DeepSeek V4 akhirnya diluncurkan. Ini adalah momen yang ditunggu hampir lima bulan. Model utama MoE 1T parameter + versi Flash 285B parameter, versi Pro lengkap 1,6T menyusul, sepenuhnya open source di GitHub, lisensi Apache 2.0, bobot dan kode deployment dirilis bersamaan.
Begitu model keluar, pasar modal memberikan tanggapan dengan tiga cara yang saling independen namun saling terkait.
Reaksi Berbeda Pasar Modal
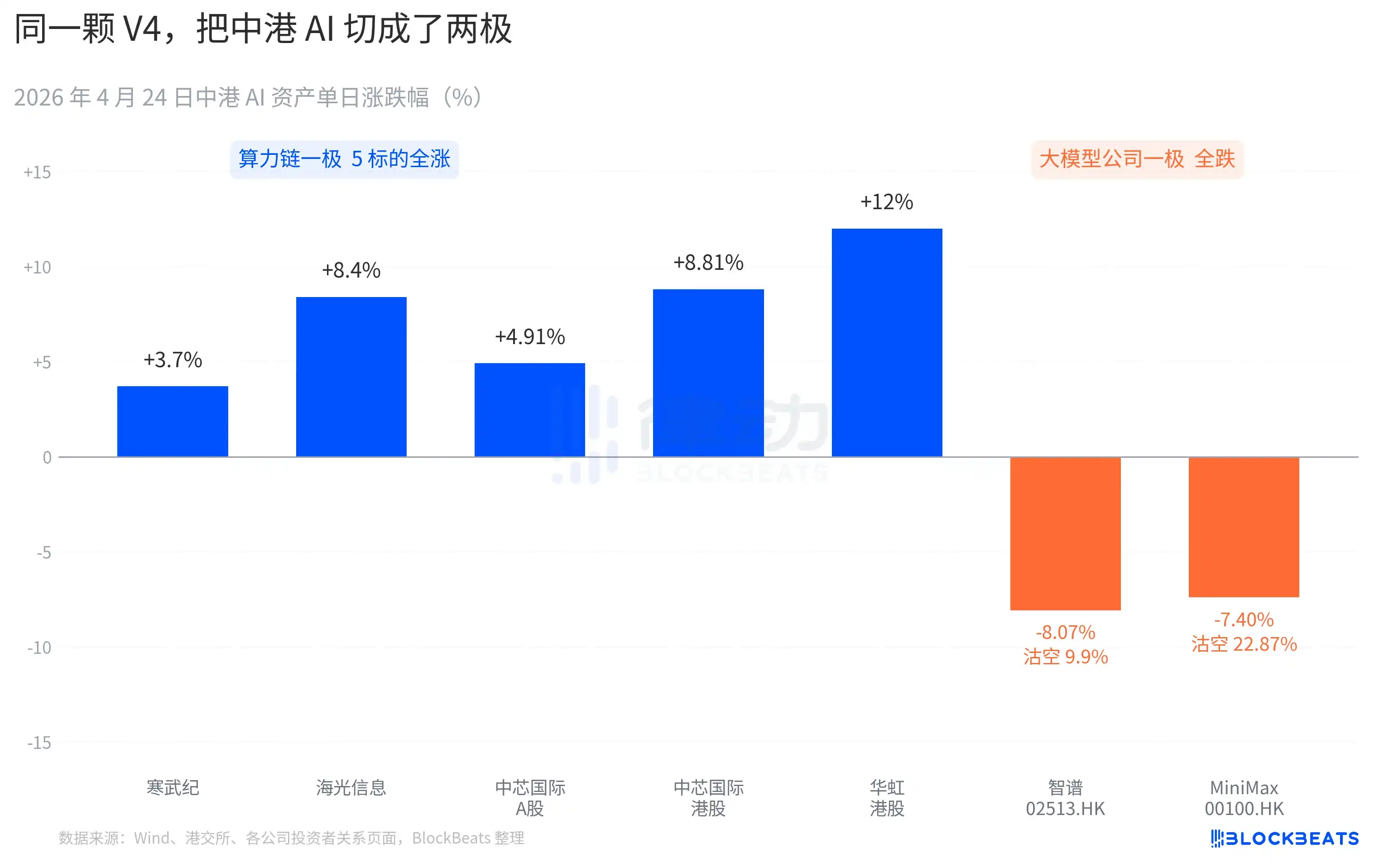
Di sisi rantai komputasi A-shares, hampir semuanya melonjak. Cambricon mengalami 11 hari hijau berturut-turut, naik 3,7% dalam sehari, kenaikan kumulatif bulanan menembus 60%. Haiguang Information menyentuh limit up 10% intraday, ditutup +8,4%. SMIC A-shares +4,91%, H-shares +8,81%. Huahong H-shares ditarik hingga +18% tertinggi, ditutup +12%. ETF Cathay Pacific S&T Chip menghimpun dana 2,4 miliar yuan dalam sehari, skala mencapai rekor tertinggi sejarah.
Di sisi perusahaan model besar H-shares, warnanya berbeda. Zhipu (02513.HK) turun 8,07%, rasio short selling 9,9%. MiniMax (00100.HK) turun 7,40%, rasio short selling melonjak ke 22,87%. Yang terakhir ini adalah data short selling tertinggi harian untuk sektor AI H-shares dalam tiga bulan terakhir. Kedua perusahaan ini adalah perwakilan dari gelombang IPO AI H-shares paruh kedua 2025, kompetensi inti yang tertulis di prospektus IPO adalah kalimat yang sama, "Model dasar besar yang dikembangkan sendiri".
Reaksi di seberang Samudra Pasifik juga konkretnya. Saham Nvidia semalam dibuka turun 1,8%, sempat turun hingga -2,6% intraday, ditutup datar sepanjang hari. Ulasan pasar Bloomberg membandingkan konsolidasi ini dengan momen V3 "DeepSeek" pada 27 Januari. Perbedaannya adalah, yang pada bulan Januari adalah panic selling, kapitalisasi pasar menguap 600 miliar dolar AS dalam sehari. Kali ini lebih seperti penilaian ulang, skalanya lebih lunak tetapi arahnya jelas. Dalam riset lembaga pembeli muncul ungkapan baru, "Permintaan inferensi China mulai terlepas dari permintaan inferensi AI Amerika Utara".
Menggabungkan ketiga papan ini bersama-sama, itulah putusan pertama yang ditulis pasar dalam 24 jam setelah V4 diluncurkan. Setelah open source menang, uang mulai memilih sisi lagi, yang bisa dinilai bukan lagi modelnya sendiri, tapi di kartu apa model itu berjalan, di rantai industri mana model itu dipasang.
11 Model Baru dalam 30 Hari, V4 Menambah Api ke Kubu Open Source
Jendela waktu rilis V4 sendiri adalah bagian dari alasan mengapa reaksi ini diperbesar.
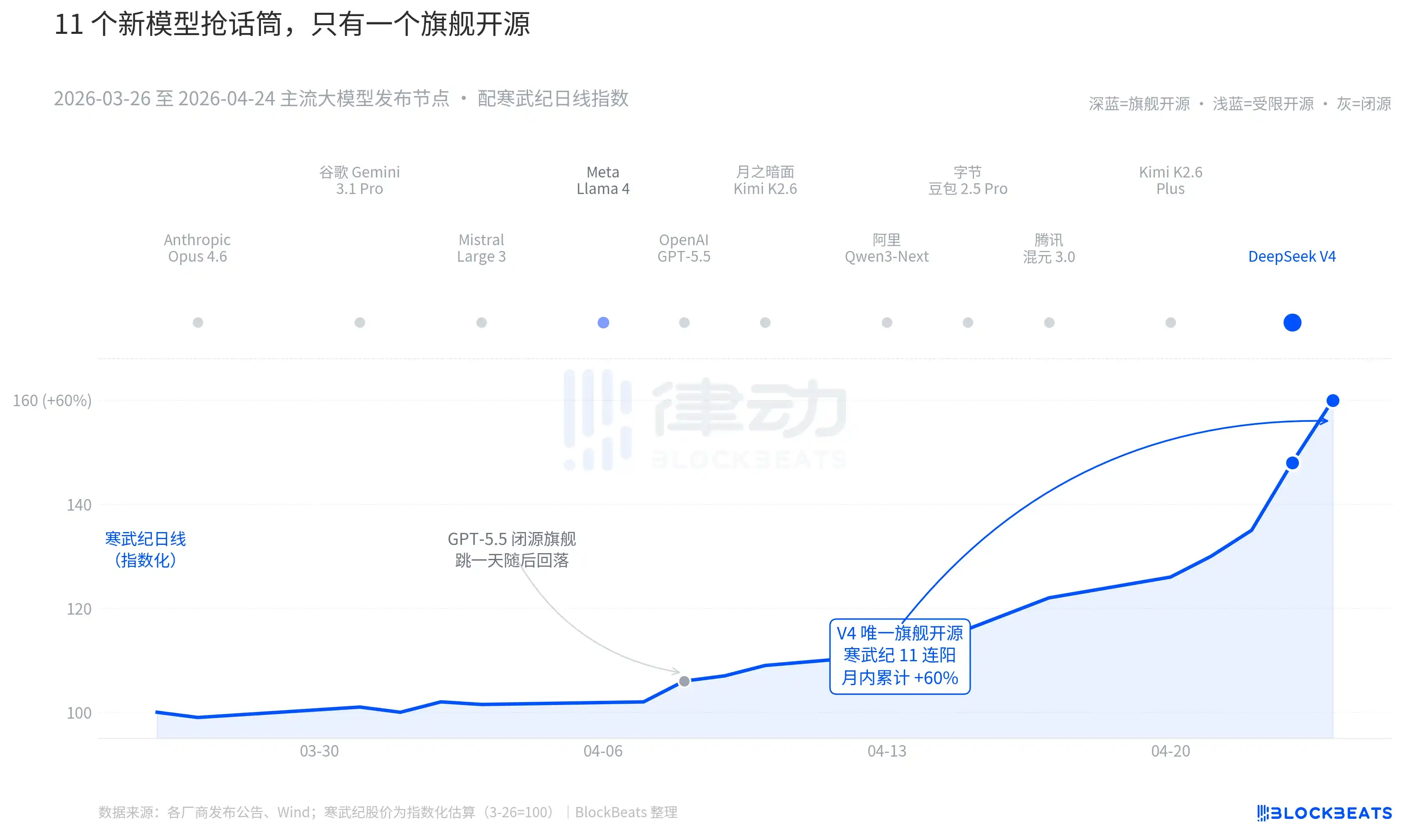
Membawa lensa ke 30 hari terakhir. Antara 26 Maret hingga 24 April, setidaknya ada 11 model besar dengan pengaruh signifikan yang dirilis atau diperbarui secara besar-besaran, daftarnya mencakup hampir semua pemain utama. Anthropic Opus 4.6, Google Gemini 3.1 Pro, OpenAI GPT-5.5, Mistral Large 3, Meta Llama 4, Moonlight Kimi K2.6, Alibaba Qwen3-Next, ByteDance Doubao 2.5 Pro, Tencent Hunyuan 3.0, Kimi K2.6 Plus, dan terakhir DeepSeek V4 yang dirilis dini hari 23 April.
Rata-rata, setiap 2,7 hari ada model baru yang keluar. Ini adalah kecepatan yang bahkan manajer fund tidak sempat membaca rilisnya. Tetapi melihat garis K aset AI China-Hong Kong selama 30 hari ini, hanya satu nama yang meninggalkan jejak berkelanjutan di papan. GPT-5.5 pada 8 April mendorong Nvidia naik 4,2% dalam sehari, puncak dalam sehari. Kemudian DeepSeek V4 pada 23-24 April, mendorong rantai komputasi China-Hong Kong mengalami kenaikan beruntun.
Perbedaannya tidak terletak pada kemampuan model itu sendiri. Kesenjangan 11 model ini di peringkat LMArena, dalam banyak kasus tidak lebih dari 50 poin, berada di pita sempit "segmen yang sama". Perbedaannya terletak pada dua hal yang bertumpukan.
Pertama adalah open source. Dari 10 model pertama, hanya Llama 4 yang open source, tetapi perjanjian bobot Llama 4 disertai dengan sejumlah klausa pembatasan komersial, komunitas pengembang Eropa-Amerika menilainya dingin, OpenRouter jatuh dari 10 besar pada hari ketiga. Protokol V4 adalah Apache 2.0, bobot tanpa门槛, tanpa batasan komersial, kode inferensi dirilis bersamaan. Ini adalah model open source unggulan pertama dalam setengah tahun terakhir yang membuat kubu closed source tertekan secara bersamaan dalam tiga dimensi: kinerja, harga, dan keterbukaan.
Kedua adalah waktu. Dalam konteks kubu closed source terus mengeluarkan jurus andalan, narasi open source sedang diperas berulang kali. Opus 4.6 mendorong SWE-Bench tugas kode ke rekor baru, GPT-5.5 menetapkan harga anchor turun 1,25 dolar AS per juta token. Apakah open source bisa mengejar closed source, perdebatan ini telah berlangsung dua tahun di Silicon Valley. V4 menggunakan model open source unggulan dengan perkiraan MAU melonjak ke 90 juta, menjeda perdebatan ini.
Menurut seorang manajer fund besar domestik dalam roadshow, "Sebelum V4 kami memberikan diskon untuk valuasi model besar open source, setelah V4 diskon ini mulai ditarik secara terbalik."
DeepSeek Mengganti Tabel Harga Rantai Pasok Komputasi
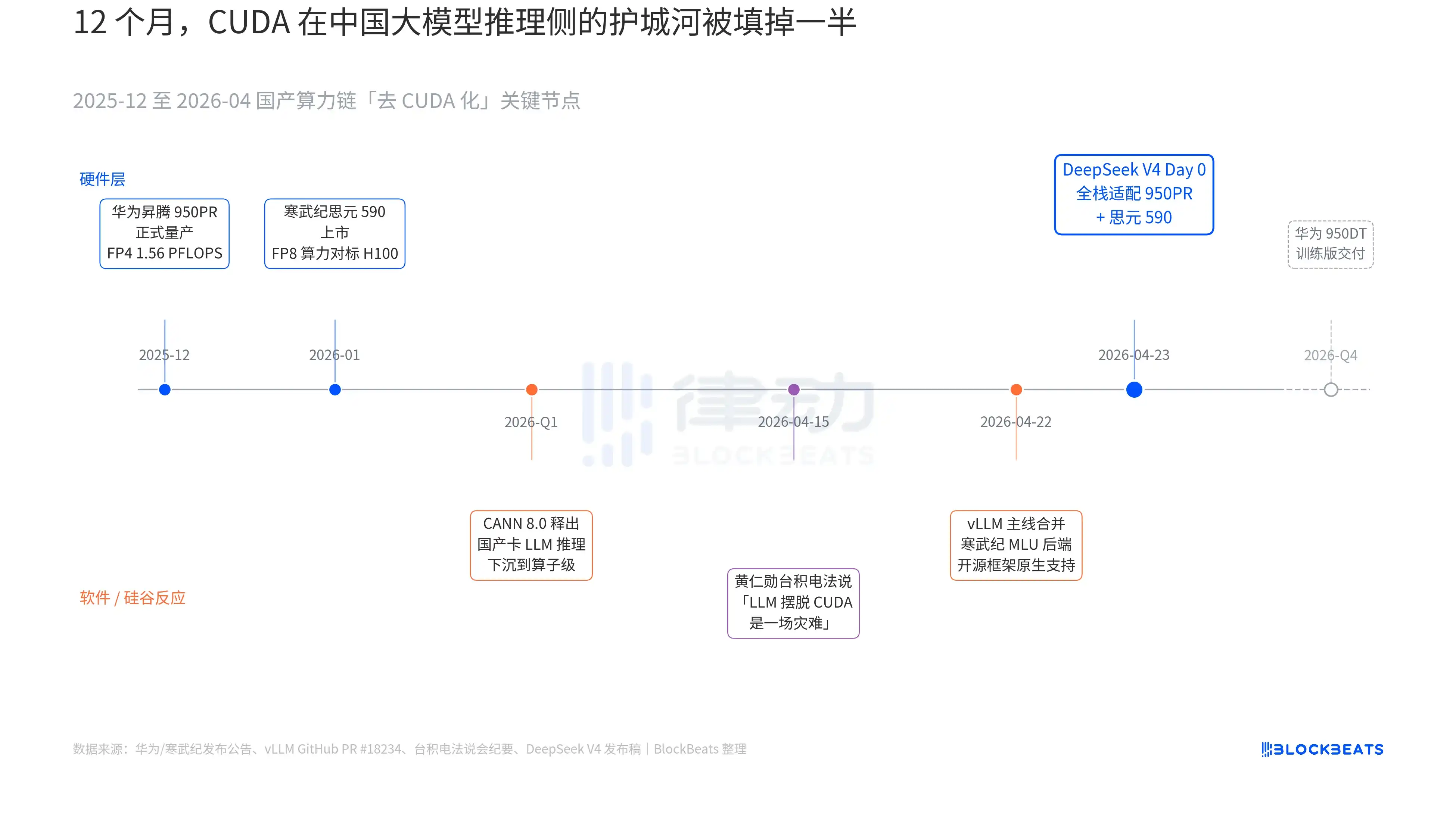
Dalam rilis V4 ada satu baris yang sebelumnya tidak pernah muncul dalam dokumen resmi model besar China mana pun: "Day 0 adaptasi full-stack untuk Cambricon Siyuan 590 dan Huawei Ascend 950PR, kode deployment dirilis open source bersamaan." Bobot baris ini baru bisa dipahami dengan menyambungkan tiga garis paralel yang berkembang dalam 12 bulan terakhir. Ketiga garis ini masing-masing milik perangkat keras, perangkat lunak, dan reaksi Silicon Valley.
Garis pertama di sisi chip. Huawei Ascend 950PR mulai diproduksi massal pada Desember 2025, komputasi FP4 1,56 PFLOPS, kapasitas HBM 112GB, ini adalah pertama kalinya chip AI domestik menyamai seri B Nvidia dalam indikator keras. Dalam tugas inferensi MoE 1T parameter seperti V4, throughput single-card meningkat 2,87 kali lipat dibandingkan H20. Software stack CANN 8.0 yang menyertainya, mengoptimalkan kerangka inferensi LLM hingga level operator, Benchmark yang dipublikasikan DeepSeek menunjukkan, latency inferensi end-to-end V4 pada super-node Ascend (8-card 950PR) 35% lebih rendah dari cluster H100 skala setara. Data Cambricon Siyuan 590 lebih agresif, komputasi FP8 single-chip setara H100, harga jual kurang dari setengah.
Garis kedua di sisi perangkat lunak. vLLM trunk pada 22 April menggabungkan PR backend MLU Cambricon, kerangka inferensi open source untuk pertama kalinya mendukung natively GPU domestik non-Nvidia. DCU Haiguang Information melalui ekosistem ROCm mengambil jalan lain, tetapi dapat menjalankan lapisan perutean MoE V4 secara utuh. Ini berarti deployment V4 bukan lagi "hanya bisa berjalan di kartu domestik tertentu", tetapi "bisa dipilih di antara beberapa kartu domestik". Ketergantungan ekosistem pada pemasok tunggal dipatahkan, ini adalah titik balik kunci production.
Garis ketiga berasal dari Silicon Valley. Pada 15 April, Huang Renxun ditanyai oleh analis tentang perkembangan komputasi domestik China dalam konferensi pers TSMC, kata-katanya dingin dan konkret, "Jika mereka benar-benar bisa membuat LLM lepas dari CUDA, itu akan menjadi bencana (a disaster) bagi kami". Sembilan hari kemudian, DeepSeek memberikan jawaban dengan pengumuman Day 0.
Empat kata "penggantian domestik" ini telah diucapkan berlebihan hingga kehilangan makna dalam tiga tahun terakhir. Tetapi setelah pagi hari 24 April, untuk pertama kalinya hal ini memiliki data konkret yang dapat dinilai oleh pasar modal. Throughput single-card, latency inferensi end-to-end, biaya inferensi, kode deployment yang dapat dikomersialkan, diam-diam mendorong perang retorika yang panjang ini ke dalam ambang production.
Logika kenaikan 11 hari hijau berturut-turut saham Cambricon tersembunyi di sini. Itu bukan lagi "saham konsep GPU domestik", tetapi "penyedia infrastruktur inferensi DeepSeek V4". Logika yang sama juga dapat menjelaskan kenaikan 12% saham Huahong H-shares, yang memproduksi proses 7nm ekuivalen untuk 950PR. Setiap token V4 yang berjalan di Ascend domestik, berarti kapasitas yang awalnya akan mengalir ke Nvidia dan TSMC, sebagian ditahan di Delta Sungai Mutiara.
Dan langkah selanjutnya早已 dipersiapkan. Dalam peta jalan Huawei, 950DT (versi pelatihan) direncanakan dikirim pada kuartal keempat 2026, target yang sesuai adalah "pelatihan full-stack model V5 atau setara pada cluster 10.000 kartu". Jika jalan ini dapat dilalui, parit pertahanan CUDA di sisi pelatihan model besar China, akan diturunkan dari "wajib" menjadi "opsional".