原文作者:Luccy,BlockBeats
原文编辑:Jack,BlockBeats
就在上周,在 Blast 用户突破 10 万名以及 TVL 升破 13 亿美元之际,Blast 测试网正式上线,并同步开启 BIG BANG 竞赛,Blast 生态也因此吸引了大量加密爱好者,其中不乏开发人员。
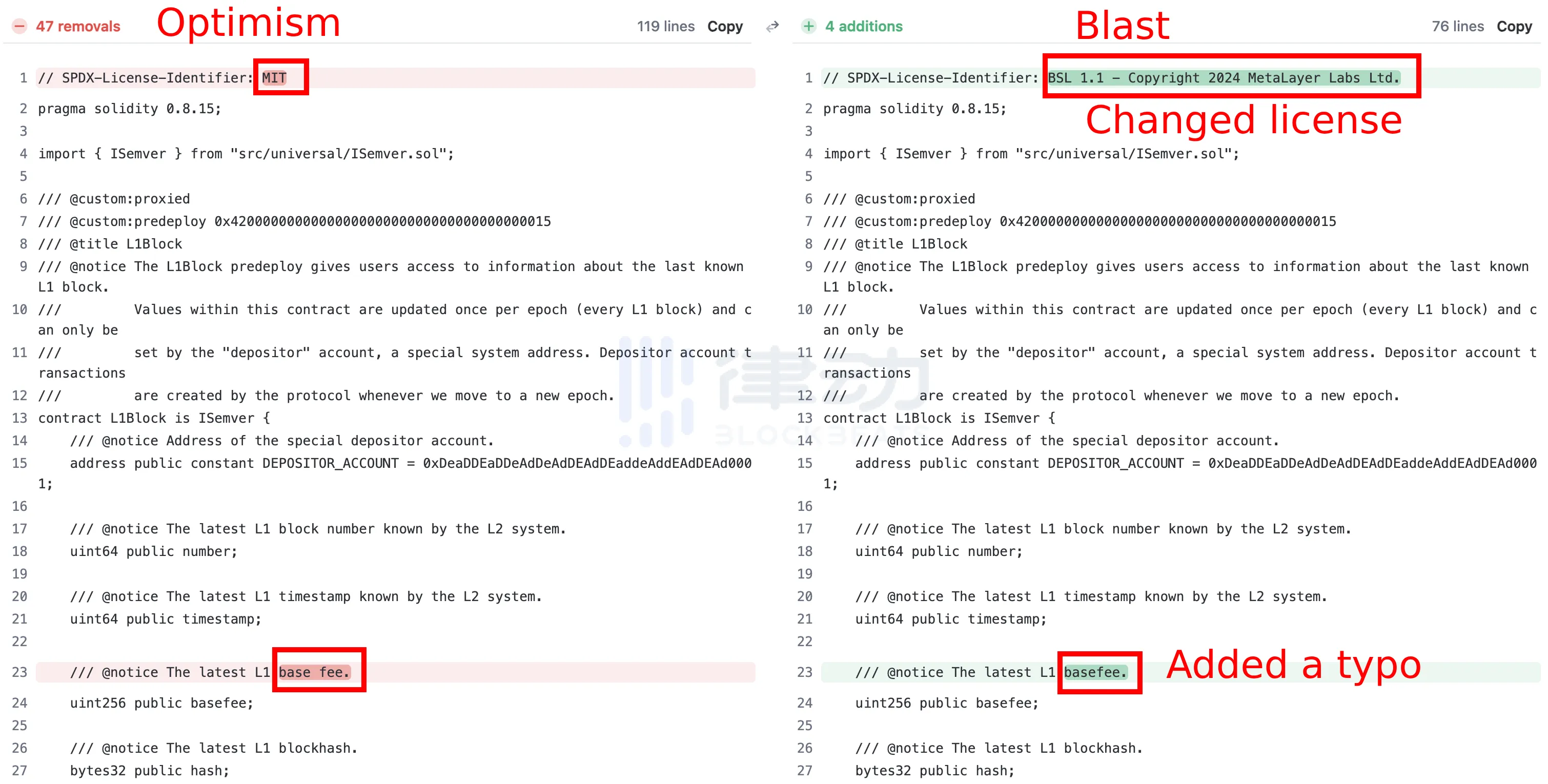
在这些竞赛者中,EVM 安全工程师 @0x Kaden 发现了 Blast 的代码库有问题。2 月 1 日,@0x Kaden 在社交媒体平台发推表示,Blast 将 Optimism 的 MIT 许可更改为 BSL。
消息一出,gaslite 联合创始人 @PopPunkOnChain 随即对比了 Blast 和 Optimism 的代码库。可以看到,在原始的 Optimism 的代码库中,第一行为「// SPDX-License-Identifier:MIT」,而在 Blast 的提交界面中,「MIT」被更改为「BSL」。
不仅仅是许可证的修改,在第 23 行中,「base fee」代码空格被删除,更改为「basefee」。@PopPunkOnChain表示,Blast 意图分叉 Optimism 的代码、添加拼写错误、删除功能,甚至调侃这对 Blast 来说「并不需要花费很多钱」。
本应是吸引开发者建设 Blast 生态的活动,活动刚过半个月就被扒出代码「抄袭」,社区用 meme 对 Blast 开启了「嘲笑」模式。而在这些 meme 图中,最值得被说道的莫过于 Blast 修改过的 BSL 许可证。

MIT 许可证(Massachusetts Institute of Technology License)和 BSL 许可证(Business Source License)都是软件许可证,用于规定软件的使用和分发条件。其中,MIT 许可证更具开放性,是一种宽松的开源许可证,允许在商业和非商业项目中自由使用、修改、分发和合并代码。而 BSL 许可证是一种相对较新的许可证,它允许免费使用软件,但对于商业使用可能会施加一些限制。
以太坊 OG「落井下石」
Blast 将 Optimism 的 MIT 代码更改为 BSL 意味着,商业用户可能需要在某个时点之后支付许可费用或遵守其他商业使用方面的限制。
虽然 BSL 本意是在开源精神和商业需求之间找到平衡,其初衷也受到大部分人的认同;但与其他较为宽松的许可证(例如 MIT)相比,BSL 显然过于严苛,也被诟病存在「阻碍创新」「不够开源」等问题。
最重要的是,MIN 许可证的开源性在一定程度上确实意味着「随意修改」,但将其直接修改为 BSL,就好像一句玩笑话「解决不了问题,就解决提出问题的人」,颇有一种耍赖的感觉。对此 Scroll 开发者 @0x G 00 gly 也反问到,「MIT 许可证并不意味着你可以用它做你想做的事,所以直接删除它?」

而 Scroll 的开发者 @pseudotheos 也解释到,「实际上,移除许可证是 MIT 唯一不允许做的事情」。甚至 Bankless 普通合伙人 @TrustlessState 也用一句简短的「yikes」表示感叹。

不仅仅是 Scroll 和 Bankless,我们可以在这件事上看到多家项目开发人员的身影。
包括 Mocaverse 顾问 @waleswoosh、MemeLand 建设者 @0x Char、Waterfall 协议负责人 @Sabnock 66、安全公司 Spearbit 高级工程师 @real_philogy、wartime capital 合伙人 @rockyxbt 以及 Shadow 工程师 @BeckerrJon 等等。虽然他们没有明确表态,只是一两个简单的单词或是一张 meme 图,但能看出他们对 Blast 的举动表示反对。
其中,EthernautDAO 建设者 @m 4 rio_eth 也表示,「代码有点复杂,有一些自定义函数,这就是为什么我认为他们做了许可证。」
加密圈 BSL 争议已久
实际上,社区对 BSL 的怨气由来已久,甚至有人将 BSL 解读成「BullShit License」(胡扯许可证)
此前 dYdX 的 V4 版本启动了从以太坊 2 层网络到 Cosmos 上独立区块链的过渡,获得了社区的普遍认同。因为其创始人 Antonio Juliano 在社交媒体明确表示:「dYdX V4 将完全开源,不会包含任何商业版权许可,任何人都可以根据需要自由使用对应代码。」
而另一边,同样是推出 V4 版本,Uniswap 的 V4 就引起了不少社区成员的反对,因为其宣布延续 V3 版本,实施 BSL。
在 BlockBeats 对 1inch 联合创始人 Anton Bukov 进行的专访中了解到,Anton 认为「MIT 许可允许任何人使用我们编写的代码做任何事情」,同时「商业许可可能会阻止一些公开团队或公平的竞争者进行分叉」。
相关阅读:《专访 1inch:Uniswap 垄断阴影下,如何在 DEX 领域创新?》
此外,在加密社区中也鲜有人喜欢 BSL。因为在选择许可证时,开发者通常会根据项目的需求和开发目标来权衡不同许可证的优缺点。风投公司 Lemniscap 成员 @stonecoldpat 0 曾对此做了非正式的民意调查,据社区投票显示, 76% 的人愿意选择 MIT 许可证。

在这个投票活动的评论中,OP Labs 研究员 @kelvinfichter 就针对开源代码的使用明确表示,选择什么许可证甚至不能算是一个问题,「你永远不会在 Optimism 存储库上获得商业源代码许可证。」

@kelvinfichter 认为,以太坊生态系统应该是自由和开放的,以便在每一步中竞争和创新。但商业源许可证是防御性的、非协作性的。它与以太坊的价值观不一致。「我认为这是一种心态,我不在乎有多少人想捍卫自己的私人商业利益,以太坊就是通过合作创造丰富。Optimism 永远是自由开源软件。」
为什么造一条 L2 的时间越来越短?
从抄袭、更改许可证这一事跳出来,可以看到的是,Blast 所代表的 L2 们正在「内卷」的道路上狂奔。纵观整个 L2 的发展趋势,老牌公链花费了大量的时间构建自己的技术堆栈、构建社区,而新生公链如雨后春笋般爆发的同时却直接「偷家」。
L2 最初的发展可谓非常艰难,最先跑出来的那一批主流 L2 中,Optimism 希望启动 Layer 2 就像今天将智能合约部署到以太坊一样简单。
Optimism 因此打造了 OP Stack,是一个可分叉模块化扩展区块链的基础设施,能让各类 Layer 2 整合成一个单一的超级链(Superchain),把原本相互孤立的 Layer 2 集成到一个具备互操作性和组合性的系统中,引领了「一键发链」叙事。本质上而言,超级链是一个可横向扩展的区块链网络,与各链之间共享以太坊的安全性、通信层以及开发套件。
相关阅读:《疯狂的多链宇宙,疯狂的 OP Stack》
在 OP Stack 后,其它主流 L2 如 Arbitrum、zkSync、Starknet、Polygon 也相继推出了 Stack 堆栈方案,试图将核心组件开源,并推进 RaaS 方案,而 Arbitrum Orbit 也又一次 RaaS 战争浪潮,模块化发展进一步加大了老牌 L2 的压力。
可以看出,尽管这些 L2 的愿景各不相同,但它们的核心都是定制化和应用特定的链,让加密行业的技术发展从「一键发币」升级迭代到「一键发链」,最终目标都是抢占 Layer 2 乃至 Layer 3 的战略高地。有趣的是,这些前辈的努力背后反而是便宜了后起之辈。新链的构建不仅在技术上被降低了准入门槛,甚至甚至还会被争抢,而老人们只能不断 PUA 自己,秉持着「抢到一个是一个」态度继续默默做开发。
对于新链来说,如果「一键发链」是站在巨人的肩膀上发展,那么像 Blast 这样直接「抄家」、甚至修改许可证,那可谓是对前人的「被刺」了。
虽然 Blast 和 Optimism 属于 op rollup 赛道的一员,但这并不意味它可以直接抄袭或删除 Optimism 的代码,各 rollup 都应该有自己独属的代码库。而新链的抄袭也显然不是一个新现象,曾经孙宇晨和 Vitalik Buterin 就关于公链代码抄袭的问题曾掀起过热烈讨论。
Blast 在诞生之初就给了 L2 们一记重拳,在极短的时间内达到名利双收,如今爆出代码抄袭而引得多位开发者「唏嘘」也不足为奇。面对这场风波,Blast 官方暂未表态,BlockBeats 将持续跟踪事件进展。





