Par | Xiang Xianzhi
Luo Fuli a publié un message sur X, mettant un point final à la polémique sur la baisse de prix de MiMo.
Le 26 mai, le compte officiel Xiaomi MiMo sur X a posté une annonce : les API de la série MiMo-V2.5 sont définitivement réduites, avec une baisse maximale de 99%. Tarification unifiée pour toutes les longueurs de contexte, et les forfaits Token sont mis à niveau de 5 à 8 fois.
Cette annonce a fait le buzz pendant une semaine dans le milieu chinois de l'IA. Les premières réactions de l'industrie se sont divisées en plusieurs tendances. La plus importante affirme qu'il s'agit d'"une nouvelle guerre des prix" – ces deux dernières années, des modèles chinois comme ZhiPu, DeepSeek, Byte's Doubao et Alibaba's Tongyi se sont succédé pour baisser leurs prix, tout le monde joue le jeu.
Une autre tendance a une vision plus pessimiste : Xiaomi vient d'annoncer que ses bénéfices ont été divisés par deux cette année, et maintenant elle investit 600 milliards dans l'IA tout en baissant ses API de 90% – un cas typique de "conquête de marché à perte". D'autres encore y voient la continuation de l'effet DeepSeek – ce dernier a tiré le prix de référence de toute l'industrie vers le bas, celui qui ne suit pas est éliminé.
C'est pourquoi Luo Fuli, responsable de MiMo, a directement publié hier soir un article technique de 5000 mots, exposant à tous le calcul d'ingénierie derrière la baisse de prix.
"Regardez, c'est une véritable capacité d'ingénierie, pas un coup marketing".
Pour comprendre ce que dit Luo Fili, il faut d'abord savoir sur quoi porte exactement cette baisse de 99%.
Ce n'est pas une réduction sur l'ensemble du modèle. La remise de 99% concerne spécifiquement une catégorie de tarification appelée Input (Cache Hit) – c'est-à-dire la partie où "l'utilisateur relit le contexte historique répété dans une conversation longue". La baisse pour les nouvelles entrées normales (No Cache Hit) est beaucoup plus faible, et la plus petite réduction concerne la sortie du modèle (Output).
Si vous imaginez le modèle comme un café, c'est plus facile à comprendre.
Vous commandez un latte demi-sucré. Le café a deux façons de faire : moudre les grains, mesurer le sirop, verser le lait à chaque fois, payant pour les ingrédients et la main-d'œuvre à chaque commande ; mais le modèle sait que vous voulez le même latte demi-sucré tous les jours cette semaine, alors il en prépare une grande quantité qu'il met au réfrigérateur, et la prochaine fois, il en sert une portion. Ce que MiMo a fait cette fois-ci, c'est la seconde option – transformer la partie "relecture répétée" de l'utilisateur de "calculée sur place" en "récupérée sur place", donc le coût réel de cette partie est proche de 0, permettant naturellement une remise de 99%.
Pour réaliser cette "récupération sur place", l'article technique présente six travaux d'ingénierie, chacun étant indispensable. Détaillons-les un par un.
Travail d'ingénierie n°1 : Compresser la "mémoire" du modèle à 1/7
Lorsque le modèle dialogue avec vous, chaque token doit calculer un "état intermédiaire", stocké pour être utilisé à l'étape suivante. Cette chose s'appelle KVCache – on peut la comprendre comme le "carnet de notes de mémoire à court terme" du modèle. À chaque phrase prononcée, le modèle note un résumé de cette phrase dans son carnet, et la fois suivante, il consulte directement ses notes, sans avoir à réécouter tout ce que vous avez dit depuis le début.
Les modèles traditionnels font une "Full Attention" à chaque couche – c'est-à-dire que chaque token doit examiner tous les tokens de la conversation entière, le carnet de notes s'épaississant de plus en plus. MiMo-V2.5-Pro a modifié l'architecture : sur 70 couches, 60 couches ne regardent que les 128 derniers tokens (SWA, Sliding Window Attention), et seules 10 couches "archivistes" voient tout.
Le résultat est que le volume de KVCache est directement compressé à 1/7 de celui de Full Attention, et la quantité de calcul est également réduite à 1/7.
C'est la première fondation de la réduction des coûts. Pour faire une analogie, à l'origine, chaque employé de l'entreprise devait se souvenir de tous les procès-verbaux de réunion, mais le cerveau de chacun était saturé et l'efficacité faible. La nouvelle règle réduit la charge mentale de 60 employés à 1/7, ne laissant que 10 archivistes gérer toute l'histoire – la capacité de mémoire globale de l'entreprise n'a pas diminué, mais l'efficacité a été multipliée par 7.
Travail d'ingénierie n°2 : Permettre à l'espace économisé par SWA d'être réellement utilisable
Compresser le carnet de notes à 1/7 au niveau de l'architecture est la première étape, mais pour transformer le "1/7 théorique" en "1/7 réel", il y a un obstacle.
Les systèmes KVCache traditionnels allouent de la mémoire vidéo (VRAM) de manière uniforme à toutes les couches en fonction de "l'utilisation maximale possible". Cela signifie : même si les 60 couches SWA n'ont besoin que d'un petit carnet, le système alloue à toutes les couches en fonction du "grand carnet de l'archiviste" – l'espace économisé par SWA est réservé inutilement, ce qui équivaut à ne rien économiser.
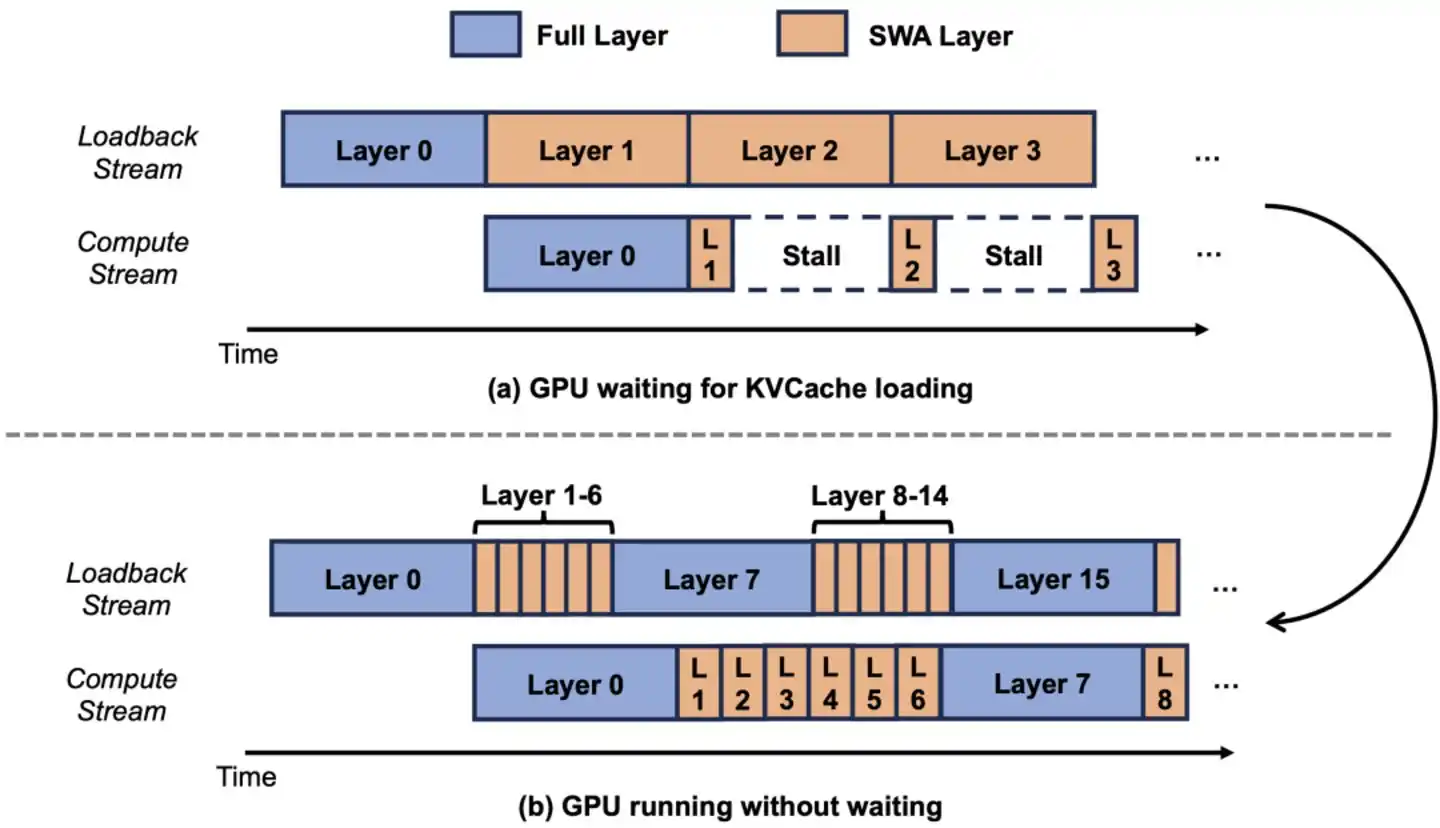
L'approche de l'équipe de Luo Fuli consiste à diviser le KVCache en deux pools indépendants. Les 10 couches de Full Attention utilisent le "grand pool", alloué en fonction de la longueur totale ; les 60 couches SWA utilisent le "petit pool", alloué uniquement en fonction de la fenêtre de 128 tokens.
Pour reprendre l'analogie, à l'origine, l'entreprise donnait à chaque employé un "armoire à archives pouvant contenir 100 ans de documents" – mais 60 employés n'avaient en réalité besoin que d'"une petite armoire contenant une semaine de documents", et 99% de l'espace dans ces grandes armoires était vide. La nouvelle approche consiste à attribuer des armoires en fonction des besoins réels. Résultat, tout le bureau peut accueillir plus de 5 fois plus de collègues pour travailler – le même GPU peut servir un nombre d'utilisateurs simultanés multiplié par 5.
Cette étape semble simple, mais sans elle, l'avantage de l'architecture SWA conçue précédemment serait vain.
Travail d'ingénierie n°3 : Permettre aux "relectures répétées des utilisateurs réguliers" de réellement toucher le cache
Carnet de notes compressé à 1/7 + espace réellement utilisable, l'étape suivante consiste à résoudre un vieux problème : le taux de succès du cache de préfixe.
De nombreuses conversations d'utilisateurs commencent de la même manière – le même prompt système, la même base de code, le même long document. Le système stocke les résultats déjà calculés de ces débuts, et les réutilise directement lors de la correspondance suivante. Ce mécanisme s'appelle le cache de préfixe.
Mais un problème survient en mode SWA : deux requêtes ayant les mêmes tokens ne signifient pas que les KV sont encore présents. Le préfixe peut avoir été calculé, mais les parties en dehors de la fenêtre SWA ont déjà été éliminées. Si le système applique toujours l'ancienne règle "tokens identiques = succès" pour vous permettre une réutilisation, vous lirez des données invalides ou écrasées, et la performance du modèle s'effondrera directement.
L'équipe de Luo Fuli a amélioré la règle en introduisant la "longueur de sécurité de la fenêtre" – elle ne garantit que "la partie que vous pouvez emprunter intégralement".
Par analogie, une bibliothèque possède 1 million de livres, et vous voulez emprunter la trilogie complète "Le Problème à trois corps" en trois volumes. L'ancienne architecture vous dirait "le livre est là", vous vous précipitez pour découvrir qu'il ne reste sur l'étagère que la couverture et le premier tome, les deux suivants ayant déjà été empruntés. Ce "faux succès" vous fait faire le déplacement pour rien et vous devez recommencer l'emprunt. La nouvelle règle du système ne garantit que la partie que vous pouvez emprunter intégralement – elle vous donne d'abord le premier tome, puis vous fait venir les deux suivants.
Cela semble plus strict, et on pourrait penser que le taux de succès diminue. Mais en réalité, c'est l'inverse : parce que SWA réduit le volume de KVCache à 1/7, le même espace de stockage peut contenir plusieurs fois plus de contenu, ce qui augmente considérablement le taux de succès réel.
Le blog de Luo Fuli fournit des chiffres réels de test en ligne : sous le framework harness standard, le taux de succès du cache côté serveur atteint en moyenne 93%, et peut dépasser 95% pour les utilisateurs intensifs sur de longues périodes.
Traduisons la signification de ce chiffre : 95% des requêtes de "relecture répétée" n'ont pas besoin d'être calculées par le GPU, elles sont directement extraites du cache. C'est la base physique de la remise de 99%.
Travail d'ingénierie n°4 : Installer le "cache" dans le SSD intégré au GPU
Le taux de succès augmente, la question suivante est : où stocker ces caches.
La mémoire vidéo (HBM sur le GPU) est chère et limitée – une machine H100 à huit cartes n'a que 640 Go de VRAM, mais les KVCache que MiMo doit stocker peuvent atteindre des dizaines de To. Il faut donc une hiérarchie : les données récentes vont dans la VRAM (L1), les données un peu plus anciennes dans la mémoire CPU (L2), et les données froides dans un cache distribué (L3).
C'est comme gérer votre argent. L'argent liquide dans votre portefeuille, c'est la VRAM – accessible immédiatement mais en petite quantité. Le solde de votre carte bancaire, c'est la mémoire CPU – 30 secondes pour un retrait mais peut en contenir beaucoup. Le dépôt à terme, c'est le cache distribué L3 – 2 minutes pour un retrait mais beaucoup moins cher.
La pratique courante de l'industrie consiste à construire un cluster de stockage dédié pour le L3, avec des machines et des salles dédiées, payant un loyer mensuel.
L'approche de l'équipe de stockage de Xiaomi est différente. Ils ont développé un cache distribué appelé GCache, déployé directement sur les SSD intégrés aux machines GPU – co-localisé avec les tâches d'entraînement et d'inférence sur la même machine.
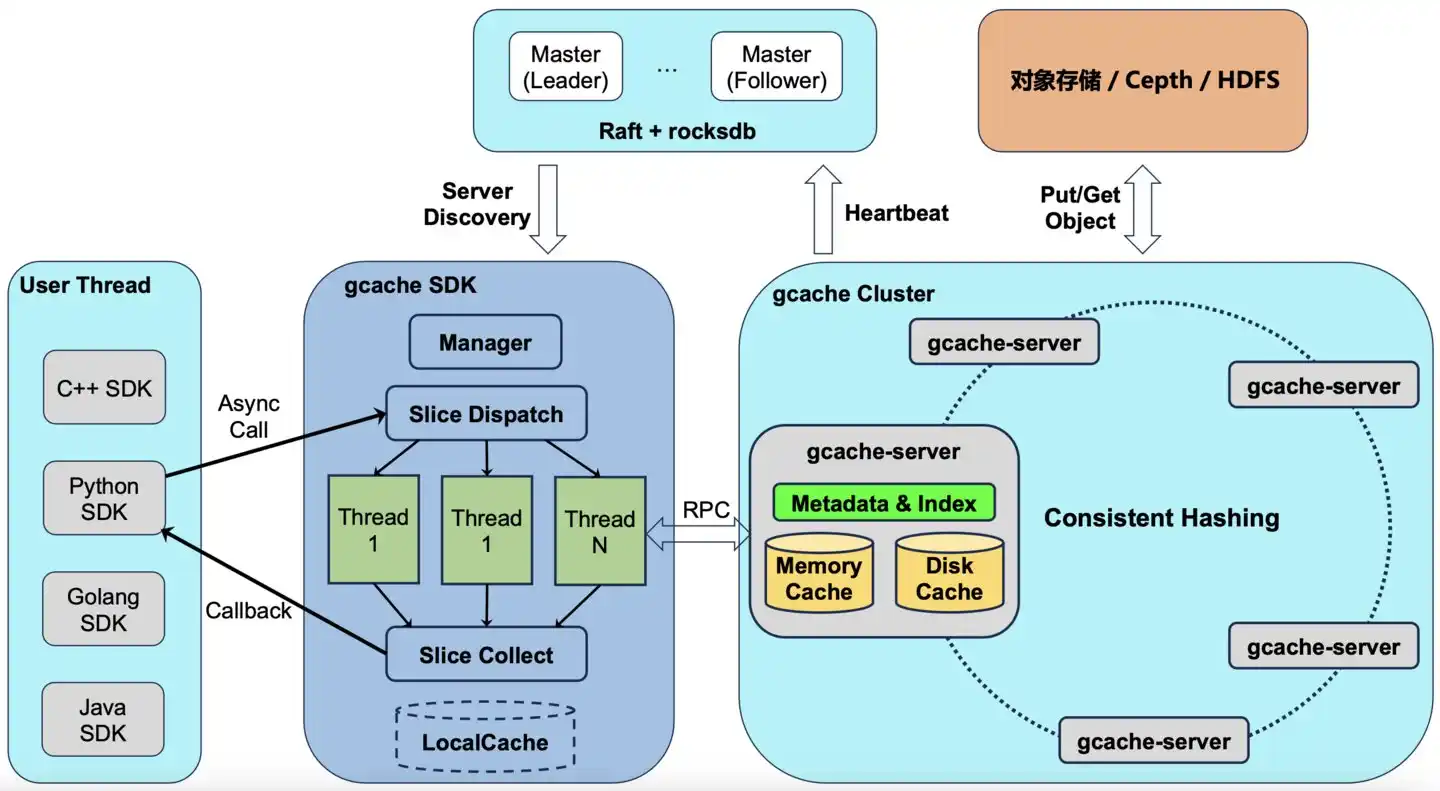
Traduction simple : les autres louent un entrepôt dédié pour stocker de grandes quantités de données ; Xiaomi s'est rendu compte que le garage des machines GPU était en fait vide, et y a directement stocké les données. Loyer mensuel économisé.
La formulation exacte de l'article technique est : "Le coût de stockage supplémentaire est de 0."
L'impact de cela est plus grand qu'il n'y paraît. Dans le "calcul de puissance de calcul standard d'une entreprise d'IA", le coût de stockage est un poste de dépenses fixe – plus votre modèle est grand, plus vos utilisateurs sont nombreux, plus la facture de stockage est longue. L'approche GCache supprime directement cet élément. Combiné au faible volume de SWA + un taux de succès de 93-95%, la durée de vie (TTL) du KVCache en L3 passe de quelques minutes à plusieurs heures, voire plusieurs jours – plus le TTL est long, plus la fenêtre de possibilité de succès du contexte historique est large, plus le taux de succès du cache est élevé, et plus la remise de 99% est justifiée.
Travail d'ingénierie n°5 : Faire emprunter le chemin le plus court aux requêtes qui touchent le cache
Le cache peut être stocké, interrogé, et est bon marché. La dernière étape est : comment router les bonnes requêtes vers la bonne machine.
Xiaomi a développé son propre système de planification appelé LLM-Router, qui fait trois choses :
Premièrement, l'affinité de planification. Les requêtes ayant le même préfixe sont routées vers la même machine, maximisant la réutilisation du cache.
Deuxièmement, le regroupement par longueur. Les requêtes courtes (0-64K), moyennes (64K-256K) et longues (256K-1M) sont réparties dans différents canaux de traitement, évitant que les requêtes courtes ne soient retardées par les longues.
Troisièmement, l'optimisation du TTFT. Dans la file d'attente des requêtes en attente d'inférence, priorité est donnée aux requêtes ayant une faible charge de calcul réelle (c'est-à-dire celles qui touchent massivement le cache) – évitant qu'elles ne soient bloquées par des requêtes de "nouvelle entrée" nécessitant un calcul lourd.
Par exemple, dans la planification classique d'un aéroport, tous les passagers allant à la même destination sont regroupés dans le même salon d'embarquement, partageant le processus de récupération des bagages – c'est l'affinité de planification. Ceux avec un bagage cabine et ceux avec 3 grands bagages en soute empruntent deux voies de sécurité différentes, les rapides ne sont pas retardés par les lents – c'est le regroupement par longueur. À l'embarquement, priorité est donnée à ceux qui n'ont qu'un bagage cabine, ils embarquent vite, permettant à l'avion de décoller plus tôt – c'est l'optimisation du TTFT.
Cette stratégie de planification a permis d'augmenter le taux de succès du cache L2 de 25%, le débit d'entrée par machine de 30%, et de réduire la latence P90 des requêtes longues de 30% lors des tests.
Traduction : le même GPU peut servir plus d'utilisateurs. L'autre moitié de la logique de la baisse de prix se trouve là – la production effective par unité de puissance de calcul est plus élevée, le coût par utilisateur est plus faible.
Travail d'ingénierie n°6 : Rendre le modèle plus rapide pour "taper" aussi
Les cinq points précédents optimisent le côté "lecture" – réduire à presque 0 le coût de la relecture du contexte historique par l'utilisateur. Le sixième point optimise le côté "écriture" – c'est-à-dire le processus de génération du token suivant par le modèle.
Les modèles traditionnels ne peuvent générer qu'un seul token à la fois. MiMo supporte nativement 3 couches de MTP (Multi-Token Prediction) – prédire les 3 tokens suivants en une fois, et si la prédiction intermédiaire est correcte, sauter directement le calcul intermédiaire.
Par analogie, taper de manière traditionnelle, c'est lettre par lettre – pour taper "aujourd'hui il fait beau", vous devez appuyer 4 fois sur des touches. Le MTP, c'est comme avoir une saisie automatique qui devine les 1-2 prochains mots – s'il devine juste, vous n'avez pas à appuyer sur ces deux touches.
Le MTP de MiMo, dans des scénarios agentiques testés : accélération de 2,3 fois pour les 128 premiers tokens de décode, et de 1,5 fois pour les tokens 128-256.
La signification de cela est que la remise de 99% vise spécifiquement l'Input (Cache Hit), mais lorsque le modèle sert réellement un utilisateur, l'input et l'output se produisent dans la même requête – si l'output n'est pas économisé, le coût global de la requête n'est réduit qu'à moitié. Le MTP permet également de réduire l'autre moitié de l'output, et c'est seulement ainsi que le modèle de rentabilité de l'ensemble de la réduction de prix boucle la boucle.
Enchaîner les six points en une chaîne de réduction des coûts :
Architecture SWA → KVCache 1/7 → Double pool libérant réellement la capacité → Le même GPU peut accueillir 5+ fois plus d'utilisateurs simultanés → Taux de succès du cache de préfixe 93-95% → 95% des requêtes n'ont presque pas besoin de calcul → GCache ramène le coût de stockage à zéro → La planification donne la priorité aux requêtes à succès → MTP permet également d'économiser la génération → Temps GPU par requête réduit d'un ordre de grandeur → Coût unitaire réduit de 95%+ → Prix réduit de 99%, marge brute toujours positive.
Si un maillon manque, la chaîne se brise à un certain point. La baisse de prix de 99% n'est pas un chiffre marketing, c'est l'effet cumulatif de six piliers d'ingénierie superposés + une validation en ligne réelle.
En repensant aux premières interprétations de l'industrie, chacune a une part de vérité. La guerre des prix entre les entreprises chinoises de grands modèles ces deux dernières années est réelle ; la division par deux des bénéfices de Xiaomi et son investissement massif dans l'IA sont réels ; DeepSeek tirant le prix de référence de l'industrie vers le bas est également réel.
Mais Luo Fuli, en publiant cet article technique et en détaillant les aspects techniques, espère sans aucun doute répondre aux propos sur la guerre des prix, pour que "les problèmes techniques restent techniques, et les problèmes marketing restent marketing."
Elle écrit dans son blog que l'efficacité d'inférence des modèles de la série MiMo-V2.5 ne provient pas d'une percée ponctuelle dans un seul domaine, mais des résultats d'une optimisation collaborative multidimensionnelle. L'Hybrid SWA profite à la fois au prefill et au decode, mais une mise en œuvre de KVCache non suffisamment optimisée augmenterait en réalité les coûts à chaque étape. Autour de cet objectif, l'équipe MiMo a systématiquement reconstruit la gestion du KVCache, le cache hiérarchique, l'arbre de cache de préfixe, a surmonté les problèmes clés du KVCache SWA, optimisé les stratégies de planification et les chaînes Prefill / Decode, et après validation dans des scénarios réels en ligne, a finalement concrétisé son avantage d'efficacité théorique dans l'environnement de production. Ce n'est qu'alors que l'Hybrid SWA a pu déployer ses avantages architecturaux combinant puissance et efficacité dans le raisonnement sur de longs textes. Combiné à la configuration MoE et aux diverses optimisations du raisonnement multimodal, cela améliore considérablement les performances des services d'inférence en ligne.
C'est une approche systémique d'ingénierie de l'IA, et un moyen de réduction des coûts que l'industrie peut partager et s'inspirer.
Une guerre des prix n'a pas besoin d'un blog, la concrétisation d'un travail d'ingénierie, si.





