Penulis: qinbafrank
Pada bulan Februari, dalam tulisan "Apa Arti dari Perang Pengeluaran Modal Ini?", sempat dibahas bahwa link kunci dalam rantai pasokan tenaga AI masih bisa mengeruk nilai terbesar: chip, pengujian dan kemasan, penyimpanan, modul optik, dll. Kapasitas mana yang tidak mudah diperluas dengan cepat, mana yang memiliki parit pertahanan yang sangat tinggi, akan menikmati keuntungan dari pengeluaran modal yang besar.
Ruang optimisasi efisiensi masih sangat besar: distilasi pada sisi inferensi, kuantisasi, MoE, chip khusus, pendinginan cair, fusi nuklir (jangka panjang), dll, dapat mengurangi konsumsi energi dan biaya per unit tenaga hingga 10–100 kali. Peluang perlu dicari pada link-link ini.
Baru-baru ini, beberapa bank investasi besar seperti Morgan Stanley, JP Morgan, Bank of America, Goldman Sachs, UBS, Citigroup, Bernstein, HSBC, merilis laporan terkini terkait AI/semikonduktor/kelistrikan/penyimpanan. Hambatan perangkat keras AI telah berkembang dari dimensi tunggal "pasokan GPU" menjadi ketegangan kolektif di lima dimensi: listrik, chip, penyimpanan, peralatan, dan material.
Skala permintaan AI telah melampaui semua interval prediksi dari perencanaan listrik tradisional, kapasitas peralatan semikonduktor, model harga penyimpanan, dan asumsi pemasangan robot.
Penelitian tema global Morgan Stanley menunjukkan bahwa konsumsi token model bahasa besar global per minggu melonjak dari 6,4 triliun menjadi 22,7 triliun dalam 3 bulan, peningkatan 2,5 kali lipat. Kekurangan daya pusat data AS tahun 2025-28 mencapai 55 Gigawatt. Laporan obligasi proyek komputasi kinerja tinggi pusat data JP Morgan pertama kali mencakup dan langsung memberikan angka kekurangan "122 Gigawatt yang perlu dibiayai dalam 5 tahun ke depan". Rencana kelistrikan 5 tahun AS melonjak dari 101 Gigawatt menjadi 230 Gigawatt, 44% proyek baru memiliki waktu tunggu penyambungan ke jaringan lebih dari 4 tahun. Laporan harga target terbaru Bank of America untuk Alphabet merevisi pengeluaran modal tahun 2026 langsung menjadi $181,5 miliar, dua kali lipat secara tahunan, arus kas bebas turun 62%. Ketiga set data ini bukan hasil dari kerangka kerja yang sama, melainkan gambaran independen dari tiga lembaga independen pada jalur penelitian yang berbeda.
Evolusi hambatan pada rantai pasokan semikonduktor (khususnya di bidang tenaga AI), bergerak maju dengan urutan yang jelas: dari "Komputasi (GPU) → Penyimpanan (HBM, dll) → Interkoneksi Optik → Listrik/Pendinginan Cair". Ini adalah konsensus industri tahun 2025-2026. Seiring dengan perluasan kluster pelatihan/inferensi AI dari rak tunggal (puluhan GPU) ke skala sangat besar (ribuan hingga puluhan ribu GPU), setiap kali satu hambatan teratasi, batasan fisik/rantai pasokan berikutnya akan segera terungkap, membentuk kendala komplementer "Leontief" (jika satu kurang, tidak dapat dikirim).
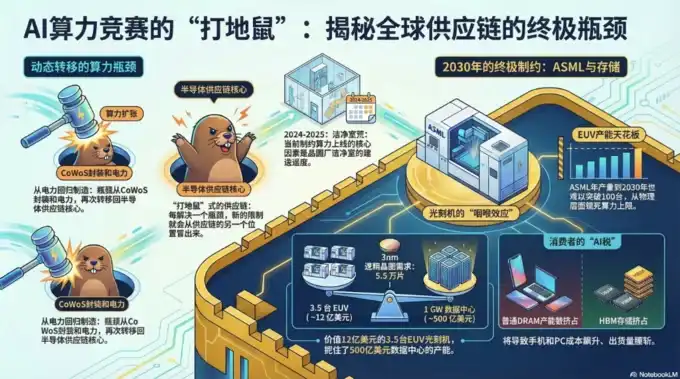
Perlu dipahami mengapa evolusi ini terjadi, kondisi saat ini, dan alasan fisik/teknis di baliknya:
1. Hambatan Tahap Pertama: Komputasi GPU (mendominasi 2022-2024) Batasan Inti:
Kapasitas wafer dari GPU kelas atas (seperti NVIDIA Hopper H100 → Blackwell B200 → Rubin) + kemasan canggih.
Mengapa jadi hambatan: Model AI besar membutuhkan komputasi paralel masif, proses logika TSMC 4nm/3nm/2nm + kapasitas kemasan CoWoS (2.5D/3D) sempat menjadi titik tersumbat terbesar. Meskipun wafer depan cukup, kemampuan di belakang untuk menumpuk dan mengemas chip logika + HBM tidak bisa mengimbangi, maka seluruh GPU tidak bisa keluar.
Kondisi peredaan: TSMC memperluas CoWoS secara besar-besaran (kapasitas berlipat ganda 2024-2025), NVIDIA Blackwell telah dikirimkan dalam skala besar. Tapi ini hanya membuka kunci link "komputasi", segera memunculkan masalah baru.
2. Hambatan Tahap Kedua: Penyimpanan (HBM - High Bandwidth Memory, menjadi yang paling ketat pada 2024-2025)
Batasan Inti: Kapasitas HBM3/HBM3e/HBM4.
Mengapa menjadi penerus hambatan: Daya komputasi GPU meningkat, tetapi parameter model meledak secara eksponensial (triliunan bahkan puluhan triliun parameter), perpindahan data (bandwidth memori) menjadi "tembok memori". HBM dapat mentransmisikan data hingga beberapa TB per detik, lebih dari 20 kali lebih cepat dari memori DDR biasa. Karena HBM berdekatan dengan chip logika, data tidak perlu ditransmisikan jauh, sehingga menghemat energi.
Satu GPU B200 membutuhkan 192GB+ HBM3e, total HBM per rak tunggal (NVL72) mencapai 30-40TB, dan kebutuhan bandwidth jauh melampaui DRAM tradisional.
Kondisi rantai pasokan: Hanya SK Hynix, Samsung, Micron yang dapat memproduksi HBM secara skala besar, prosesnya rumit (TSV + penumpukan), 2025 sudah habis terjual, 2026 masih kekurangan pasokan, harga melonjak 246% secara tahunan. Meskipun chip GPU siap, tanpa HBM tidak dapat dirakit dan dikirim, menyebabkan penundaan penyebaran seluruh kluster AI.
Hasil: Penyimpanan berubah dari "komoditas" menjadi link strategis yang menyumbat, kontribusinya dalam pengeluaran modal bisa mencapai 30%.
3. Hambatan Tahap Ketiga: Interkoneksi Optik (sedang beralih pada 2025-2026)
Batasan Inti: Batas fisik kabel tembaga (NVLink/NVSwitch) pada bandwidth, jarak, konsumsi daya, dan berat.
Mengapa pasti beralih ke optik: Di dalam rak tunggal (72 GPU) masih bisa mengandalkan kabel tembaga, tetapi ketika perlu diperluas ke multi-rak, bahkan interkoneksi ribuan GPU, kabel tembaga mengalami redaman serius (pada bandwidth 1,8TB/s jarak efektif <1 meter), ledakan berat (lebih dari 5.000 kabel tembaga di rak NVL72, total berat 1,36 ton), konsumsi daya tinggi (modul optik pluggable menggantikan kabel tembaga akan mengonsumsi tambahan 20.000 watt). Integritas sinyal, latensi, pendinginan tidak bisa mendukung kluster yang lebih besar.
Solusi: Beralih ke interkoneksi optik (CPO - Co-Packaged Optics + teknologi fotonik silikon). Menempatkan mesin optik langsung di samping GPU/ASIC, menggunakan serat optik untuk Scale-Out, kepadatan bandwidth lebih tinggi, daya per bit lebih rendah, jarak lebih jauh.
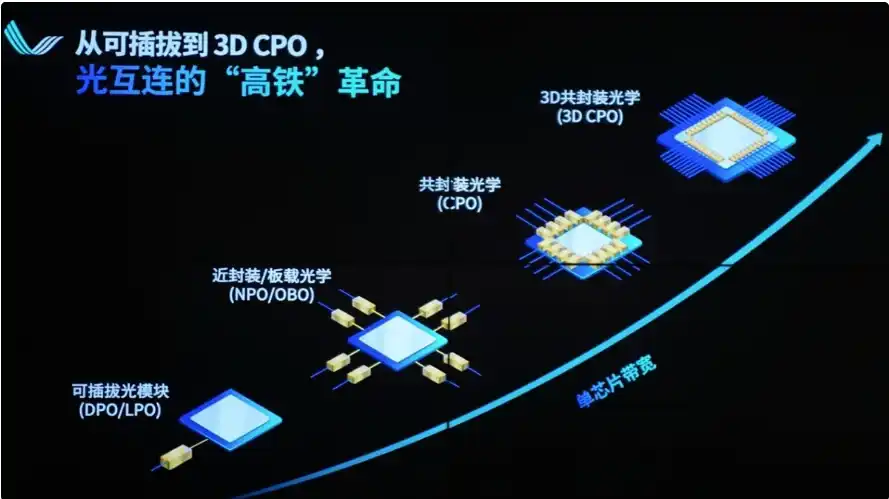
NVIDIA pada GTC 2026 bertaruh besar, telah berinvestasi di perusahaan optik, permintaan modul optik 800G/1.6T meledak. Lite, Broadcom, Coherent, Ayar Labs, dll. menjadi pemenang baru.
Kemajuan saat ini: Kabel tembaga sudah mencapai batas, interkoneksi optik sedang berubah dari "opsional" menjadi "wajib", sedang menembus langit-langit kinerja pusat data AI.
4. Hambatan Tahap Keempat (paling mutakhir saat ini): Listrik + Pendinginan Cair (menjadi batasan fisik akhir mulai 2026) Batasan Inti: Tembok daya + tembok panas + akses jaringan listrik.
Mengapa menjadi hambatan utama: Setiap GPU dari 300W → 700-1200W, rak tunggal dari 10-20kW (era CPU) melonjak ke 120-200kW+ bahkan lebih tinggi. Batas fisik pendinginan udara tradisional hanya 20-50kW, kebisingan, aliran udara, konsumsi energi tidak dapat diterima.
Sisi listrik: Pusat data membutuhkan catu daya tingkat Gigawatt, antrean penyambungan ke jaringan bisa bertahun-tahun, siklus pengiriman peralatan seperti transformator, transformator padat memanjang hingga 100 minggu. CEO Microsoft pernah berkata tegas "ada GPU tapi tidak ada listrik untuk dipasang".
Sisi pendinginan cair: Harus beralih ke Direct-to-Chip (pendinginan cair langsung ke chip) atau pendinginan cair perendaman, dikombinasikan dengan teknologi mikrofuidik, cold plate, dll. TSMC telah mendemonstrasikan pendinginan cair berbasis silikon pada platform CoWoS, mendukung TDP >2.6kW. Vertiv (VRT) dll., produsen pendinginan cair/manajemen panas menjadi inti baru infrastruktur.
Efek berantai: Persyaratan PUE (Power Usage Effectiveness) <1.2, pemulihan panas buangan, penyambungan ke jaringan tenaga nuklir/energi baru menjadi topik baru. Meskipun semua link sebelumnya teratasi, tanpa listrik dan pendinginan, rak tidak dapat dioperasikan.
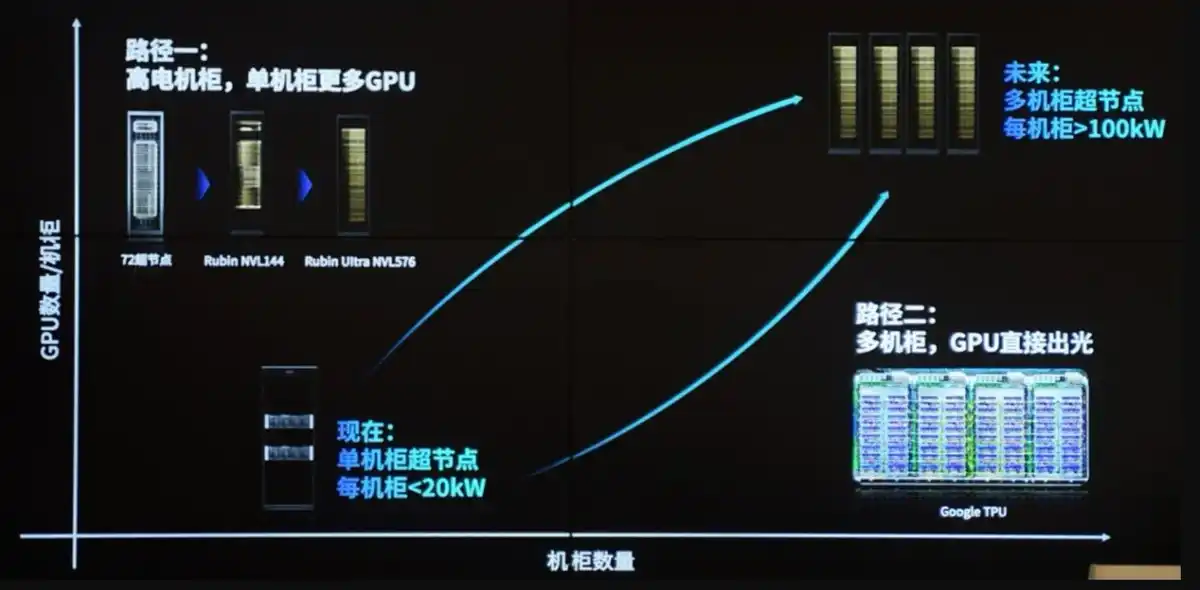
Logika Esensial Perpindahan Hambatan Rantai Pasokan Tenaga AI Tenaga AI bukan masalah "titik tunggal", melainkan fungsi produksi sistemik Leontief — GPU, HBM, interkoneksi, listrik, pendinginan harus cocok sesuai papan terpendek. Hyperscaler (Google, Microsoft, Meta, dll.) setiap kali menyelesaikan satu, segera mendorong modal dan inovasi ke link berikutnya.
Saat ini (2026) berada pada periode transisi "interkoneksi optik dipercepat implementasinya + listrik/pendinginan cair digunakan secara komersial skala besar", di masa depan mungkin masih akan muncul hambatan baru (seperti laser, material serat optik, atau transformator jaringan listrik), tetapi rantai "komputasi → penyimpanan → optik → listrik/pendinginan" ini sudah menjadi jalur yang diakui industri.
Ini juga menjelaskan mengapa logika investasi beralih dari NVIDIA/TSMC ke tiga raksasa HBM (SK Hynix, dll.), produsen optik (Lumentum, Coherent), infrastruktur pendinginan cair/kelistrikan (Vertiv, perusahaan catu daya terkait).
Setiap kali perpindahan hambatan, membentuk kembali distribusi nilai dari seluruh rantai pasokan semikonduktor + pusat data.






