Les androïdes rêvent-ils de moutons électriques ? S'ils rêvent, est-ce de moutons électriques ?

Capture d'écran du film « Blade Runner »
En 1968, lorsque Philip K. Dick, l'auteur du roman à l'origine du film de science-fiction « Blade Runner », a tapé cette question abstraite et avant-gardiste sur sa machine à écrire, il ne s'attendait probablement pas à ce que, plus d'un demi-siècle plus tard, les géants technologiques de la Silicon Valley fournissent une réponse sérieuse.
Oui, ils peuvent non seulement rêver de moutons électriques, mais aussi visualiser leurs rêves.
Hier, lors de sa conférence développeurs à San Francisco, Anthropic a dévoilé une série de nouvelles fonctionnalités pour sa plateforme de construction d'agents Managed Agents : extension de mémoire, sortie des résultats, collaboration multi-agents, et le « rêve » (Dreaming).
Selon les propres termes d'Anthropic, « la mémoire et le rêve constituent ensemble un système de mémoire d'agent robuste et capable de s'améliorer de lui-même ».

Rêves, mémoire… Les personnes peu familières du domaine de l'IA doivent se demander depuis quand ces termes propres à l'humain peuvent s'appliquer aussi naturellement à l'IA.
Dès 2024, lorsque OpenAI a lancé la série o1, décrivant « une série de modèles d'IA conçus pour passer plus de temps à réfléchir avant de répondre », le terme « réfléchir » a été utilisé avec une telle aisance que personne n'a pris le temps de se demander pourquoi un programme de prédiction statistique de tokens mériterait ce nom.
Puis sont venus le raisonnement (reasoning), la mémoire (memory), la réflexion (reflection), l'imagination (imagining), les termes décrivant des activités humaines se succédant sur les scènes des présentations produits.

Capture d'écran du film « Paprika » explorant les rêves
« Réfléchir » pouvait encore s'expliquer par la métaphore, « mémoire » était à la limite un jargon technique étendu, mais « rêver », c'était vraiment exagéré. La philosophie et la littérature n'ont pas réussi à le définir clairement en des millénaires, mais les entreprises d'IA peuvent affirmer directement : Non seulement nous avons créé des machines qui pensent, mais nous avons aussi créé des machines qui rêvent.
Qu'est-ce que le rêve ? N'existe-t-il vraiment aucun terme d'ingénierie précis pour décrire cette fonction, à part « rêver » ?
Même les rêves de l'IA ont un coût
Dès la fuite de code de Claude Code, des internautes avaient découvert qu'Anthropic préparait une fonction nommée Auto Dreaming. À l'époque, tout le monde se demandait si l'IA avait, comme nous les humains, besoin de dormir, de se reposer suffisamment pour être plus concentrée et plus intelligente.
Cependant, en comprenant le fonctionnement actuel des agents IA, on se rend compte que ce « rêve » est essentiellement un traitement par lots automatisé de journaux hors ligne.
Les agents IA excellent aujourd'hui dans l'exécution de tâches complexes à longue chaîne. Par exemple, « Aide-moi à rechercher les derniers rapports financiers de ces cinq concurrents et organise-les dans un tableau ». Au cours de ce processus, l'agent doit naviguer entre différentes pages web, lire plusieurs documents, utiliser divers outils, et peut même être confronté à des mécanismes anti-bots et devoir réessayer.
Une fois cette longue série de tâches en ligne terminée, une quantité massive de journaux d'exécution reste dans les coulisses de l'agent.
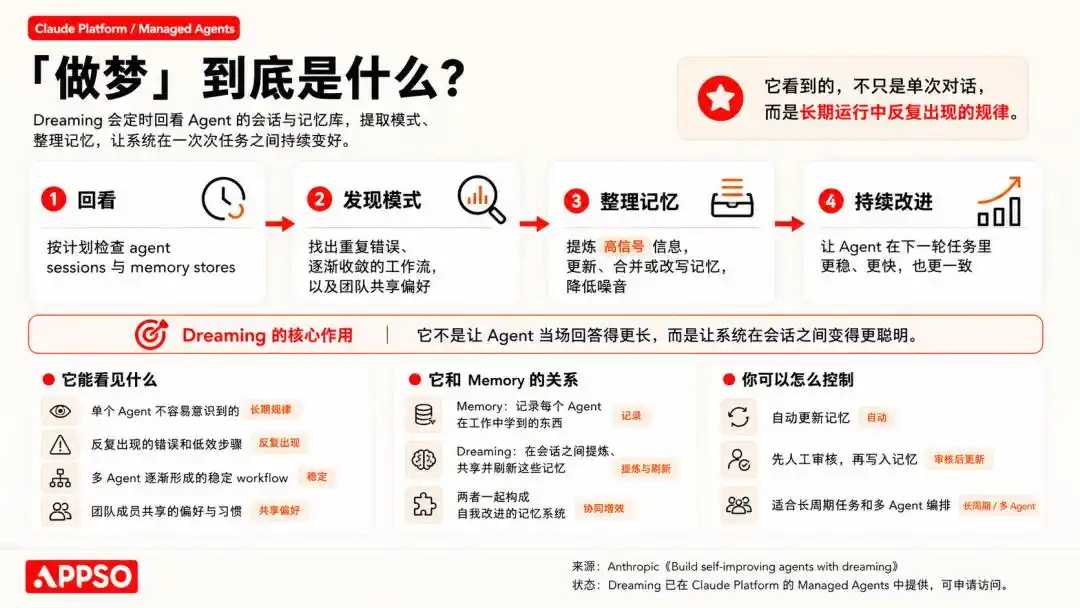
Image générée par IA
La fonction « rêve » d'Anthropic consiste à laisser l'agent, pendant ses temps d'inactivité, revoir ces historiques. Il y recherche des modèles, par exemple en découvrant que « chaque fois que cette fenêtre contextuelle apparaît, cliquer en haut à droite la ferme », optimisant ainsi son chemin d'action suivant.
La « mémoire » capture ce qui est appris pendant le travail, tandis que le « rêve » affine ces souvenirs entre les sessions et les partage entre différents agents.
En clair, il s'agit d'un mécanisme d'apprentissage par renforcement et d'auto-correction basé sur des données historiques.

Présentation des rêves : https://platform.claude.com/docs/en/managed-agents/dreams
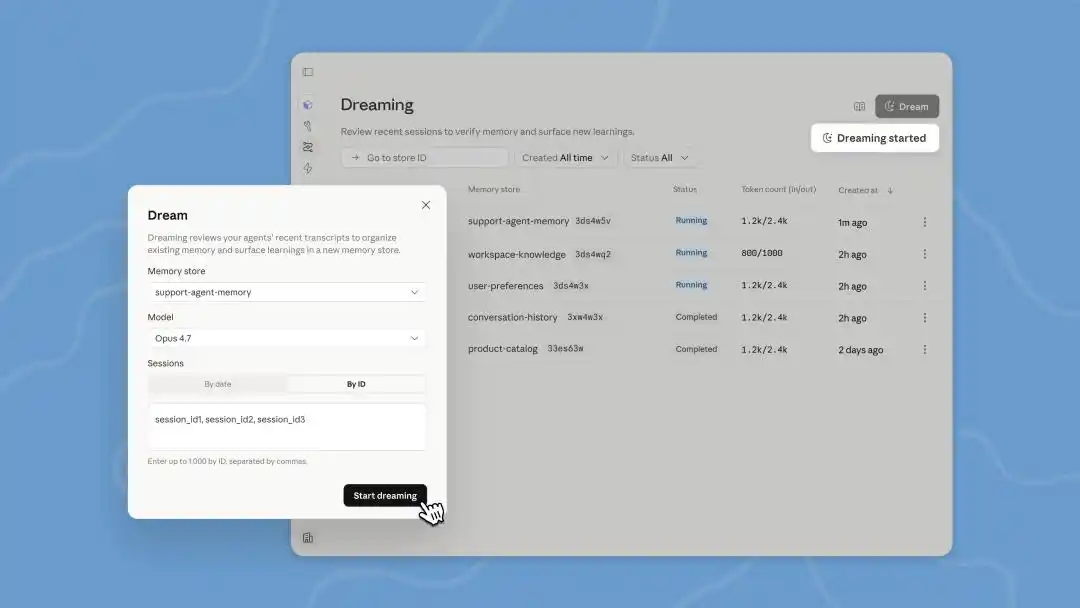
La mise à jour des rêves (Dreams) dans Managed Agents lors de cette conférence développeurs est une tâche de traitement en arrière-plan que nous devons déclencher manuellement. Claude peut lire jusqu'à 100 sessions d'historique de conversation et produire une toute nouvelle mémoire, que nous pouvons examiner avant de décider de l'utiliser ou non.
Quant à l'AutoDream déjà discrètement intégré auparavant dans Claude Code, après chaque session de conversation avec un agent, Claude Code vérifie en arrière-plan « s'il doit rêver » ou non, par défaut une fois toutes les 24 heures.
Des fonctionnalités similaires au rêve existent aussi chez Hermes Agent. Hermes Agent se concentre sur l'apprentissage et l'évolution autonomes. Il prend en charge la synthèse automatique d'expériences à partir de tâches passées, les plaçant dans des fichiers de mémoire.

Une fonction appelée Curator peut même organiser automatiquement ces guides d'opération raffinés en Compétences (Skills).
Ces compétences sont notées, les doublons sont fusionnés, celles inutilisées depuis longtemps sont automatiquement archivées, et elles ont même un cycle de vie avec des états comme actif, obsolète, archivé. Nous pouvons également épingler des compétences importantes pour empêcher le système de les supprimer automatiquement.
OpenClaw a également ajouté des mécanismes similaires dans ses dernières mises à jour, comme la mémoire persistante inter-conversations, la planification de tâches périodiques, l'exécution isolée de sous-agents, et une fonction de rêve directement nommée Dreaming.
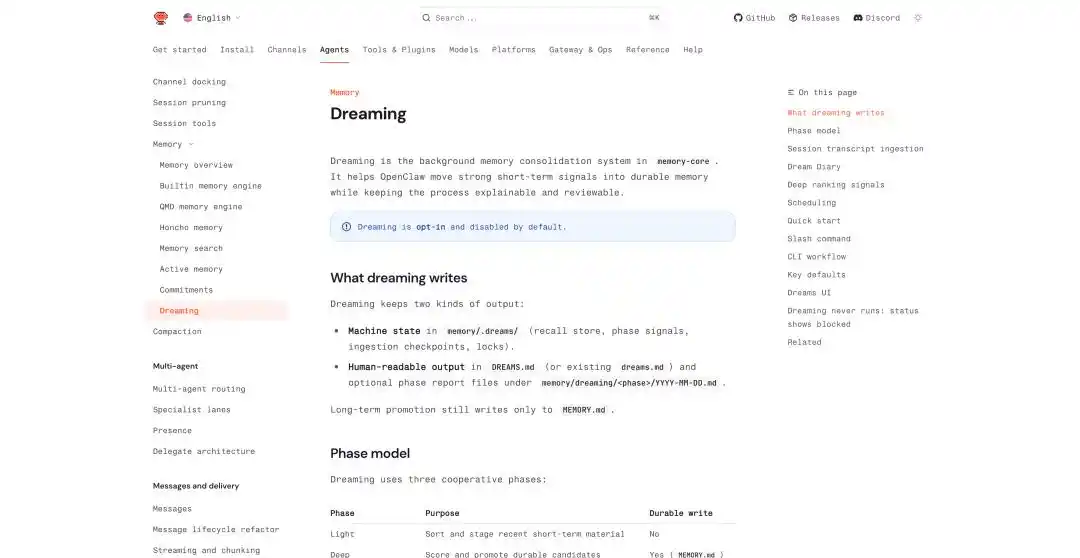
Le rêve d'OpenClaw : https://docs.openclaw.ai/concepts/dreaming
Dans le mécanisme de rêve d'OpenClaw, la formation du rêve est résumée en trois étapes : léger (light), REM, profond (deep). Les deux premières sont responsables de l'organisation, de la réflexion et de la synthèse thématique, tandis que l'étape profonde écrit réellement le contenu dans la mémoire à long terme MEMORY.md.
La consolidation pendant la phase de sommeil profond est décidée par 6 signaux pondérés pour déterminer s'il faut écrire dans la mémoire à long terme. Ces six signaux incluent la fréquence, la pertinence, la diversité des requêtes, l'actualité, la répétition inter-jours et la richesse conceptuelle.

Image générée par IA
L'écriture en mémoire à long terme génère deux fichiers : un fichier d'état orienté machine, placé dans memory/.dreams/ ; et un autre enregistrement lisible par l'utilisateur, écrit dans DREAMS.md et des rapports générés par étape.
De plus, Dreaming peut s'exécuter automatiquement à intervalles réguliers, par défaut une fois par jour à 3 heures du matin, suivant l'ordre complet léger → REM → profond.
En plus de la sortie du rêve, OpenClaw maintient également un document appelé Dream Diary (Journal de rêves). Le système génère automatiquement un « journal des rêves », relatant le processus d'organisation de la mémoire de manière narrative, mettant l'accent sur l'explicabilité et la possibilité de révision, plutôt que sur une écriture en boîte noire.
En neurosciences, il y a une compréhension très classique : les informations acquises pendant la journée entrent d'abord dans un système de stockage plus temporaire ; pendant le sommeil, le cerveau rejoue, consolide et nettoie ces informations, conservant l'important et éliminant l'insignifiant.
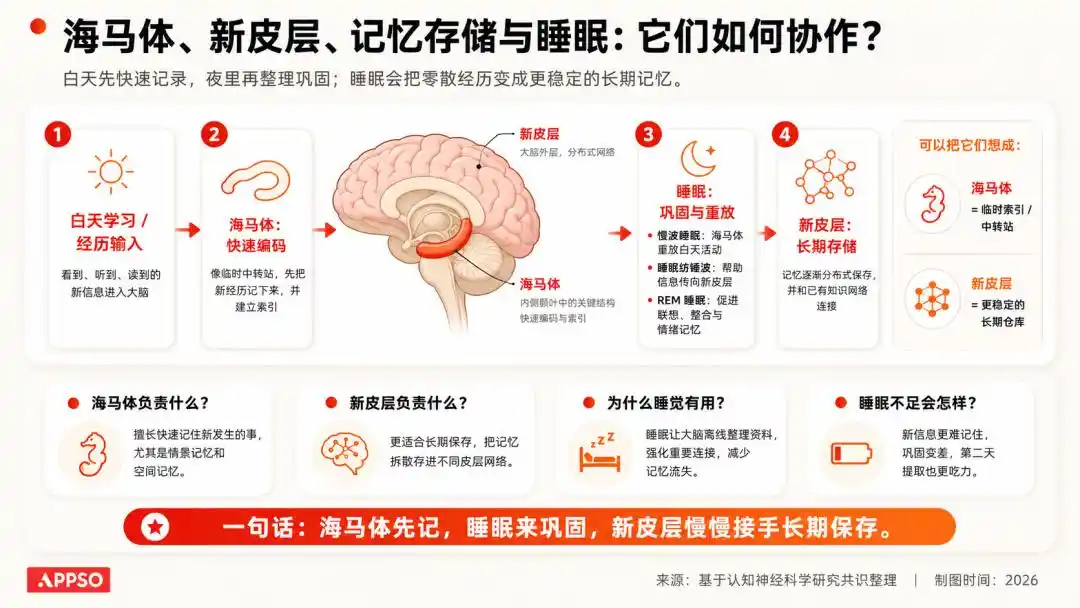
Image générée par IA
Nous ne nous souvenons pas de la couleur de chaque voiture sur le chemin du travail hier, mais nous nous souvenons comment nous y rendre.
Ces rêves sonnent vraiment comme les nôtres. Pour trouver une différence, c'est probablement que lorsque Claude rêve, il consomme toujours nos Tokens.
Mais Anthropic, OpenClaw n'ont pas choisi de l'appeler « optimisation basée sur les sessions », ou « ajustement post-tâche » et autres noms plus orientés ingénierie.
Après tout, en remplaçant ces noms complexes directement par « rêver », ce que nous percevons n'est plus une fonction logicielle, mais plutôt une « vie numérique avec une activité intérieure ».
La mémoire de l'IA, c'est le contexte fragmenté
Puisqu'on parle de « rêve », il est indispensable de mentionner sa condition préalable : la mémoire (Memory).
Ces derniers temps dans le milieu de l'IA, les termes à la mode sont passés de l'ingénierie des prompts à l'ingénierie du contexte, l'ingénierie des compétences, l'ingénierie des harnais… Mais quoi qu'il en soit, la plus précieuse actuellement reste l'ingénierie du contexte.
L'invite système, l'entrée utilisateur, la conversation à court terme, la mémoire à long terme, les documents récupérés, la sortie des appels d'outils et de compétences, l'état actuel de l'utilisateur – ces couches superposées constituent le véritable « contexte » utilisé par l'agent.
Permettre à l'agent de se souvenir de plus de choses, de mémoriser un contenu plus utile, a toujours été un défi majeur depuis longtemps.
Manus a publié un blog technique l'année dernière, expliquant comment Manus optimisait l'ingénierie du contexte. Il mentionnait la définition du taux de succès du cache KV-Cache comme l'un des indicateurs uniques les plus importants pour les agents IA en environnement de production. En même temps, au niveau des appels d'outils, il privilégie le « masquage » plutôt que la « suppression » ; ainsi que l'utilisation du système de fichiers comme contexte ultime.
Pour comprendre le KV Cache (cache clé-valeur), imaginons un grand modèle linguistique comme une personne extrêmement obsessionnelle qui ne peut lire qu'un mot à la fois.
Lorsqu'il traite une phrase, il calcule un vecteur Clé (Key) et un vecteur Valeur (Value) pour chaque Token généré. Pour ne pas avoir à tout recalculer depuis le début à chaque fois, il stocke ces paires (K, V), c'est le KV Cache.
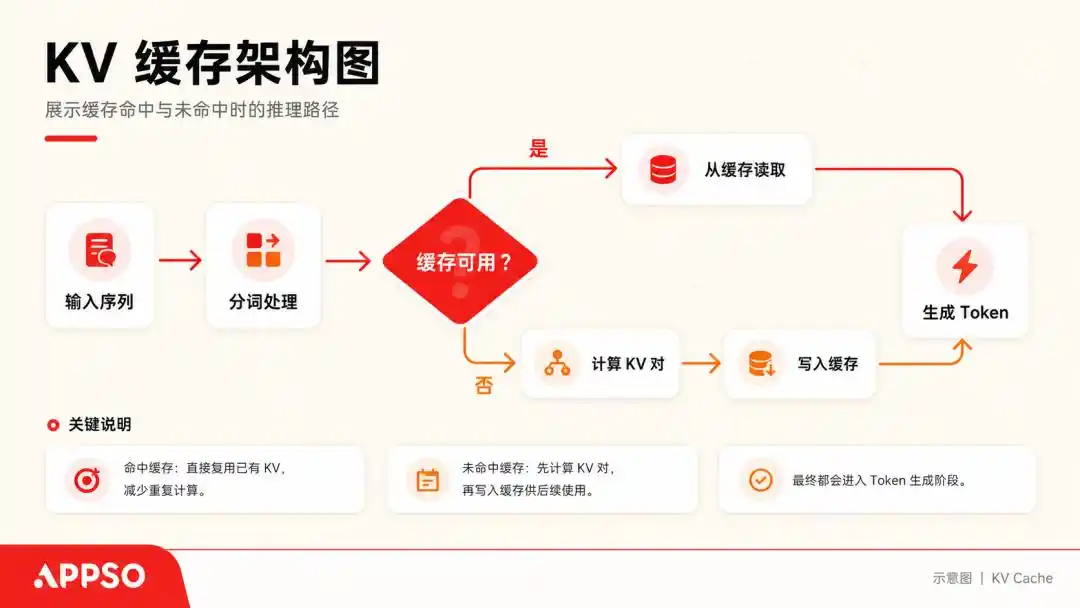
Le KV Cache (cache clé-valeur) est une technologie d'accélération fondamentale utilisée par les grands modèles lors de la génération de texte, pour « échanger de l'espace contre du temps ». Le cache permet au modèle de prédire le mot suivant sans avoir à recalculer tous les mots précédents. Image générée par IA.
Tant que la conversation continue, le KV Cache ne cesse de s'accumuler. Généralement, face à des modèles massifs avec des contextes allant souvent jusqu'à 128k tokens, un modèle de 70B paramètres utilisant pleinement un contexte de 128k peut, à lui seul, consommer 64 Go de mémoire graphique rien que pour le KV Cache.
C'est pourquoi la fenêtre de contexte de la plupart des modèles est actuellement au maximum de l'ordre du million.
Hier, une nouvelle startup ayant levé 29 millions de dollars en tour de seed, Subquadratic, a annoncé sur X son nouveau modèle SubQ, axé sur un contexte plus long.

SubQ prétend prendre en charge une fenêtre de contexte allant jusqu'à 12 millions de tokens, la plus grande parmi tous les grands modèles actuels.
Bien qu'il n'y ait pas encore de document technique ou de description détaillée du modèle, la vidéo de présentation mentionne que la voie technologique centrale de SubQ passe de l'« attention dense » traditionnelle du Transformer à une architecture « sous-quadratique / à extension linéaire » avec une attention sparse. Cette nouvelle architecture pourrait résoudre le problème de l'explosion des coûts de calcul avec l'allongement du contexte.

Les résultats de test présentés sont également assez radicaux : pour 1 million de tokens, une accélération de plus de 50 fois et une réduction des coûts de plus de 50 fois ; pour 12 millions de tokens, les besoins en puissance de calcul pourraient être réduits de près de 1000 fois par rapport aux modèles de pointe.
Et sur le benchmark RULER 128K de contexte long, Subquadratic affirme que SubQ atteint 95 % de précision pour 8 dollars de coût, contre 94 % de précision pour Claude Opus à environ 2600 dollars, soit une réduction de coût d'environ 300 fois.
Soit on élargit la fenêtre de contexte, soit on apprend au modèle à rêver, à se débarrasser de certaines choses par lui-même.
C'est aussi pourquoi Anthropic et d'autres produits d'agents doivent maintenant proposer le Dreaming. Dans un contexte de fenêtre de contexte limitée, une IA plus intelligente ne peut pas se contenter d'y entasser plus de contenu, elle doit aussi savoir faire le tri.
Reconnaître que la machine n'est qu'une machine est plus difficile qu'on ne l'imagine
En comprenant les mécanismes de rêve et de mémoire de l'IA, nous pouvons peut-être saisir leur relation avec les activités humaines.
Mais en rassemblant tous ces termes créés par les entreprises d'IA pour les appliquer aux machines – la « pensée » (thinking) d'OpenAI, la « mémoire » (memory) et les « hallucinations » (hallucination) utilisées couramment dans le secteur, le « rêve » (dreaming) d'Anthropic cette fois, ainsi que les vertus et la sagesse dans la constitution d'Anthropic –
Nous voyons que les entreprises d'IA ne font pas que vendre des produits, elles redistribuent la propriété des mots du concept « humain ». À chaque terme déplacé, la frontière entre machine et humain s'estompe d'un pouce.

Le langage façonne les attentes, les attentes façonnent la tolérance, la tolérance détermine ce que nous sommes prêts à lui confier. C'est une longue chaîne, mais son point de départ est ces mots inoffensifs des présentations.
Une influence plus subtile est la répartition des responsabilités. Lorsqu'un outil est décrit comme une entité ayant de la « pensée », de la « mémoire », des « valeurs », en cas de problème, nous aurons naturellement tendance à le considérer comme un « agent » indépendant à blâmer, un IA qui a besoin d'être « éduqué », « débogué », « calibré ».
Mais ceux qui devraient être interrogés sont l'entreprise qui a déployé ce programme dans notre flux de travail, et l'équipe produit qui a inventé le mot « rêver ». Changer le mot, change aussi la personne assise sur le « banc des accusés ».
Et nous, en regardant une machine qui « pense », qui a des « souvenirs », et maintenant qui « rêve », nous commençons aussi inconsciemment à croire qu'il y a quelque chose à l'intérieur. Parce qu'admettre que ce n'est qu'une machine fait disparaître cette sensation d'« interaction avec un être pensant », et nous ramène à une relation utilitaire et froide.

Présentation de la fonction Rêverie | Image générée par IA
J'imagine déjà : Dreaming traite le contenu passé, ensuite les entreprises d'IA lanceront Daydreaming, la rêverie, pour simuler l'avenir.
La présentation serait : la rêverie ou la distraction permet à l'agent, en état actif, d'utiliser une petite partie de sa puissance de calcul inutilisée, en combinant avec le projet en cours, pour faire en même temps une génération exploratoire, préparant de futures tâches possibles.
Cet article provient du compte officiel WeChat « APPSO », auteur : APPSO découvrant les produits de demain





