Jika AI dilemparkan ke lokasi proyek yang tidak memiliki jawaban baku, apakah ia masih bisa bertahan?
Selama ini, AI Agent terlihat serba bisa, tetapi sebenarnya kebanyakan hanya "menggali ingatan" dari basis pengetahuan yang sudah diketahui.
Namun dunia teknik yang sesungguhnya adalah kejam: stabilitas robot bawah air, batas dendrit litium pada baterai lithium, kontrol kebisingan pada sirkuit kuantum... Masalah-masalah ini tidak memiliki "nilai sempurna", hanya ada "optimasi yang semakin mendekati batas".
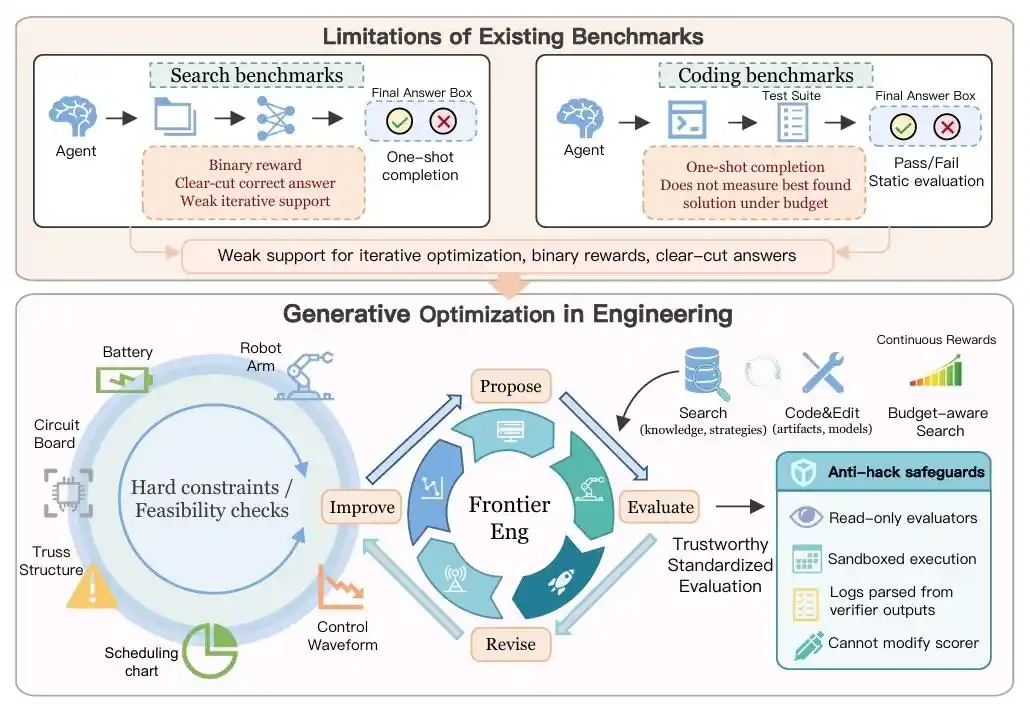
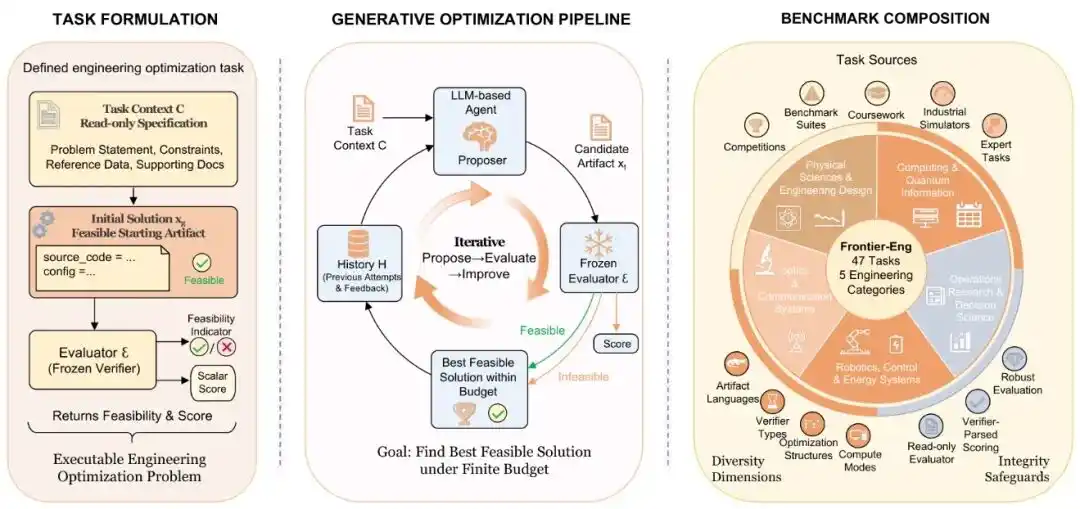
Baru-baru ini, Agent Benchmark yang dirilis oleh Navers lab di bawah Einsia AI — Frontier-Eng Bench — secara resmi merobek label "penghafal soal" dari AI.

Tim peneliti tidak meminta AI mengerjakan soal kode usang, melainkan memberinya serangkaian "siklus rekayasa" yang lengkap: mengajukan rencana, terhubung ke simulator, menerima laporan error, mengubah parameter, menjalankan ulang.
Di hadapan 47 tugas lintas disiplin yang menantang ini, AI harus bertindak seperti insinyur berpengalaman, mencari solusi optimal di tengah "segitiga mustahil" antara konsumsi daya, keamanan, dan kinerja.
Ini bukan hanya seperangkat uji, tetapi lebih seperti sebuah pemanasan untuk "evolusi" Agent.
Ketika AI mulai belajar memperbaiki diri melalui umpan balik, era Auto Research di mana "manusia menetapkan tujuan, dan AI kemudian mengiterasi tanpa henti 24 jam sehari", mungkin lebih dekat dari yang kita bayangkan.
AI Mulai Mengerjakan "Pekerjaan Teknis" yang Nyata
Model bahasa besar sebelumnya, lebih mirip seorang jenius akademis.
Anda melempar pertanyaan, ia "menggali ingatan" dari data pelatihan yang masif, lalu merangkainya menjadi jawaban yang terlihat masuk akal.
Dalam mode ini, model bahasa besar pada dasarnya sedang bermain "rangkai kata", bukan memecahkan masalah dunia nyata.
Namun kehadiran Frontier-Eng Bench membuat AI mengerjakan tugas "optimasi rekayasa".
Alurnya berubah menjadi: AI mengajukan rencana, lalu terhubung ke simulator untuk menjalankan eksperimen, kemudian memperoleh umpan balik dan laporan error, memodifikasi parameter dan kode, dan melanjutkan iterasi sampai kinerja terus meningkat.
Dalam sistem loop tertutup ini, peran AI mengalami perubahan kualitatif.
Ingin membuat robot bawah air lebih stabil? AI harus mulai menyesuaikan controller secara otomatis.
Ingin meningkatkan kecepatan lengan robot sedikit lagi? AI harus menjalankan simulasi sendiri.
Dalam arti tertentu, AI telah lepas dari sekadar pemahaman semantik, dan mulai seperti insinyur profesional yang melakukan optimasi berkelanjutan dalam umpan balik lingkungan nyata.
△
Tempat paling menarik dari Frontier-Eng Bench adalah: yang diujinya bukan apakah AI "menjawab dengan benar", melainkan apakah AI benar-benar bisa terus menjadi lebih kuat.
Karena optimasi rekayasa yang nyata, tidak pernah berupa pilihan ganda, tidak ada jawaban baku yang tunggal.
Ambil contoh pengisian cepat baterai, tujuannya terdengar sederhana — semakin cepat terisi semakin baik, tetapi kenyataannya tidak semudah itu.
AI harus menemukan titik keseimbangan kinerja yang tepat di bawah kendala ketat: suhu tidak boleh meledak, voltase tidak boleh melampaui batas, umur baterai tidak boleh turun terlalu cepat, dan juga harus menghindari pertumbuhan dendrit litium.
Ini berarti AI tidak dapat melewatinya dengan "mengerjakan soal" yang bersifat trik, ia harus menunjukkan daya tahan evolusi berkelanjutan dalam umpan balik jangka panjang.
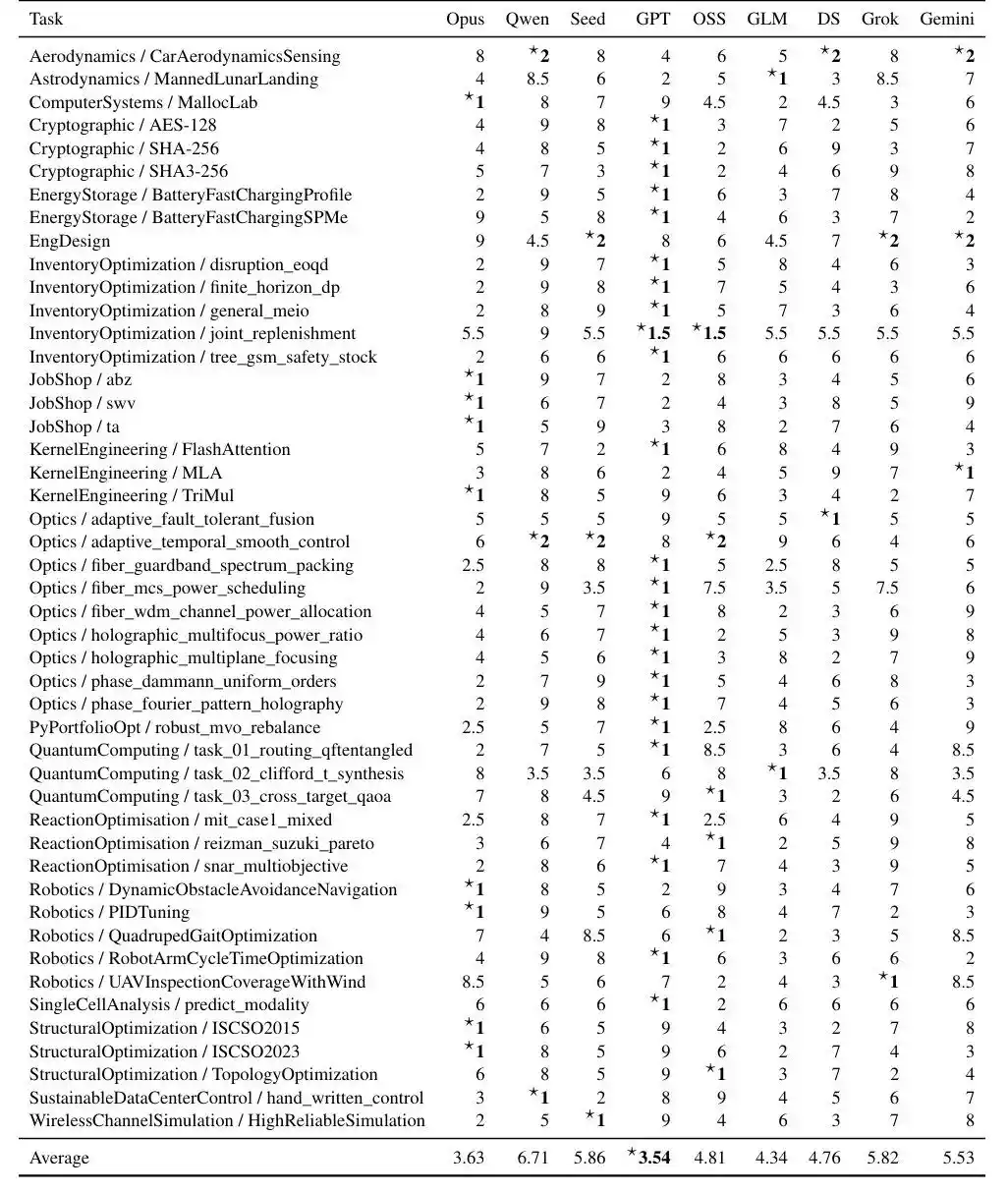
Mampukah AI melakukan optimasi jangka panjang di lingkungan nyata?
Dari hasilnya, GPT5.4 secara keseluruhan menunjukkan performa paling stabil, tetapi jarak untuk "menyelesaikan" Benchmark ini, masih sangat jauh bagi AI.
△
Auto Research Masuk Era "Iterasi dan Optimasi"
Tim peneliti mengangkat poin yang sangat menarik dalam makalah mereka:
Kecerdasan yang benar-benar tinggi pada dasarnya bergantung pada loop umpan balik jangka panjang.
Seperti halnya AlphaGo yang mampu mengalahkan Lee Sedol, terletak pada simulasi dan umpan balik instan yang sangat masif di balik setiap keputusannya, bukan pada menghafal pola permainan yang sudah tetap.
Riset sejati juga demikian, laboratorium top tidak bergantung pada ledakan inspirasi sekali saja, melainkan terus-menerus mengajukan hipotesis, menjalankan eksperimen, melihat hasil, mengubah rencana, dan terus mencoba.
Begitu pula dengan optimasi rekayasa, versi pertama seringkali bisa dibuat oleh siapa saja, yang benar-benar sulit adalah lompatan kinerja 1% terakhir itu.
Makna Frontier-Eng Bench terletak pada: ini pertama kalinya mulai menguji "kemampuan iterasi dan optimasi" AI secara sistematis, dan merangkum dua hukum evolusi AI yang hampir kejam.
△
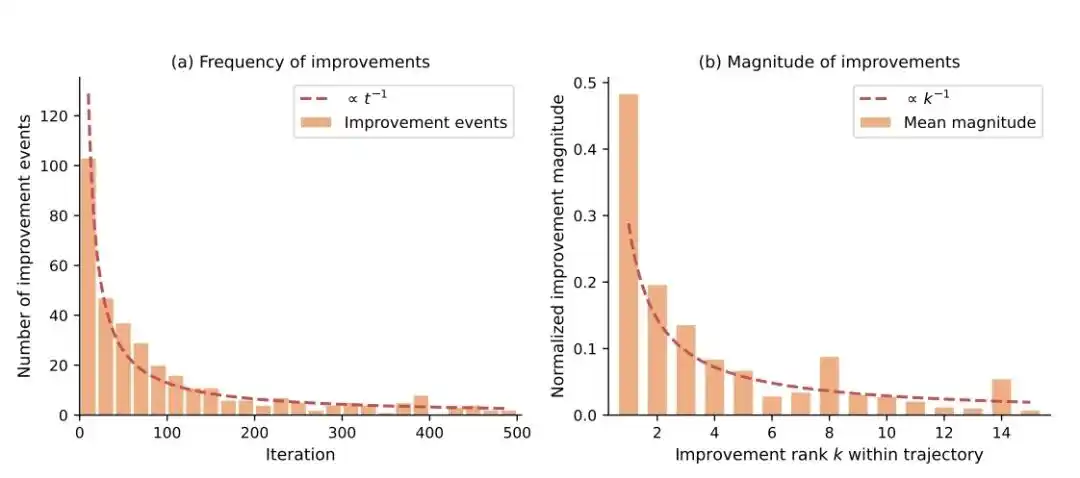
Hukum pertama: Semakin ke belakang, semakin sulit peningkatannya.
Makalah ini menemukan bahwa frekuensi dan besarnya perbaikan Agent menunjukkan penurunan mengikuti hukum pangkat (power law):
- Frekuensi perbaikan ∝ 1/jumlah iterasi
- Besarnya perbaikan ∝ 1/jumlah perbaikan
Sederhananya: beberapa iterasi pertama meningkat paling cepat, kemudian semakin sulit, semakin kecil peningkatannya.
Ini sangat mirip dengan proses pengembangan nyata, versi pertama AI dapat dengan cepat menghabisi banyak "buah yang rendah", tetapi semakin mendekati ke jenuh, bahkan untuk meningkatkan kinerja sedikit saja perlu usaha keras.
Apakah lebih menguntungkan jika membuka beberapa jalur paralel untuk mencoba-coba? Jawabannya tersembunyi dalam hukum kedua.
△
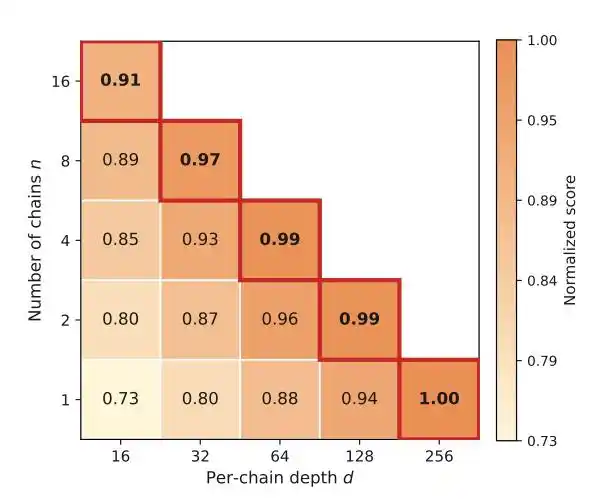
Hukum kedua: Lebar (breadth) berguna, tetapi kedalaman (depth) lebih penting dan tak tergantikan.
Menjalankan beberapa jalur paralel dapat menghindari kebuntuan, tetapi dengan anggaran tetap, setiap penambahan satu rantai akan mengurangi kedalaman.
Banyak terobosan rekayasa memerlukan akumulasi berkelanjutan dan koreksi terus-menerus, baru akan muncul lompatan struktural, bukan dengan "mencoba beberapa kali lagi".
Ini sebenarnya mengisyaratkan arah pengembangan Agent generasi berikutnya: bukan model yang "menghasilkan jawaban sekali jadi", melainkan sistem yang mampu terus beriterasi dan berevolusi sendiri dalam umpan balik jangka panjang.
Insinyur AI, Mungkin Benar-Benar Akan Datang
Makna mendalam yang sebenarnya dari penelitian ini adalah bahwa ia menguraikan secara awal seperangkat sistem AI yang mulai mendekati siklus rekayasa nyata.
△
Bayangkan, ketika AI terhubung ke perangkat lunak industri, lingkungan simulasi, sistem CAD, alat desain chip, platform komputasi ilmiah...
Perubahan besar pada modalitas produktivitas sudah di depan mata.
Di laboratorium masa depan, sangat mungkin muncul pembagian kerja seperti ini:
Peneliti manusia bertanggung jawab mengusulkan arah dan tujuan.
Misalnya, "kurangi konsumsi energi komponen ini sebesar 30%", "tekan penggunaan GPU pada forward pass model ini lebih rendah lagi", "tingkatkan stabilitas kontrol robot sedikit lagi", "membuat fidelitas sirkuit kuantum terus mendekati batas", dan sebagainya.
Sedangkan AI bertanggung jawab "mencari jalan dengan gigih", mereka berfokus pada tujuan-tujuan ini, melakukan optimasi berkelanjutan.
Misalnya, secara otomatis menjalankan simulasi dan eksperimen, secara otomatis membaca umpan balik dari verifier dan simulator, lalu terus memodifikasi dan mengoptimasi, beriterasi 24 jam tanpa henti.
Logika evolusi ini membebaskan AI dari identitas "alat bantu", dan mulai seperti tim rekayasa sejati yang menyelesaikan masalah sistem kompleks, dan itu juga tanpa mengenal lelah.
Dan masalah yang diungkapkan oleh Benchmark Frontier-Eng ini sebenarnya juga sangat langsung:
Ketika AI mulai belajar "optimasi jangka panjang", seberapa jauh jaraknya dengan kecerdasan rekayasa yang sesungguhnya?
Judul Makalah: Frontier-Eng: Benchmarking Self-Evolving Agents on Real-World Engineering Tasks with Generative Optimization
Halaman Proyek: https://lab.einsia.ai/frontier-eng/
Arxiv: https://arxiv.org/abs/2604.12290
Repositori GitHub: https://github.com/EinsiaLab/Frontier-Engineering
Artikel ini berasal dari akun WeChat publik "量子位", penulis: Yun Zhong






