Authors: Li Hailun, Su Yang
On January 6th, Beijing time, NVIDIA CEO Jensen Huang, clad in his signature leather jacket, once again took the main stage at CES 2026.
At CES 2025, NVIDIA showcased the mass-produced Blackwell chip and a full-stack physical AI technology suite. During the event, Huang emphasized that an "era of Physical AI" was dawning. He painted a future full of imagination: autonomous vehicles with reasoning capabilities, robots that can understand and think, and AI Agents capable of handling long-context tasks involving millions of tokens.
A year has passed in a flash, and the AI industry has undergone significant evolution and change. Reviewing these changes at the launch event, Huang specifically highlighted open-source models.
He stated that open-source reasoning models like DeepSeek R1 have made the entire industry realize: when true openness and global collaboration kick in, the diffusion speed of AI becomes extremely rapid. Although open-source models still lag behind the most advanced models by about six months in overall capability, they close the gap every six months, and their downloads and usage have already seen explosive growth.

Compared to 2025's focus more on vision and possibilities, this time NVIDIA began systematically addressing the question of "how to achieve it":围绕推理型 AI (focusing on reasoning AI), it is bolstering the compute, networking, and storage infrastructure required for long-term operation, significantly reducing inference costs, and embedding these capabilities directly into real-world scenarios like autonomous driving and robotics.
Huang's CES keynote this year unfolded along three main lines:
● At the system and infrastructure level, NVIDIA redesigned the compute, networking, and storage architecture around long-term inference needs. With the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the Inference Context Memory Storage platform at the core, these updates directly target bottlenecks like high inference costs, difficulty in sustaining context, and scalability limitations, solving the problems of letting AI 'think a bit longer', 'afford to compute', and 'run persistently'.
● At the model level, NVIDIA placed Reasoning / Agentic AI at the core. Through models and tools like Alpamayo, Nemotron, and Cosmos Reason, it is pushing AI from "generating content" towards "continuous thinking", and from "one-time response models" to "agents that can work long-term".
● At the application and deployment level, these capabilities are being directly integrated into Physical AI scenarios like autonomous driving and robotics. Whether it's the Alpamayo-powered autonomous driving system or the GR00T and Jetson robotics ecosystem, they are driving scaled deployment through partnerships with cloud providers and enterprise platforms.

01 From Roadmap to Mass Production: Rubin's Full Performance Data Revealed for the First Time
At this CES, NVIDIA fully disclosed the technical details of the Rubin architecture for the first time.
In his speech, Huang started with the concept of Test-time Scaling. This concept can be understood as: making AI smarter isn't just about making it "study harder" during training anymore, but rather letting it "think a bit longer when encountering a problem".
In the past, improvements in AI capability relied mainly on throwing more compute power at the training stage, making models larger and larger; now, the new change is that even if the model stops growing, simply giving it a bit more time and compute power to think during each use can significantly improve the results.
How to make "AI thinking a bit longer" economically feasible? The Rubin architecture's next-generation AI computing platform is here to solve this problem.
Huang introduced it as a complete next-generation AI computing system, achieving a revolutionary drop in inference costs through the co-design of the Vera CPU, Rubin GPU, NVLink 6, ConnectX-9, BlueField-4, and Spectrum-6.

The NVIDIA Rubin GPU is the core chip responsible for AI compute in the Rubin architecture, aiming to significantly reduce the unit cost of inference and training.
Simply put, the Rubin GPU's core mission is to "make AI cheaper and smarter to use".
The core capability of the Rubin GPU lies in: the same GPU can handle more work. It can process more inference tasks at once, remember longer context, and communicate faster with other GPUs. This means many scenarios that previously required "stacking multiple cards" can now be accomplished with fewer GPUs.
The result is that inference is not only faster, but also significantly cheaper.
Huang recapped the hardware specs of the Rubin architecture's NVL72 for the audience: it contains 220 trillion transistors, with a bandwidth of 260 TB/s, and is the industry's first platform supporting rack-scale confidential computing.

Overall, compared to Blackwell, the Rubin GPU achieves a generational leap in key metrics: NVFP4 inference performance increases to 50 PFLOPS (5x), training performance to 35 PFLOPS (3.5x), HBM4 memory bandwidth to 22 TB/s (2.8x), and single GPU NVLink interconnect bandwidth doubles to 3.6 TB/s.
These improvements work together to enable a single GPU to handle more inference tasks and longer context, fundamentally reducing the reliance on the number of GPUs.

The Vera CPU is a core component designed specifically for data movement and Agentic processing, featuring 88 NVIDIA-designed Olympus cores, equipped with 1.5 TB of system memory (3x that of the previous Grace CPU), and achieving coherent memory access between CPU and GPU through 1.8 TB/s NVLink-C2C technology.
Unlike traditional general-purpose CPUs, Vera focuses on data scheduling and multi-step reasoning logic processing in AI inference scenarios, essentially acting as the system coordinator that enables "AI thinking a bit longer" to run efficiently.
NVLink 6, with its 3.6 TB/s bandwidth and in-network computing capability, allows the 72 GPUs in the Rubin architecture to work together like a single super GPU, which is key infrastructure for reducing inference costs.
This way, the data and intermediate results needed by AI during inference can quickly circulate between GPUs, without repeatedly waiting, copying, or recalculating.


In the Rubin architecture, NVLink-6 handles internal collaborative computing between GPUs, BlueField-4 handles context and data scheduling, and ConnectX-9 undertakes the system's high-speed external network connectivity. It ensures the Rubin system can communicate efficiently with other racks, data centers, and cloud platforms, a prerequisite for the smooth operation of large-scale training and inference tasks.
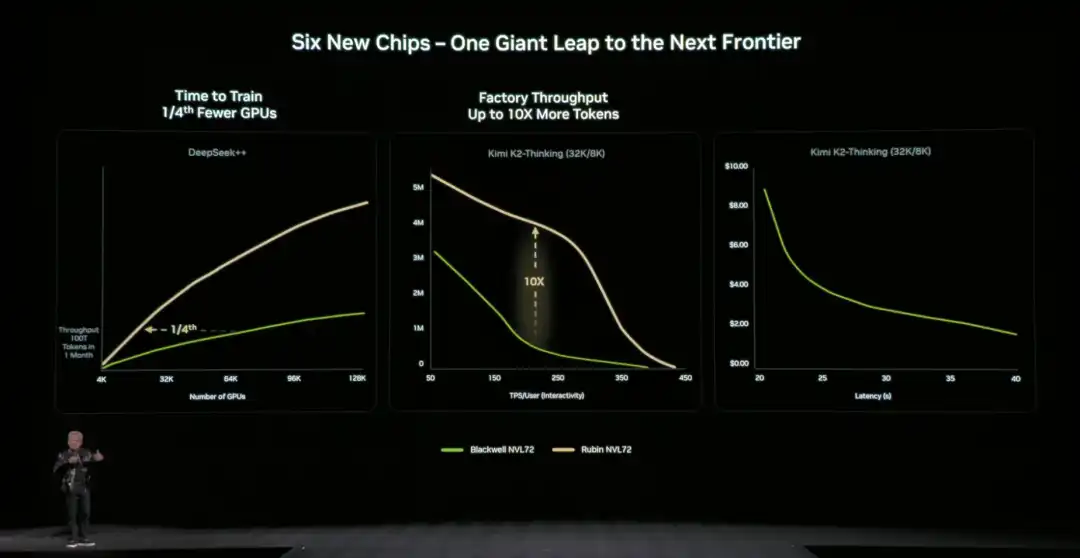
Compared to the previous generation architecture, NVIDIA also provided specific,直观的数据 (intuitive data): compared to the NVIDIA Blackwell platform, it can reduce token costs in the inference phase by up to 10 times, and reduce the number of GPUs required for training Mixture of Experts (MoE) models to 1/4 of the original.
NVIDIA officially stated that Microsoft has already committed to deploying hundreds of thousands of Vera Rubin chips in its next-generation Fairwater AI super factory, and cloud service providers like CoreWeave will offer Rubin instances in the second half of 2026. This infrastructure for "letting AI think a bit longer" is moving from technical demonstration to scaled commercial use.

02 How is the "Storage Bottleneck" Solved?
Letting AI "think a bit longer" also faces a key technical challenge: where should the context data be stored?
When AI handles complex tasks requiring multi-turn dialogue or multi-step reasoning, it generates a large amount of context data (KV Cache). Traditional architectures either cram it into expensive and capacity-limited GPU memory or put it in ordinary storage (which is too slow to access). If this "storage bottleneck" isn't solved, even the most powerful GPU will be hampered.
To address this issue, NVIDIA fully disclosed the BlueField-4 powered Inference Context Memory Storage Platform for the first time at this CES. The core goal is to create a "third layer" between GPU memory and traditional storage. It's fast enough, has ample capacity, and can support AI's long-term operation.
From a technical implementation perspective, this platform isn't the result of a single component working alone, but rather a set of co-designed elements:
- BlueField-4 is responsible for accelerating the management and access of context data at the hardware level, reducing data movement and system overhead;
- Spectrum-X Ethernet provides high-performance networking, supporting high-speed data sharing based on RDMA;
- Software components like DOCA, NIXL, and Dynamo are responsible for optimizing scheduling, reducing latency, and improving overall throughput at the system level.
We can understand this platform's approach as extending the context data, which originally could only reside in GPU memory, to an independent, high-speed, shareable "memory layer". This一方面 (on one hand) relieves pressure on the GPU, and另一方面 (on the other hand) allows for rapid sharing of this context information between multiple nodes and multiple AI agents.
In terms of actual效果 (effects), the data provided by NVIDIA官方 (officially) is: in specific scenarios, this method can increase the number of tokens processed per second by up to 5 times, and achieve同等水平的 (equivalent levels of) energy efficiency optimization.
Huang emphasized多次 (repeatedly) during the presentation that AI is evolving from "one-time dialogue chatbots" to true intelligent collaborators: they need to understand the real world, reason continuously, call tools to complete tasks, and retain both short-term and long-term memory. This is the core characteristic of Agentic AI. The Inference Context Memory Storage Platform is designed precisely for this long-running,反复思考的 (repeatedly thinking) form of AI. By expanding context capacity and speeding up cross-node sharing, it makes multi-turn conversations and multi-agent collaboration more stable, no longer "slowing down the longer it runs".

03 The New Generation DGX SuperPOD: Enabling 576 GPUs to Work Together
NVIDIA announced the new generation DGX SuperPOD (Super Pod) based on the Rubin architecture at this CES, expanding Rubin from a single rack to a complete data center solution.
What is a DGX SuperPOD?
If the Rubin NVL72 is a "super rack" containing 72 GPUs, then the DGX SuperPOD connects multiple such racks together to form a larger-scale AI computing cluster. This released version consists of 8 Vera Rubin NVL72 racks, equivalent to 576 GPUs working together.
When AI task scales continue to expand, the 576 GPUs of a single SuperPOD might not be enough. For example, training ultra-large-scale models, simultaneously serving thousands of Agentic AI agents, or processing complex tasks requiring millions of tokens of context. This requires multiple SuperPODs working together, and the DGX SuperPOD is the standardized solution for this scenario.
For enterprises and cloud service providers, the DGX SuperPOD provides an "out-of-the-box" large-scale AI infrastructure solution. There's no need to figure out how to connect hundreds of GPUs, configure networks, manage storage, etc., themselves.
The five core components of the new generation DGX SuperPOD:
○ 8 Vera Rubin NVL72 Racks - The core providing computing power, 72 GPUs per rack, 576 GPUs total;
○ NVLink 6 Expansion Network - Allows the 576 GPUs across these 8 racks to work together like one超大 (super large) GPU;
○ Spectrum-X Ethernet Expansion Network - Connects different SuperPODs, and to storage and external networks;
○ Inference Context Memory Storage Platform - Provides shared context data storage for long-running inference tasks;
○ NVIDIA Mission Control Software - Manages scheduling, monitoring, and optimization of the entire system.
With this upgrade, the foundation of the SuperPOD is the DGX Vera Rubin NVL72 rack-scale system at its core. Each NVL72 is itself a complete AI supercomputer, internally connecting 72 Rubin GPUs via NVLink 6, capable of handling large-scale inference and training tasks within a single rack. The new DGX SuperPOD consists of multiple NVL72 units, forming a system-level cluster capable of long-term operation.
When the compute scale expands from "single rack" to "multi-rack", new bottlenecks emerge: how to stably and efficiently传输海量数据 (transfer massive amounts of data) between racks.围绕这一问题 (Around this issue), NVIDIA simultaneously announced the new generation Ethernet switch based on the Spectrum-6 chip at this CES, and introduced "Co-Packaged Optics" (CPO) technology for the first time.
Simply put, this involves packaging the originally pluggable optical modules directly next to the switch chip, reducing the signal transmission distance from meters to millimeters, thereby significantly reducing power consumption and latency, and also improving the overall stability of the system.
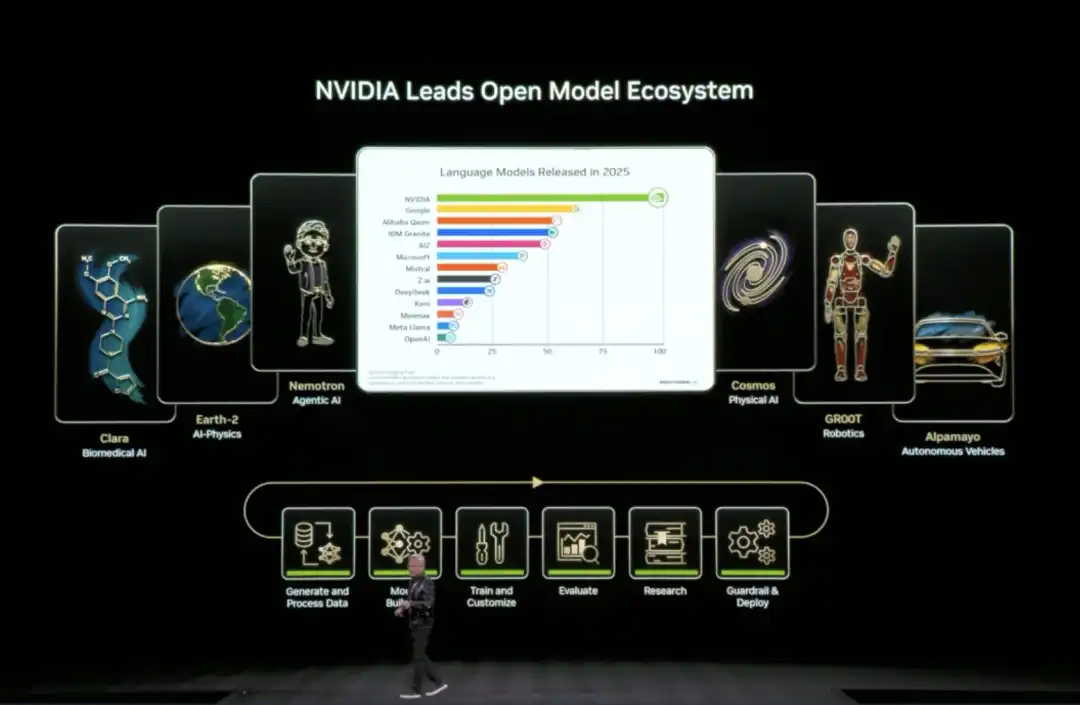
04 NVIDIA's Open Source AI "Full Stack": Everything from Data to Code
At this CES, Huang announced the expansion of its open-source model ecosystem (Open Model Universe), adding and updating a series of models, datasets, code libraries, and tools. This ecosystem covers six areas: Biomedical AI (Clara), AI Physics Simulation (Earth-2), Agentic AI (Nemotron), Physical AI (Cosmos), Robotics (GR00T), and Autonomous Driving (Alpamayo).
Training an AI model requires not just compute power, but also high-quality datasets, pre-trained models, training code, evaluation tools, and a whole set of infrastructure. For most companies and research institutions, building these from scratch is too time-consuming.
Specifically, NVIDIA has open-sourced six layers of content: compute platforms (DGX, HGX, etc.), training datasets for various domains, pre-trained foundation models, inference and training code libraries, complete training process scripts, and end-to-end solution templates.
The Nemotron series was a key focus of this update, covering four application directions.
In the reasoning direction, it includes small-scale reasoning models like Nemotron 3 Nano, Nemotron 2 Nano VL, as well as reinforcement learning training tools like NeMo RL and NeMo Gym. In the RAG (Retrieval-Augmented Generation) direction, it provides Nemotron Embed VL (vector embedding model), Nemotron Rerank VL (re-ranking model), relevant datasets, and the NeMo Retriever Library. In the safety direction, there is the Nemotron Content Safety model and its配套数据集 (matching dataset), and the NeMo Guardrails library.
In the speech direction, it includes Nemotron ASR for automatic speech recognition, the Granary Dataset for speech, and the NeMo Library for speech processing. This means if a company wants to build an AI customer service system with RAG, it doesn't need to train its own embedding and re-ranking models; it can directly use the code NVIDIA has already trained and open-sourced.
05 Physical AI Domain Moves Towards Commercial Deployment
The Physical AI domain also saw model updates—Cosmos for understanding and generating videos of the physical world, the general-purpose robotics foundation model Isaac GR00T, and the vision-language-action model for autonomous driving, Alpamayo.

Huang claimed at CES that the "ChatGPT moment" for Physical AI is approaching, but there are many challenges: the physical world is too complex and variable, collecting real data is slow and expensive, and there's never enough.
What's the solution? Synthetic data is one path. Hence, NVIDIA introduced Cosmos.
This is an open-source foundational model for the physical AI world, already pre-trained on massive amounts of video, real driving and robotics data, and 3D simulation. It can understand how the world works and connect language, images, 3D, and actions.
Huang stated that Cosmos can achieve several physical AI skills, such as generating content, performing reasoning, and predicting trajectories (even if only given a single image). It can generate realistic videos based on 3D scenes, generate physically plausible motion based on driving data, and even generate panoramic videos from simulators, multi-camera footage, or text descriptions. It can even还原 (recreate) rare scenarios.
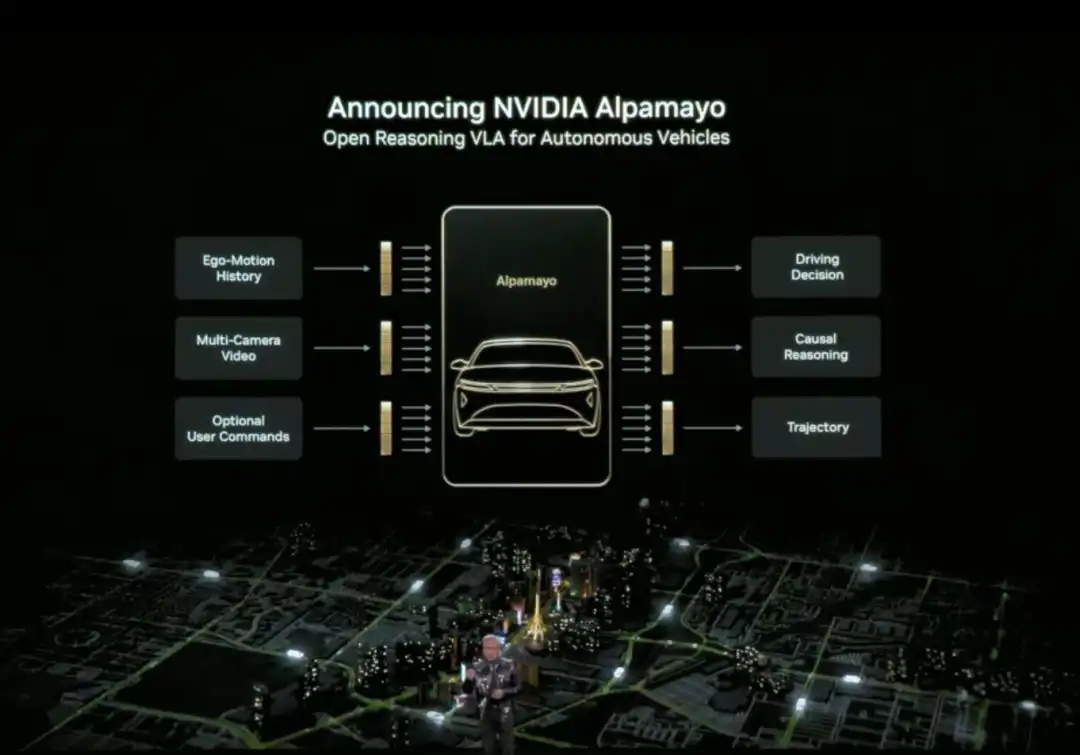
Huang also officially released Alpamayo. Alpamayo is an open-source toolchain for the autonomous driving domain, and the first open-source vision-language-action (VLA) reasoning model. Unlike previous open-sourcing of only code, NVIDIA this time open-sourced the complete development resources from data to deployment.
Alpamayo's biggest breakthrough is that it is a "reasoning" autonomous driving model. Traditional autonomous driving systems follow a "perception-planning-control" pipeline architecture—see a red light and brake, see a pedestrian and slow down, following preset rules. Alpamayo introduces "reasoning" capability, understanding causal relationships in complex scenes, predicting the intentions of other vehicles and pedestrians, and even handling decisions requiring multi-step thinking.
For example, at an intersection, it doesn't just recognize "there's a car ahead", but can reason "that car might be turning left, so I should wait for it to go first". This capability upgrades autonomous driving from "driving by rules" to "thinking like a human".
Huang announced that the NVIDIA DRIVE system has officially entered the mass production phase, with the first application being the new Mercedes-Benz CLA, planned to hit US roads in 2026. This vehicle will be equipped with an L2++ level autonomous driving system, adopting a hybrid architecture of "end-to-end AI model + traditional pipeline".
The robotics field also saw substantial progress.
Huang stated that leading global robotics companies, including Boston Dynamics, Franka Robotics, LEM Surgical, LG Electronics, Neura Robotics, and XRlabs, are developing products based on the NVIDIA Isaac platform and the GR00T foundation model, covering various fields from industrial robots and surgical robots to humanoid robots and consumer robots.

During the launch event, Huang stood in front of a stage filled with robots of different forms and用途 (purposes), displayed on a tiered platform: from humanoid robots, bipedal and wheeled service robots, to industrial robotic arms, engineering machinery, drones, and surgical assist devices, presenting a "robotics ecosystem landscape".
From Physical AI applications to the Rubin AI computing platform, to the Inference Context Memory Storage platform and the open-source AI "full stack".
These actions showcased by NVIDIA at CES constitute NVIDIA's narrative for推理时代 AI 基础设施 (AI infrastructure for the reasoning era). As Huang repeatedly emphasized, when Physical AI needs to think continuously, run persistently, and truly enter the real world, the problem is no longer just about whether there's enough compute power, but about who can actually build the entire system.
At CES 2026, NVIDIA has provided an answer.
Pertanyaan Terkait
QWhat are the three main topics of Jensen Huang's CES 2026 keynote?


AThe three main topics are: 1) Reconstructing computing, networking, and storage architecture around long-term inference needs with the Rubin platform, NVLink 6, Spectrum-X Ethernet, and the inference context memory storage platform. 2) Placing reasoning/agentic AI at the core through models and tools like Alpamayo, Nemotron, and Cosmos Reason. 3) Directly applying these capabilities to physical AI scenarios like autonomous driving and robotics.
QWhat is the key innovation of the Rubin GPU architecture and its primary goal?
AThe key innovation of the Rubin GPU architecture is its ability to handle more inference tasks and longer context within a single GPU, facilitated by a significant performance leap over Blackwell. Its primary goal is to 'make AI cheaper and smarter to use' by dramatically reducing the cost of inference and the number of GPUs required for many tasks.
QWhat problem does the Inference Context Memory Storage Platform solve, and what are its core components?
AIt solves the 'storage bottleneck' problem, where context data (KV Cache) from multi-step AI reasoning tasks traditionally had to be stored in expensive, limited GPU memory or slow conventional storage. Its core components are the BlueField-4 DPU (for hardware-accelerated data management), Spectrum-X Ethernet (for high-performance networking), and software components like DOCA, NIXL, and Dynamo for system optimization.
QWhat major advancement did NVIDIA announce for the autonomous driving sector?
ANVIDIA announced the official entry of its DRIVE system into mass production, with the first application being the new Mercedes-Benz CLA, planned for US roads in 2026. They also open-sourced Alpamayo, the first visual-language-action (VLA) reasoning model for autonomous driving, which introduces causal reasoning and multi-step decision-making capabilities.
QWhat is the significance of the new DGX SuperPOD based on the Rubin architecture?
AThe new DGX SuperPOD scales the Rubin architecture from a single rack (NVL72 with 72 GPUs) to a data-center-scale solution. Composed of 8 NVL72 racks for a total of 576 GPUs, it provides an 'out-of-the-box' massive AI computing cluster for training ultra-large models or serving thousands of Agentic AI agents, managed by the NVIDIA Mission Control software.
Bacaan Terkait




Trading
Artikel Populer
Apa Itu $S$
Memahami SPERO: Tinjauan Komprehensif Pengenalan SPERO Seiring dengan perkembangan lanskap inovasi, munculnya teknologi web3 dan proyek cryptocurrency memainkan peran penting dalam membentuk masa depan digital. Salah satu proyek yang telah menarik perhatian di bidang dinamis ini adalah SPERO, yang dilambangkan sebagai SPERO,$$s$. Artikel ini bertujuan untuk mengumpulkan dan menyajikan informasi terperinci tentang SPERO, untuk membantu para penggemar dan investor memahami dasar-dasar, tujuan, dan inovasi dalam domain web3 dan crypto. Apa itu SPERO,$$s$? SPERO,$$s$ adalah proyek unik dalam ruang crypto yang berusaha memanfaatkan prinsip desentralisasi dan teknologi blockchain untuk menciptakan ekosistem yang mendorong keterlibatan, utilitas, dan inklusi finansial. Proyek ini dirancang untuk memfasilitasi interaksi peer-to-peer dengan cara baru, memberikan pengguna solusi dan layanan keuangan yang inovatif. Pada intinya, SPERO,$$s$ bertujuan untuk memberdayakan individu dengan menyediakan alat dan platform yang meningkatkan pengalaman pengguna dalam ruang cryptocurrency. Ini termasuk memungkinkan metode transaksi yang lebih fleksibel, mendorong inisiatif yang dipimpin komunitas, dan menciptakan jalur untuk peluang finansial melalui aplikasi terdesentralisasi (dApps). Visi mendasar dari SPERO,$$s$ berputar di sekitar inklusivitas, bertujuan untuk menjembatani kesenjangan dalam keuangan tradisional sambil memanfaatkan manfaat teknologi blockchain. Siapa Pencipta SPERO,$$s$? Identitas pencipta SPERO,$$s$ tetap agak samar, karena ada sumber daya publik yang terbatas yang memberikan informasi latar belakang terperinci tentang pendiriannya. Kurangnya transparansi ini dapat berasal dari komitmen proyek terhadap desentralisasi—sebuah etos yang banyak proyek web3 bagi, memprioritaskan kontribusi kolektif di atas pengakuan individu. Dengan memusatkan diskusi di sekitar komunitas dan tujuan kolektifnya, SPERO,$$s$ mewujudkan esensi pemberdayaan tanpa menonjolkan individu tertentu. Dengan demikian, memahami etos dan misi SPERO tetap lebih penting daripada mengidentifikasi pencipta tunggal. Siapa Investor SPERO,$$s$? SPERO,$$s$ didukung oleh beragam investor mulai dari modal ventura hingga investor malaikat yang berdedikasi untuk mendorong inovasi di sektor crypto. Fokus investor ini umumnya sejalan dengan misi SPERO—memprioritaskan proyek yang menjanjikan kemajuan teknologi sosial, inklusivitas finansial, dan tata kelola terdesentralisasi. Fondasi investor ini biasanya tertarik pada proyek yang tidak hanya menawarkan produk inovatif tetapi juga memberikan kontribusi positif kepada komunitas blockchain dan ekosistemnya. Dukungan dari investor ini memperkuat SPERO,$$s$ sebagai pesaing yang patut diperhitungkan di domain proyek crypto yang berkembang pesat. Bagaimana SPERO,$$s$ Bekerja? SPERO,$$s$ menerapkan kerangka kerja multi-faceted yang membedakannya dari proyek cryptocurrency konvensional. Berikut adalah beberapa fitur kunci yang menekankan keunikan dan inovasinya: Tata Kelola Terdesentralisasi: SPERO,$$s$ mengintegrasikan model tata kelola terdesentralisasi, memberdayakan pengguna untuk berpartisipasi aktif dalam proses pengambilan keputusan mengenai masa depan proyek. Pendekatan ini mendorong rasa kepemilikan dan akuntabilitas di antara anggota komunitas. Utilitas Token: SPERO,$$s$ memanfaatkan token cryptocurrency-nya sendiri, yang dirancang untuk melayani berbagai fungsi dalam ekosistem. Token ini memungkinkan transaksi, hadiah, dan fasilitasi layanan yang ditawarkan di platform, meningkatkan keterlibatan dan utilitas secara keseluruhan. Arsitektur Berlapis: Arsitektur teknis SPERO,$$s$ mendukung modularitas dan skalabilitas, memungkinkan integrasi fitur dan aplikasi tambahan secara mulus seiring dengan perkembangan proyek. Kemampuan beradaptasi ini sangat penting untuk mempertahankan relevansi di lanskap crypto yang selalu berubah. Keterlibatan Komunitas: Proyek ini menekankan inisiatif yang dipimpin komunitas, menggunakan mekanisme yang memberikan insentif untuk kolaborasi dan umpan balik. Dengan memelihara komunitas yang kuat, SPERO,$$s$ dapat lebih baik memenuhi kebutuhan pengguna dan beradaptasi dengan tren pasar. Fokus pada Inklusi: Dengan menawarkan biaya transaksi yang rendah dan antarmuka yang ramah pengguna, SPERO,$$s$ bertujuan untuk menarik basis pengguna yang beragam, termasuk individu yang mungkin sebelumnya tidak terlibat dalam ruang crypto. Komitmen ini terhadap inklusi sejalan dengan misi utamanya untuk memberdayakan melalui aksesibilitas. Garis Waktu SPERO,$$s$ Memahami sejarah proyek memberikan wawasan penting tentang trajektori dan tonggak perkembangannya. Berikut adalah garis waktu yang disarankan yang memetakan peristiwa signifikan dalam evolusi SPERO,$$s$: Fase Konseptualisasi dan Ideasi: Ide awal yang membentuk dasar SPERO,$$s$ dikembangkan, sangat selaras dengan prinsip desentralisasi dan fokus komunitas dalam industri blockchain. Peluncuran Whitepaper Proyek: Setelah fase konseptual, whitepaper komprehensif yang merinci visi, tujuan, dan infrastruktur teknologi SPERO,$$s$ dirilis untuk menarik minat dan umpan balik komunitas. Pembangunan Komunitas dan Keterlibatan Awal: Upaya jangkauan aktif dilakukan untuk membangun komunitas pengguna awal dan investor potensial, memfasilitasi diskusi seputar tujuan proyek dan mendapatkan dukungan. Acara Generasi Token: SPERO,$$s$ melakukan acara generasi token (TGE) untuk mendistribusikan token asli kepada pendukung awal dan membangun likuiditas awal dalam ekosistem. Peluncuran dApp Awal: Aplikasi terdesentralisasi (dApp) pertama yang terkait dengan SPERO,$$s$ diluncurkan, memungkinkan pengguna untuk terlibat dengan fungsionalitas inti platform. Pengembangan Berkelanjutan dan Kemitraan: Pembaruan dan peningkatan berkelanjutan terhadap penawaran proyek, termasuk kemitraan strategis dengan pemain lain di ruang blockchain, telah membentuk SPERO,$$s$ menjadi pemain yang kompetitif dan berkembang di pasar crypto. Kesimpulan SPERO,$$s$ berdiri sebagai bukti potensi web3 dan cryptocurrency untuk merevolusi sistem keuangan dan memberdayakan individu. Dengan komitmen terhadap tata kelola terdesentralisasi, keterlibatan komunitas, dan fungsionalitas yang dirancang secara inovatif, ia membuka jalan menuju lanskap keuangan yang lebih inklusif. Seperti halnya investasi di ruang crypto yang berkembang pesat, calon investor dan pengguna dianjurkan untuk melakukan riset secara menyeluruh dan terlibat dengan perkembangan yang sedang berlangsung dalam SPERO,$$s$. Proyek ini menunjukkan semangat inovatif industri crypto, mengundang eksplorasi lebih lanjut ke dalam berbagai kemungkinan yang ada. Meskipun perjalanan SPERO,$$s$ masih berlangsung, prinsip-prinsip dasarnya mungkin benar-benar mempengaruhi masa depan cara kita berinteraksi dengan teknologi, keuangan, dan satu sama lain dalam ekosistem digital yang saling terhubung.
75 Total TayanganDipublikasikan pada 2024.12.17Diperbarui pada 2024.12.17


Apa Itu AGENT S
Agent S: Masa Depan Interaksi Otonom di Web3 Pendahuluan Dalam lanskap Web3 dan cryptocurrency yang terus berkembang, inovasi secara konstan mendefinisikan ulang cara individu berinteraksi dengan platform digital. Salah satu proyek perintis, Agent S, menjanjikan untuk merevolusi interaksi manusia-komputer melalui kerangka agen terbuka. Dengan membuka jalan untuk interaksi otonom, Agent S bertujuan untuk menyederhanakan tugas-tugas kompleks, menawarkan aplikasi transformasional dalam kecerdasan buatan (AI). Eksplorasi mendetail ini akan menyelami seluk-beluk proyek, fitur uniknya, dan implikasinya untuk domain cryptocurrency. Apa itu Agent S? Agent S berdiri sebagai kerangka agen terbuka yang inovatif, dirancang khusus untuk mengatasi tiga tantangan mendasar dalam otomatisasi tugas komputer: Memperoleh Pengetahuan Spesifik Domain: Kerangka ini secara cerdas belajar dari berbagai sumber pengetahuan eksternal dan pengalaman internal. Pendekatan ganda ini memberdayakannya untuk membangun repositori pengetahuan spesifik domain yang kaya, meningkatkan kinerjanya dalam pelaksanaan tugas. Perencanaan Selama Rentang Tugas yang Panjang: Agent S menggunakan perencanaan hierarkis yang ditingkatkan pengalaman, pendekatan strategis yang memfasilitasi pemecahan dan pelaksanaan tugas-tugas rumit dengan efisien. Fitur ini secara signifikan meningkatkan kemampuannya untuk mengelola beberapa subtugas dengan efisien dan efektif. Menangani Antarmuka Dinamis dan Tidak Seragam: Proyek ini memperkenalkan Antarmuka Agen-Komputer (ACI), solusi inovatif yang meningkatkan interaksi antara agen dan pengguna. Dengan memanfaatkan Model Bahasa Besar Multimodal (MLLM), Agent S dapat menavigasi dan memanipulasi berbagai antarmuka pengguna grafis dengan mulus. Melalui fitur-fitur perintis ini, Agent S menyediakan kerangka kerja yang kuat yang mengatasi kompleksitas yang terlibat dalam mengotomatisasi interaksi manusia dengan mesin, membuka jalan untuk berbagai aplikasi dalam AI dan seterusnya. Siapa Pencipta Agent S? Meskipun konsep Agent S secara fundamental inovatif, informasi spesifik tentang penciptanya tetap samar. Pencipta saat ini tidak diketahui, yang menyoroti baik tahap awal proyek atau pilihan strategis untuk menjaga anggota pendiri tetap tersembunyi. Terlepas dari anonimitas, fokus tetap pada kemampuan dan potensi kerangka kerja. Siapa Investor Agent S? Karena Agent S relatif baru dalam ekosistem kriptografi, informasi terperinci mengenai investor dan pendukung keuangannya tidak secara eksplisit didokumentasikan. Kurangnya wawasan yang tersedia untuk umum mengenai fondasi investasi atau organisasi yang mendukung proyek ini menimbulkan pertanyaan tentang struktur pendanaannya dan peta jalan pengembangannya. Memahami dukungan sangat penting untuk mengukur keberlanjutan proyek dan potensi dampak pasar. Bagaimana Cara Kerja Agent S? Di inti Agent S terletak teknologi mutakhir yang memungkinkannya berfungsi secara efektif dalam berbagai pengaturan. Model operasionalnya dibangun di sekitar beberapa fitur kunci: Interaksi Komputer yang Mirip Manusia: Kerangka ini menawarkan perencanaan AI yang canggih, berusaha untuk membuat interaksi dengan komputer lebih intuitif. Dengan meniru perilaku manusia dalam pelaksanaan tugas, ia menjanjikan untuk meningkatkan pengalaman pengguna. Memori Naratif: Digunakan untuk memanfaatkan pengalaman tingkat tinggi, Agent S memanfaatkan memori naratif untuk melacak sejarah tugas, sehingga meningkatkan proses pengambilan keputusannya. Memori Episodik: Fitur ini memberikan panduan langkah demi langkah kepada pengguna, memungkinkan kerangka untuk menawarkan dukungan kontekstual saat tugas berlangsung. Dukungan untuk OpenACI: Dengan kemampuan untuk berjalan secara lokal, Agent S memungkinkan pengguna untuk mempertahankan kontrol atas interaksi dan alur kerja mereka, sejalan dengan etos terdesentralisasi Web3. Integrasi Mudah dengan API Eksternal: Versatilitas dan kompatibilitasnya dengan berbagai platform AI memastikan bahwa Agent S dapat dengan mulus masuk ke dalam ekosistem teknologi yang ada, menjadikannya pilihan menarik bagi pengembang dan organisasi. Fungsionalitas ini secara kolektif berkontribusi pada posisi unik Agent S dalam ruang kripto, saat ia mengotomatisasi tugas-tugas kompleks yang melibatkan banyak langkah dengan intervensi manusia yang minimal. Seiring proyek ini berkembang, aplikasi potensialnya di Web3 dapat mendefinisikan ulang bagaimana interaksi digital berlangsung. Garis Waktu Agent S Pengembangan dan tonggak Agent S dapat dirangkum dalam garis waktu yang menyoroti peristiwa pentingnya: 27 September 2024: Konsep Agent S diluncurkan dalam sebuah makalah penelitian komprehensif berjudul “Sebuah Kerangka Agen Terbuka yang Menggunakan Komputer Seperti Manusia,” yang menunjukkan dasar untuk proyek ini. 10 Oktober 2024: Makalah penelitian tersebut dipublikasikan secara terbuka di arXiv, menawarkan eksplorasi mendalam tentang kerangka kerja dan evaluasi kinerjanya berdasarkan tolok ukur OSWorld. 12 Oktober 2024: Sebuah presentasi video dirilis, memberikan wawasan visual tentang kemampuan dan fitur Agent S, lebih lanjut melibatkan pengguna dan investor potensial. Tanda-tanda dalam garis waktu ini tidak hanya menggambarkan kemajuan Agent S tetapi juga menunjukkan komitmennya terhadap transparansi dan keterlibatan komunitas. Poin Kunci Tentang Agent S Seiring kerangka Agent S terus berkembang, beberapa atribut kunci menonjol, menekankan sifat inovatif dan potensinya: Kerangka Inovatif: Dirancang untuk memberikan penggunaan komputer yang intuitif seperti interaksi manusia, Agent S membawa pendekatan baru untuk otomatisasi tugas. Interaksi Otonom: Kemampuan untuk berinteraksi secara otonom dengan komputer melalui GUI menandakan lompatan menuju solusi komputasi yang lebih cerdas dan efisien. Otomatisasi Tugas Kompleks: Dengan metodologinya yang kuat, ia dapat mengotomatisasi tugas-tugas kompleks yang melibatkan banyak langkah, membuat proses lebih cepat dan kurang rentan terhadap kesalahan. Perbaikan Berkelanjutan: Mekanisme pembelajaran memungkinkan Agent S untuk belajar dari pengalaman masa lalu, terus meningkatkan kinerja dan efektivitasnya. Versatilitas: Adaptabilitasnya di berbagai lingkungan operasi seperti OSWorld dan WindowsAgentArena memastikan bahwa ia dapat melayani berbagai aplikasi. Saat Agent S memposisikan dirinya di lanskap Web3 dan kripto, potensinya untuk meningkatkan kemampuan interaksi dan mengotomatisasi proses menandakan kemajuan signifikan dalam teknologi AI. Melalui kerangka inovatifnya, Agent S mencerminkan masa depan interaksi digital, menjanjikan pengalaman yang lebih mulus dan efisien bagi pengguna di berbagai industri. Kesimpulan Agent S mewakili lompatan berani ke depan dalam pernikahan AI dan Web3, dengan kapasitas untuk mendefinisikan ulang cara kita berinteraksi dengan teknologi. Meskipun masih dalam tahap awal, kemungkinan aplikasinya sangat luas dan menarik. Melalui kerangka komprehensifnya yang mengatasi tantangan kritis, Agent S bertujuan untuk membawa interaksi otonom ke garis depan pengalaman digital. Saat kita melangkah lebih dalam ke dalam ranah cryptocurrency dan desentralisasi, proyek-proyek seperti Agent S pasti akan memainkan peran penting dalam membentuk masa depan teknologi dan kolaborasi manusia-komputer.
309 Total TayanganDipublikasikan pada 2025.01.14Diperbarui pada 2025.01.14
Cara Membeli S
Selamat datang di HTX.com! Kami telah membuat pembelian Sonic (S) menjadi mudah dan nyaman. Ikuti panduan langkah demi langkah kami untuk memulai perjalanan kripto Anda.Langkah 1: Buat Akun HTX AndaGunakan alamat email atau nomor ponsel Anda untuk mendaftar akun gratis di HTX. Rasakan perjalanan pendaftaran yang mudah dan buka semua fitur.Dapatkan Akun SayaLangkah 2: Buka Beli Kripto, lalu Pilih Metode Pembayaran AndaKartu Kredit/Debit: Gunakan Visa atau Mastercard Anda untuk membeli Sonic (S) secara instan.Saldo: Gunakan dana dari saldo akun HTX Anda untuk melakukan trading dengan lancar.Pihak Ketiga: Kami telah menambahkan metode pembayaran populer seperti Google Pay dan Apple Pay untuk meningkatkan kenyamanan.P2P: Lakukan trading langsung dengan pengguna lain di HTX.Over-the-Counter (OTC): Kami menawarkan layanan yang dibuat khusus dan kurs yang kompetitif bagi para trader.Langkah 3: Simpan Sonic (S) AndaSetelah melakukan pembelian, simpan Sonic (S) di akun HTX Anda. Selain itu, Anda dapat mengirimkannya ke tempat lain melalui transfer blockchain atau menggunakannya untuk memperdagangkan mata uang kripto lainnya.Langkah 4: Lakukan trading Sonic (S)Lakukan trading Sonic (S) dengan mudah di pasar spot HTX. Cukup akses akun Anda, pilih pasangan perdagangan, jalankan trading, lalu pantau secara real-time. Kami menawarkan pengalaman yang ramah pengguna baik untuk pemula maupun trader berpengalaman.
538 Total TayanganDipublikasikan pada 2025.01.15Diperbarui pada 2025.03.21



