原文作者:Cathie,Hyper Oracle
前期提要
Vitalik Buterin 的最新文章探讨了区块链和人工智能 (AI) 之间的交叉点,主要关注于如何将 AI 应用于加密世界,并探讨了四个交叉点: AI 作为参与者、AI 作为界面、AI 作为规则、以及 AI 作为目标。
文章讨论了在这些交叉点上的前景和挑战,强调了对抗性机器学习攻击和密码学开销的问题。 文章提到了使用零知识证明等密码学形式隐藏模型内部运作的可能性,同时指出了密码学开销和黑匣子对抗性机器学习攻击的挑战。
最后,文章讨论了创建可扩展的去中心化隐私 AI 的技术,并考虑了在 AI 安全和 AI 作为游戏目标方面的应用。 文章总结时强调了在这些领域中需要谨慎实践,但对于区块链和 AI 的交叉领域的前景表示期待。
0. 「Crypto + AI 应用前景和挑战」
在 Vitalik 的最新文章中,他讨论了人工智能与密码学的交叉,并提出了两个主要的挑战: 密码学开销和黑盒对抗性机器学习攻击。
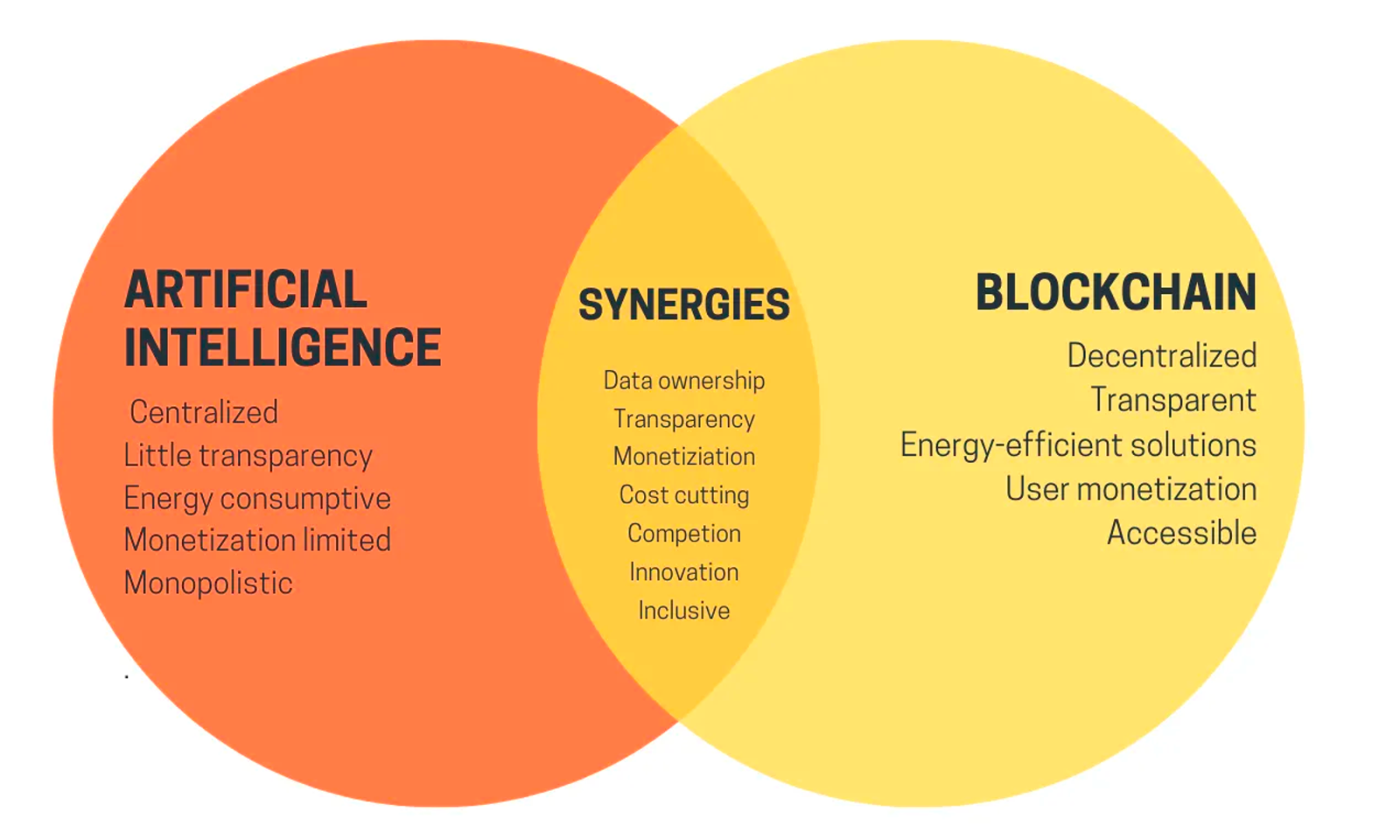
Vitalik 认为人工智能与加密货币方向大有可为。 在帮助加密货币变得更好的过程中,人工智能可以发挥关键作用,如作为「游戏界面」或「游戏规则」。
1. 挑战: 密码学开销
a) 密码学开销问题已经被解决?
虽然 Vitalik 认为 AI x Crypto 大有可为,但他指出,主要的反对意见之一是密码学开销。 目前最主流的链上 AI/ML 方法是 zkML,它将 ML 模型编译成 zk 电路,这样就可以在链上验证密码学证明。
「人工智能计算本来就很昂贵」,再加上密码学,速度就更慢了。
Vitalik 认为,密码学开销的问题已经得到了部分解决:
人工智能计算及其密码学开销适合高度加速,而且不像 zkEVM 那样存在「非结构化」计算类型。
随着时间的推移,更高效的 zk 密码学方案将会被发明出来,开销也会大大减少。
b) 目前,额外开销是 1000 倍。
然而,这种方法远远不够实用,尤其是对于 Vitalik 所描述的使用案例。 下面是一些相关的例子:
zkML 框架 EZKL 生成一个 1 M-nanoGPT 模型的证明大约需要 80 分钟。
根据 Modulus Labs 的说法,zkML 比纯计算的开销 >>1000 倍,最新报告的数字是 1000 倍。
根据 EZKL 的测试,RISC Zero 的随机森林分类平均证明时间为 173 秒。
在实践中,要等待几分钟才能得到 AI 所生成的交易的易读解释是不可接受的。
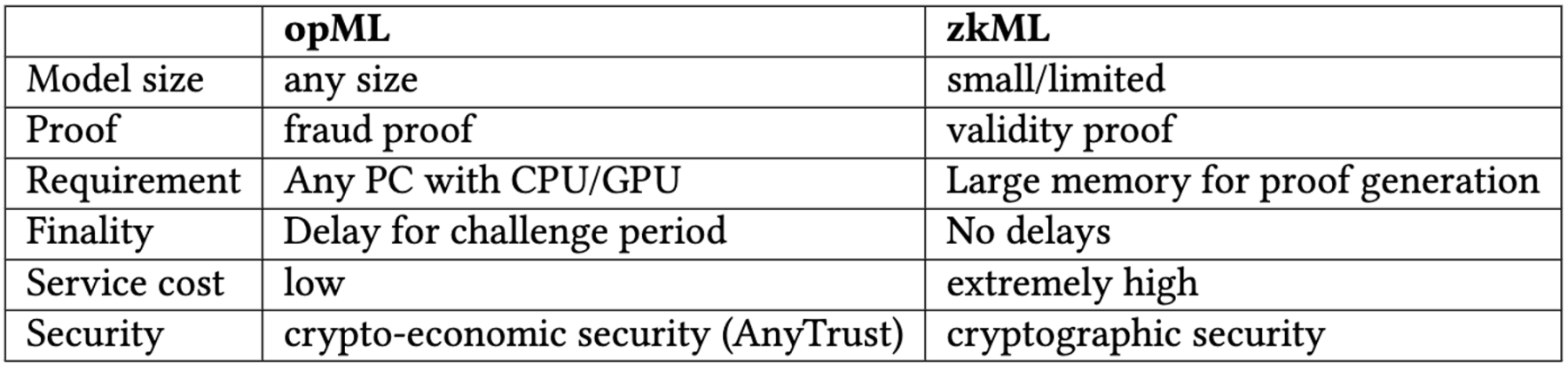
2. 通过 opML 解决
a) opML: Optimistic 机器学习
在文章的最后,Vitalik 提到:「我期待在所有这些领域看到更多人工智能建设性用例的尝试,这样我们就能看到其中哪些是真正可行的规模化应用。」我们认为,zkML 在现阶段并不「可行」,无法实现上述应用。
作为 opML 的发明者和 opML 的首个开源实现的创建者,我们相信,opML 可以通过博弈论解决密码学开销问题,让人工智能 x Crypto 现在就能实现。
b) 通过激励措施实现安全性
opML 在保证安全性的同时,解决了链上 ML 的密码学开销问题。 为了简单起见,我们可以使用 Arbitrum 的 AnyTrust 假设来评估 opML 系统的安全性。
AnyTrust 假设每个主张至少有一个诚实节点,确保提交者或至少一个验证者是诚实的。 在 AnyTrust 下,安全性和有效性得以保持:
安全性: 一个诚实的验证者可以通过质疑恶意节点的错误结果来强制执行正确的行为,从而通过仲裁程序进行惩罚。
有效性: 提议的结果要么在最长期限内被接受,要么被拒绝。
比较「AnyTrust」和「Majority Trust」,opML 的「AnyTrust」 模型更安全。「AnyTrust」 保持了很高的安全性,在各种条件下都优于「Majority Trust」。
c) 用户隐私 > 模型隐私
Vitalik 在文章中还谈到了模型隐私问题。 事实上,对于大多数模型 ( 尤其是 zkML 目前在实践中支持的小型模型 ),都可以通过足够的推理来重建模型。
对于一般隐私,尤其是用户隐私,由于需要保持挑战的公开性,opML 似乎缺乏固有的隐私功能。 通过结合 zkML 和 opML,我们可以获得恰到好处的隐私级别,确保安全和不可逆转的混淆。
d) 实现 AI x Crypto 用例
opML 已经可以直接在以太坊上运行 Stable Diffusion 和 LLaMA 2 。 Vitalik 提到的四个类别 ( 人工智能作为玩家 / 界面 / 规则 / 目标 ) 已经可以通过 opML 实现,而且没有任何额外开销。
我们正在积极探索以下用例和方向:
AIGC NFT (ERC-7007), 7007 Studio 在 Story Protocol Hackathon 中获胜
链上人工智能游戏 ( 如龙与地下城游戏 )
使用 ML 的预测市场
内容真实性 (Deepfake 验证器 )
合规的可编程隐私
Prompt 市场
信誉 / 信用评分
3. 总结
有了 opML,我们就能消除密码学开销带来的挑战,保留去中心化和可验证性,让 AI x Crypto 现在就变得可行。





