual penawaran yang lebih murah, akses terbuka, privasi, verifiability, dan siklus insentif baru.
Baru-baru ini, kejadian di mana Anthropic melarang pengguna di luar AS menggunakan model Mythos (Fable 5) mereka membuat banyak orang menyadari kembali risiko bergantung berlebihan pada model kepemilikan tunggal di garis depan.
Yang menarik, kedua dunia mulai tumpang tindih: privasi, komputasi rahasia, atau pembayaran native untuk agen (Venice dan Targon sangat menonjol dalam hal ini).
Bagaimana Memandang Pasar Daya Komputasi AI
Perspektif yang lebih baik adalah membagi pasar menjadi dua kubu besar: tradisional dan kripto:
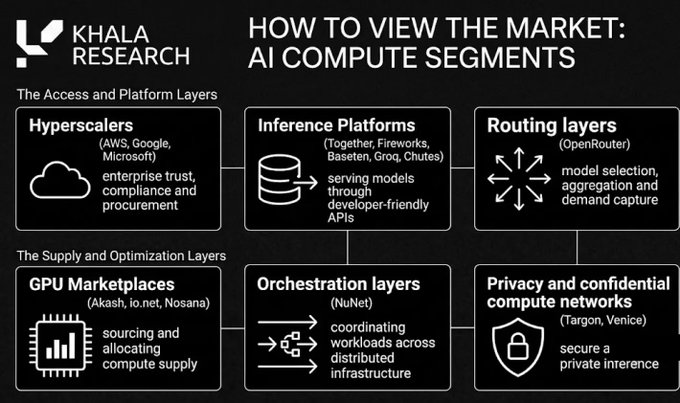
Sisi tradisional menjual keandalan, pengalaman pengembang, dan pengadaan perusahaan.
Jaringan kripto terutama bersaing dalam akses terbuka, penawaran biaya lebih rendah, privasi, verifiability, dan mekanisme insentif baru, untuk mengkoordinasikan modal secara mulus secara global.
Mengapa Inferensi adalah Pasar AI yang Sebenarnya
Lapisan model tetap penting, tetapi kualitas model sedang dikompresi dengan kecepatan yang melebihi harapan. Model open source telah mencapai 90-95% kualitas model garis depan, namun hanya memerlukan 10% biayanya (misalnya GLM-5.2 dari Z.ai).
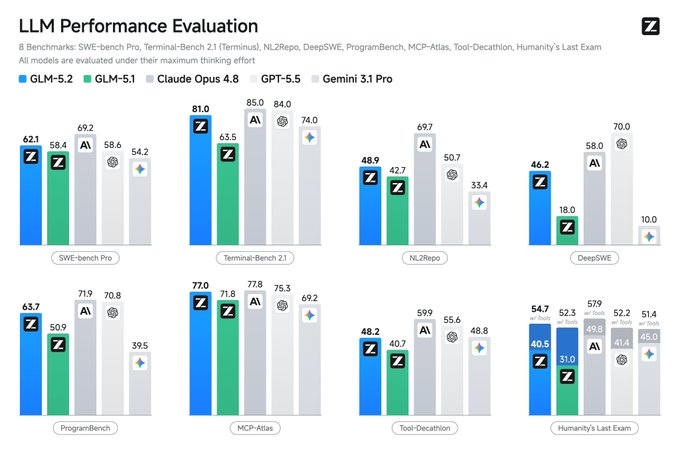
Model open source terus berulang, laboratorium Cina terus menekan harga. Model garis depan masih bisa mempertahankan harga premium, tetapi di bawahnya, persaingan harga token sudah sangat ketat.
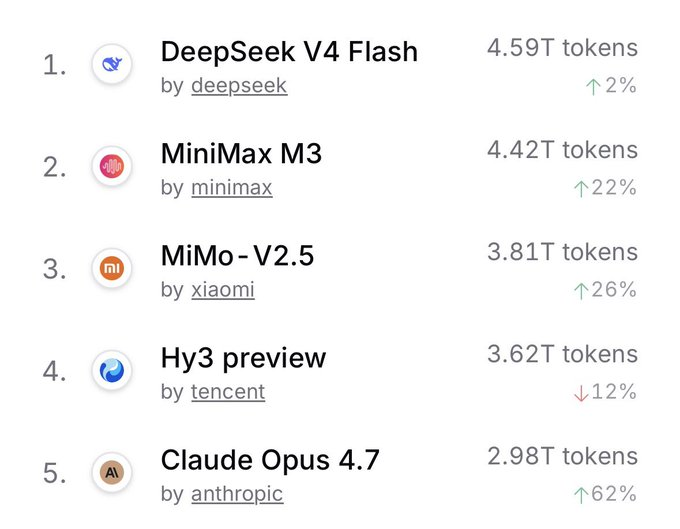
Inilah mengapa lapisan routing menjadi krusial: model open source yang sama mungkin ditawarkan oleh lima penyedia berbeda dengan lima harga berbeda, pengembang tidak ingin selamanya meng-hardcode satu endpoint, mereka membutuhkan router.
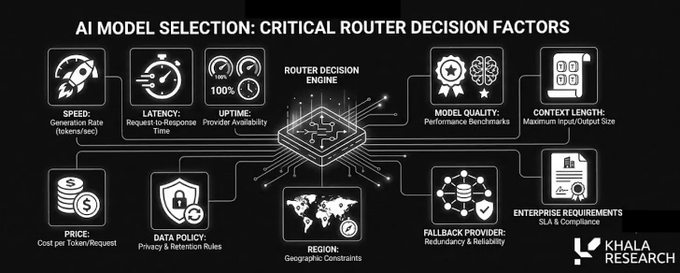
</p
Router dapat memilih berdasarkan harga, latensi, privasi, keandalan, dan berbagai faktor lainnya.
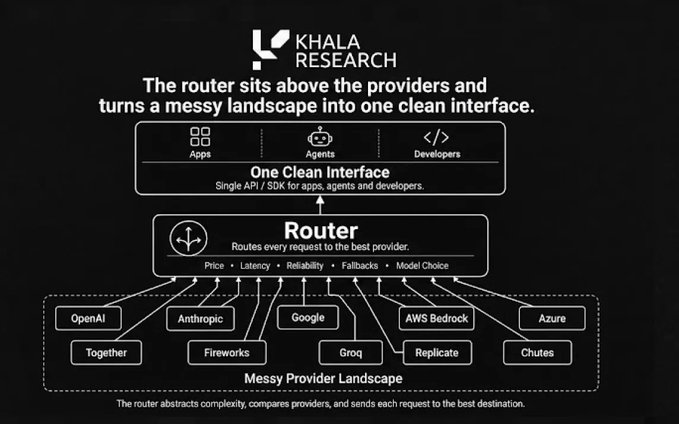
Router berada di atas semua penyedia, mengubah lanskap yang berantakan menjadi antarmuka yang bersih dan seragam.
Inilah yang dilakukan OpenRouter dengan benar, dan menjelaskan mengapa dana modal ventura menginvestasikan $113 juta dalam pendanaan Seri B baru-baru ini, untuk menangkap peluang routing ini.
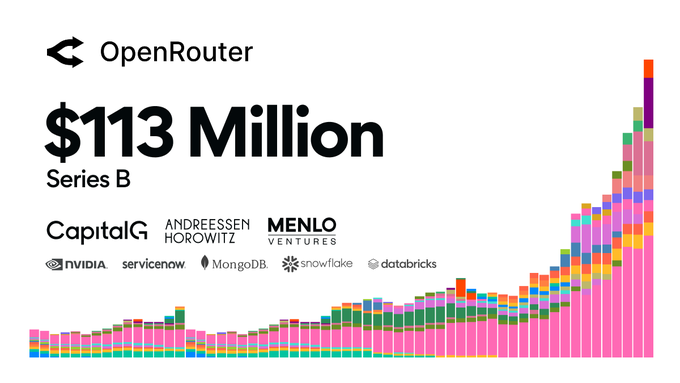
OpenRouter dengan cepat menjadi antarmuka pasar: satu kunci untuk mengakses ratusan model di berbagai penyedia. Nilai sebenarnya bukan pada daftar model, tetapi pada fakta bahwa permintaan yang sama dapat diarahkan ke penyedia yang paling cocok untuk tugas tersebut.
Ini mulai menyerupai pasar energi: pengguna tidak peduli dari pembangkit listrik mana listrik dihasilkan, mereka hanya peduli apakah lampu menyala, harganya wajar, dan sistemnya stabil.
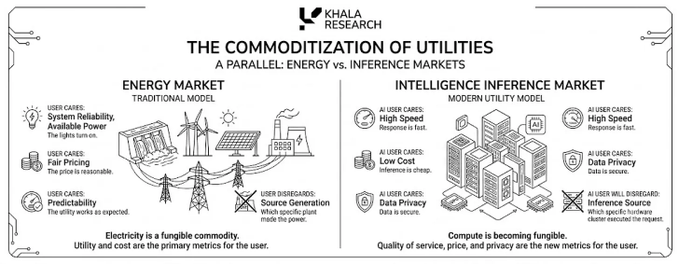
Pengguna AI juga akan semakin berpikir seperti ini — mereka tidak peduli kluster GPU mana yang melayani token ini, mereka hanya peduli apakah responsnya cepat, murah, pribadi, dan andal.
Penyedia Inferensi Tradisional

Sisi tradisional terpecah menjadi empat kategori:
i) Penyedia Cloud Hyperscaler: AWS, Google, Microsoft
Mereka menguasai 'benua yang dibentengi'. Mereka menang bukan karena selalu paling murah, tetapi karena mereka sudah lama mengendalikan pengadaan perusahaan, kepatuhan, identitas, keamanan, dan sistem penagihan. Menyerang posisi ini secara frontal sangat mahal.
Mereka menang melalui kepercayaan perusahaan. Perusahaan besar tidak hanya membeli token, tetapi juga kepatuhan, keamanan, kemudahan pengadaan, dan seseorang yang bertanggung jawab jika terjadi masalah.
ii) Pasar Routing: OpenRouter dan Berbagai Gerbang AI
Router berada di atas penyedia model, mengirimkan setiap permintaan ke opsi terbaik. Seiring dengan berubahnya kepemimpinan model setiap minggu, meng-hardcode model tunggal menjadi semakin rapuh. AI membutuhkan agregator, seperti di dunia kripto.
iii) Layanan Model Open Source yang Dioptimalkan: Together, Fireworks, Baseten, Groq
Mereka bukan sekadar API murah, tetapi perusahaan infrastruktur kinerja yang berfokus pada kecepatan, batch processing, skalabilitas, fine-tuning, endpoint kustom, dan dukungan produksi.
iv) Pasar Model: Replicate dan Platform Serupa Hugging Face
Inferensi jauh lebih dari sekadar obrolan. Gambar, video, suara, embeddings, model robot, simulasi, dan agen multimodal semuanya membutuhkan model untuk dijalankan. Pasar membuat kebutuhan model ekor panjang menjadi mudah diakses.
Penyedia Inferensi AI Kripto
Jaringan Terdesentralisasi adalah 'Wilayah Gerilya'
Jaringan inferensi kripto tidak berusaha menghabiskan lebih banyak uang di medan tempur utama AWS. Mereka membuka front baru: model tanpa sensor, penawaran GPU yang lebih murah, inferensi pribadi, pembayaran native untuk agen, dan beban kerja yang tidak memerlukan tingkat keandalan penyedia cloud hyperscaler.
Sisi kripto sering disederhanakan sebagai 'daya komputasi terdesentralisasi', ungkapan ini terlalu kabur, setidaknya ada lima arah berbeda:
- Jaringan inferensi tanpa server
- Pasar GPU terdesentralisasi
- Jaringan komputasi rahasia
- Aplikasi dan Gerbang AI Privat
- Lapisan orkestrasi
Mereka tidak boleh dianalisis secara setara.
i) Chutes: Inferensi Native Kripto
@chutes_ai paling baik dipahami sebagai platform inferensi terdesentralisasi, bukan sekadar pasar GPU.
Intinya adalah: Pengembang tidak ingin menyewa GPU atau mengelola infrastruktur, mereka menginginkan endpoint yang berfungsi. Chutes menyajikan model open source melalui API yang familiar, menggunakan penawaran GPU terdesentralisasi di lapisan bawah.
Pertanyaan kunci adalah apakah mereka dapat mengubah penggunaan puncak menjadi permintaan berbayar dan berulang. Token murah berguna, tetapi hanya jika pengembang mempercayai waktu aktif, latensi, dan keandalannya.
Pendapatan per triliun token mereka terus meningkat, menunjukkan potensi profitabilitas/kelayakan berkelanjutan.
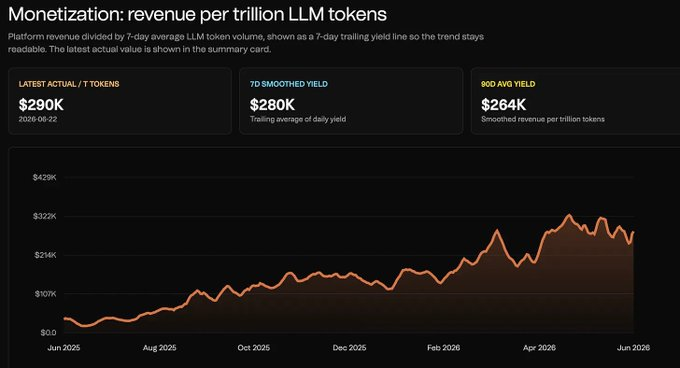
ii) Akash: Lapisan Lelang GPU
@akashnet adalah pasar cloud terdesentralisasi.
Pengguna mendefinisikan daya komputasi yang dibutuhkan, penyedia menawar untuk menyediakannya, beban kerja dijalankan melalui sewa. Ini lebih mirip pasar daya komputasi, bukan router inferensi langsung.
Ini paling cocok untuk beban kerja yang sensitif terhadap harga, dapat mentolerir fluktuasi infrastruktur, dan tidak memerlukan integrasi mendalam AWS/Azure/Google Cloud. Biayanya berkorelasi dengan harga token dan menunjukkan tren naik.
iii) io.net: Cloud GPU Terdesentralisasi
@ionet lebih mendekati penyedia cloud GPU terdesentralisasi.
Nilai jual intinya adalah akses ke penawaran GPU terdistribusi dengan biaya lebih rendah dan kecepatan penyiapan yang lebih cepat, cocok untuk tim AI yang membutuhkan daya komputasi tetapi tidak ingin menandatangani kontrak cloud jangka panjang atau menerima penetapan harga hyperscaler.
Tantangannya terletak pada eksekusi: verifikasi perangkat keras, keandalan, penjadwalan, dukungan, dan kinerja yang konsisten. Akses GPU mentah berharga, tetapi lapisan laba yang lebih tinggi masih berupa routing, pengelolaan inferensi, dan orkestrasi.
io.net menonjol dalam 30 hari terakhir, dengan pendapatan tahunan mencapai $12,3 juta.
iv) Targon: Komputasi Rahasia
@TargonCompute (dibuat oleh @manifoldlabs) berfokus pada komputasi rahasia untuk beban kerja AI.
Masalah yang dipecahkannya jelas: Banyak pengguna tidak ingin menjalankan perintah sensitif, model, atau data pada infrastruktur yang dioperasikan oleh pihak ketiga yang tidak dikenal.
Targon menyediakan eksekusi yang dilindungi melalui Trusted Execution Environment, mesin virtual terenkripsi, remote attestation, dan infrastruktur GPU rahasia. Singkatnya, membuktikan bahwa beban kerja berjalan di lingkungan aman, dan mengurangi apa yang dapat dilihat operator.
Ini sangat relevan untuk inferensi pribadi di bidang seperti keuangan, kesehatan, dan AI perusahaan. Komputasi rahasia bukanlah sihir, ia memindahkan kepercayaan ke perangkat keras, firmware, dan sistem attestation.
Tahun lalu, protokol ini melaporkan pendapatan tahunan $10,4 juta, dan bersama Intel menulis makalah penelitian tentang 'Daya Komputasi Terdesentralisasi pada Perangkat Keras yang Tidak Terpercaya'.

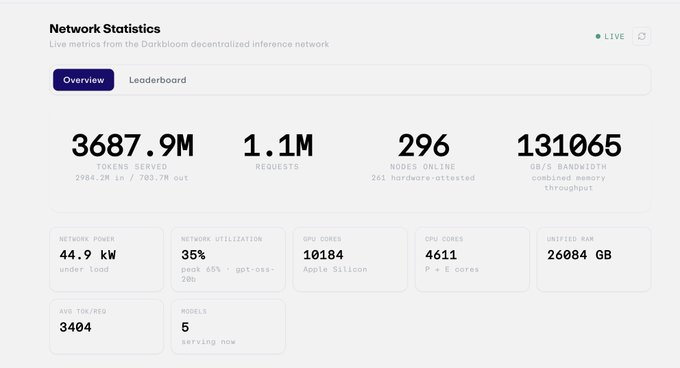
v) Darkbloom: Inferensi Privat di Mac yang Menganggur
Darkbloom (dibuat oleh @eigenlabs) mengambil jalur yang berbeda.
Alih-alih membagi-bagi model besar ke GPU acak, ini mengubah Mac Apple Silicon yang menganggur menjadi jaringan inferensi pribadi. Model berjalan secara lokal di Mac, permintaan dienkripsi dan dirutekan ke penyedia yang diverifikasi.
Nilai jualnya adalah privasi dan biaya, bukan memaksimalkan kinerja model garis depan.
Ini berguna karena 'tidak ada node yang menyimpan model lengkap' tidak secara otomatis berarti perintahnya bersifat pribadi. Darkbloom lebih eksplisit menargetkan masalah privasi, tetapi masih perlu membuktikan skala penawaran, kinerja, dan kepercayaan pengembang.
Saat ini jaringan sudah memiliki 300 mesin, telah melayani 2 miliar token dan 1 juta permintaan.
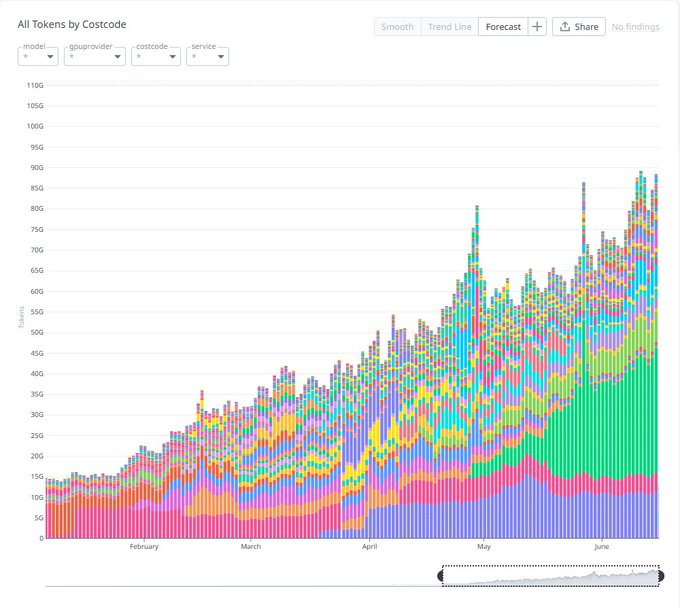
vi) Venice: Inferensi Privat untuk Konsumen
@AskVenice berada di posisi yang berbeda dari jaringan seperti Akash atau io.net. Ini lebih mirip aplikasi AI pribadi dan gerbang inferensi, bukan pasar GPU utama.
Throughput gerbangnya telah mencapai 85 miliar token per hari (data @ErikVoorhees).
Kebanyakan pengguna menginginkan produk AI yang menghormati privasi, dapat mengakses model yang kuat, dan tidak mengumpulkan banyak data.
Venice membungkus ide infrastruktur menjadi pengalaman untuk konsumen, berputar di sekitar perintah pribadi, model open source, akses tanpa sensor, fungsionalitas API, dan daya komputasi tokenisasi melalui VVV dan DIEM.
Komponen DIEM sangat menarik, ini mengarah pada konsep ekonomi agen yang lebih luas: memberikan akses daya komputasi seharga $1 per hari. Pasar baru-baru ini telah memberikan label harga yang bagus untuk konsep ini.
Jika agen membutuhkan akses inferensi yang berkelanjutan, maka kredit daya komputasi mulai menyerupai aset native untuk agen, dan seluruh pasar sekunder dapat dibangun di sekitarnya.
Agen yang dapat secara langsung memegang dan membelanjakan hak daya komputasi lebih praktis daripada agen yang bergantung pada manusia untuk secara berkala menggesek kartu kredit.
Ini menyoroti argumen AI kripto yang lebih dalam: Agen pada akhirnya membutuhkan akses ke dana, identitas, memori, dan daya komputasi, dan sistem kripto menyediakan kerangka kerja untuk memprogram sumber daya ini.
Venice tidak langsung bersaing dengan OpenRouter dalam keluasan model, melainkan bersaing dalam privasi, akses, dan daya komputasi tokenisasi. Ini adalah ceruk yang legitimate, tetapi pertanyaan kuncinya adalah apakah permintaan untuk produk AI pribadi akan cukup besar untuk mendukung model token melampaui siklus naratif saat ini. Penilaian saya adalah, seiring dengan meluasnya AI, narasi privasi hanya akan semakin kuat.
vii) NuNet: Orkestrasi Daya Komputasi Terdistribusi
@nunet_global sering dikategorikan sebagai proyek daya komputasi terdesentralisasi, tetapi kerangka kerja yang lebih berguna adalah 'orkestrasi'.
Orkestrasi mencakup pencocokan beban kerja dengan sumber daya daya komputasi yang paling sesuai, dan mengoordinasikan eksekusi di berbagai mesin, lingkungan, dan lokasi.
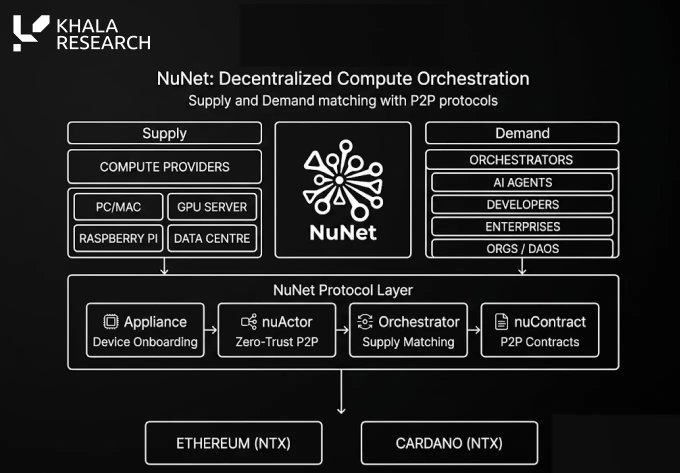
Hal ini menjadi semakin penting seiring dengan perkembangan AI melampaui infrastruktur cloud terpusat.
Sistem AI di masa depan kemungkinan besar akan berjalan melintasi GPU cloud, perangkat edge, server lokal, robot, ponsel, sensor, dan jaringan penyedia terdesentralisasi.
Robot gudang mungkin tidak bisa menunggu respons API lintas wilayah; drone tidak dapat berasumsi koneksi sempurna setiap saat; robot di lapangan perlu melakukan inferensi lokal saat jaringan tidak dapat diandalkan.
Karena itu, orkestrasi menjadi kategori yang mandiri dan bermakna.
Tantangan NuNet adalah apakah mereka dapat mengubah masalah koordinasi ini menjadi jaringan ekonomi fungsional dengan penawaran, permintaan, dan adopsi pengembang yang cukup.
viii) OpenServ: Orkestrasi Agen, Bukan Inferensi Murni
@openservai paling baik dipahami sebagai platform infrastruktur agen dan orkestrasi, bukan jaringan inferensi terdesentralisasi.
Ini penting karena agen adalah salah satu sumber permintaan inferensi yang paling jelas di masa depan. Chatbot biasa mungkin hanya memanggil model sekali, sedangkan agen akan memanggil model berulang kali: inferensi, menggunakan alat, memeriksa output, memanggil model lain, mengambil tindakan, lalu mengulangi.
Ini menciptakan permintaan inferensi yang berat, yang telah menarik perhatian di dalam lingkaran kripto.
Karena itu, OpenServ terkait dengan pasar inferensi dari sisi permintaan, bukan sisi penawaran. Jika platform ini dapat menjadi tempat yang berguna bagi pengembang untuk membangun, menerapkan, dan mengoordinasikan agen, secara alami platform ini akan menjadi lapisan yang merutekan inferensi ke berbagai penyedia di lapisan bawah.
Pertanyaan kuncinya adalah apakah OpenServ dapat menjadi lapisan eksekusi agen yang sebenarnya, atau hanya pasar agen lain dengan token terlampir.
Setelah beberapa kali berbicara dengan tim, saya percaya kemampuannya tidak hanya sebatas yang terakhir, framework inferensinya memiliki sejumlah performa benchmark yang signifikan, dan ada model kepemilikan eksklusifnya sendiri di peta jalan.
Jika OpenServ dapat menguasai alur kerja operasional yang diagenkan, inferensi menjadi input untuk platform, bukan produk utama.
Dalam dunia yang diagenkan, lapisan yang paling berharga adalah tempat agen menghabiskan banyak waktu dan sumber daya yang berkelanjutan.
ix) Dolphin AI: Inferensi Terdesentralisasi yang Digerakkan oleh Produk
Yang menarik dari @dphnAI adalah bahwa ia memulai dari permintaan model, bukan dari pasar GPU.
Keluarga model Dolphin telah memiliki reputasi untuk model open source tanpa sensor, memberikan alasan keberadaan yang lebih jelas bagi jaringan.
Ini penting karena banyak proyek inferensi terdesentralisasi dimulai dari sisi penawaran: 'Kami punya GPU, sekarang siapa yang mau membeli?'
Dolphin sebaliknya: mulai dari kumpulan model yang sudah ingin digunakan orang, lalu membangun jaringan inferensi terdesentralisasi di sekitar permintaan tersebut.
Arsitekturnya sering disebut peer-to-pool: Pemilik GPU menyumbangkan kapasitasnya ke pool model tertentu, alih-alih setiap pembeli langsung menyewa node tertentu. Permintaan dirutekan ke dalam pool, node yang tersedia memprosesnya.
Ini adalah desain yang lebih baik untuk penawaran konsumen yang tidak dapat diandalkan. Jika seseorang menyumbangkan GPU gaming yang menganggur, mereka mungkin tidak selalu tetap online, pool model dapat menyerap fluktuasi ini lebih alami daripada pasar sewa satu lawan satu.
Yang lebih menarik adalah verifikasi. Dolphin sedang mendorong pembuktian bobot real-time (live-weight proofs). Singkatnya, memeriksa apakah bobot model yang dimuat saat layanan sesuai dengan model yang diklaim dijalankan oleh node.
Ini penting karena kecurangan adalah salah satu masalah tersulit dalam inferensi terdesentralisasi. Node mungkin mengklaim menjalankan model mahal, tetapi diam-diam melayani model yang lebih kecil, lebih murah, atau versi terkuantisasi. Jika jaringan tidak dapat mendeteksi, seluruh pasar akan kehilangan kredibilitas.
x) c0mpute: Inferensi Terdistribusi untuk Agen
@c0mputeAI perlu diperhatikan karena mencoba memecahkan salah satu masalah tersulit dalam inferensi terdesentralisasi: menjalankan model besar di GPU yang tersebar di internet terbuka.
Mesin Shard-nya membagi model ke beberapa mesin, alih-alih meminta satu server raksasa menampung model lengkap. Ini sangat relevan untuk model open source skala garis depan yang mungkin terlalu besar atau terbatas untuk dijalankan melalui rute hosting konvensional.
Tautan @virtuals_io adalah sudut pandang sisi permintaan yang kunci. Virtuals sedang membangun ekonomi agen, dan agen adalah pengguna inferensi berat: mereka merencanakan, memanggil alat, bertransaksi, memeriksa hasil, dan mengulangi. Ini menciptakan permintaan inferensi yang murah, terbuka, dan tahan sensor.
Caveat-nya adalah ini masih dalam tahap awal. c0mpute perlu membuktikan kinerja di bawah beban nyata, keandalan node, verifikasi, dan privasi perintah.
Tapi arahnya penting: Pasar GPU menjual akses daya komputasi; c0mpute sedang mencoba mendistribusikan model itu sendiri.
Inferensi Tradisional vs Inferensi Kripto
Keduanya akan hidup berdampingan, masing-masing dengan keunggulan unik yang jelas dan layak dipahami.

Apa yang Perlu Diperhatikan
Jumlah Token Berbayar
Pasar harus mengurangi perhatian pada statistik pemrosesan token mentah, kecuali token-token ini menghasilkan pendapatan. Aktivitas di lapisan gratis dan penggunaan bersubsidi dapat menghasilkan angka yang mencolok, tetapi tidak dapat membuktikan kecocokan pasar produk yang sebenarnya.
Permintaan inferensi berbayar adalah metrik kuncinya — itu lebih berkelanjutan dan dapat mendukung kelangsungan jangka panjang.
ii) Pendapatan per GPU
Jaringan daya komputasi terdesentralisasi hanya berkelanjutan jika GPU menghasilkan nilai lebih tinggi di dalam jaringan daripada di luar. Jika emisi adalah alasan utama penyedia berpartisipasi, begitu insentif turun, penawaran akan menghilang. Penyedia GPU akan menghitung biaya peluang.
iii) Integrasi Router: Distribusi
Distribusi seringkali lebih penting daripada infrastruktur itu sendiri.
Integrasi OpenRouter, pengkodean agen, dompet, endpoint pembayaran, alat pengembang, dan aplikasi konsumen semuanya adalah sumber permintaan potensial.
Endpoint pembayaran adalah saluran di mana perangkat lunak dapat membayar layanan secara langsung melalui API.
iv) Verifikasi
Penipuan GPU, kapasitas palsu, dan penyedia yang tidak dapat diandalkan masih merupakan risiko nyata.
Jaringan memerlukan verifikasi perangkat keras yang kuat, lalu lintas terenkripsi, sistem reputasi, dan hukuman yang berarti untuk perilaku buruk.
v) Jaminan Privasi
Inferensi pribadi masih merupakan salah satu peluang AI kripto terkuat, tetapi jaminannya harus nyata. Memasarkan privasi itu mudah; eksekusi yang aman, arsitektur lokal-first, minimalisasi data, dan infrastruktur yang dapat diaudit jauh lebih sulit.
vi) Penangkapan Nilai Token
Model token terkuat akan langsung menghubungkan permintaan dengan penggunaan inferensi nyata. Ini mungkin melibatkan pembelian kembali, penghancuran, persyaratan penaruhan, hak daya komputasi, atau mekanisme yang terkait dengan pendapatan.
Hanya bergantung pada narasi AI yang luas kemungkinan tidak cukup dalam jangka panjang.
Kesimpulan Inti
Akhir Permainan adalah Kontrol Permintaan
Dalam permainan 'Risk', hanya memiliki wilayah yang tercerai-berai tidak cukup. Anda membutuhkan wilayah yang terhubung, rute bantuan, dan jalur pasokan yang bertahan lama.
Demikian juga di pasar inferensi. Pemenang akan mengendalikan permintaan, routing, verifikasi, dan penyelesaian; hanya memiliki GPU itu sendiri tidak cukup.
Pasar inferensi membuat AI mulai menyerupai sistem keuangan:
- Setiap token yang dihasilkan membawa biaya,
- Setiap endpoint membawa keuntungan,
- Setiap siklus agen menciptakan permintaan,
- Setiap router seperti pembuat pasar,
- Setiap jaringan GPU menjadi sumber penawaran...
Penyedia tradisional saat ini mendominasi lapisan pengalaman pengembang dan kepercayaan perusahaan.
Jaringan AI kripto sedang menjelajahi frontier lainnya: penawaran tanpa izin, inferensi pribadi, daya komputasi yang dapat diverifikasi, akses tokenisasi, dan pembayaran native untuk agen (tanpa batasan KYC).
Dalam jangka pendek, pemenangnya kemungkinan besar bukan jaringan yang paling terdesentralisasi, melainkan lebih mungkin jaringan yang membuat inferensi terdesentralisasi terasa biasa dan andal — melalui endpoint cepat, dokumentasi yang kuat, waktu aktif yang andal, penetapan harga yang transparan, penawaran terverifikasi, dan permintaan berbayar yang nyata.
Chutes tetap menjadi salah satu proyek yang perlu diperhatikan, karena yang paling mendekati mengubah daya komputasi yang didukung Bittensor menjadi pasar inferensi yang fungsional, bukan sekadar narasi GPU. Begitu juga 'Darkbloom' dari Eigen Labs.
Akash dan io.net mewakili penantang sisi penawaran, Targon mewakili argumen komputasi rahasia, Venice mewakili lapisan permintaan AI pribadi, NuNet mewakili orkestrasi untuk masa depan daya komputasi yang lebih terdistribusi.
Argumen yang lebih luas:
'Model AI mungkin semakin dikomoditisasi, tetapi pasar inferensi kecil kemungkinan mengikuti jalur yang sama.'
Nilai terbesar akan menjadi milik entitas yang merutekan pekerjaan, memverifikasi pekerjaan, menyelesaikan pekerjaan, dan menangkap permintaan.
Di sinilah peluang AI kripto berikutnya kemungkinan akan muncul... setidaknya sampai AI fisik mampu bekerja di masyarakat.





