Écrit par: Vaidik Mandloi
Traduit par: Luffy, Foresight News
Lancé fin 2022, ChatGPT a, jusqu'à aujourd'hui, donné naissance à un vaste écosystème d'agents IA. Actuellement, le trafic web total généré par ces programmes dépasse celui de tous les utilisateurs humains mondiaux. Les habitudes de navigation des intelligences artificielles sont radicalement différentes de celles des humains : elles ne consultent pas de publicités, ne cliquent pas sur des liens, n'effectuent pas d'achats en ligne, mais se contentent d'extraire des données web pour accomplir des tâches, quittant le site une fois terminé.
L'architecture et la logique commerciale initiales d'Internet ont été construites autour des comportements et habitudes d'utilisation humaines. Or, aujourd'hui, la grande majorité des accès au réseau ne proviennent pas de vrais utilisateurs, ce qui perturbe profondément les sites web. Près de 2,5 millions de sites ont déjà commencé à bloquer les robots d'exploration IA, entraînant des poursuites judiciaires contre des plateformes comme Perplexity. Le fournisseur de services cloud Cloudflare a même mis en place un « labyrinthe de pots de miel », utilisant des textes générés par l'IA, désordonnés et sans signification, pour créer des pages en boucle infinie, piégeant ainsi les robots collecteurs de données.
Mais certains agents IA avancés sont déjà capables de contourner ces mesures de protection. Face à cette escalade de la confrontation homme-machine, l'ensemble du secteur s'efforce de développer un mécanisme de vérification d'identité humaine plus fiable. Ce système doit être capable d'identifier avec précision si l'opérateur de l'autre côté de l'écran est un être humain : un utilisateur humain montre de l'hésitation, fait des fautes de frappe, et ses mouvements de souris présentent des micro-tremblements caractéristiques du système nerveux humain. Cet article analysera les causes de cette transformation, les deux principales approches technologiques, et le choix auquel nous serons confrontés : accepter une surveillance biométrique centralisée, ou adopter des techniques cryptographiques à preuve de connaissance zéro pour une vérification humaine anonyme.
L'IA bouleverse le modèle économique d'Internet
La raison pour laquelle les sites web bloquent massivement les programmes IA réside dans le fait que l'IA a simultanément sapé les fondements commerciaux sur lesquels repose Internet. La logique de rentabilité de l'Internet traditionnel repose sur l'attention des utilisateurs : les visiteurs consultent des pages, voient des publicités, et les éditeurs de contenu en tirent des revenus. Si un IA fait des achats en ligne, elle peut interroger cinq mille sites en une seule fois, tandis qu'un humain ne consultera généralement que quatre ou cinq pages.
La vitesse de lecture de l'IA dépasse de loin celle des humains. En quelques minutes, elle peut comparer les prix sur l'ensemble du web et même passer directement commande, sans générer aucune impression publicitaire. Cela signifie que les sites web supportent les coûts d'exploitation des serveurs sans percevoir aucun revenu.
Parallèlement, la recherche IA détourne continuellement le trafic des sites web. Après que Google a ajouté un résumé IA en haut de ses résultats de recherche, seuls 8 % des utilisateurs cliquent pour accéder au site web original, entraînant une baisse de 33 % du trafic provenant de Google pour les principaux sites de contenu. Un an seulement après son lancement, cette fonction a dépassé le milliard d'utilisateurs actifs mensuels, et le volume de recherches sur la plateforme double chaque trimestre depuis son introduction.
Beaucoup se souviennent de la plateforme d'aide aux devoirs Chegg. Spécialisée à l'origine dans les questions-réponses académiques grâce à un bon classement dans les moteurs de recherche, elle a officiellement fermé sa section questions-réponses, attribuant son déclin à l'impact de ChatGPT. Les créateurs de contenu sont pris en tenaille : d'un côté, les robots explorent librement leurs contenus, de l'autre, les résumés IA captent le trafic avant même que les utilisateurs n'atteignent leur site.
L'écart de données est encore plus frappant : pour chaque redirection de trafic vers un site partenaire, le robot d'exploration d'OpenAI a précédemment extrait les données de 400 pages ; pour Anthropic, ce ratio atteint 38 000:1. Ces entreprises utilisent gratuitement les données publiques du web entier pour entraîner leurs modèles d'IA, puis utilisent les produits finis pour détourner le trafic qui revenait initialement aux sites web.
Dans tout autre secteur, un tel pillage de données aurait déjà donné lieu à d'innombrables procès, mais dans le domaine de l'IA, ces entreprises atteignent des valorisations de mille milliards de dollars.
Votre corps est le nouveau mot de passe
Au cours des 25 dernières années, Internet s'est principalement appuyé sur les CAPTCHA pour distinguer les humains des robots. Les utilisateurs devaient identifier des panneaux de signalisation ou saisir des caractères déformés. Ce mécanisme fonctionnait car, à l'époque, les capacités de reconnaissance d'image des machines étaient bien inférieures à celles des humains.
Aujourd'hui, la situation s'est complètement inversée. Le programme d'opérations intelligentes d'OpenAI obtient un score de simulation humaine bien supérieur à celui des humains dans le système de vérification Google, capable de cliquer avec précision sur les interfaces, de copier-coller du contenu ; les photos générées par l'IA peuvent tromper les systèmes de vérification d'identité, et les appels vidéo deepfake sont même utilisés par des fraudeurs pour effectuer des virements bancaires. Le postulat de conception des méthodes de vérification traditionnelles — la machine est moins performante que l'homme — n'existe plus.
Le secteur doit désormais se concentrer sur ce que l'IA ne peut pas encore reproduire : les caractéristiques biométriques comportementales liées à l'interaction humaine avec les appareils électroniques. Des entreprises comme IBM et BioCatch développent des systèmes qui non seulement vérifient l'identité lors de la connexion, mais surveillent également en continu l'utilisation, collectant des données telles que la vitesse de déplacement du curseur, la façon de faire défiler les pages, le rythme de frappe, la force d'appui sur les touches, les habitudes de correction, l'angle de maintien du téléphone, etc. Le gyroscope du téléphone enregistre ces informations en continu.
Le système peut également identifier des détails comme la main dominante de l'utilisateur ou la trajectoire des doigts sur l'écran. IBM n'a besoin de collecter des données d'utilisation que huit fois pour créer un profil comportemental propre à l'utilisateur, chaque action ultérieure étant comparée en temps réel à ces données de référence.
La technologie de BioCatch peut même détecter des scénarios de fraude en ligne. Lorsqu'une victime tape son mot de passe en le lisant à haute voix sous les instructions téléphoniques d'un fraudeur, le rythme de frappe haché et nerveux est précisément capté par le système. En un an seulement, ce système a aidé 257 banques à identifier environ 2 millions de comptes de blanchiment d'argent. Aujourd'hui, l'UE expérimente également la reconnaissance de la démarche. Trois ans seulement après l'avènement des agents IA, les agents des frontières de l'UE collectent déjà la démarche des citoyens.
Des études intègrent également l'effet Stroop : lorsque le mot « bleu » est écrit en vert, le cerveau humain est perturbé par le conflit entre le sens du mot et la couleur perçue, ralentissant sa réaction, mais l'IA n'est pas affectée. La recherche montre que cette interférence cognitive se reflète directement dans le comportement de frappe. La plateforme n'a même pas besoin de poser de question spécifique ; simplement en analysant le rythme des frappes, elle peut déterminer si l'opérateur est humain. Les habitudes de frappe révèlent les caractéristiques uniques du traitement de l'information par le cerveau humain.
Auparavant, le suivi en ligne enregistrait principalement les comportements de navigation, de clic et d'achat des utilisateurs, qui pouvaient être évités en bloquant les cookies, en utilisant un VPN ou en désactivant la géolocalisation. Mais la biométrie comportementale capture des caractéristiques instinctives du corps humain : la façon de bouger la souris, le rythme de frappe sont difficiles à modifier volontairement.
Les caractéristiques comportementales de chacun sont aussi uniques qu'une empreinte digitale. Contrairement à un mot de passe ou une clé, ce profil biométrique ne peut être changé ou réinitialisé. Une fois cette technologie généralisée, toutes les grandes plateformes seront obligées de s'y adapter. Aujourd'hui, la synthèse vocale peut déjà tromper lors d'un appel, et les deepfakes vidéo suivent de près. Si tel est l'avenir, une question cruciale émerge : qui contrôlera ces données corporelles humaines ?
Qui contrôlera le système de vérification humaine ?
Actuellement, deux grands camps se distinguent dans le secteur, explorant chacun des solutions pour la vérification d'identité humaine.
Le premier est World de Sam Altman (anciennement Worldcoin). L'utilisateur doit s'approcher d'un dispositif sphérique de scan de l'iris, qui capture les informations de l'iris et génère une preuve cryptographique, attestant que l'utilisateur est un être humain unique. À ce jour, 18 millions de personnes dans 160 pays ont enregistré leur iris. En avril 2026, World a conclu des partenariats de vérification avec l'application de rencontres Tinder, la plateforme de visioconférence Zoom et le service de signature électronique DocuSign. Il a également lancé conjointement avec Coinbase l'outil AgentKit, permettant aux utilisateurs de lier leurs agents IA à leur identité vérifiée, confirmant ainsi qu'un agent est contrôlé par un humain sans révéler d'informations personnelles.
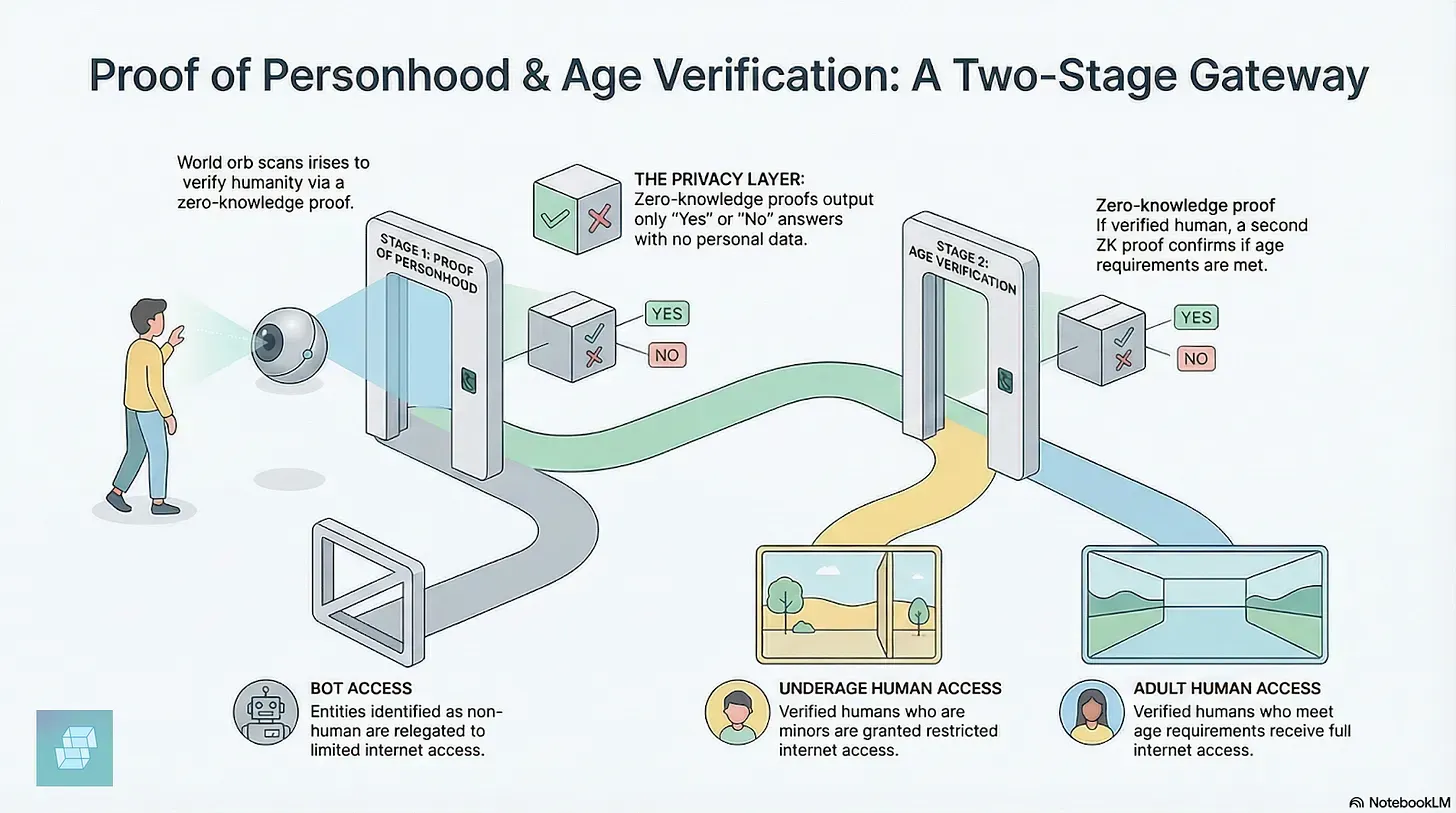
Cependant, la technologie de scan de l'iris est interdite dans plusieurs pays. La principale raison de cette opposition est que les citoyens ne comprennent pas pleinement les risques liés à la collecte de données biométriques. Une enquête du MIT Technology Review a également révélé que World, sans autorisation valide, collectait en secret des données sur les signes vitaux comme la fréquence cardiaque et la respiration, en plus de l'iris.
Le second type repose sur la cryptographie à preuve de connaissance zéro, qui vous permet de prouver que vous êtes humain sans révéler votre identité réelle, votre localisation ou votre apparence. Vitalik Buterin avait déjà proposé cette idée en 2023. Selon lui, si nous ne parvenons pas à construire un système d'identité humaine décentralisé, Internet finira par évoluer vers un contrôle centralisé de l'identité. Si le pouvoir de vérification est détenu par des entreprises ou des gouvernements, un mécanisme de surveillance sera ancré dans les fondements du réseau.
Des tentatives de systèmes d'identité humaine décentralisés à grande échelle ont déjà eu lieu, mais ont échoué. Idena était l'un des premiers projets de blockchain promouvant « une personne, une identité ». En deux ans seulement, 40 % des comptes et 48 % des récompenses du réseau étaient contrôlés par 23 organisations. En Inde, en Russie et ailleurs, des équipes louaient les identités de personnes ordinaires pour moins d'un dollar de l'heure, réalisant des profits jusqu'à 55 fois supérieurs. Les chercheurs ont même découvert que des informations d'identité d'enfants étaient utilisées pour des comptes fantômes.
Vitalik avait anticipé ce risque. Il a déclaré que, pour un système de vérification d'identité humaine, l'attaque la moins coûteuse n'était pas le deepfake ou les techniques de piratage sophistiquées, mais le fait de payer des personnes dans des régions à faible revenu pour prêter leur identité. Tout système de vérification d'identité humaine nécessite un financement : les dispositifs de scan d'iris, les nœuds de vérification sur la blockchain exigent des investissements continus.
Mais dès qu'une preuve d'identité acquiert une valeur économique, un marché noir du prêt d'identité émerge. Dans un monde réel marqué par d'énormes disparités de richesse, les plus puissants finissent par contrôler ce type de marché.
« Essayer d'imposer une règle d'une personne, un vote dans un système avec de réelles incitations économiques ne fera que répéter l'échec des expériences sociales du vingtième siècle. »
Objectivement, les deux voies présentent des défauts évidents. La solution centralisée peut être déployée à grande échelle, mais les données biométriques des utilisateurs seront confiées à des entreprises déjà enclines à collecter des informations de manière excessive, et qui tirent profit de la prolifération des robots. La voie cryptographique protège théoriquement la vie privée, mais peine à échapper aux déséquilibres économiques réels, finissant par être exploitée par des industries parallèles.
Si je devais parier, je miserais toujours sur la solution cryptographique. Car la biométrie comportementale et le scan centralisé de l'iris enregistrent de façon permanente les informations de votre corps, dont la propriété appartient à ceux qui déploient le système. Une fois qu'ils détiennent vos données, vous ne pouvez ni les supprimer ni les transférer ; ces données seront verrouillées chez l'entreprise qui les a collectées.
Même en sachant que les preuves de connaissance zéro peuvent être contournées, elles valent la peine d'être développées, car elles permettent de confirmer que vous êtes humain sans révéler plus d'informations. À l'inverse, si nous abandonnons cette voie, à l'avenir, chaque site que nous visiterons conservera les données de nos comportements physiques. Aujourd'hui, cette solution centralisée à caractère surveillance se déploie déjà beaucoup plus rapidement que la voie technologique cryptographique.






