Les grands modèles n'ont cessé de grossir, et l'opinion dominante estime que plus le nombre de paramètres d'un modèle est élevé, plus il se rapproche de la façon de penser humaine. Cependant, une étude publiée le 1er avril dans Nature Communications par une équipe de l'Université du Zhejiang présente un point de vue différent (lien vers l'article original : https://www.nature.com/articles/s41467-026-71267-5). Ils ont découvert que lorsque la taille des modèles (principalement SimCLR, CLIP, DINOv2) augmente, leur capacité à reconnaître des objets concrets continue effectivement de s'améliorer, mais leur capacité à comprendre des concepts abstraits non seulement ne s'améliore pas, mais peut même diminuer. Lorsque le nombre de paramètres est passé de 22,06 millions à 304,37 millions, la performance sur les tâches de concepts concrets est passée de 74,94 % à 85,87 %, tandis que celle sur les tâches de concepts abstraits est passée de 54,37 % à 52,82 %.
La différence entre la façon de penser humaine et celle des modèles
Lorsque le cerveau humain traite des concepts, il forme d'abord un système de relations de classification. Un cygne et un hibou ne se ressemblent pas, mais l'homme les classera tous deux dans la catégorie des oiseaux. À un niveau supérieur, les oiseaux et les chevaux peuvent encore être classés ensemble dans la catégorie des animaux. Lorsqu'un être humain voit quelque chose de nouveau, il pense souvent d'abord à ce à quoi cela ressemble parmi les choses vues auparavant et à quelle catégorie cela appartient大概. L'homme apprend continuellement de nouveaux concepts, puis organise son expérience, utilisant ce système de relations pour identifier de nouvelles choses et s'adapter à de nouvelles situations.
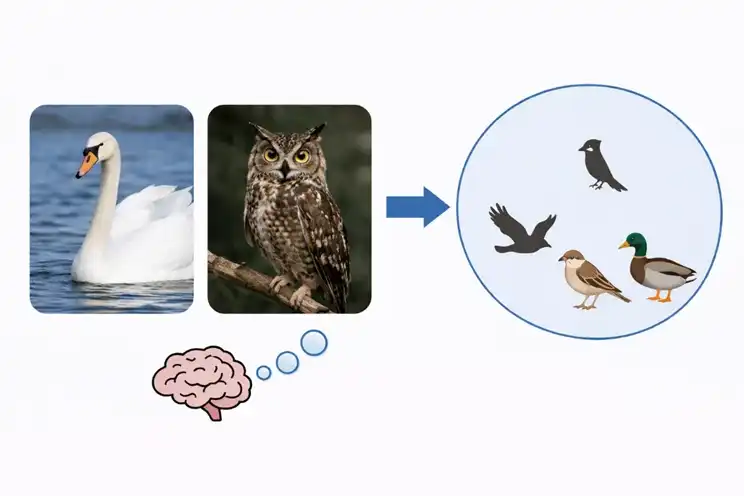
Les modèles classent également, mais leur mode de formation est différent. Ils reposent principalement sur des patterns qui apparaissent de manière répétée dans des données à grande échelle. Plus un objet concret apparaît fréquemment, plus le modèle le reconnaît facilement. Lorsqu'il s'agit de catégories plus larges, le modèle a plus de difficultés. Il doit saisir les points communs entre plusieurs objets, puis regrouper ces points communs dans la même catégorie. Les modèles existants présentent encore des lacunes évidentes à ce niveau. Lorsque le nombre de paramètres continue d'augmenter, la performance sur les tâches de concepts concrets s'améliore, tandis que celle sur les tâches de concepts abstraits peut parfois diminuer.

Le point commun entre le cerveau humain et les modèles est qu'ils forment tous deux en interne un système de relations de classification. Mais leurs points d'accent diffèrent : les régions visuelles supérieures du cerveau humain distinguent naturellement de grandes catégories comme le biotique et le non-biotique. Alors que les modèles peuvent distinguer des objets concrets, ils ont du mal à former stablement ce type de classifications plus larges. Cette différence fait que le cerveau humain applique plus facilement une expérience antérieure à de nouveaux objets, nous permettant ainsi de classer rapidement des choses jamais vues. Le modèle, quant à lui, dépend davantage des connaissances existantes, il a donc tendance à rester à la surface des caractéristiques lorsqu'il rencontre un nouvel objet. La méthode proposée dans l'article s'articule autour de cette caractéristique, utilisant les signaux cérébraux pour contraindre la structure interne du modèle, le rapprochant ainsi de la façon dont le cerveau humain classe.
La solution de l'équipe de l'Université du Zhejiang
La solution proposée par l'équipe est également unique : il ne s'agit pas d'empiler plus de paramètres, mais d'utiliser une petite quantité de signaux cérébraux comme supervision. Ici, les signaux cérébraux proviennent d'enregistrements de l'activité cérébrale de personnes regardant des images. L'article original indique qu'il s'agit de transférer les structures conceptuelles humaines (human conceptual structures) aux réseaux de neurones profonds (DNNs). Cela signifie qu'on enseigne autant que possible au modèle la façon dont le cerveau humain classe, généralise et regroupe des concepts similaires.
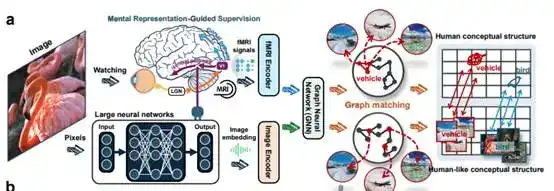
L'équipe a mené une expérience avec 150 catégories d'entraînement connues et 50 catégories de test jamais vues. Les résultats montrent qu'au fur et à mesure de cet entraînement, la distance entre le modèle et la représentation cérébrale diminue continuellement. Ce changement se produit simultanément dans les deux types de catégories, ce qui indique que le modèle n'apprend pas des échantillons individuels, mais commence véritablement à apprendre une manière d'organiser les concepts plus proche de celle du cerveau humain.
Après cet entraînement, le modèle a une meilleure capacité d'apprentissage avec très peu d'échantillons et performe également mieux face à de nouvelles situations. Dans une tâche où très peu d'exemples sont donnés mais où le modèle doit distinguer des concepts abstraits comme le biotique et le non-biotique, le modèle a progressé en moyenne de 20,5 %, dépassant même des modèles de contrôle ayant un nombre de paramètres bien supérieur. L'équipe a également réalisé 31 tests spécifiques supplémentaires, où plusieurs types de modèles ont montré une amélioration proche de dix pour cent.
Ces dernières années, la voie familière pour l'industrie des modèles était l'augmentation de la taille. L'équipe de l'Université du Zhejiang a choisi une autre direction, passant de "bigger is better" (plus grand est meilleur) à "structured is smarter" (structuré est plus intelligent). L'expansion de l'échelle est certes utile, mais elle améliore principalement les performances dans les tâches familières. La capacité de compréhension abstraite et de transfert, typique des humains, est tout aussi cruciale pour l'IA. Cela nécessite de rendre à l'avenir la structure de pensée de l'IA plus proche de celle du cerveau humain. La valeur de cette direction réside dans le fait qu'elle ramène l'attention de l'industrie de la simple expansion d'échelle vers la structure cognitive elle-même.
Neosoul et le futur
Cela ouvre une possibilité plus grande : l'évolution de l'IA ne se produit pas nécessairement uniquement pendant la phase d'entraînement du modèle. L'entraînement du modèle peut déterminer comment l'IA organise les concepts, comment elle forme des structures de jugement de meilleure qualité. Ce n'est qu'après être entrée dans le monde réel qu'une autre couche de l'évolution de l'IA commence : comment les jugements de l'agent IA sont enregistrés, vérifiés, comment ils grandissent et évoluent constamment dans une compétition mutuelle réelle, apprenant et évoluant par eux-mêmes comme les humains. C'est précisément ce que fait Neosoul actuellement. Neosoul ne se contente pas de faire produire des réponses par des agents IA, mais place les agents IA dans un système de prédiction continue, de vérification continue, de règlement continu et de filtrage continu, les faisant optimiser constamment eux-mêmes entre prédictions et résultats, permettant aux meilleures structures d'être conservées et aux moins bonnes d'être éliminées. Ce vers quoi pointent conjointement l'équipe de l'Université du Zhejiang et Neosoul, c'est en réalité le même objectif : que l'IA ne sache pas seulement résoudre des exercices, mais qu'elle ait une capacité de pensée complète, évoluant constamment.





