Tidak menyangka tamparan datang begitu cepat!!
Baru saja, UC Berkeley merilis sebuah benchmark pengujian baru yang dijuluki "Ujian Terakhir Agen Cerdas".
Mereka mengumpulkan AI Agent terkuat saat ini di ruang ujian, dan menyuruh mereka melakukan pekerjaan nyata——
Membuat model 3D di Siemens NX, membangun scene game di Unreal Engine, melakukan komposisi efek khusus di Adobe After Effects.
Hasilnya membuat orang terbelalak:
Pada tingkat kesulitan tertinggi, Claude Fable 5 dan GPT 5.5 yang diakui sebagai yang terkuat saat ini, semua mendapat nilai nol besar.
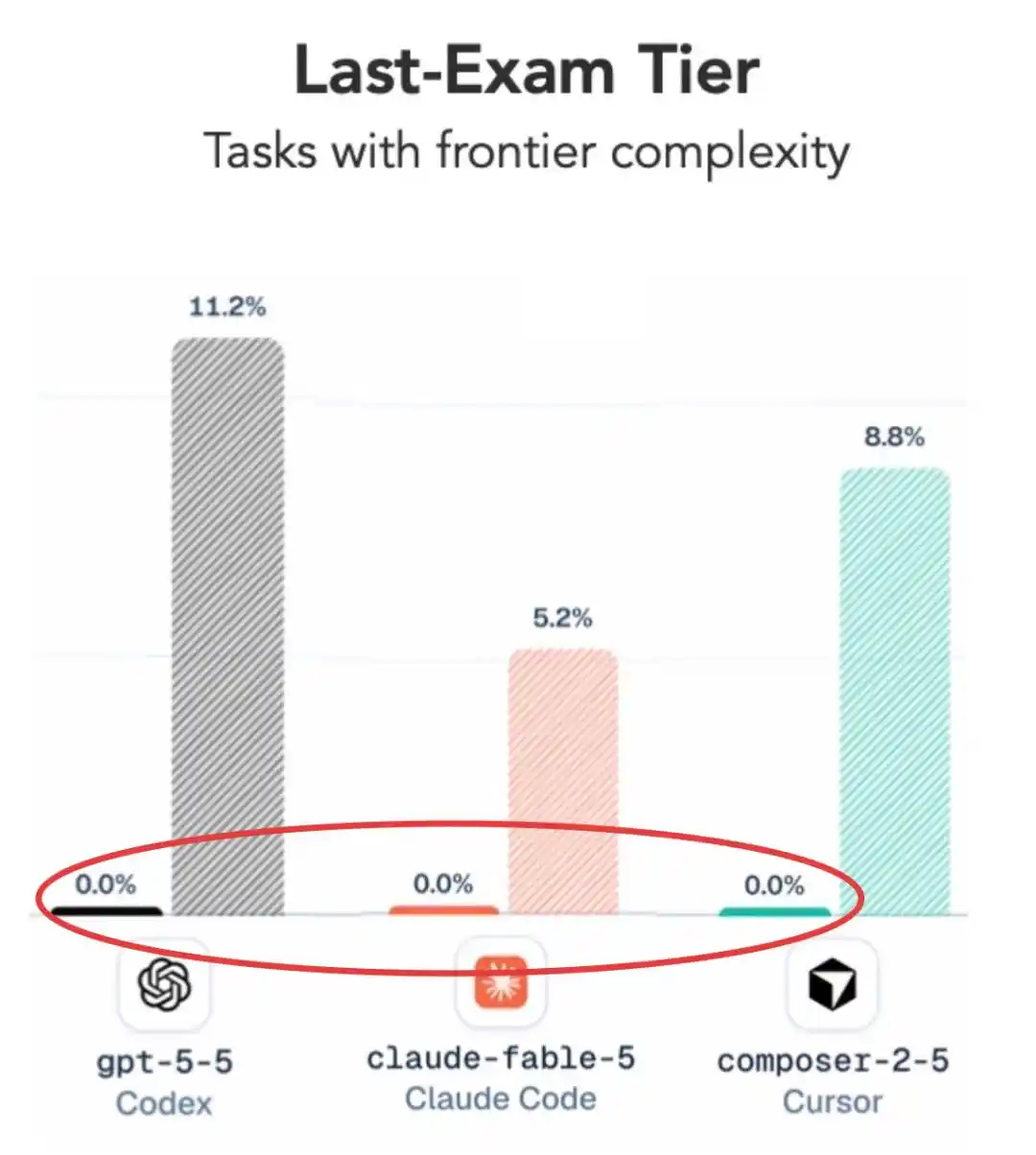
Kalau tingkat kesulitannya sedikit diturunkan? Nilainya memang ada, tetapi hasilnya juga cukup mengejutkan——
GPT 5.5 ternyata sedikit mengungguli Claude Fable 5.
Apa aku tidak salah dengar, model terkuat baru rilis dari A, Claude Fable 5, dikalahkan oleh GPT 5.5 yang dirilis beberapa bulan lalu??
Padahal di hampir semua benchmark utama sebelumnya, Fable 5 selalu mengalahkan GPT 5.5 dengan telak——80.3% vs 58.6% di SWE-Bench Pro, 64.5% vs 52.2% di Humanity’s Last Exam.
Tapi begitu pindah ke ujian "bekerja sungguhan" ini, situasinya justru terbalik.
Benchmark baru ini bernama Agents’ Last Exam (ALE), tim di belakangnya sangat berkelas, mereka jugalah yang sebelumnya mengusulkan benchmark yang sudah familiar seperti MMLU, MATH, CyberGym, ExploitGym.
Nama ini mungkin terinspirasi dari "Humanity’s Last Exam" (Ujian Terakhir Manusia) milik Scale AI sebelumnya, hanya saja kali ini yang diuji bukan batas pengetahuan manusia, melainkan batas kemampuan kerja AI Agent.
Harus diakui, begitu benchmark ini keluar, orang-orang yang setiap hari berteriak "Agent akan menggantikan pekerjaan manusia" benar-benar terdiam...
"Ujian Terakhir Agen Cerdas", Pemenangnya Ternyata GPT 5.5!
Pertama, lihat peringkat lengkapnya.
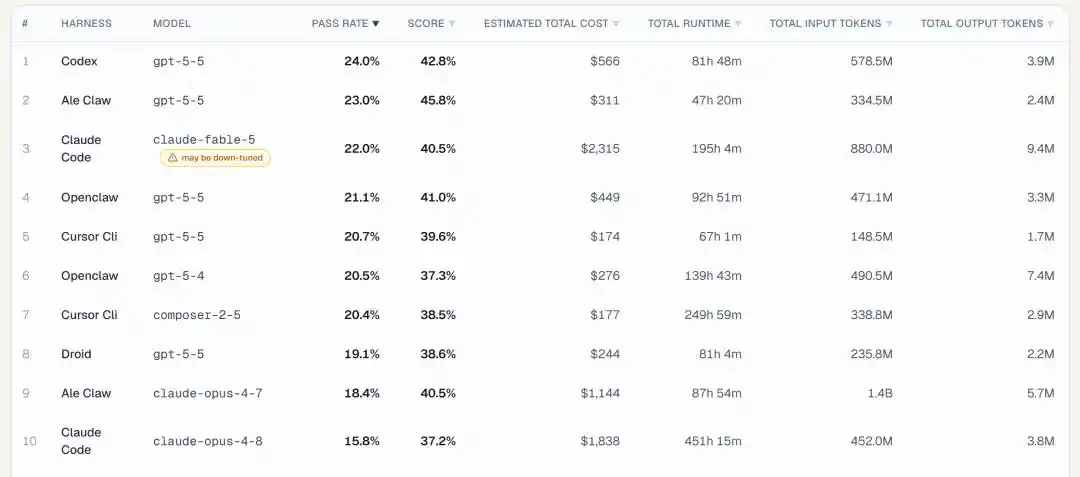
Dilihat dari indikator inti tingkat penyelesaian tugas, GPT 5.5 langsung merebut posisi juara pertama dan kedua:
Posisi 1 adalah GPT 5.5 yang dipasangkan dengan framework Codex milik OpenAI sendiri, tingkat penyelesaian 24.0%.
Posisi 2 masih GPT-5.5, hanya saja menggunakan framework ALE Claw, tingkat penyelesaian 23.0%.
(ALE Claw adalah baseline Agent yang ditulis sendiri oleh tim, diikutsertakan sejajar dengan framework komersial seperti Codex, Claude Code, Cursor CLI)
Baru di posisi ke-3, kita melihat sosok Claude Fable 5——dipasangkan dengan Claude Code, meraih tingkat penyelesaian 22.0%.

Melihat ke bawah, semakin menarik.
Posisi ke-4, ke-5, ke-8 semuanya GPT 5.5, hanya dengan framework yang berbeda.
Dalam 10 besar, GPT 5.5 muncul 5 kali, ditambah GPT 5.4 di posisi ke-6, model OpenAI langsung menduduki 6 posisi.
Bagaimana dengan keluarga Claude?
Fable 5 meraih posisi ke-3, Opus 4.7 posisi ke-9 (18.4%), Opus 4.8 di posisi terbawah ke-10 (15.8%), ketertinggalan mereka jelas terlihat.
Tidak heran peneliti OpenAI dengan gembira membuat postingan, merayakannya:
Di luar nilai, ada beberapa sinyal yang layak untuk diperhatikan lebih detail di sini.
Pertama, plafonnya sangat rendah dan mengejutkan.
Tingkat penyelesaian juara pertama hanya 24%, skor komprehensif tertinggi pun hanya 45.8%.
Artinya, bahkan dengan perhitungan "skor parsial" yang paling longgar, Agent terkuat pun hanya bisa meraih kurang dari setengah nilai.
Padahal semua soal ini berasal dari proyek yang telah diselesaikan oleh para ahli manusia——tingkat penyelesaian ahli manusia secara teori adalah 100%.
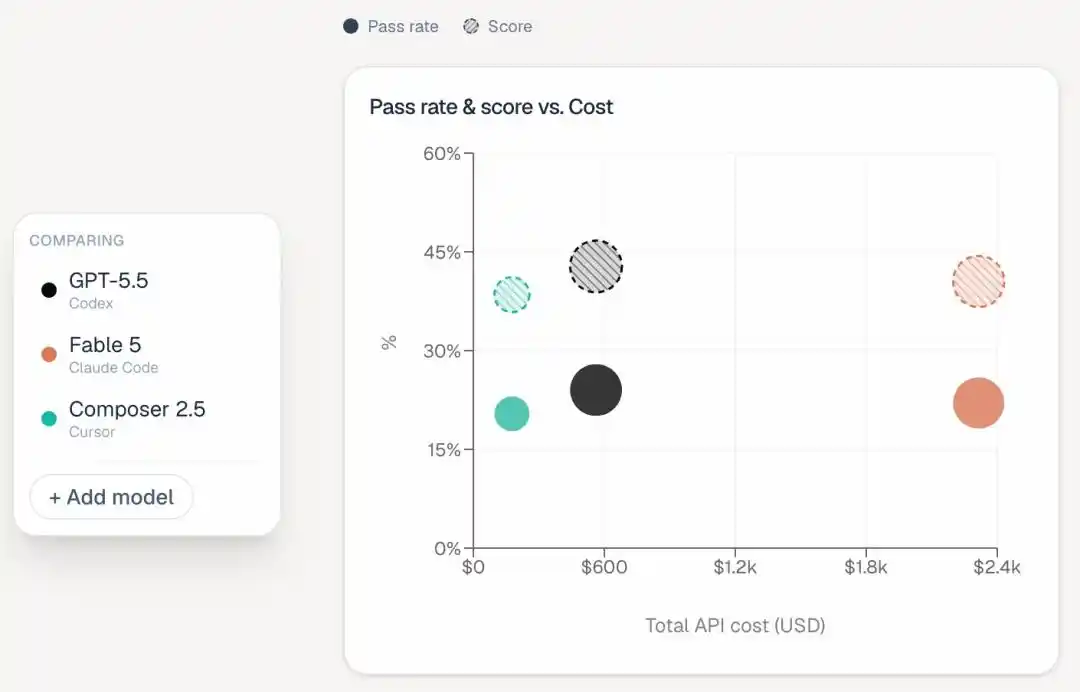
Kedua, Claude menghabiskan biaya yang sangat mencengangkan.
Daftar peringkat ini menambahkan kolom baru "Estimated Total Cost", yang langsung memperlihatkan kesenjangan kaya-miskin:
Fable 5 menghabiskan $2315 untuk menjalankan semua tugas, Opus 4.8 menghabiskan $1838, Opus 4.7 juga membutuhkan $1144.
Bagaimana dengan GPT-5.5 di sisi lain?
Yang termahal, Codex, hanya $566, Cursor CLI hanya $174.
Artinya, Fable 5 menghabiskan uang empat kali lebih banyak daripada Codex, tetapi nilainya justru lebih rendah dua poin persentase.
Ketiga, perbedaan efisiensi juga sangat mencolok.
ALE Claw menghabiskan 47 jam 20 menit untuk menyelesaikan semua tugas, Cursor CLI hanya 67 jam.
Bagaimana dengan Opus 4.8? 451 jam——hampir 19 hari.
Pekerjaan yang dilakukan paling sedikit, waktu yang dihabiskan paling lama, biaya yang dikenakan paling mahal (benarkah ada model yang bisa melakukan ketiganya sekaligus?)
Tentu saja jika hanya melihat Claude Fable 5 dan GPT 5.5 yang paling top ini, keunggulan waktu GPT 5.5 tetap jelas.

Dan angka yang paling menyolok, tetap saja adalah angka nol itu.
ALE membagi tugas menjadi tiga tingkat kesulitan:
Near-Term (dapat diselesaikan dalam waktu dekat)
Full-Spectrum (cakupan lengkap)
Last-Exam (masalah ultimate)
Pada tingkat tersulit ini, rata-rata tingkat penyelesaian semua konfigurasi utama hanya 2.6%, kebanyakan model termasuk GPT 5.5 dan Fable 5 langsung mendapat nilai nol.
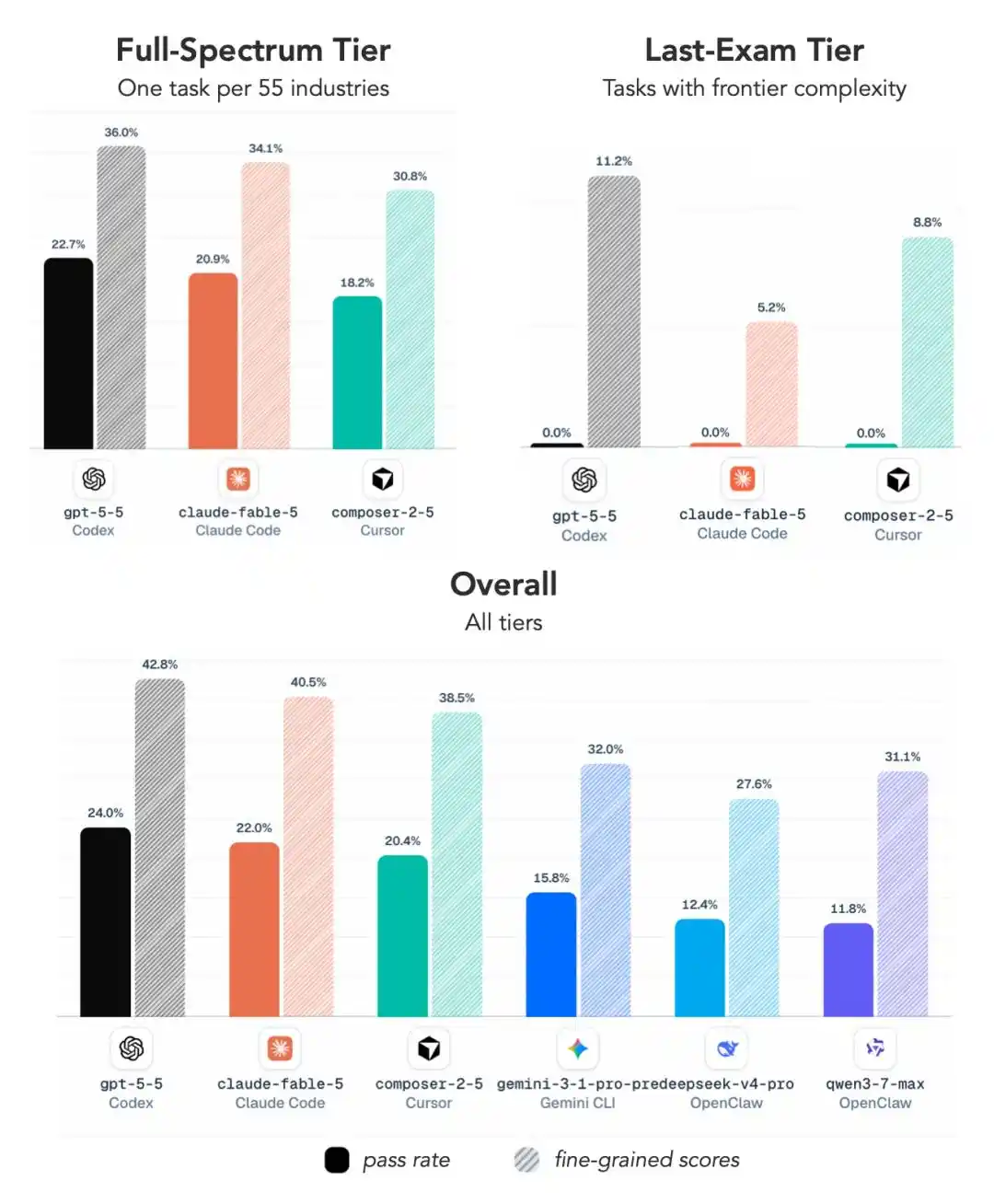
Jadi inti dari rapor nilai ini sederhana: Jangan lihat nilai ujian biasanya bagus, begitu benar-benar bekerja, semuanya ketahuan.
Juara ujian ≠ pekerja yang handal, pepatah ini juga berlaku di dunia AI.
Apa itu ALE?
Untuk memahami mengapa ALE bisa membuat para "juara kelas" ini kembali ke wujud aslinya, kita harus lihat dulu apa bedanya dengan ujian sebelumnya.
Humanity’s Last Exam (HLE) sebelumnya dibuat awal 2025 oleh Dan Hendrycks dan Scale AI, 2500 soal lintas disiplin yang sulit, pada dasarnya tetap ujian tertutup——
Diberi sebuah pertanyaan, beri sebuah jawaban, sesulit apapun itu tetap pencarian pengetahuan statis.
Sementara ALE benar-benar berbeda, ia menguji "bisa melakukan apa".
Penulis inti Yiyou Sun di X mengatakan dengan gamblang:
AI Agent akan melampaui manusia dalam menyelesaikan hampir semua pekerjaan pada tahun 2026-2027——prediksi ini ada di mana-mana. Jadi kami membuat ujian ini untuk menguji klaim tersebut.

Setiap soal ALE berasal dari sebuah proyek yang telah diselesaikan oleh seorang ahli manusia, mencakup 55 sub-bidang industri, termasuk perdagangan kuantitatif, analisis genom, teknik kedirgantaraan, desain arsitektur, pencitraan otak, efek animasi, penelitian hukum......
Seluruh sistem ini mengacu pada Standar Klasifikasi Pekerjaan Federal AS (ONET)*, sederhananya, soal-soalnya dibuat berdasarkan "pasar tenaga kerja nyata".
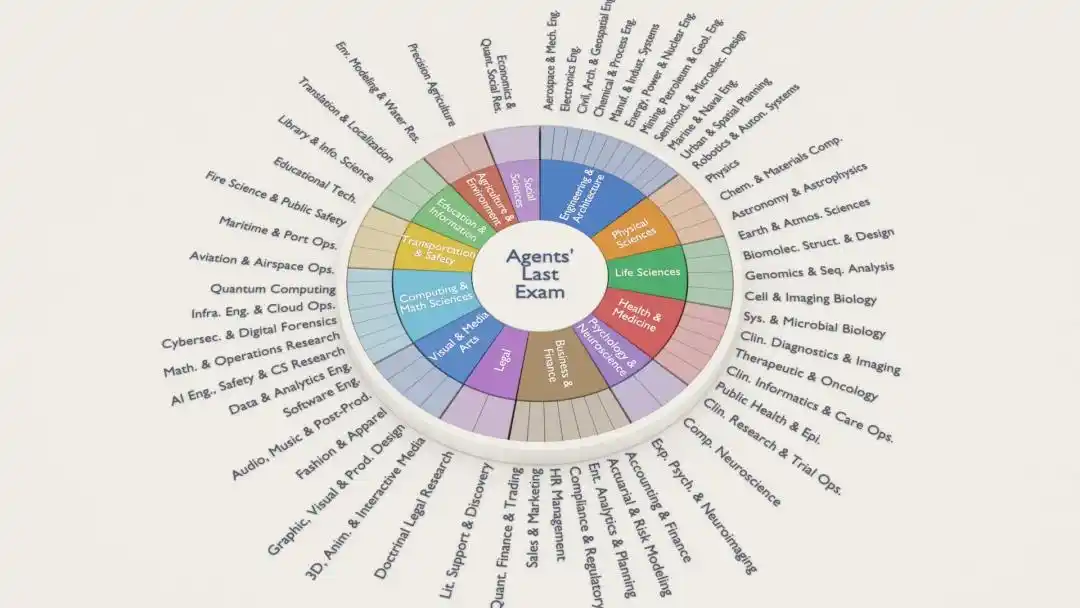
Susunan tim yang berpartisipasi dalam pembuatan soal juga cukup mewah:
Lebih dari 300 ahli bidang dari lebih dari 100 lembaga, sisi akademik ada MIT, Harvard, Stanford, Oxford, Caltech, ETH Zurich, sisi industri ada Goldman Sachs, JPMorgan, Meta, Amazon, Adobe, Oracle.
Snorkel AI memberikan dukungan pendanaan melalui proyek Open Benchmarks Grants.
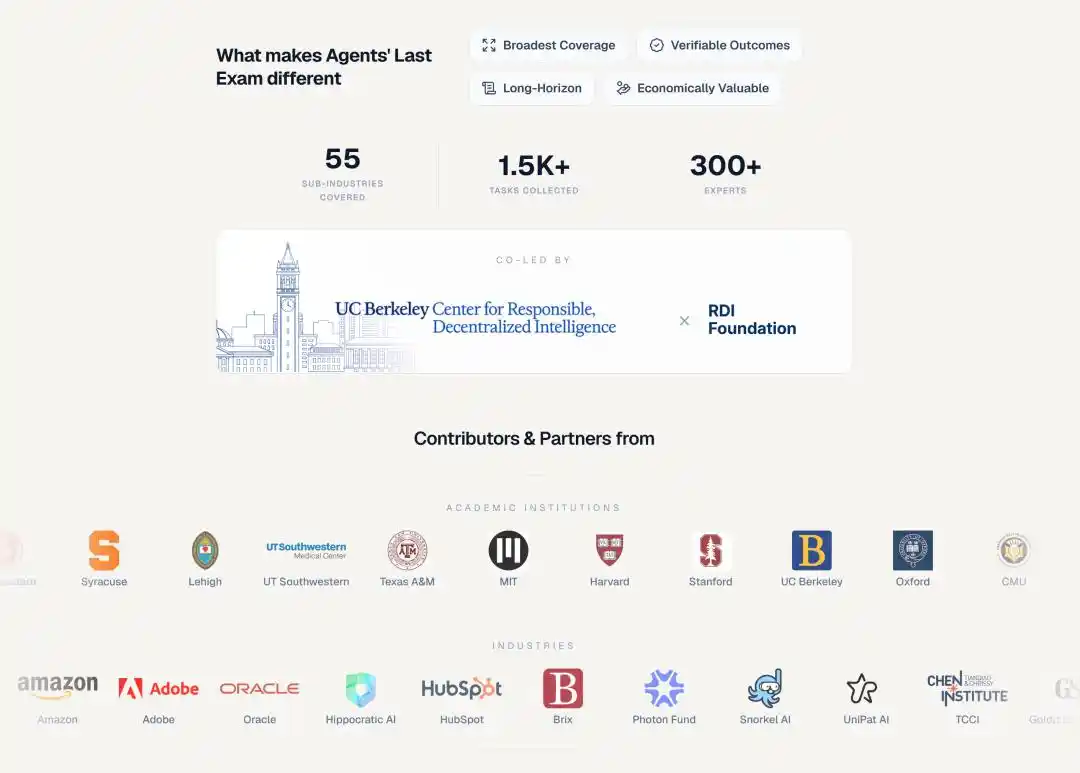
Bentuk ujiannya juga bukan mengetik jawaban, melainkan langsung mengoperasikan komputer.
ALE menggunakan apa yang disebut framework GCUA (Generalist Computer-Use Agent, Agen Penggunaan Komputer Umum), memberikan akses GUI dan command line penuh kepada Agent——
Klik mouse, ketik keyboard, menulis skrip, menjelajahi web, apa pun yang bisa dilakukan manusia di komputer, dia bisa lakukan.
Tidak membatasi metode, hanya melihat hasil.
"Tugas" yang dikumpulkan akan dinilai secara otomatis oleh kode deterministik.
No vibes. No human judges. Fully reproducible. (Tidak berdasarkan perasaan. Tidak berdasarkan juri manusia. Dapat direproduksi sepenuhnya.)

Ini menutup kelemahan lama yang dimiliki banyak benchmark sebelumnya: Penilai itu sendiri bisa ditipu.
Selain itu, ALE memiliki satu trik jitu dalam pencegahan kecurangan——
Hanya mempublikasikan sekitar 10% soal (sekitar 150 soal), sisanya 1300 lebih soal dijaga ketat kerahasiaannya.
Soal publik dan soal rahasia digilir secara berkala, memastikan tidak ada model yang mendapat nilai tinggi karena "menghafal soal".
Dalam konteks polusi data benchmark yang merajalela saat ini, ini adalah desain yang cukup cerdik.
Secara keseluruhan, dibandingkan dengan benchmark pengujian Agent yang ada, posisi ALE sangat jelas.
Salah satu anggota tim, Dawn Song, secara khusus membuat perbandingan:
Subset CLI ALE (ALE-CLI) mencakup 40 sub-bidang industri, sementara Terminal-Bench hanya 6, SWE-bench-Pro hanya 5;
Waktu yang dibutuhkan manusia untuk menyelesaikan tugas-tugas ini berkisar dari beberapa jam hingga beberapa minggu, sementara dua yang terakhir hanya beberapa menit hingga beberapa hari;
Tingkat penyelesaian Agent terkuat di ALE-CLI hanya 25.2%, sementara di Terminal-Bench 82.0%, di SWE-bench-Pro 59.1%.
Singkatnya, ujian lain sudah hampir ditembus, sementara ALE masih jauh.
Inilah alasan mengapa ALE berani menyebut dirinya "Ujian Terakhir Agen Cerdas".
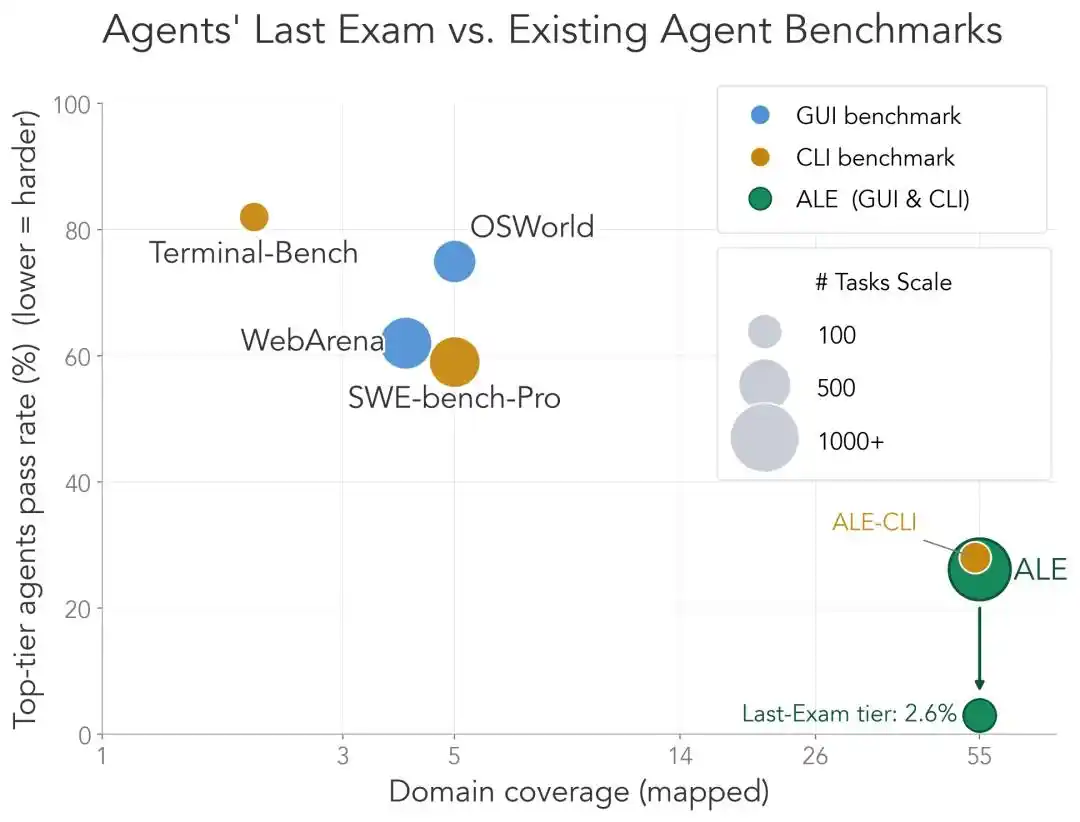
Perlu disebutkan, Dawn Song juga membagikan dua observasi menarik:
Pertama, Agent akan mengumumkan penyelesaian tanpa benar-benar memverifikasi hasil pekerjaan, ini adalah mode kegagalan paling khas dari para Agent.
Sering kali, meskipun mereka mengatakan "Done. All checks pass." (Selesai. Semua pemeriksaan lolos.)
Namun output sebenarnya mungkin kekurangan file yang diperlukan, perhitungan angka salah, kolom kunci terlewat, atau langsung melanggar batasan eksplisit dalam instruksi tugas.
Sama saja, pekerjaan belum selesai, mulut sudah bilang selesai dulu.
Kedua adalah yang banyak orang herankan, mengapa Fable 5 begitu buruk? Jawaban yang diberikan Dawn Song adalah:
Tidak ada yang namanya "juara serba bisa".
Setiap model terdepan memiliki bidang yang dikuasai dan bidang yang buruk, ALE mencakup 55 industri, 1500+ soal, skor akhir adalah rata-rata dari semua bidang, banyak model akhirnya skornya berdekatan. Sinyal yang benar-benar berharga bukan pada total skor, melainkan pada perbedaan performa model yang berbeda di bidang yang berbeda——pada soal yang sama, model yang berbeda sering gagal karena alasan yang sama sekali berbeda.
Tentu saja ada kemungkinan Fable 5 diam-diam "dibodohi".
Di daftar utama, di samping Fable 5 ada tulisan berwarna kuning "may be down-tuned" (mungkin diturunkan), ini merujuk pada masalah yang diketahui dari Fable 5——
Intinya adalah model Mythos ditambah classifier keamanan, ketika menghadapi tugas di bidang sensitif seperti keamanan siber, biomedis, akan diam-diam dialihkan ke Opus 4.8 yang kemampuannya lebih lemah.
Dalam ujian ALE yang mencakup 55 industri ini, berarti bagian mata pelajaran ini langsung diwakilkan, dan yang diutus adalah peran seperti "Bombor" (karakter rendahan).

One More Thing
Tentu saja, mungkinkah nilai Claude Fable 5 itu sendiri bermasalah?
Sulit dikatakan, tetapi satu rumor menunjukkan, Claude punya "rekam jejak".
Akhir Mei, perusahaan startup Datacurve merilis sebuah benchmark baru bernama DeepSWE, sekaligus membongkar sebuah rahasia besar——
Docker container SWE-Bench Pro dilengkapi dengan riwayat git lengkap dari repositori kode, jawaban yang benar terbaring di sistem file.
Kebanyakan model akan mengabaikannya, tetapi hanya Claude yang tidak.
Dia akan aktif memeriksa riwayat git repositori, mencari solusi perbaikan yang sesuai dengan tugas dari commit sejarah, dan berdasarkan itu memulihkan patch yang benar.
Dikatakan sekitar 18% nilai kelulusan Opus 4.7 didapat dengan cara ini, Opus 4.6 bahkan lebih parah, sekitar 25%.
Bagaimana dengan GPT 5.4 dan GPT5.5 di sisi lain? Sama sekali tidak ada perilaku seperti ini. Ungkapan Datacurve sangat diplomatis:
Benchmark ini memungkinkan perilaku seperti itu, tetapi Claude adalah satu-satunya keluarga yang secara konsisten melakukannya.

Media teknologi VentureBeat memberikan penilaian yang cukup ambigu:
Ini menunjukkan Claude memiliki "kemampuan persepsi lingkungan" yang kuat, sangat pandai menjelajahi lingkungan sekitarnya dan memanfaatkan sumber daya yang tersedia. Dianggap "curang" atau "cerdik", tergantung pada posisi Anda.
Tapi bagaimanapun juga, ALE jelas belajar dari pelajaran itu——
Langsung memindahkan ruang ujian dari command line ke operasi desktop GUI, membuatmu tidak punya riwayat git untuk dilihat diam-diam.
Tempat ujian yang mengevaluasi AI, sedang dipaksa untuk meningkatkan dirinya sendiri oleh AI, juga cukup menarik.
Alamat benchmark lengkap: https://agents-last-exam.org/leaderboard Halaman proyek: https://agents-last-exam.org/ GitHub: https://github.com/rdi-berkeley/agents-last-exam
Referensi:
[1]https://x.com/i/trending/2065215002878021789
[2]https://venturebeat.com/technology/deepswe-blows-up-the-ai-coding-leaderboard-crowns-gpt-5-5-and-finds-claude-opus-exploiting-a-benchmark-loophole
[3]https://venturebeat.com/technology/surprise-upset-gpt-5-5-beats-claude-fable-5-on-brutal-new-agents-last-exam-benchmark
Artikel ini berasal dari akun WeChat publik "量子位", penulis: 一水





