【Introduction】C'est fou ! Les données d'évolution de l'IA récemment mesurées par Meta et METR coïncident parfaitement avec la « loi de densité » proposée il y a deux ans par une équipe chinoise. La Silicon Valley se retourne soudainement et découvre que les chercheurs chinois ont deux ans d'avance sur cette voie !
Les trois institutions de recherche en IA les plus sérieuses au monde sont entrées en collision collective la semaine dernière !
Le 3 avril, l'institution de recherche américaine METR a discrètement mis à jour un rapport technique, résumant sa conclusion principale en une phrase.
La capacité de l'IA double tous les 88,6 jours.
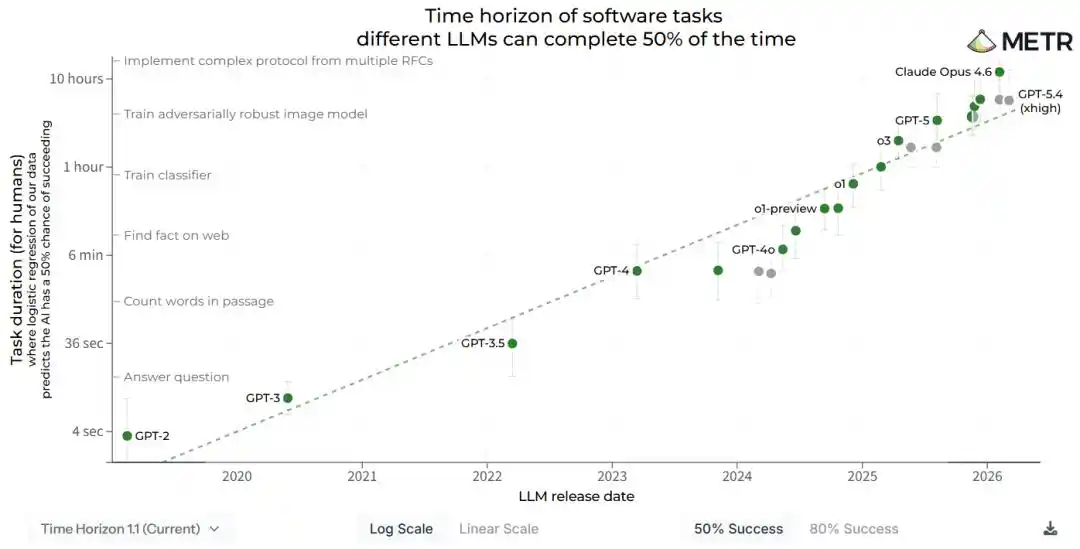
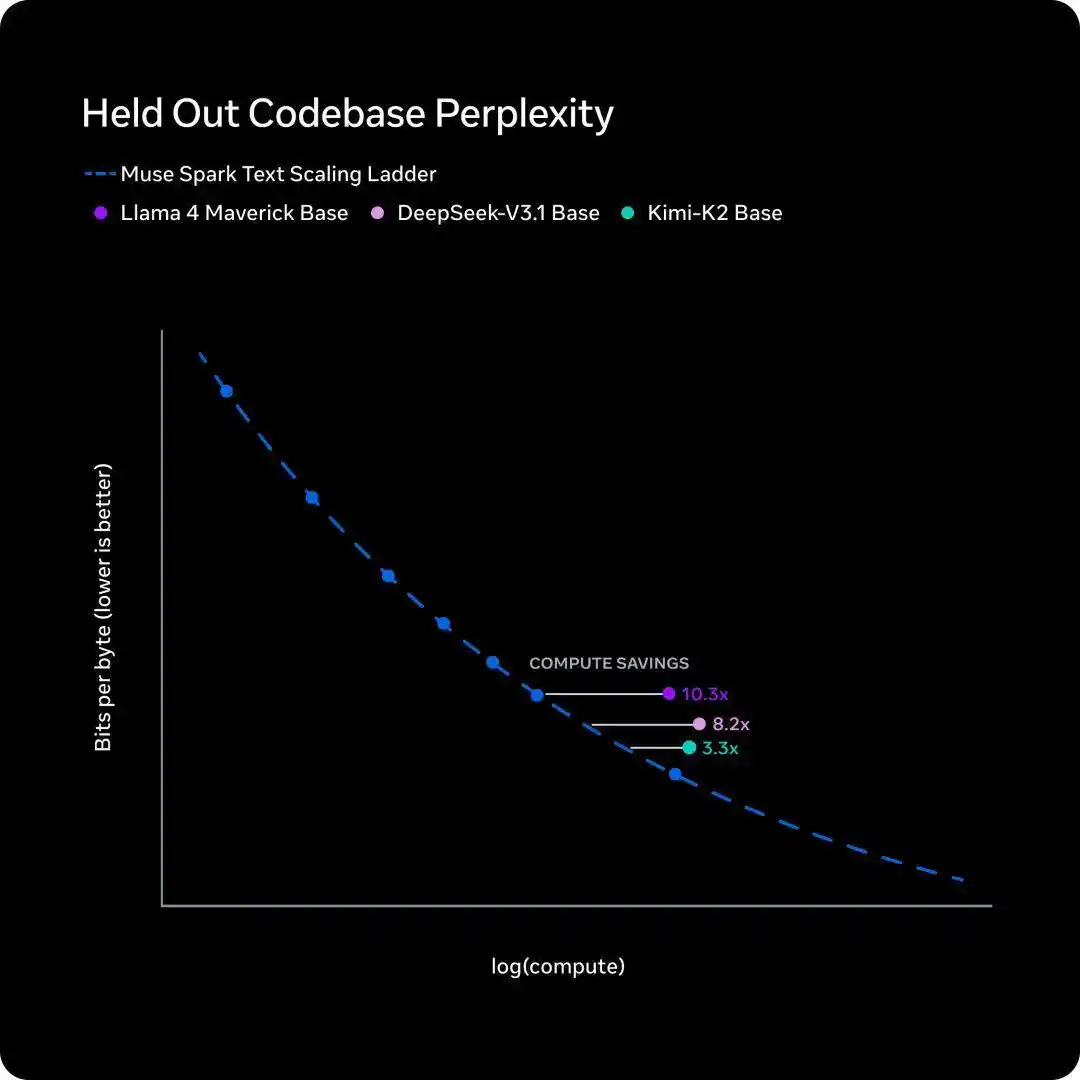
Cinq jours plus tard, le 8 avril, le Meta Super Intelligence Lab a publié un nouveau modèle, Muse Spark, présentant une courbe d'efficacité d'entraînement appelée en interne « scaling ladder », dont la conclusion est également une phrase.
Pour atteindre les performances du Llama 4 Maverick d'il y a un an, le nouveau modèle n'a besoin que de moins d'un dixième de la puissance de calcul d'entraînement.
L'un mesure la durée des tâches, l'autre la puissance d'entraînement. Les deux institutions n'ont aucun lien, et leurs méthodes de recherche ne se chevauchent pas.
Mais lorsque les deux courbes sont converties dans le même système de coordonnées, leurs pentes coïncident presque parfaitement.
Jusqu'ici, c'était déjà assez incroyable.
Ce qui l'est encore plus, c'est que cette courbe avait été tracée intégralement il y a deux ans par une équipe chinoise, et avait été publiée dans un journal affilié à Nature.
Elle s'appelle la loi de densité.

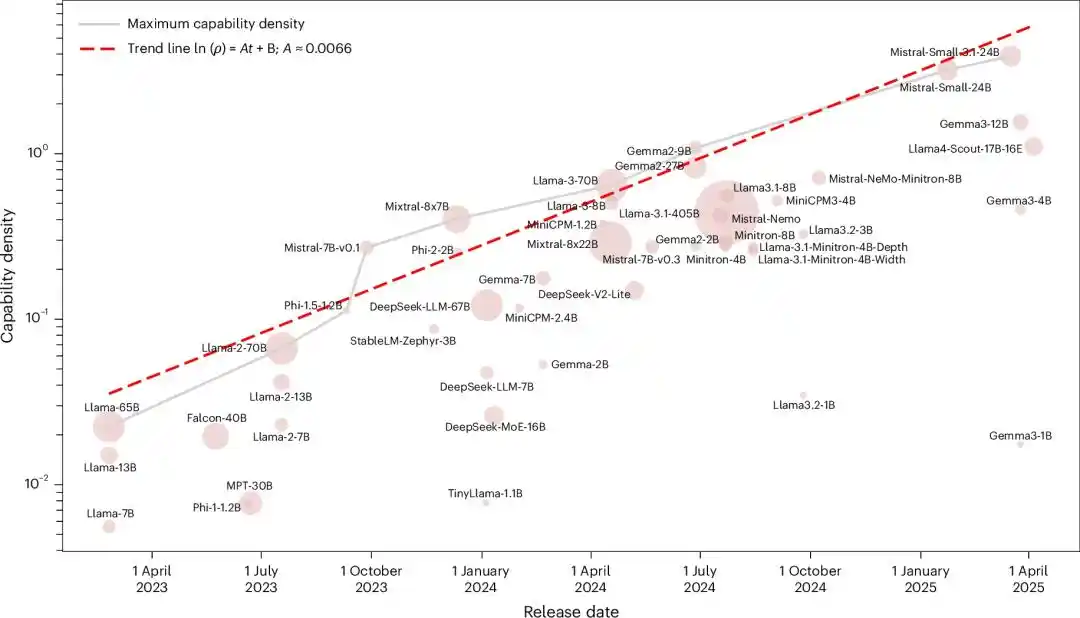
Il y a deux ans, quelqu'un avait déjà tracé cette ligne
Ce concept est apparu pour la première fois dans un article intitulé « Densing Law of LLMs ».
Les auteurs étaient une équipe conjointe de Smart Surface (面壁智能) et de l'Université Tsinghua, dirigée par les professeurs Sun Maosong et Liu Zhiyuan, avec le doctorant Xiao Chaojun comme premier auteur.
L'article a été mis en ligne sur arXiv en décembre 2024 et accepté par Nature Machine Intelligence en novembre 2025.

Adresse de l'article : https://arxiv.org/abs/2412.04315

Adresse de l'article : https://www.nature.com/articles/s42256-025-01137-0
Le jugement central de l'article ne tient qu'en une phrase.
La densité d'intelligence du modèle augmente de façon exponentielle avec le temps, et le nombre de paramètres requis pour atteindre un niveau d'intelligence spécifique diminue de moitié tous les 3,5 mois.
Fin 2024, cette affirmation semblait un peu radicale.
A cette époque, toute l'industrie vénérait la « scaling law ». OpenAI empilait les modèles, Anthropic empilait les modèles, Meta aussi empilait les modèles.
Tout le monde pensait que plus les paramètres étaient grands, plus l'intelligence était forte, et que la voie royale était de pousser les GPU à leur limite.
Mais l'équipe de recherche ne voyait pas les choses ainsi.
Ils ont placé tous les modèles de base open source influents de l'époque, de Llama-1 à Gemma-2 et MiniCPM-3, soit 51 modèles au total, dans la même échelle pour les mesurer.
Après avoir exécuté cinq benchmarks, le résultat était une relation exponentielle presque parfaite, avec un R² atteignant 0,934.
Considérant que l'évaluation des grands modèles est facilement biaisée par la contamination des données, ils ont retesté avec un nouvel ensemble de données filtré contre la pollution, MMLU-CF. R²=0,953.
Les deux ajustements ont obtenu un R² proche de 1. Statistiquement, il est presque impossible que ce soit une coïncidence.
En d'autres termes, chaque modèle open source majeur publié ces deux dernières années, quelle que soit l'équipe ou l'architecture utilisée, s'est situé sur la même ligne exponentielle de « doublement tous les 3,5 mois ».
Jusqu'ici, l'histoire n'était que « une équipe chinoise a proposé une loi empirique qui semble radicale ».
Ce qui a vraiment transformé cela en un « moment », c'est ce qui s'est passé au cours des six mois suivants.
Trois institutions, trois méthodes, une même pente
Examinons les conclusions des trois parties : Smart Surface, Meta, METR.
- La loi de densité de Smart Surface mesure « combien de paramètres sont nécessaires pour un même niveau d'intelligence ». La conclusion est que le besoin en paramètres diminue de moitié tous les 3,5 mois.
- Le « scaling ladder » de Meta mesure « combien de puissance de calcul d'entraînement est nécessaire pour un même niveau d'intelligence ». La conclusion est que Muse Spark économise un ordre de grandeur par rapport au Llama 4 Maverick d'il y a un an.
- Le rapport sur l'horizon temporel de METR mesure « la longueur de tâche qu'un même modèle peut gérer ». La conclusion est que la durée des tâches double tous les 88,6 jours.
Trois mesures. Trois institutions académiques. Trois chemins de recherche sans aucun chevauchement.
Mais lorsque tous les chiffres sont convertis dans le même système de coordonnées, les pentes de leurs courbes coïncident presque parfaitement.
Le point le plus facilement négligé est que la loi de densité est la première des trois à avoir été proposée. Près de deux ans avant le « scaling ladder » de Meta, et plus d'un an avant la modélisation complète de METR.
Et lorsque Meta a tracé cette courbe « scaling ladder » dans son blog de publication début avril, ils ne se sont probablement pas rendu compte que la forme de ce graphique était presque identique à celle d'une courbe sur une présentation PPT d'une conférence académique à Pékin en 2024.
Quelle observation mérite le nom de « loi »
Dans le monde scientifique, il existe un ensemble de critères informels pour juger si une observation empirique mérite d'être appelée une « loi ».
Ce n'est pas la beauté des données qui compte, mais sa capacité à tenir dans plusieurs systèmes de mesure indépendants.
La loi de Moore est une loi parce que l'industrie des semi-conducteurs l'a validée maintes et maintes fois sur des décennies, sous trois angles complètement différents : la précision de la photolithographie, la densité des transistors, le coût par unité de calcul.
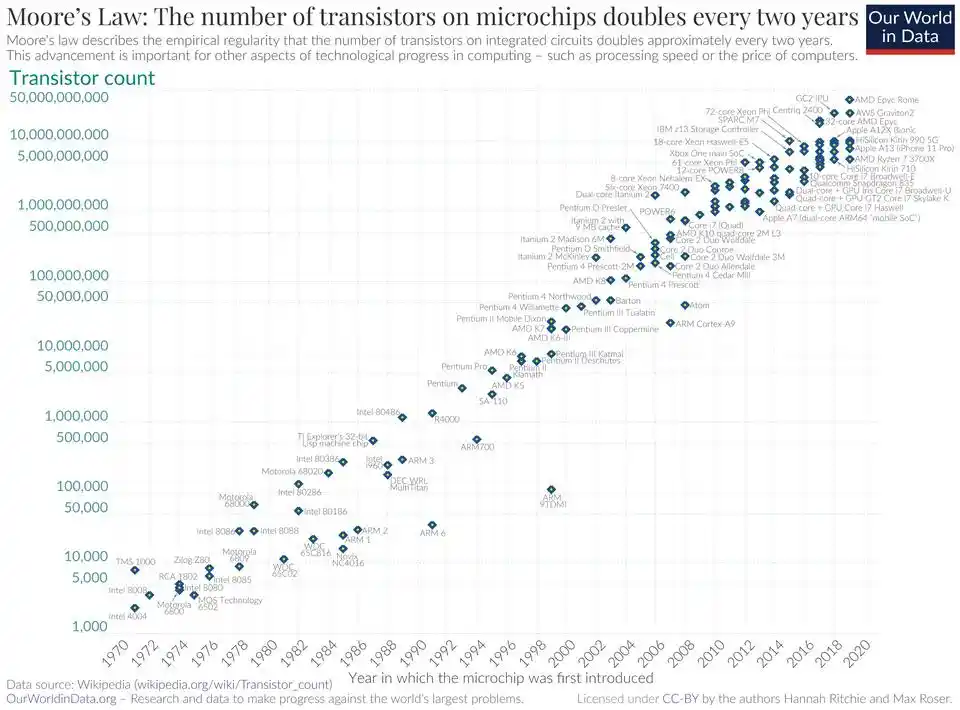
La loi de densité suit le même chemin.
Au début, ce n'était qu'une courbe d'ajustement provenant d'une seule équipe. Au moment de son acceptation par Nature Machine Intelligence, elle pouvait déjà être reproduite sur un ensemble de données filtré contre la pollution. Et ce mois-ci, elle a été validée indépendamment deux fois de plus, dans les données d'entraînement de Meta et les évaluations de tâches de METR.
Placé dans un système de coordonnées plus large, ce moment ressemble étrangement aux années 1880, lorsque l'électricité est entrée à New York.
À cette époque aussi, plusieurs inventeurs différents, ingénieurs différents, villes différentes, travaillaient chacun sur leur propre réseau électrique. Jusqu'à ce que quelqu'un trace les courbes de développement de tous les projets sur une même feuille de papier, et que les gens réalisent soudain. Ce n'était pas quelques progrès techniques dispersés, c'était une nouvelle ère qui se déployait discrètement.
Sauf que cette fois, il a fallu moins d'un an entre la publication de l'article et sa validation par des pairs mondiaux.
Trois推论 (inférences), chacune réécrit les hypothèses de l'industrie
Si la loi de densité tient debout, elle va réécrire beaucoup de choses simultanément.
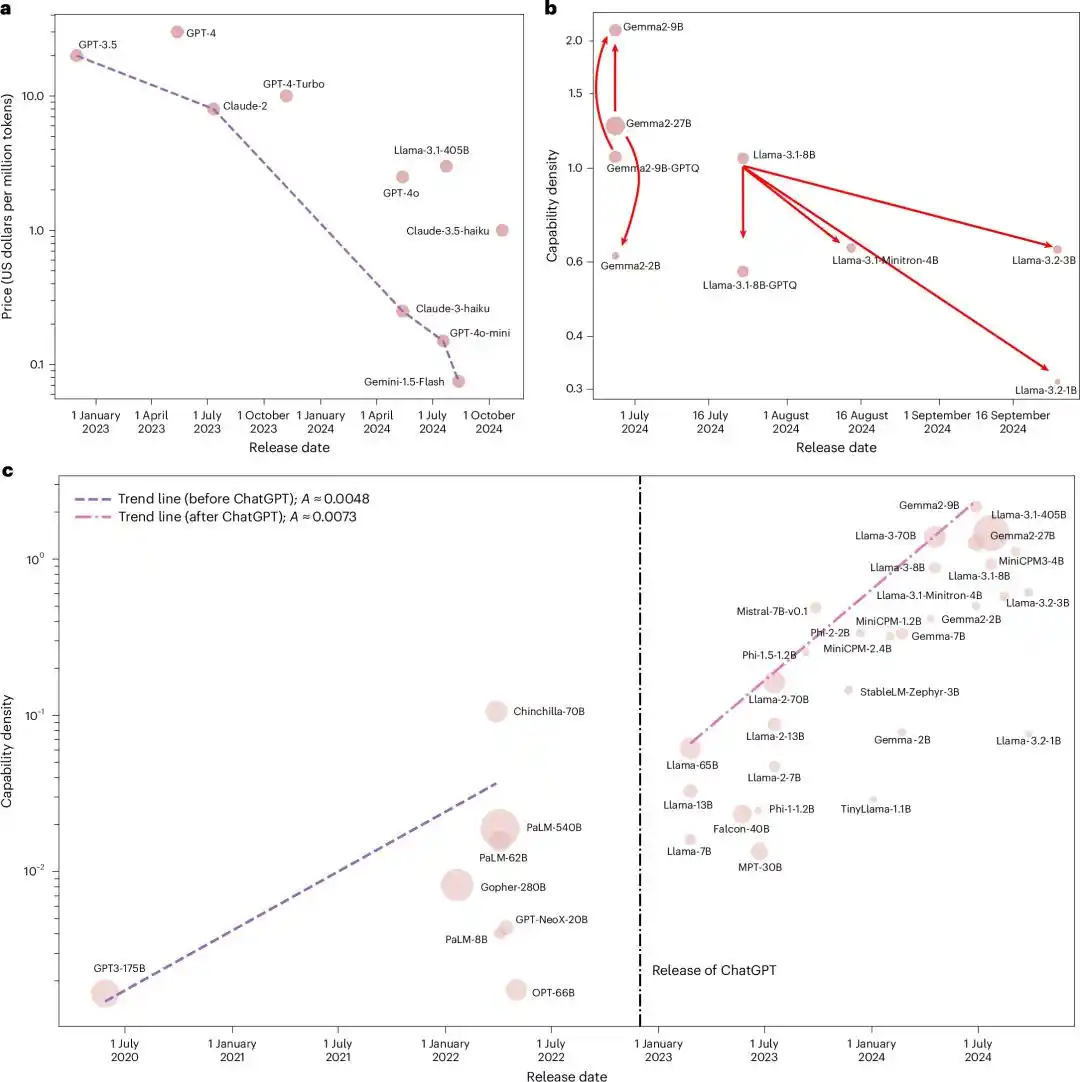
Premièrement, le coût de l'inférence s'effondrera plus vite que prévu par tous.
Une inférence de la loi de densité est que le coût de l'inférence pour un LLM de performances similaires diminue probablement de moitié environ tous les 2,6 mois.
Aujourd'hui, cette baisse a déjà été dépassée par la réalité.
Les dernières données de suivi d'Epoch AI montrent que pour les LLM atteignant le niveau de performance de Claude 3.5 Sonnet, le prix par token a baissé de 400 fois au cours de la dernière année. La baisse la plus rapide pour ce niveau de performance a atteint 900 fois/an.
Le niveau tarifaire de GPT-3.5 fin 2022, à 20 dollars par million de tokens, coûte aujourd'hui seulement 0,02 dollar avec Mistral Nemo, 1000 fois moins cher, et le modèle est plus performant.
Rétrospectivement, les prédictions de l'article étaient conservatrices.
Deuxièmement, le point de rupture de l'intelligence on-device est plus proche que tout le monde ne le pensait.
Multiplier la loi de densité par la loi de Moore donne un chiffre encore plus stimulant.
Selon les estimations actuelles, la taille maximale effective du modèle pouvant fonctionner sur une puce au même prix double environ tous les 88 jours.
Ce chiffre concorde presque parfaitement avec les 88,6 jours calculés par METR. Deux chemins de calcul complètement différents sont entrés en collision après la décimale.
Dans les trois à cinq prochaines années, faire tourner un modèle de niveau GPT actuel sur un ordinateur portable ordinaire, voire un téléphone portable, pourrait ne plus être de la science-fiction.
Troisièmement, la stratégie optimale de l'industrie des grands modèles est en train de s'inverser discrètement.
Au cours des trois dernières années, la compréhension par l'industrie de la « scaling law » est restée bloquée sur « empiler les paramètres et les données ».
Mais la loi de densité donne un jugement contre-intuitif. Dans un contexte de croissance exponentielle continue de la densité, tout modèle le plus performant à un instant donné n'a qu'une fenêtre d'optimalité de quelques mois.
Miser toutes les ressources pour entraîner un modèle plus grand, puis attendre trois mois pour qu'il soit surpassé par un nouveau modèle deux fois plus petit, n'est pas rentable sur le plan économique.
La voie vraiment durable est d'investir les ressources dans l'amélioration de la densité elle-même. De meilleures architectures, des données de meilleure qualité, des algorithmes d'entraînement plus intelligents.
Smart Surface, avançant toujours selon l'échelle qu'elle a elle-même tracée
Il convient de mentionner que la loi de densité n'est pas un article publié puis oublié.
Smart Surface (面壁智能), qui a proposé cette théorie, a passé les deux dernières années à la vérifier avec sa propre série de modèles « Little Cannon » (小钢炮, MiniCPM).
Lorsque le MiniCPM-1-2.4B a été publié en février 2024, ses scores égalait ou dépassait ceux du Mistral-7B de septembre 2023. Autrement dit, en quatre mois, avec 35% des paramètres, il atteignait des performances équivalentes.
Ce chiffre a été directement inscrit dans l'article de Nature Machine Intelligence, comme première preuve empirique de la loi de densité.
Depuis, la série Little Cannon a été open source tout du long, couvrant les quatre grandes directions : texte, multimodal, voix, pleine modalité, avec des paramètres inférieurs à 10B. Cette exhaustivité en open source, en Chine, seule Alibaba, outre Smart Surface, l'a atteinte.
Jusqu'à présent, la série Little Cannon a dépassé les 24 millions de téléchargements open source dans le monde.
Ce n'est pas le plus grand modèle de l'industrie. Mais c'est la première équipe de l'industrie à avoir exécuté la priorité à la « densité » comme méthodologie d'entreprise.
Et lorsque Meta et METR ont validé la loi de densité à leur manière durant la semaine d'avril 2026, cette entreprise chinoise qui a commencé à entraîner des modèles selon cette méthodologie dès 2024, avait en réalité deux ans d'avance en expérience technique.
Cette fois, les chercheurs chinois se tiennent au point de départ de la courbe
Un cadre théorique proposé il y a deux ans par une équipe de recherche chinoise est en train d'être redécouvert, chacun à sa manière, par des institutions étrangères des plus sérieuses comme Meta et METR.
Le poids de cet événement pourrait prendre un peu de temps pour être pleinement compris.
Ce n'est pas une histoire de « nous aussi, nous pouvons le faire ». C'est une histoire de « nous l'avons vu un peu plus tôt ».
De tels instants ne sont pas si fréquents dans l'histoire des sciences. Un jugement mis en doute en 2024 est devenu en 2026 une même courbe pointée par plusieurs preuves indépendantes.
Ce genre de « coïncidence » transrégionale, transméthode, transinstitutionnelle, s'est produit quelques fois en physique, chacune marquant la fin d'un ancien paradigme et le début d'un nouveau.
Cette fois, les chercheurs chinois en IA se tiennent à ce point de départ.
Et cette courbe continue de monter, doublant tous les 88 jours.
Références :
La « loi de densité »首创 (pionnière) de Smart Surface, reconnue par Meta et d'autres institutions étrangères de premier plan
https://arxiv.org/abs/2412.04315
https://www.nature.com/articles/s42256-025-01137-0
https://metr.org/blog/2026-1-29-time-horizon-1-1/
https://ai.meta.com/blog/introducing-muse-spark-msl/
Cet article provient du compte WeChat public « 新智元 » (New Zhi Yuan), édité par Hao Kun et Taozi







