Auteurs originaux: Li Hailun, Su Yang
Rédacteur en chef original: Xu Qingyang
Source originale: Tencent Technology
Le 1er juin 2026, lors de la conférence NVIDIA GTC Taipei organisée pendant le COMPUTEX 2026, Jensen Huang, fondateur et PDG de NVIDIA, a prononcé un discours d'ouverture.
Trois mois seulement se sont écoulés depuis la dernière GTC.
À l'époque, NVIDIA avait lancé le "pack famille" de puces Vera Rubin, incluant : le CPU Vera, le GPU Rubin, le LPU Groq 3, le ConnectX-9, le DPU BlueField-4, le commutateur Spectrum-6. Ces six puces composent un supercalculateur IA de niveau rack et ont annoncé une réduction du nombre de GPU nécessaires à l'entraînement de grands modèles MoE à un quart, une augmentation du débit d'inférence de 10 fois par watt, et une réduction du coût par token à un dixième.
Contrairement aux précédentes présentations axées sur des solutions systémiques comme le "pack famille de puces" ou le "pack famille de puissance de calcul", lors du COMPUTEX trois mois plus tard, Jensen Huang a porté son regard sur la cible que serviront ces infrastructures : l'Agent.
Jensen Huang a révélé dans son discours : Vera Rubin entre officiellement en production de masse, le CPU Vera commence à être livré dans le monde entier, la DGX Station fait pour la première fois son entrée sur les bureaux d'entreprise sous forme Windows, Cosmos 3 refond le cadre de perception de l'IA physique, et DSX devient le système d'exploitation opérationnel des usines d'IA. NVIDIA a également co-présenté avec Unitree le H2 Plus — le premier design de référence pour robot humanoïde basé sur Isaac GR00T, étendant ainsi la frontière des Agents du monde numérique à la forme physique.
NVIDIA est en train de réorganiser son système technologique complet, des puces aux centres de données, des modèles, des logiciels jusqu'aux plateformes robotiques, autour de l'écosystème des Agents.
Jensen Huang a déclaré : "L'ère de l'Agent IA et de l'intelligence artificielle utilitaire est arrivée. Aujourd'hui, le token (ou 'unit lexicale') est une unité de profit, l'IA est un 'générateur' de PIB, le nombre d'ingénieurs logiciel est en augmentation. Les gens parlent de l'IA qui réduit les emplois, c'est complètement absurde, en réalité, plus d'ingénieurs logiciel sont embauchés".

La même usine d'IA, exécutant 10 fois plus de tâches d'Agent
La plateforme Vera Rubin est entièrement en production.
Contrairement au passé, axé principalement sur l'entraînement et l'inférence des grands modèles, Vera Rubin a été conçue dès le départ avec l'Agent comme charge de travail prioritaire.
Jensen Huang a indiqué dans son discours qu'une tâche d'Agent n'est souvent pas qu'une simple inférence de modèle, mais comprend plusieurs étapes comme l'inférence, la recherche, l'appel d'outils, l'exécution de code et la validation des résultats, pouvant impliquer des milliers d'étapes en arrière-plan. À l'avenir, ce que les centres de données devront traiter ne sera plus seulement des requêtes de modèles individuels, mais davantage un grand nombre de tâches d'Agent s'exécutant en continu et collaborant entre elles.
Cette plateforme est définie comme un énorme supercalculateur IA unifié au niveau de l'unité de calcul, conçu spécifiquement pour gérer les charges de travail d'Agent intelligent, de l'inférence à la recherche en passant par l'utilisation d'outils. Dans des centres de données hyperscale de taille similaire, l'efficacité de traitement des tâches d'Agent IA autonome avec la toute nouvelle plateforme Vera Rubin est 10 fois supérieure à celle de la plateforme Grace Blackwell de la génération précédente.
Outre la plateforme de calcul elle-même, le réseau est également devenu un point de mire de la mise à niveau de Vera Rubin.
Auparavant, dans les centres de données, la transmission de données entre GPU reposait principalement sur des modules optiques traditionnels et des architectures de commutateurs, mais lorsque la taille des clusters continue de s'étendre, la consommation électrique, le refroidissement et la complexité du déploiement augmentent rapidement. Pour cela, NVIDIA a introduit le système réseau Spectrum-X Ethernet Photonics dans la plateforme Vera Rubin.
C'est la première fois que NVIDIA introduit à grande échelle la technologie d'optique co-packagée (CPO) dans les réseaux de centres de données d'IA.
En termes simples, les solutions traditionnelles nécessitent de brancher les modules optiques à l'extérieur du commutateur, tandis que le CPO intègre directement les composants optiques à l'intérieur du commutateur, réduisant ainsi la consommation d'énergie et la perte de signal.
De plus, la sécurité est également une capacité clé mise en avant dans cette plateforme Vera Rubin.
Pour cela, NVIDIA a étendu les capacités de calcul confidentiel (Confidential Computing) à l'ensemble de la plateforme Vera Rubin. Grâce à des environnements d'exécution de confiance, une vérification au niveau matériel et des mécanismes de chiffrement de bout en bout, les entreprises peuvent obtenir un niveau de sécurité plus élevé lors du traitement de données privées, d'informations sensibles du secteur et de modèles critiques.
Jensen Huang a révélé que Vera Rubin est entrée en phase de production de masse. En tant que système de troisième génération de niveau rack MGX, sa mise en œuvre implique plus de 150 partenaires, plus de 350 usines et une chaîne d'approvisionnement couvrant plus de 30 pays et régions. Selon le plan annoncé par NVIDIA, Vera Rubin commencera ses livraisons officielles cet automne.

Le processeur "né pour l'Agent"
NVIDIA a lancé un nouveau processeur, Vera, conçu spécifiquement pour l'ère des Agents, et a commencé sa production complète.
Jensen Huang a souligné que les progrès des systèmes mémoire stimuleront l'innovation et la modernisation des systèmes de stockage. Tous les CPU jusqu'à présent ont été conçus pour les humains, tandis que Vera est un CPU conçu pour l'ère de l'IA, conçu pour les Agents.
Successeur de Grace, Vera adopte l'architecture de cœur CPU "Olympus" conçue par NVIDIA, passant de 72 à 88 cœurs, et augmentant considérablement les capacités de mémoire et de traitement des données. Selon NVIDIA, dans les tests de charges de travail liées aux Agents, la vitesse d'exécution des tâches de Vera atteint 1,8 fois celle des CPU serveurs x86 contemporains.
Plus important que le simple gain de performance, le changement clé réside dans la relation entre Vera et le GPU Rubin : Vera se connecte au GPU Rubin via le NVLink-C2C de deuxième génération, avec une bande passante d'interconnexion atteignant 1,8 To/s, réduisant encore les coûts de transfert de données entre le CPU et le GPU pendant l'exécution des Agents.
Jensen Huang a déclaré que Vera Rubin utilise la HBM (mémoire à haut débit) de Micron, SK Hynix et Samsung, l'échelle de la chaîne d'approvisionnement étant "le double" de celle de la génération précédente Blackwell. Cependant, déployer un grand rack Blackwell nécessite deux heures, tandis que le temps pour Vera Rubin est compressé au niveau de la minute.

Faire passer l'usine d'IA de la "construction" à l'"exploitation"
Le DSX lancé par NVIDIA cette fois peut être compris comme une "boîte à outils pour la construction et l'exploitation d'usines d'IA".
Auparavant, pour construire un centre de données d'IA, les clients devaient considérer séparément les serveurs, le réseau, l'électricité, le refroidissement, la conception de la salle informatique et les systèmes d'exploitation, de nombreux aspects dépendant de la coordination de différents fournisseurs. L'objectif de DSX est de rassembler ces éléments autrefois dispersés dans un même cadre, offrant aux clients une solution de référence standardisable et vérifiable, de la conception et de la simulation à la construction et à l'exploitation.
Jensen Huang a déclaré sur scène lors du lancement : NVIDIA ne vend pas seulement des puces, mais fournit également aux constructeurs d'infrastructures un plan complet pour une usine d'IA.
Les deux capacités ajoutées les plus importantes de DSX cette fois sont les suivantes.
La première est DSX MaxLPS. Elle résout le problème le plus concret des usines d'IA : avec un budget électrique fixe, comment placer plus de GPU et générer plus de Tokens.
Selon NVIDIA, MaxLPS, combiné au refroidissement liquide et à l'optimisation de la consommation électrique dans les racks, permet aux opérateurs d'exécuter jusqu'à 40% de GPU supplémentaires sans impact significatif sur les performances.
La seconde est DSX OS. Elle équivaut au logiciel d'exploitation de l'usine d'IA, responsable de la gestion du cycle de vie, de l'ordonnancement intelligent, de la surveillance de l'état de santé, de la récupération après panne, de la gestion multi-locataires, etc. En termes simples, si l'usine d'IA est une usine complexe, DSX OS est responsable de son fonctionnement stable et continu.
Dans la matrice produit DSX, Reference Design fournit la conception de référence de l'usine d'IA, indiquant aux clients comment configurer la salle informatique, les racks, le réseau, le système électrique et le système de refroidissement ; DSX Sim est responsable de la simulation, permettant aux clients de vérifier la faisabilité de la conception avant la construction ; DSX Flex connecte l'usine d'IA au réseau électrique, permettant au centre de données d'ajuster les tâches en fonction du prix de l'électricité, de la charge et des signaux de réponse à la demande ; DSX Exchange est responsable de la connexion des données entre les systèmes informatiques, les systèmes opérationnels, les systèmes énergétiques et de refroidissement.
En termes d'écosystème, des partenaires cloud comme CoreWeave, Crusoe, Lambda déploient DSX Sim, MaxLPS et DSX OS pour réduire les risques et améliorer l'utilisation des GPU. Des fabricants comme Dell, HPE, Lenovo, Supermicro ainsi qu'ASUS, Foxconn, GIGABYTE, Wiwynn construisent des systèmes compatibles DSX.
S'allier avec Windows et ARM
Dans son discours, Jensen Huang a officiellement annoncé l'apparition de la station de travail "DGX Station for Windows", définie par NVIDIA comme un supercalculateur IA de bureau pour l'écosystème Windows.
Matériellement, elle est équipée du GB300 Grace Blackwell Ultra Desktop Superchip, connectant le GPU Blackwell Ultra et le CPU Grace 72 cœurs via NVLink-C2C, offrant jusqu'à 748 Go de mémoire unifiée et des performances de 20 PFLOPS FP4, avec une capacité réseau allant jusqu'à 800 Gb/s.
L'intérêt de ce produit réside dans l'évolution du mode de déploiement des Agents.
NVIDIA souhaite que les entreprises puissent exécuter plusieurs Agents localement, de manière sécurisée et gérable, dans un environnement Windows, et les intégrer dans des flux de travail comme la conception, l'ingénierie, la science des données, l'inférence et l'IA physique. OpenShell, lancé simultanément, assure la sécurité d'exécution des Agents, via un bac à sable isolé et un contrôle des stratégies au niveau du système, limitant les opérations non autorisées ou les fuites d'informations d'identification et de données privées par les Agents.
Outre le produit pour les bureaux d'entreprise, Jensen Huang a également présenté un SoC système — RTX Spark SoC, intégrant le CPU N1X et le GPU Blackwell sur une seule puce, avec une architecture de mémoire unifiée, spécialement conçu pour les ordinateurs portables fins et légers et les petits PC de bureau.
Parmi ceux-ci, le N1X est le premier processeur pour PC co-développé par NVIDIA et Microsoft. Il est basé sur l'architecture Arm, conçu sur mesure par MediaTek, fabriqué en processus 3 nm de TSMC. Il sera disponible pour la première fois cet automne sur des ordinateurs portables de Microsoft, Dell, HP, ASUS, Lenovo et MSI, avec plus de 30 modèles en première vague, principalement des ordinateurs portables fins et légers haut de gamme.
C'est le "super-puce" préparé par NVIDIA pour l'ère des PC IA, que Jensen Huang considère comme une refonte importante de la forme des PC.
Les "deux cerveaux" de l'Agent
Lors de ce lancement, NVIDIA a dévoilé les dernières avancées de deux lignes de produits modèles clés, correspondant à deux scénarios pour les Agents : l'un fonctionnant dans les systèmes d'entreprise, l'autre dans le monde physique.
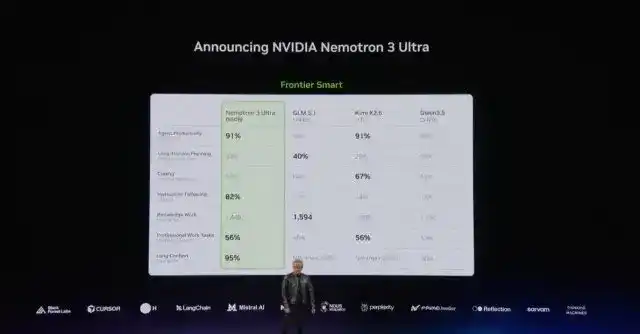
NVIDIA a publié un modèle d'experts mixtes de 550 milliards de paramètres, Nemotron 3 Ultra, fournissant des capacités intelligentes de pointe pour les agents de longue durée dans le développement de code, la recherche scientifique et les processus métier des entreprises. Par rapport aux principaux modèles open source de pointe de même niveau, ce modèle offre une vitesse d'inférence jusqu'à 5 fois supérieure et un coût d'utilisation réduit jusqu'à 30%, aidant les agents à accomplir leurs tâches plus efficacement et à moindre coût.
Autour des modèles ouverts Nemotron, NVIDIA a publié une série de logiciels, de modèles open source et d'avancées de partenariat, visant à permettre aux entreprises de construire des "collègues numériques" capables d'assister les employés dans des scénarios comme la conception technique, la santé, le développement logiciel et les opérations métier.
Dans cette combinaison, Nemotron fournit les capacités de base du modèle, NemoClaw organise le modèle en Agent, OpenShell assure la sécurité d'exécution, et Agent Toolkit transforme les bibliothèques logicielles NVIDIA comme CUDA-X en outils directement utilisables par les Agents. Les Agents peuvent utiliser des outils, appeler des données, exécuter des tâches dans un environnement contrôlé et s'intégrer aux systèmes existants de l'entreprise.
Jensen Huang a déclaré que les sociétés logicielles mondiales intègrent les Agents IA dans les systèmes de travail réels, les aidant à accomplir des tâches complexes plus rapidement. NemoClaw fournit les composants ouverts nécessaires à la construction d'Agents de longue durée, incluant des capacités d'orchestration, de contexte, de mémoire, d'appel d'outils et de contrôle de sécurité.
Auparavant, les entreprises discutaient de l'IA en se concentrant sur ce que le modèle pouvait répondre ; maintenant, NVIDIA cherche à résoudre comment les Agents peuvent s'intégrer de manière sécurisée aux outils, aux données et aux processus métier, et fonctionner de manière continue dans un travail réel.
Il y a aussi Cosmos 3, lancé officiellement en tant que troisième génération de la série Cosmos, représentant également une refonte architecturale.
Cosmos 3 est un modèle de base mondial pour l'IA physique, fournissant les capacités fondamentales de "comprendre le monde physique, prédire ce qui va se passer, décider comment agir".
Comparé aux versions précédentes de Cosmos, les premières versions s'adressaient principalement aux développeurs de robots et de voitures autonomes, se concentrant sur la génération vidéo et la simulation du monde physique, essentiellement un framework de génération relativement unimodal. Cosmos 3 adopte une nouvelle architecture — le Transformer hybride, unifiant pour la première fois le raisonnement visuel, la génération du monde et la prédiction des actions dans un seul système.
Il comprend et génère nativement du texte, des images, des vidéos, des sons environnementaux et des actions, atteignant un niveau avancé en précision physique, et est le premier modèle universel entièrement ouvert au monde. NVIDIA affirme qu'il pourrait réduire le cycle d'entraînement et d'évaluation de l'IA physique de plusieurs mois à quelques jours.
Jensen Huang prédit que grâce aux avancées dans le raisonnement multimodal, le langage, la vision et les modèles du monde, le big bang de l'IA physique est imminent.
La série de modèles universels ouverts et de pointe Cosmos 3 offre aux développeurs une capacité de saut générationnel pour construire des robots, des voitures autonomes et des IA visuelles capables de percevoir, raisonner, planifier et agir dans le monde physique.
Baisser le seuil d'entrée de l'IA physique
NVIDIA et Unitree ont co-présenté le H2 Plus — un robot humanoïde de démonstration pour la recherche et le développement.
"Démonstration" signifie : Unitree est responsable du corps du robot, NVIDIA des logiciels et de la plateforme de calcul, les deux parties pré-intègrent le matériel et les logiciels, permettant aux équipes de développement de commencer directement le développement des compétences sans perdre de temps à résoudre les problèmes d'intégration de bas niveau. C'est également le premier robot humanoïde ouvert construit sur la plateforme de développement NVIDIA Isaac GR00T.
Cette machine de démonstration cible un point douloureux de longue date dans le développement des robots humanoïdes : l'intégration matérielle, la collecte de données, la simulation, l'entraînement, l'évaluation, le déploiement — chaque étape est fragmentée et fonctionne de manière isolée.
NVIDIA indique que les équipes de recherche, après avoir obtenu un corps de robot, passent souvent beaucoup de temps à assembler les couches basses, repoussant constamment le véritable développement des compétences. Ce que tente de faire le H2 Plus, c'est de fluidifier ce parcours, permettant aux équipes de recherche de sauter l'intégration bas niveau et de passer directement au développement des compétences et à la validation en scénarios réels.
Selon Jensen Huang, les robots humanoïdes apporteront l'IA physique à la plus grande industrie mondiale, ouvrant des opportunités économiques de milliers de milliards de dollars, et le H2 Plus est le point de départ pour faire avancer la recherche de pointe vers des scénarios réels comme les usines, les entrepôts et les systèmes logistiques.
De plus, NVIDIA a annoncé l'ouverture officielle d'un ensemble d'outils de compétences (Skills) pour l'IA physique, couvrant les scénarios clés comme la robotique, la conduite autonome, l'IA visuelle et les jumeaux numériques industriels.
Ces "compétences" peuvent être comprises comme la standardisation par NVIDIA des modes d'utilisation de ses plateformes comme Cosmos, Omniverse, Isaac, Metropolis, rédigés sous forme d'instructions opérationnelles directement compréhensibles et exécutables par les agents intelligents. L'ouverture de ces instructions regroupées constitue l'ensemble d'outils publié cette fois.
Lorsqu'un agent reçoit une tâche, comme générer un lot de données d'entraînement pour détecter des défauts, il sait quel modèle appeler, quel format de sortie produire, comment valider les résultats — l'ensemble du processus s'exécute automatiquement, sans nécessiter une intervention humaine étape par étape à chaque niveau.
Améliorer le stockage IA : de "rapide" à "gérable"
Lors du GTC de San José en mars, NVIDIA avait lancé Vera BlueField-4 STX, et Jensen Huang avait alors mis l'accent sur "l'architecture de stockage native IA", l'argument principal étant la fourniture d'un support de stockage KV Cache haute performance pour le raisonnement en contexte long des agents.
Maintenant, NVIDIA annonce l'ajout d'une série de capacités de sécurité sur la base du STX, l'accent passant des "performances de stockage" à la "sécurité du stockage".
La logique et la réflexion sous-jacentes résident dans l'évolution des modes d'utilisation de l'IA en entreprise. Aujourd'hui, de nombreuses entreprises déploient activement des agents. Lorsqu'un Agent s'intègre aux systèmes d'entreprise, lisant et écrivant continuellement, partageant des informations entre systèmes sans supervision directe — qui accède à quelles données, y a-t-il des dépassements de droits, des fuites — ce sont des problèmes préoccupants pour les entreprises.
La solution de NVIDIA est d'ajouter une couche de sécurité sur la base du stockage accéléré — grâce à un logiciel de sécurité NVIDIA DOCA unifié, et à l'exécution matérielle des politiques directement dans la puce BlueField-4, les plateformes basées sur STX peuvent inspecter et contrôler en temps réel les interactions entre les agents, les données et la mémoire contextuelle, aidant les entreprises à mettre en œuvre des politiques de manière continue sur le chemin de données de l'IA.
Jensen Huang a expliqué : "Les agents transforment les données de l'entreprise en un système en temps réel et vivant, et ce système doit être protégé là où les données se déplacent, là où le contexte est stocké, là où les agents agissent. Ce que fait Vera BlueField-4 STX, c'est appliquer la confiance à la vitesse de l'IA, dans la puce, avec une conception intrinsèquement sécurisée".
TSMC et NVIDIA "sont mutuellement fournisseurs"
Un point très intéressant de cette conférence est la collaboration entre NVIDIA et TSMC — actuellement, TSMC utilise la technologie NVIDIA pour améliorer le temps de rotation, l'efficacité énergétique, le rendement et la productivité opérationnelle de ses usines de pointe.
La relation entre TSMC et NVIDIA, pendant près de trente ans, n'avait qu'une seule forme : TSMC fabriquait les puces pour NVIDIA. Mais maintenant, les rôles ont subtilement changé, NVIDIA commence à aider TSMC à "gérer ses usines".
Jensen Huang a déclaré : "NVIDIA et TSMC collaborent depuis près de trente ans, repoussant constamment les limites du calcul. TSMC introduit l'IA et le calcul accéléré de NVIDIA à l'intérieur de ses usines, utilisant la simulation, l'optimisation et l'IA pour relever les défis de conception et de fabrication les plus complexes au monde, afin d'améliorer la vitesse, l'efficacité et le rendement des prochaines générations de puces."
La relation entre les deux, autrefois unilatérale entre client et fournisseur, est devenue une interdépendance bilatérale.
Conclusion
En revenant sur ce lancement, NVIDIA est en train d'assembler un nouveau plan autour de l'"Agent".
Le CPU Vera planifie les tâches des Agents, Vera Rubin fournit la puissance de calcul aux Agents, BlueField-4 STX protège la sécurité des données des Agents, Cosmos 3 permet aux Agents de comprendre le monde physique, Nemotron+NemoClaw+OpenShell permettent aux Agents d'être organisés, appelés, contraints, DGX Station for Windows fait entrer les Agents sur le bureau des employés d'entreprise, H2 Plus donne un corps aux Agents, DSX et Skills permettent à tout cela d'être produit et déployé en masse.
Sous cet angle, Jensen Huang tente de décrire une nouvelle ère informatique. Cela fait également écho à sa déclaration d'ouverture : "L'ère de l'Agent IA et de l'intelligence artificielle utilitaire est arrivée".
En fin de compte, ce que Jensen Huang a voulu raconter cette fois, c'est une seule chose : lorsque l'Agent devient l'infrastructure de l'IA, NVIDIA peut être présent à chaque niveau.







