Auteur : Aying, Produit IA
J'ai lu un article de blog de l'équipe Anthropic intitulé « Lessons from building Claude Code: How we use skills ». C'est probablement le résumé pratique le plus approfondi sur les Skill que j'ai vu à ce jour.
Le concept de Skill n'est pas très compliqué, mais pour vraiment bien les maîtriser, je pense que ce n'est pas si facile non plus.
Je me souviens que lorsque les Skill ont commencé à être à la mode, tout le monde aimait créer des Skill de style d'écriture, des Skill de rédaction. On avait l'impression qu'il suffisait d'y insérer son propre style d'écriture pour que le modèle puisse produire de manière stable des textes dans ce style.
Mais après avoir testé moi-même plusieurs approches, j'ai réalisé que souvent, cela ne fonctionnait tout simplement pas.
Parce qu'un Skill de style pouvait contenir des milliers, voire des dizaines de milliers de caractères. Le simple chargement du Skill occupait déjà une grande partie du contexte. Plus le contexte est lourd, plus la capacité de réflexion du modèle a tendance à diminuer.
Il arrivait souvent ceci : le style était bien appris, mais le contenu devenait superficiel, et la capacité d'analyse s'affaiblissait aussi.
Il y a aussi une autre situation courante.
Beaucoup de gens, lorsqu'ils écrivent un Skill, aiment y mettre toutes sortes d'instructions opérationnelles. Première étape, faire ceci, deuxième étape, faire cela, troisième étape, etc. Mais en pratique, on se rend compte que l'exécution par le modèle n'est pas stable.
J'ai compris plus tard que beaucoup de ce travail répétitif était en fait plus adapté à être intégré dans des Scripts plutôt que d'être écrit sous forme de longues Instructions.
Après avoir lu cet article d'Anthropic, ma plus grande impression est que beaucoup de gens utilisent des Skill, mais ne les comprennent pas vraiment.
Fondamentalement, un Skill consiste à faire de l'ingénierie de contexte. Il y a beaucoup d'expérience à acquérir pour savoir quand il faut intégrer des connaissances dans un Skill, quand il faut les diviser en Références, quand il faut les écrire en Scripts, et quand il faut utiliser des Gotchas pour contraindre le modèle.
Après avoir compris le principe de fonctionnement des Skill, en regardant à nouveau les Skill performants, on se rend compte qu'ils ne résolvent jamais un problème de prompt, mais plutôt des problèmes de contexte, de capitalisation d'expérience et de réutilisation de capacités.
Si vous voulez étudier les Skill en profondeur, je recommande vivement deux articles :
https://claude.com/blog/lessons-from-building-claude-code-how-we-use-skills
https://research.perplexity.ai/articles/designing-refining-and-maintaining-agent-skills-at-perplexity
#01 Ne pas écrire de banalités
Un Skill consiste fondamentalement à capitaliser les « connaissances tacites » d'une organisation. Donc, ne répétez pas dans un Skill les choses de bon sens qu'il connaît déjà. Ce qui a vraiment de la valeur, ce sont les informations que le modèle ne connaît tout simplement pas.
Chez Anthropic, ils insistent souvent : ce qu'il faut vraiment écrire dans un Skill, ce sont les Gotchas, c'est-à-dire les pièges dans lesquels on tombe souvent.
Par exemple :
1. Cette table ne peut pas être triée par created_at
2. Un retour 200 de staging ne signifie pas le succès
3. request_id et trace_id sont la même chose
Parce que ces informations existent souvent dans l'expérience des employés. Il faut donc toujours se rappeler quelle est l'essence d'un Skill.
Skill = Mettre par écrit l'expérience du vieux routier.
Grâce au Skill, on capitalise les expériences qui étaient auparavant dispersées dans la tête de différentes personnes.
#02 Un Skill, c'est en fait de l'Ingénierie de Contexte
C'est probablement l'un des points de vue les plus profonds d'Anthropic.
Un Skill n'est pas un fichier markdown, mais un dossier. Pour ceux qui ont déjà utilisé des Skill, cette affirmation peut sembler une évidence.
Mais j'y ai réfléchi ces derniers jours, et j'ai progressivement réalisé : c'est précisément par cette forme de dossier qu'ils veulent exprimer le concept d'Ingénierie de Contexte.
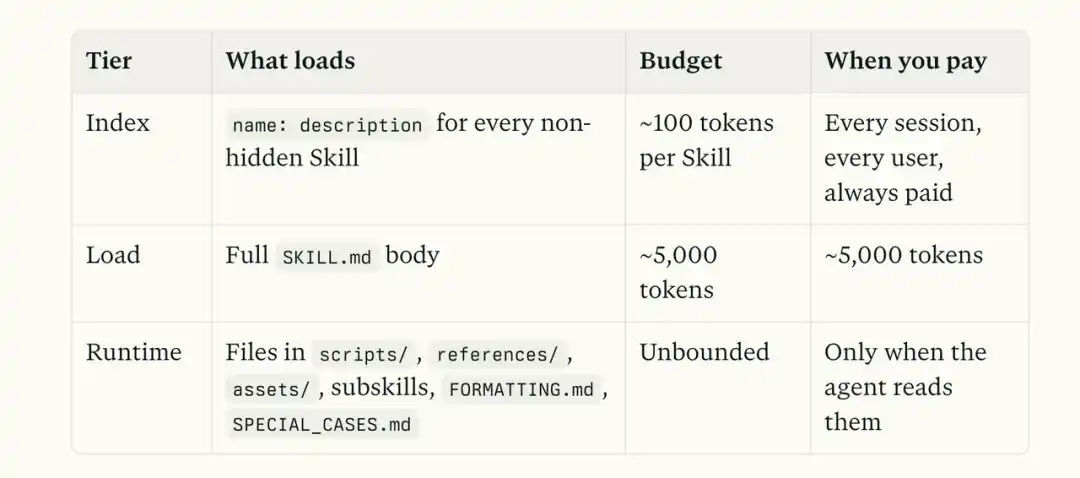
Re-regardons la structure typique d'un Skill :
skill/ ├── SKILL.md ├── references/ (détails, références API, conditions limites) ├── scripts/ (scripts exécutables) ├── examples/ (exemples) ├── assets/ (modèles, images, ressources fixes)
Lors de l'appel d'un Skill, le modèle lit d'abord SKILL.md. Si nous mettons toutes les informations dans ce fichier, le contexte explosera rapidement.
Imaginons un Skill de dépannage de paiement qui contient à la fois les explications des codes d'erreur Stripe, des cas historiques de pannes, des scripts de diagnostic et un modèle de rapport final.
Si tout ce contenu est entassé dans SKILL.md, à chaque appel du Skill, Claude doit tout relire.
Même si l'utilisateur veut juste vérifier la signification d'un code d'erreur, ou comprendre pourquoi un statut de paiement n'est pas mis à jour. Une grande quantité d'informations inutiles sera également intégrée dans le contexte.
Mais l'approche d'Anthropic est complètement différente.
SKILL.md ressemble plus à une page de navigation. Sa responsabilité est d'indiquer au modèle que, face à une erreur Stripe, il doit aller chercher les explications correspondantes dans « references ».
S'il a besoin de consulter des cas historiques, il va chercher des problèmes similaires dans « examples » ; s'il doit réellement exécuter des actions de diagnostic, il exécute les scripts dans « scripts » ; et enfin, pour générer le rapport de dépannage, il utilise les modèles dans « assets ».
Tout le processus est une exposition progressive.
Je vous recommande vivement de garder l'image ci-dessous.
#03 Utiliser des scripts autant que possible
Ne laissez pas le modèle gaspiller son contexte limité et sa capacité de raisonnement dans des tâches répétitives. Confiez ces tâches aux scripts.
Par exemple. Beaucoup de gens, lorsqu'ils écrivent un Skill, écrivent comme ça :
1. Interroger les données d'inscription ; 2. Interroger les données de paiement ; 3. Calculer le taux de conversion ; 4. Analyser les causes des anomalies.
Cette façon d'écrire n'est évidemment pas un problème. Le modèle peut le faire. Mais à chaque exécution, il doit recommencer tout le processus d'analyse depuis le début.
Interroger les données, les organiser, gérer diverses conditions limites, tout ce travail est en fait répétitif.
Puisque ces capacités ont déjà été vérifiées d'innombrables fois, pourquoi faire réinventer la roue au modèle ? Il vaut mieux fournir directement des scripts spécifiques.
De plus, grâce aux scripts, l'exécution du Skill sera plus précise et consommera moins de Tokens.
Sous cet angle, les Scripts dans un Skill capitalisent en fait les capacités organisationnelles. Derrière chaque script, il y a souvent la meilleure pratique que l'équipe a résumée après être tombée dans d'innombrables pièges.
Après avoir figé ces capacités, Claude peut travailler en se basant sur cette expérience à chaque fois, plutôt que de recommencer de zéro encore et encore.
C'est pourquoi je pense de plus en plus que, dans un Skill, les Instructions et les Scripts résolvent des problèmes à deux niveaux différents.
Les Instructions fournissent de l'expérience et du jugement, les Scripts fournissent des capacités et de l'exécution.
Par exemple, dans un Skill de dépannage de paiement, il pourrait y avoir cette phrase :
Si Stripe renvoie 200, ne pensez pas directement que le paiement est réussi, vous devez vérifier davantage la table payment_events.
Cela relève des Instructions. Car c'est de l'expérience. Et check_payment_events() relève des Scripts, car c'est une capacité d'exécution.
S'il n'y a que des Scripts, le modèle sait comment vérifier, mais ne sait pas forcément pourquoi vérifier.
S'il n'y a que des Instructions, le modèle sait qu'il doit vérifier. Mais il doit réimplémenter à chaque fois. Les deux sont indispensables.
#04 La Description ressemble plus à une règle de routage
Beaucoup de gens écrivent naturellement mal la Description d'un Skill.
Parce qu'on a l'habitude de l'écrire comme une présentation de fonctionnalités. Par exemple : Le Skill de Gestion des PR aide les utilisateurs à surveiller l'état des PR, à traiter les problèmes CI, à effectuer automatiquement les Merges.
Mais le problème est que le modèle ne recherche pas un Skill par ses fonctionnalités. Au démarrage de Claude Code, il scanne d'abord le nom et la Description de tous les Skill.
Ensuite, en fonction du problème actuel de l'utilisateur, il détermine quel Skill il doit charger.
Donc, l'information la plus importante dans la Description n'est pas ce que ce Skill peut faire, mais dans quelle situation il doit être chargé.
La Description assume en fait la tâche de routage de tout le Skill.
Dans le monde réel, peu de gens diront « aide-moi à appeler un outil de gestion de PR ». Les gens sont plus susceptibles de dire : « aide-moi à surveiller cette PR », « CI est encore en panne », etc.
Donc une bonne Description devrait décrire autant que possible l'intention de l'utilisateur, plutôt que d'énumérer des fonctionnalités.
Je pense même qu'on peut utiliser une méthode très simple pour vérifier.
Après avoir écrit la Description, supprimez tout le Skill et ne gardez que cette ligne de Description. Demandez-vous ensuite : après avoir vu la question de l'utilisateur, le modèle peut-il savoir quand il doit charger ce Skill ?
S'il ne le peut pas, alors il faut probablement continuer à le modifier.
#05 Gestion et distribution des Skill
Il y a aussi un point concernant la gestion des Skill.
Quand une seule personne utilise des Skill, c'est très simple. On écrit soi-même quelques Skill, on les maintient, on les met à jour soi-même. Mais je crois que la plupart des équipes finiront par rencontrer le même problème.
Lorsque les Skill passent de quelques-uns à des dizaines, voire des centaines, comment gérer ces Skill ? Comment les mettre à niveau ? Comment les distribuer aux membres de l'équipe ?
L'expérience d'Anthropic à ce sujet est, je pense, assez digne d'intérêt.
Quand l'équipe est de petite taille, les Skill suivent directement le dépôt de code. Il suffit de les placer dans le répertoire .claude/skills du projet. Tout le monde partage le même ensemble de Skill et la même méthode de travail.
Mais à mesure que le nombre de Skill augmente, un nouveau problème apparaît.
Au démarrage de Claude Code, il scanne le nom et la Description de tous les Skill, puis décide quel Skill appeler pour la tâche en cours. Plus il y a de Skill, plus le coût de routage est élevé.
C'est aussi pourquoi Anthropic a commencé à créer un Marketplace. Mais ce qui est plus intéressant, c'est leur façon de gérer le Marketplace.
Beaucoup d'entreprises, face à ce type de problème, ont souvent comme premier réflexe d'établir un processus d'approbation. Celui qui écrit un Skill doit d'abord soumettre une demande ; après approbation, il peut entrer dans la bibliothèque officielle de Skill. Nous l'avons aussi fait en interne, mais c'était très lourd. De la gestion pour la gestion.
J'ai constaté que chez Anthropic, l'organisation est très légère.
Laissez les nouveaux Skill se propager d'abord à petite échelle, laissez les collègues les installer eux-mêmes, les tester eux-mêmes.
Si de plus en plus de personnes commencent à les utiliser, cela signifie que ce Skill résout réellement un problème concret. À ce stade, l'auteur peut le soumettre au Marketplace officiel.
Donc, ils ne discutent pas d'abord de la valeur d'un Skill, mais le laissent d'abord être testé dans des scénarios d'utilisation réels. S'il est utilisé par beaucoup de monde, il entre naturellement dans le système officiel. Ainsi, les Skill qui restent sont essentiellement ceux dont l'équipe a réellement besoin.





