Auteur : Yanhua
Compilé à partir de : Podwise
OpenClaw fait fureur en ce moment, tout le monde en parle. Mais honnêtement, la plupart des contenus parlent de théorie, d'architecture, de vision. Qu'est-ce qu'on peut vraiment faire avec ce truc ? Comment le déployer dans le travail quotidien ? Peu de gens l'expliquent clairement.
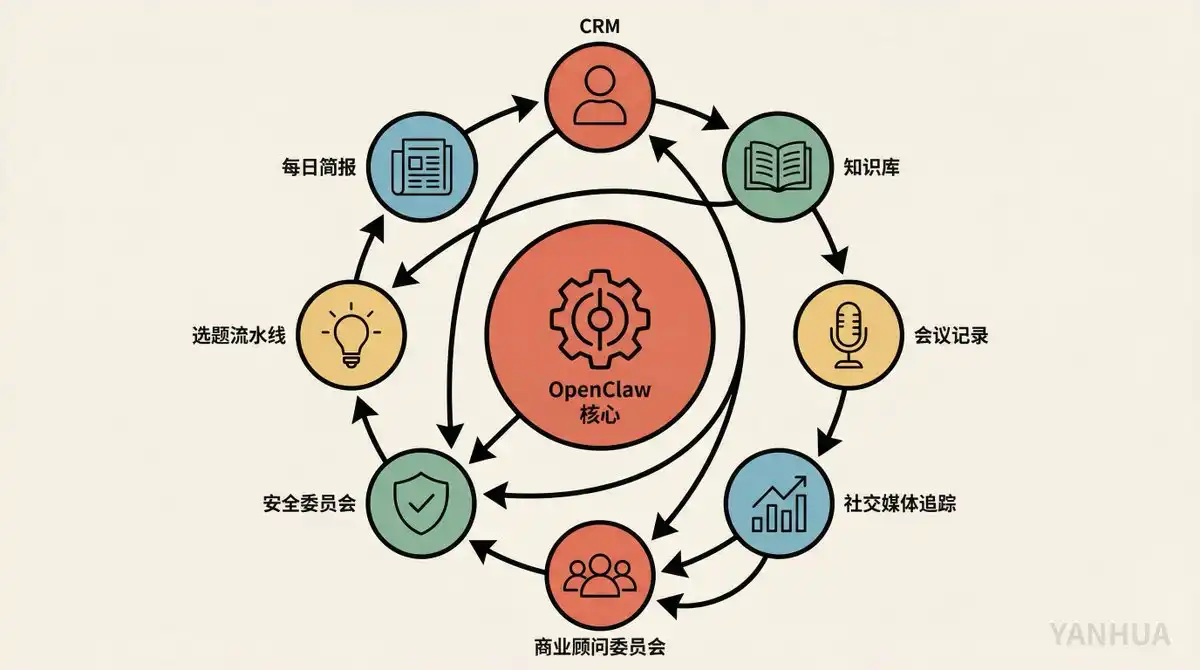
Matthew Berman a récemment publié une vidéo où il dévoile d'un coup tous les cas d'usage qu'il a construits avec OpenClaw. Pas de concepts, que de la pratique. CRM, base de connaissances, comité de conseil business, revue de sécurité, suivi des réseaux sociaux, pipeline de sujets vidéo, briefing quotidien, journal alimentaire... Une personne, un MacBook, fait le travail d'une équipe de support d'une petite entreprise.
Je détaille ses cas d'usage les plus centraux. Sans exagération, en passant en revue chaque cas : ce que c'est, comment ça fonctionne, ce qui est bien.
Cas d'usage 1 : CRM en langage naturel, de zéro à utilisable en 30 minutes
C'est le premier cas d'usage présenté par Berman, et le plus直观.
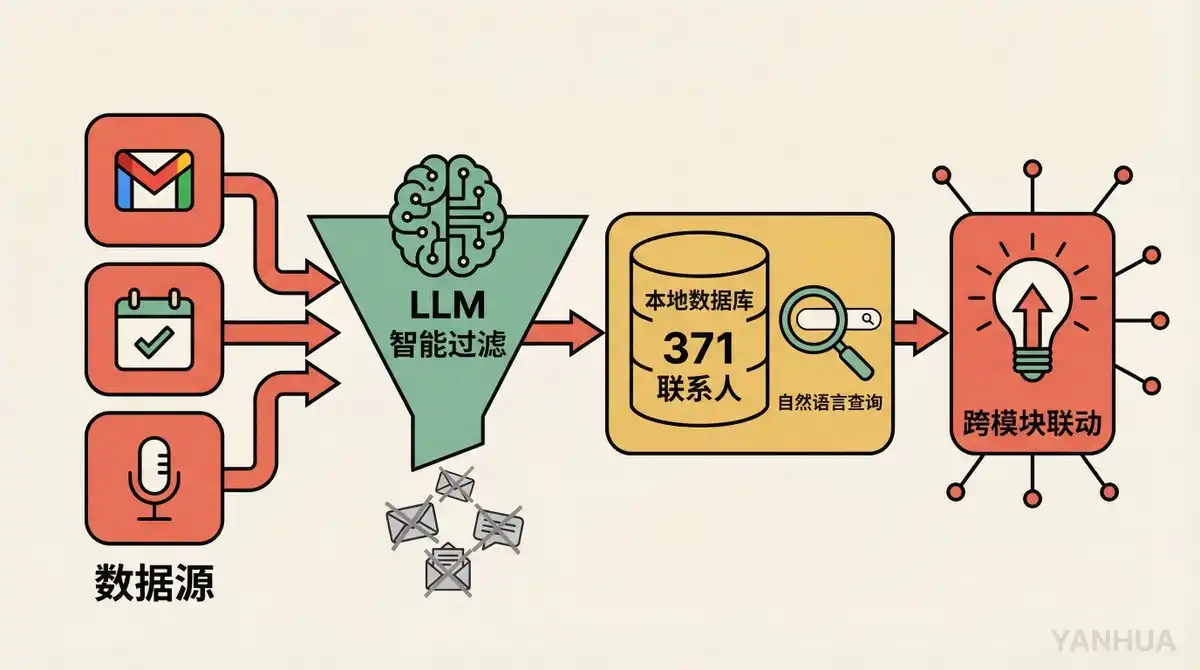
Processus de construction : Il a simplement dit en langage naturel à OpenClaw : « Aide-moi à construire un CRM, extrais les données de Gmail, Google Calendar et Fathom, filtre les emails marketing et les prospections froides, ne garde que les conversations et contacts de valeur. » Sans écrire une seule ligne de code. Fonctionnel en 30 minutes.
Ingestion des données : Le système scanne les emails toutes les 30 minutes, vérifie Fathom (outil de transcription de réunions IA) toutes les 5 minutes pendant les heures de travail. Toutes les données passent d'abord par un LLM avant stockage pour juger : cet email mérite-t-il d'être stocké ? Ce contact est-il important ?
Capacités clés :
-
371 contacts, tous interrogeables en langage naturel. « De quoi ai-je parlé avec John la dernière fois ? » « Qui était mon dernier interlocuteur chez X company ? »
-
Score de santé des relations, marquage automatique des personnes sans contact depuis longtemps
-
Détection des doublons et suggestions de fusion
-
Recherche par embedding vectoriels, support de la correspondance sémantique floue
Détail le plus impressionnant : Lorsque Berman est dans un autre contexte (comme chercher un sujet de vidéo), le CRM intervient activement : « Tu as déjà parlé d'un sujet similaire avec un sponsor, peut-être qu'ils voudraient sponsoriser cet épisode. » Le système fait le lien entre les modules, il ne stocke pas passivement les données, il crée activement des connexions.
Citation de Berman : « Si je peux monter un CRM complètement personnalisé en 30 minutes, et passer une heure ou deux à l'itérer et l'optimiser, pourquoi est-ce que je paierais une entreprise de CRM ? »
Cas d'usage 2 : Suivi automatique des points d'action de réunion
Ce cas d'usage est étroitement lié au CRM, mais mérite d'être mentionné séparément.
Workflow : Fin de réunion → Transcription complète par Fathom → OpenClaw fait correspondre le contact CRM → Extraction des points d'action → Envoi sur Telegram à Berman pour approbation → Ceux approuvés entrent automatiquement dans Todoist
Quelques conceptions clés :
-
Distinction entre les points d'action « miens » et « de l'autre ». Les choses que l'autre partie s'est engagée à vous donner, le système les marque comme « waiting on », suit automatiquement si l'autre partie tient sa promesse.
-
Filtrage auto-apprenant. Si Berman rejette un point d'action (« Ce n'est pas ma tâche »), le système apprend la raison et met à jour les règles d'extraction. La prochaine fois, il ne capturera pas dans la même situation.
-
Vérification automatique 3 fois par jour de l'état d'avancement. Par exemple, si vous dites en réunion « Je t'envoie l'email aujourd'hui », le système vérifie si vous l'avez vraiment envoyé, et coche automatiquement si c'est fait.
-
Archivage automatique après 14 jours. Les éléments non terminés et dépassés sont automatiquement nettoyés, gardant la liste propre.
La valeur de ce système ne réside pas dans une fonctionnalité ponctuelle, mais dans le fait qu'il automatise complètement le suivi post-réunion, cette étape qui traîne si facilement.
Cas d'usage 3 : Base de connaissances personnelle, il suffit d'y jeter un lien
Berman a longtemps eu une douleur : voir un bon contenu, le sauvegarder, puis ne jamais le retrouver.
Sa solution est extrêmement simple : tous les liens dans Telegram, OpenClaw s'occupe du reste.
Le système traite automatiquement ces types de contenu :
-
Articles : Récupère directement le texte intégral, pour les sites avec paywall, utilise l'automatisation du navigateur pour se connecter et extraire après connexion.
-
Vidéos YouTube : Récupère les sous-titres/le texte de transcription.
-
Posts X : Ne capture pas qu'un seul post, suit automatiquement tout le fil de discussion, les articles liés sont aussi ingérés.
-
PDF : Analyse directement le texte.
Tout le contenu est vectorisé (embedding), stocké en local dans SQLite. Ensuite, recherche en langage naturel : « Montre-moi tous les articles sur OpenAI », recherche en un clic.
Bonus collaboration d'équipe : Chaque contenu stocké est automatiquement synchronisé sur Slack sous la forme « Matt veut que vous voyez ça ». L'équipe sait que c'est le patron lui-même qui l'a lu, pas une suggestion aléatoire de l'IA.
La clé de ce cas d'usage n'est pas la complexité technique, mais le seuil d'utilisation très bas. Pas besoin de taguer, de classer, d'organiser. Jetez-le dedans, l'IA fait le reste.
Cas d'usage 4 : Comité de conseil business, 8 experts vous aident à faire le point chaque soir
Personnellement, je pense que c'est le cas d'usage le plus fou de toute la vidéo.
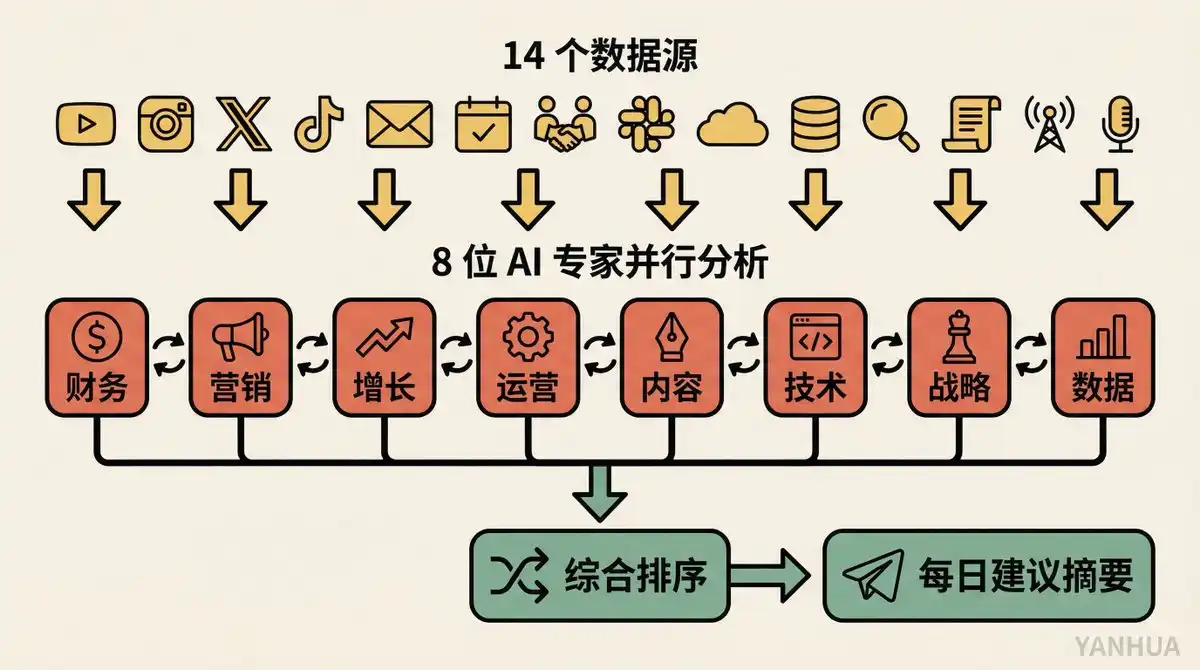
Entrée de données : 14 sources de données business. Analytics YouTube, interactions par post Instagram, analytics X, données TikTok, campagnes email, comptes-rendus de réunion, état des tâches Cron, messages Slack... Couvrant essentiellement toutes les dimensions de son activité.
Processus d'analyse : 8 rôles d'experts IA (Finance, Marketing, Croissance, Opérations, etc.), analysent indépendamment toutes les données, fonctionnent en parallèle. Après analyse, ils discutent entre eux de leurs découvertes, synthétisent les divergences, puis fusionnent en une liste de suggestions triée par priorité.
Mode de livraison : Exécution automatique chaque nuit, les résultats sont envoyés sous forme de résumé numéroté sur Telegram. Berman jette un œil au réveil et peut demander des détails sur n'importe quel point : « Développe le point 3. »
Ce cas d'usage est instructif par son mode de collaboration multi-agents. Ce n'est pas une IA qui vous donne des conseils, mais un groupe d'IA qui débat et vous donne des conseils. Comme un vrai conseil d'administration, les finances disent d'économiser, le marketing dit de dépenser, et on arrive à une solution pragmatique.
Cas d'usage 5 : Comité de sécurité, l'IA inspecte l'IA chaque nuit
Architecture similaire au conseil business, mais orientation complètement différente.
Heure d'exécution : Chaque nuit à 3h30 (décalé des autres tâches pour éviter les conflits de quota d'API Anthropic).
Équipe d'inspection : Quatre experts sécurité sous différents angles. Perspective offensive, perspective défensive, perspective vie privée des données, perspective authenticité opérationnelle.
Périmètre d'inspection : L'ensemble du codebase, l'historique des commits Git, les logs d'exécution, les logs d'erreur, les données stockées. Pas un scan par règles statiques, l'IA lit et comprend vraiment la logique du code.
Sortie : Opus 4.6 synthétise toutes les découvertes, les numérote et les envoie sur Telegram. Les problèmes critiques alertent immédiatement. Berman peut répondre directement « fix it », le système répare automatiquement.
Auto-évolution : L'expérience de chaque correction est mémorisée, les règles d'inspection itèrent continuellement. Certains soirs, il n'y a pas de nouvelles suggestions car le système confirme que l'état actuel est sûr.
Le plus génial dans ce cas d'usage est d'utiliser l'IA pour inspecter l'IA elle-même. Berman est très franc : la protection contre l'injection de prompt ne sera jamais parfaite. Mais plutôt que de faire semblant que le risque n'existe pas, autant que le système fasse son check-up quotidien.
Cas d'usage 6 : Suivi des réseaux sociaux + Briefing quotidien
Périmètre de suivi : Quatre plateformes : YouTube, Instagram, X, TikTok. Capture automatique quotidienne d'instantanés, stockés dans une base de données SQLite.
Dimensions des données : YouTube suit les vues, la durée de visionnage, le taux d'interaction par vidéo ; les autres plateformes suivent les performances au niveau des posts.
Double usage :
-
Briefing quotidien. Envoyé chaque matin sur Telegram, lui disant quel contenu a bien performé hier, lequel a moins bien performé.
-
Nourrit le comité de conseil business. Les données des réseaux sociaux sont l'une des 14 sources de données, participant directement à l'analyse business nocturne.
Ici, on voit l'effet flywheel du système global : le module de suivi des réseaux sociaux ne fonctionne pas isolément, les données qu'il produit servent à la fois au briefing quotidien et au comité de conseil en aval.
Cas d'usage 7 : Pipeline de sujets vidéo, d'une phrase à une carte Asana
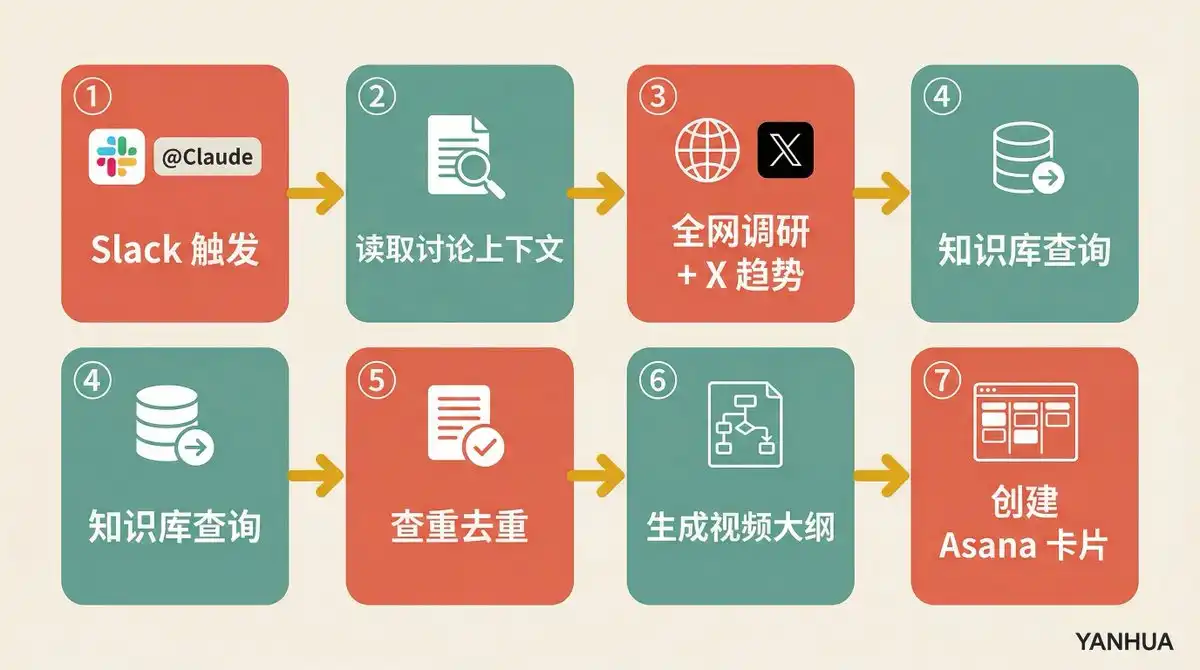
Déclenchement : Dans une discussion Slack, n'importe qui répond à un post par « @Claude, c'est une idée de vidéo ».
Processus automatisé :
-
Lit le contexte complet du fil de discussion Slack
-
Recherche sur le web + veille des tendances X
-
Interroge la base de connaissances pour voir s'il y a du matériel déjà stocké pertinent
-
Vérification des doublons, contrôle si le sujet ne répète pas un sujet existant
-
Génère un plan vidéo complet : suggestions de titre, suggestions de miniature, accroche de début, structure du flux vidéo
-
Fait une évaluation « ce sujet vaut-il la peine d'être fait ? »
-
Crée une carte projet dans Asana, avec toutes les recherches et liens
Berman a démontré un cas réel dans la vidéo : la news de la sortie de Quen 3.5 partagée sur Slack, quelqu'un l'a marquée comme idée vidéo, le système a automatiquement généré un pack de sujet complet, incluant les discussions de différents KOL sur Twitter, les réactions de la communauté open source, et l'angle vidéo suggéré.
La valeur de ce cas d'usage : compresse la distance entre « capture d'inspiration » et « plan exécutable » à presque zéro.
Cas d'usage 8 : Système de mémoire, pour que l'IA vous comprenne de mieux en mieux
L'expérience de la plupart des gens avec ChatGPT est : chaque conversation est comme une première rencontre. Le OpenClaw de Berman, non.
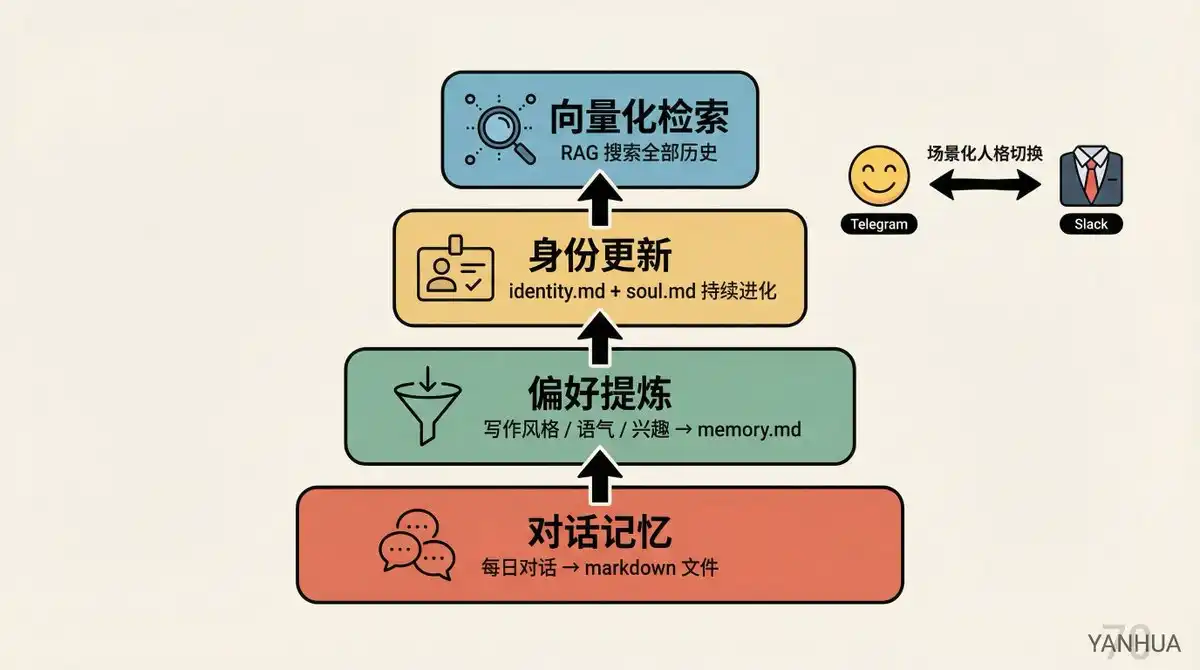
Niveaux de mémoire :
-
Mémoire de conversation : Les conversations quotidiennes sont automatiquement sauvegardées en fichiers markdown
-
Extraction des préférences : Extrait des conversations les préférences d'écriture, le style de ton, les centres d'intérêt, le suivi d'actions, les règles de classement des emails, etc., stockés dans memory.md
-
Mise à jour de l'identité : Au début de chaque nouvelle conversation, le système lit les fichiers de mémoire, met à jour identity.md et soul.md
-
Recherche vectorielle : Tous les fichiers de mémoire sont vectorisés, supportent la recherche RAG
Changement de personnalité contextuel : Berman a donné deux personnalités à l'IA. En chat privé Telegram, c'est comme un ami, humoristique et décontracté ; dans le canal d'équipe Slack, elle devient automatiquement un collègue professionnel. Tout cela est défini dans soul.md.
Ce cas d'usage transforme l'IA d'« outil » en « partenaire ». Elle n'exécute pas juste des instructions, elle comprend vraiment qui vous êtes et ce que vous voulez.
Cas d'usage 9 : Journal alimentaire, l'IA vous aide à découvrir les allergènes
C'est le cas d'usage le plus inattendu.
Mode d'utilisation : Prendre une photo de la nourriture et l'envoyer à OpenClaw, il reconnaît et enregistre automatiquement. Reçoit 3 rappels par jour pour rapporter les sensations gastriques. Toutes les données sont stockées dans un journal alimentaire.
Capacité d'analyse : Déclenche une analyse hebdomadaire, croise les enregistrements alimentaires et les rapports de symptômes, identifie des motifs.
Résultat concret : Le système, en analysant les ingrédients des photos et les retours de symptômes de Berman, a découvert que son estomac était sensible à l'oignon. C'était quelque chose qu'il ignorait complètement.
Un chatbot qui aide quelqu'un à identifier des allergènes alimentaires. Auparavant, cela nécessitait des tests spécialisés à l'hôpital.
Cas d'usage 10 : Tâches planifiées + Sauvegarde auto + Mise à jour auto
Cette partie est moins sexy, mais c'est peut-être l'infrastructure la plus importante.
Liste des tâches Cron :
| Fréquence | Tâche |
|------|------|
| Toutes les 5 minutes | Vérifie les enregistrements de réunion Fathom |
| Toutes les 30 minutes | Scan des emails |
| 3 fois par jour | Vérification de l'achèvement des points d'action |
| Chaque nuit | Synchronisation des documents, scan du CRM, revue de sécurité, ingestion des logs, actualisation des données vidéo, génération du briefing matinal |
| Hebdomadaire | Synthèse de la mémoire, aperçu des revenus |
| Toutes les heures | Commit Git + Sauvegarde de la base de données |
Stratégie de sauvegarde : Toutes les bases de données SQLite sont automatiquement découvertes, chiffrées, compressées et uploadées sur Google Drive, conservation des 7 derniers jours. Code poussé sur GitHub toutes les heures via Git. Toute défaillance de sauvegarde, alerte immédiate sur Telegram.
Mise à jour automatique : Vérifie chaque soir à 21h les nouvelles versions d'OpenClaw, affiche le changelog, un simple « update » met à jour et redémarre automatiquement.
Suivi des API : Enregistre chaque appel LLM, quel modèle a été utilisé, combien de tokens consommés. A même téléchargé les guides de prompting officiels des modèles, pour que le système optimise l'écriture des prompts en fonction du modèle réellement utilisé.
La philosophie de conception de cette infrastructure est simple : quand vous dormez, le système travaille ; quand le système a un problème, vous le savez immédiatement.
Génération d'images et vidéos : Création de contenu visuel à la demande
Berman a connecté Veo (génération vidéo) et NanoBanana Pro (génération d'images Gemini) à OpenClaw.
Le mode d'utilisation est simple : dire dans Telegram « vidéo d'une villa toscane italienne », le système appelle Veo pour générer, télécharge automatiquement et envoie sur Telegram, puis supprime le fichier local pour économiser de l'espace. Idem pour les images, dire ce qu'on veut, NanoBanana Pro génère et envoie directement.
Ce cas d'usage en lui-même n'est pas époustouflant, mais sa valeur est de pouvoir être intégré dans d'autres workflows. Par exemple, quand le pipeline de sujets vidéo génère des suggestions de miniature, il peut directement appeler la génération d'images pour produire l'image.
Retour à la vue d'ensemble : Les relations entre ces cas d'usage sont le point clé
Si vous ne regardez que des cas d'usage individuels, vous penserez « Cool, mais pas si spécial que ça ». ChatGPT peut aussi chercher des contacts, Notion AI peut aussi organiser une base de connaissances.
Mais la vraie puissance du système de Berman réside dans la circulation des données entre les cas d'usage :
-
Données du CRM → Nourrit le comité de conseil business
-
Contenu de la base de connaissances → Nourrit le pipeline de sujets vidéo
-
Données des réseaux sociaux → Nourrit le briefing quotidien + le comité de conseil
-
Comptes-rendus de réunion → Nourrit le CRM + le système de points d'action
-
Les logs d'exécution de tous les modules → Nourrit le comité de sécurité
Chaque module n'est pas une île. Ils forment une roue de données qui se renforce mutuellement. C'est pourquoi une personne + un MacBook peut produire l'effet d'une petite équipe.
Berman a une phrase très juste : « Vous commencez à voir comment toutes les différentes parties que j'ai construites interagissent et se renforcent mutuellement. »
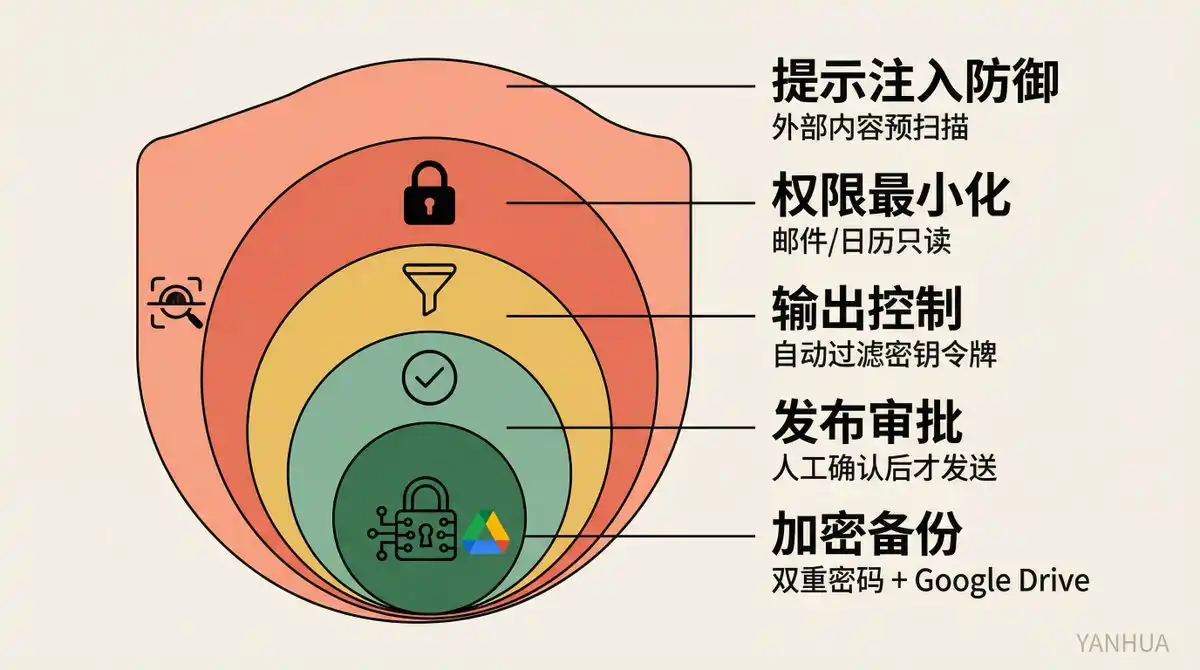
Rappel de sécurité : Attachez votre ceinture avant de démarrer
Le travail de Berman sur la sécurité mérite d'être souligné séparément :
-
Défense contre l'injection de prompt : Tout contenu externe est considéré comme potentiellement malveillant, pré-scan du code déterministe avant stockage
-
Privilèges minimum : Emails, calendrier en lecture seule, pas de permissions d'écriture
-
Contrôle de la sortie : Résume sans paraphraser mot à mot, filtre automatiquement les clés et jetons
-
Approbation avant publication : Confirmation humaine obligatoire avant d'envoyer un email, un tweet
-
Sauvegarde chiffrée : Double protection par mot de passe, le fichier .env n'est jamais stocké dans le dépôt
Il le dit très clairement lui-même : « Il n'y a pas de solution de sécurité parfaite. Les grands modèles de langage sont des systèmes non déterministes, il est impossible de se protéger complètement contre l'injection de prompt. Mais cela ne signifie pas qu'il ne faut rien faire. »
Après avoir vu ces cas d'usage, ma plus grande impression est : le « full-stack » de l'ère de l'IA ne signifie plus savoir coder le front-end et le back-end, mais signifie pouvoir construire et gérer un ensemble complet de workflows IA. Berman ne code pas, mais il a une perception extrêmement claire de ses besoins et sait comment les traduire en langage naturel en un système fonctionnel.
C'est probablement la compétence la plus digne d'être apprise en 2026.
Basé sur la vidéo de Matthew Berman « 21 INSANE Use Cases For OpenClaw », compilé par le podcast Podwise, la vidéo originale contient le prompt complet pour chaque cas d'usage, recommandé de la regarder pour les obtenir. Si vous utilisez aussi OpenClaw ou un framework similaire pour construire votre propre système IA, dites dans les commentaires quel cas d'usage vous avez construit en premier.





