Le coût de l'inférence IA a chuté de plus de 80 % en 18 mois, mais les trois grands fournisseurs de cloud chinois ont annoncé une hausse des prix la même semaine. Il s'agit d'un jeu structurel de prix qui durera au moins deux à trois ans. Cet article tente de répondre à une question plus importante : quand cela se terminera-t-il ?
Demain (18 avril), Alibaba Cloud et Baidu AI Cloud commenceront officiellement à ajuster leurs prix. Trois semaines plus tard, Tencent Cloud connaîtra également une nouvelle hausse de prix. À l'échelle mondiale, OpenAI et Anthropic ont réduit le prix de leurs API de plus de 80 % au cours des 18 derniers mois, et l'émergence de DeepSeek-R1 a renforcé la conviction que le coût de l'inférence allait bientôt atteindre zéro.
Résultat : les trois grands fournisseurs de cloud chinois ont annoncé une hausse de prix de 20 % à 30 % la même semaine.

Figure | Chronologie des événements de hausse des prix du cloud computing mondial en 2026
La première réaction des médias a été : "La guerre des prix est terminée, les grands acteurs commencent à récolter". Cette affirmation n'est pas fausse, mais elle s'arrête à l'interprétation la plus superficielle. Elle explique pourquoi les fournisseurs de cloud augmentent leurs prix, mais ne répond pas à la question clé : Cette hausse des prix est-elle une correction temporaire ou le point de départ d'une tendance durable ? La réponse se cache dans un paradoxe économique vieux de 150 ans.
01.
Le paradoxe de Jevons : Moins c'est cher, plus on en brûle
En 1865, l'économiste britannique William Jevons a observé un phénomène contre-intuitif : après l'amélioration de l'efficacité des machines à vapeur, la consommation totale de charbon en Grande-Bretagne a au contraire considérablement augmenté : l'amélioration de l'efficacité a réduit les coûts d'utilisation, déclenchant une explosion de la demande. C'est le paradoxe de Jevons (Jevons Paradox), qui se reproduit avec précision sur le marché de la puissance de calcul en 2026.
DeepSeek-R1 a effectivement réduit considérablement le coût d'inférence par Token. Mais il a simultanément ouvert une vanne de demande : de nombreuses entreprises qui trouvaient auparavant "l'IA trop chère" ont commencé à intégrer l'IA dans leurs processus métier. Une fois intégrée, la consommation de Tokens augmente de manière non linéaire.
Un changement plus crucial est que l'application de l'IA est passée de la "conversation" à l'"action" : les Agents et les Reasoning Models font leur apparition. Une tâche qui brûlait auparavant 1000 Tokens en brûle 5000 une fois connectée à une chaîne de raisonnement, car le Reasoning Model "réfléchit" par lui-même, avec une consommation 10 à 50 fois supérieure au mode normal.
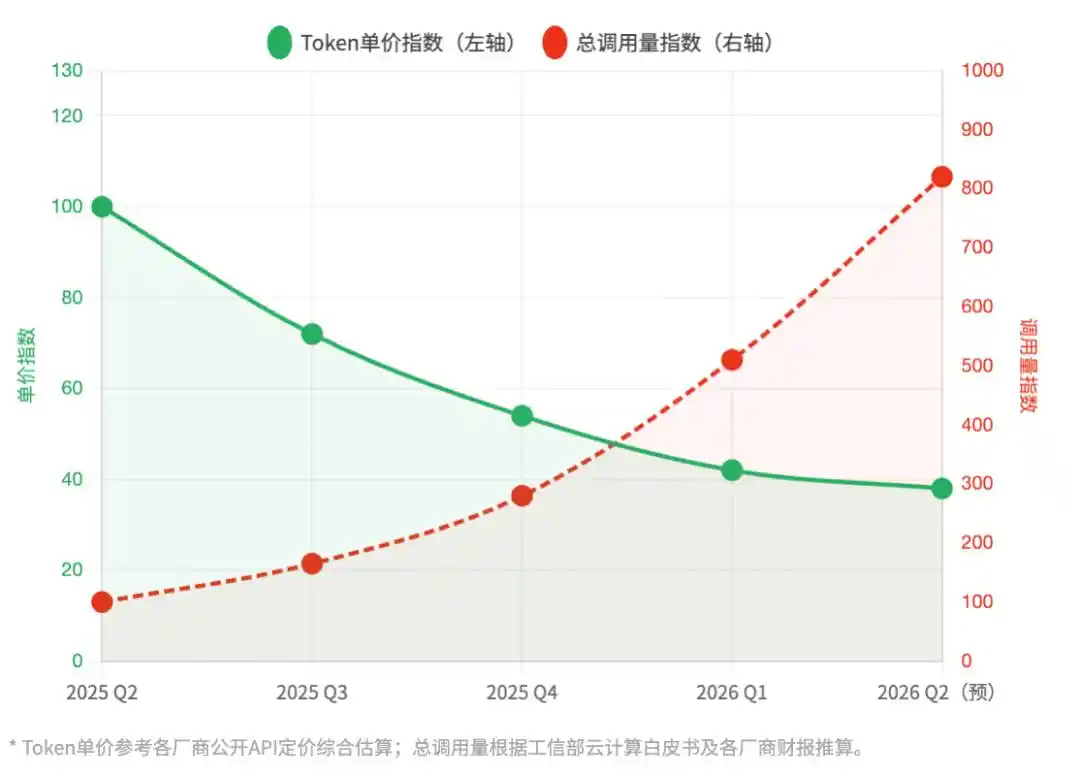
Figure | Avant et après la sortie de DeepSeek : Prix unitaire du Token vs. Tendance d'évolution du volume total d'appels
Note : Q2 2025 = Base 100 | Estimation globale des API d'inférence des principaux fournisseurs de cloud chinois
DeepSeek a abaissé le seuil de démarrage, mais a repoussé le plafond de la puissance de calcul. Chaque unité de Token devient de moins chère, mais chaque tâche métier devient de plus en plus coûteuse. C'est la véritable fondation sur laquelle repose cette hausse des prix.
02.
Les poids sont open source, pas la pile d'inférence
Un autre détail ignoré par de nombreux reportages : DeepSeek a open sourcé les poids de son modèle, mais pas sa pile d'optimisation d'inférence. La différence entre les deux est comme obtenir les plans de conception d'un moteur sans vous dire comment en tirer les performances d'une F1.
Ce qui détermine réellement le coût de l'inférence, ce n'est pas seulement l'architecture du modèle, mais les capacités d'ingénierie cachées sous la surface : le taux de réussite du décodage spéculatif (Speculative Decoding), la stratégie d'allocation mémoire du KV Cache, l'optimisation de la séparation des phases Prefill et Decode, la topologie réseau des clusters de dizaines de milliers de cartes. Ce travail technique complexe reste le fossé protecteur d'une poignée de grands fournisseurs de cloud.
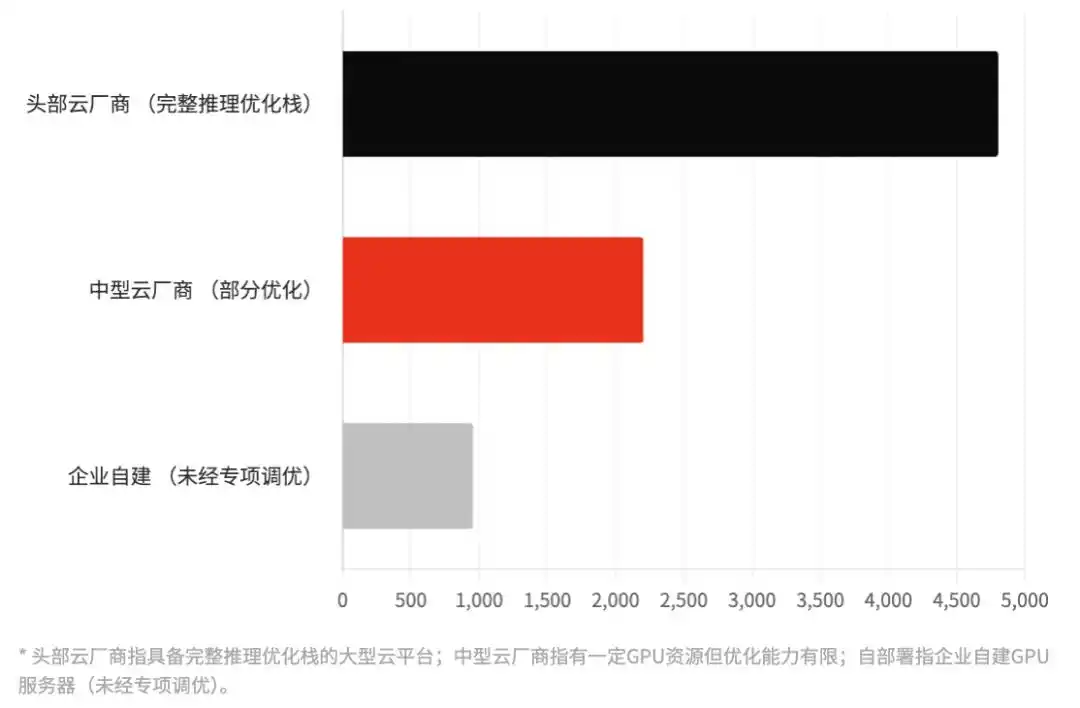
Figure | Écart d'efficacité d'inférence réel à échelle de modèle égale
Basé sur DeepSeek-R1-67B, comparaison du nombre de Tokens traités par seconde (TPS) dans différentes conditions de déploiement | Les valeurs sont des estimations sectorielles globales
Exécutant le même DeepSeek-R1, l'efficacité d'inférence des grands fournisseurs de cloud peut être 3 à 5 fois supérieure à celle des déploiements internes des entreprises. Cela signifie qu'avec le même investissement en puissance de calcul, les fournisseurs de cloud peuvent servir plus de requêtes simultanées, avec un coût unitaire inférieur.
Cet écart d'efficacité est l'une des sources de la "prime" des fournisseurs de cloud. C'est une barrière technique bien réelle. Cette hausse des prix, dans une certaine mesure, valorise également cet avantage technologique.
03.
La guerre des dieux : Les livres de comptes et les ambitions des quatre géants
Dans cette vague d'ajustements collectifs des prix, la posture des quatre géants centraux varie, reflétant des calculs commerciaux différents.
Alibaba Cloud : La bataille de "qualité des profits" à la manière de Wu Yongming. L'ajustement des prix d'Alibaba est le plus résolu, les hausses se concentrant principalement sur les instances GPU haut de gamme et le stockage (CPFS). Dans le contexte du retour complet d'Alibaba à "l'efficacité d'abord", Alibaba Cloud ne recherche plus le prétendu "premier rang en parts de marché cloud", mais vise à s'emparer du "premier rang en rentabilité de la puissance de calcul IA". Sous-entendu : Alibaba Cloud est en train de créer une "zone VIP de puissance de calcul". Si vous ne pouvez pas couvrir cette prime de 30 %, vous n'êtes probablement pas sur la liste des clients cibles principaux d'Alibaba.
Baidu AI Cloud : "Le filtre à utilisateurs". Baidu, en tant que joueur ayant parié le plus tôt sur les grands modèles, fait face à la pression des coûts d'inférence de son grand modèle Ernie qui augmentent avec le volume d'appels. La hausse des prix de Baidu ressemble donc plus à un "remaniement des utilisateurs". Il élimine activement les petits développeurs individuels qui ne font que profiter des offres gratuites sans créer de boucle commerciale fermée, pour se concentrer pleinement sur le service des grands clients B2B peu sensibles aux prix. Baidu doit prouver par cet ajustement que sa croissance IA ne repose plus sur les subventions, mais sur la "vente d'intelligence à prix majoré".
Tencent Cloud : "Correction du ROI" après le verrouillage de l'écosystème. L'action de Tencent Cloud arrive trois semaines après celle d'Alibaba, c'est une stratégie typique de "suivi". L'assurance de Tencent réside dans l'écosystème WeChat et l'intégration profonde avec Enterprise WeChat. Lorsque les flux de travail des entreprises sont déjà profondément intégrés dans l'écosystème social/collaboratif de Tencent, les coûts de migration sont extrêmement élevés. La hausse des prix de Tencent Cloud ressemble plus à un "rattrapage", visant à corriger le ROI sacrifié au cours des deux dernières années pour conquérir l'écosystème, et à rendre l'activité IA plus "présentable" dans les résultats financiers.
Volcano Engine : Suivi stratégique "déséquilibré" et plan de recrutement. Volcano Engine (ByteDance) est la variable inconnue dans cette vague de hausse des prix. Bien qu'il ait également ajusté certains prix, ses hausses sur de nombreuses API clés sont nettement inférieures à celles d'Alibaba et Baidu. ByteDance profite de cette fenêtre pour effectuer une "interception de la clientèle existante". Grâce à la capacité d'absorption massive de puissance de calcul apportée en interne par Douyin et TikTok, Volcano dispose d'un atout extrêmement fort pour lisser ses coûts. Pendant que ses concurrents "chassent les clients" pour préserver leurs profits, Volcano attend ceux qui sont laissés pour compte, tentant d'effectuer une dernière remontée en "volume d'installation" grâce à l'écart de prix.
04.
La plus grande surprise : Les grandes entreprises commencent à "partir"
Cette hausse des prix a provoqué une réaction inverse que personne n'avait prévue : elle a essentiellement renforcé la détermination des grandes entreprises à "construire leur propre puissance de calcul".
L'industrie du cloud computing a une règle cachée : lorsque la facture mensuelle dépasse un certain seuil, le modèle financier "construction interne vs. location" bascule. Pour les banques, les entreprises d'État centrales, les grands fabricants, ce seuil se situe autour de 3 à 5 millions de yuans de dépenses mensuelles en puissance de calcul cloud.
En 2024, la plupart des grandes entreprises étaient encore en dessous de ce seuil, la construction interne n'était pas rentable. En 2025, avec le déploiement des projets IA, certaines entreprises ont commencé à atteindre le seuil. Et cette hausse de prix de 20 % à 30 % en 2026 pousse directement un groupe de clients qui étaient juste à la limite dans la zone où ils "doivent sérieusement envisager la construction interne".
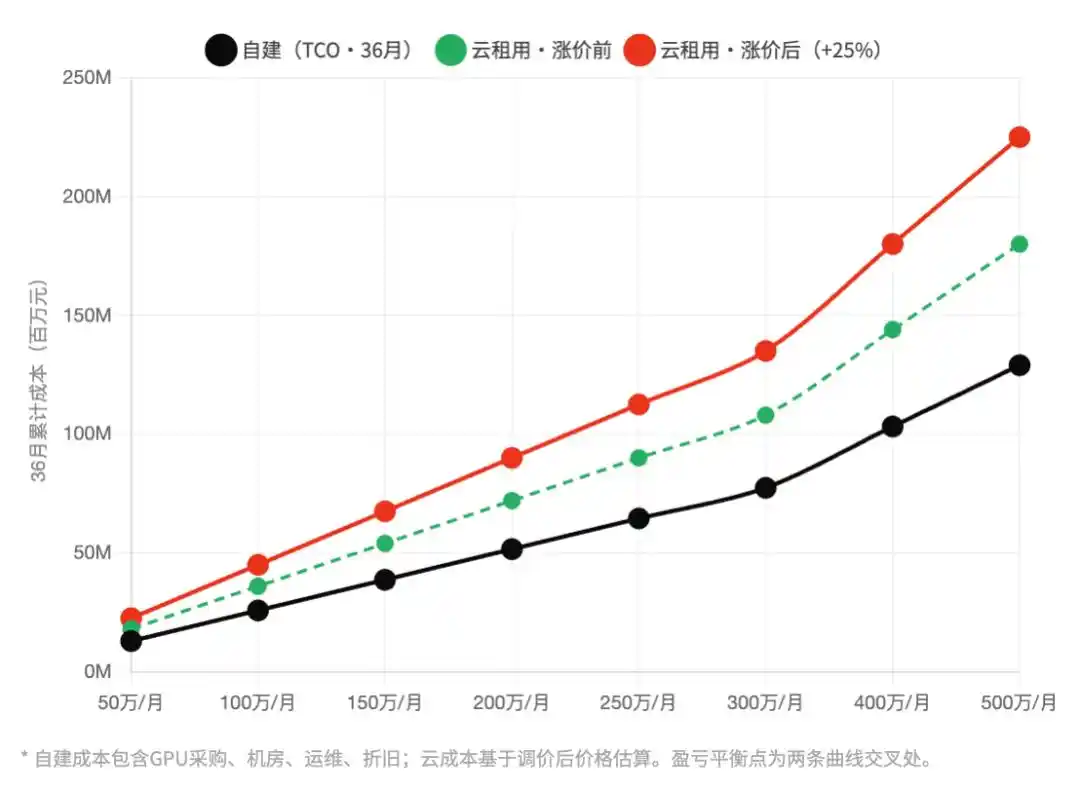
Figure | Location cloud vs. Construction interne : Calcul du point d'équilibre du coût total de possession (TCO)
Axe horizontal : Dépenses mensuelles moyennes en puissance de calcul (10k yuans/mois), Axe vertical : Coût cumulé sur 36 mois (millions de yuans) | Comparaison avant/après hausse
Les bénéficiaires de cette vague de construction interne ne sont pas les concurrents des fournisseurs de cloud, mais des acteurs plus marginaux : le nombre de demandes de devis sur les plateformes de location de GPU a doublé en mars par rapport à l'année précédente ; les délais de livraison des grands clients de Huawei Ascend se sont allongés à 6 mois ; les intégrateurs spécialisés dans les "clusters d'inférence privatifs" pour les entreprises sont soudainement devenus très demandés.
Les fournisseurs de cloud comptaient initialement augmenter les prix pour récolter les clients haut de gamme, mais ont involontairement poussé à partir un groupe de grands clients capables de construire en interne. Ce risque décisionnel pourrait être réévalué à l'arrivée de la saison des résultats financiers.

05.
Qui gagne ? La vérité sur la répartition des bénéfices
La hausse des prix des trois fournisseurs de cloud est perçue par les médias comme une "récolte par les grands acteurs". Mais si l'ensemble de la chaîne industrielle est considéré, la distribution des véritables gagnants est beaucoup plus complexe.
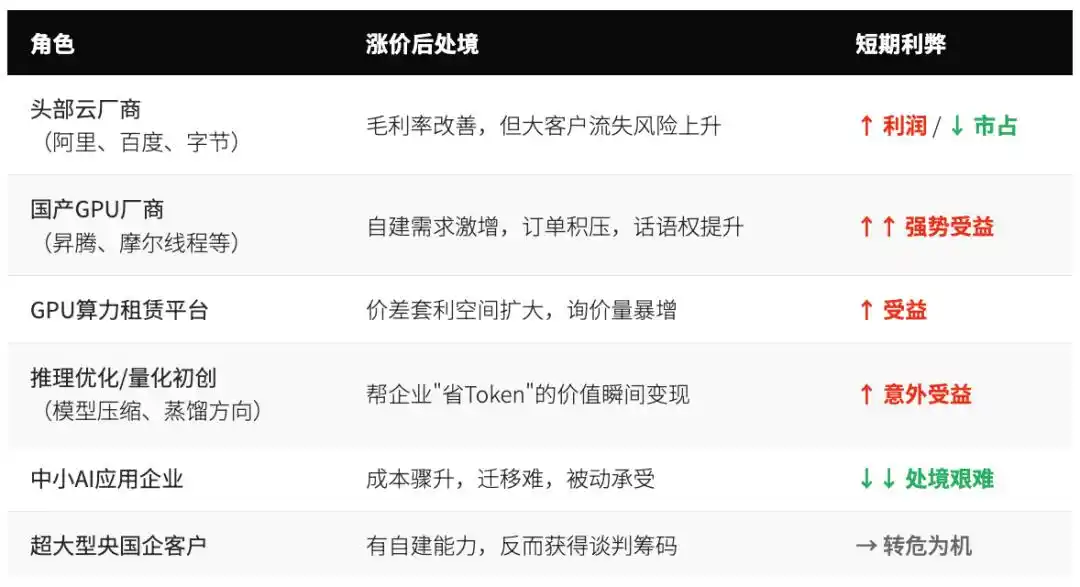
Il y a une réalité ironique : les plus touchées sont les PME d'IA les plus innovantes et dynamiques. Si elles s'effondrent en masse à cause des coûts, l'écosystème des fournisseurs de cloud lui-même se flétrira.
Ce n'est pas sans précédent. Au début des années 2010, les hausses de prix agressives d'Amazon AWS sur certains services ont accéléré la transition de certains développeurs vers Google Cloud, aidant indirectement GCP à constituer son écosystème initial. L'histoire ne se répète pas simplement, mais elle rime.
06.
Combien de temps durera l'ère de la hausse des prix ?
En clair, l'essence de cette hausse des prix est une libération de pression sur le marché chinois de la puissance de calcul IA, coincé entre une explosion de la demande et des contraintes d'approvisionnement. Pressé des deux côtés, le prix ne peut que monter. Ce n'est pas entièrement un choix actif des fournisseurs de cloud, c'est en quelque sorte une correction de tarification forcée.
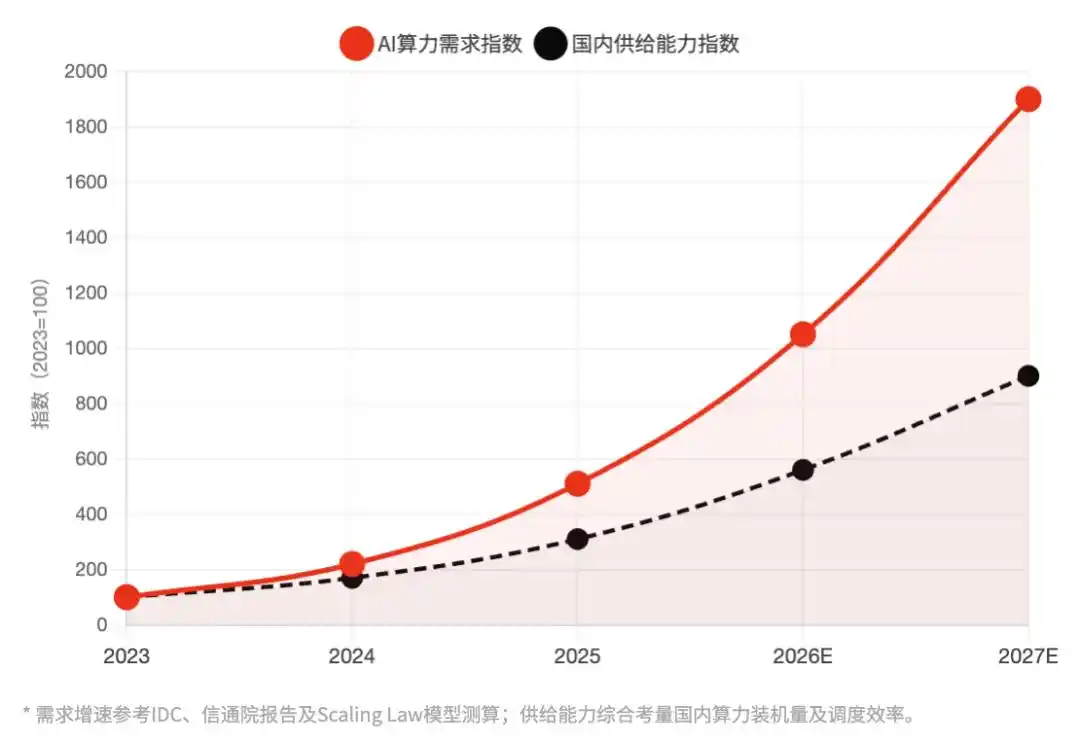
Figure | Puissance de calcul IA haute performance en Chine : Taux de croissance de la demande vs. Taux d'expansion des capacités d'approvisionnement nationales Indice : 2023 = 100 | L'élargissement continu de l'écart entre l'offre et la demande est la logique sous-jacente de cette hausse des prix
Aucun des trois facteurs structurels soutenant cette hausse des prix ne disparaîtra substantiellement dans les 12 prochains mois : le saut quantitatif de la consommation de Tokens dû à la popularisation des modèles de raisonnement, le déploiement à grande échelle des Agents IA, et les contraintes d'approvisionnement dues aux contrôles à l'exportation de Nvidia.
Le marché des logiciels B2B a une règle maintes fois vérifiée : l'effet de cliquet des prix (Ratchet Effect). Les quelques hausses de prix d'AWS au début des années 2010 n'ont jamais été entièrement annulées après l'amélioration de l'offre. La tarification du stockage Google Cloud n'a connu qu'une seule baisse depuis 2021, accompagnée d'un resserrement des plafonds de stockage. Les fournisseurs de cloud connaissent cette règle : cette hausse des prix n'est pas seulement une "récolte pendant la fenêtre", c'est aussi la fixation d'une nouvelle ligne de base tarifaire.
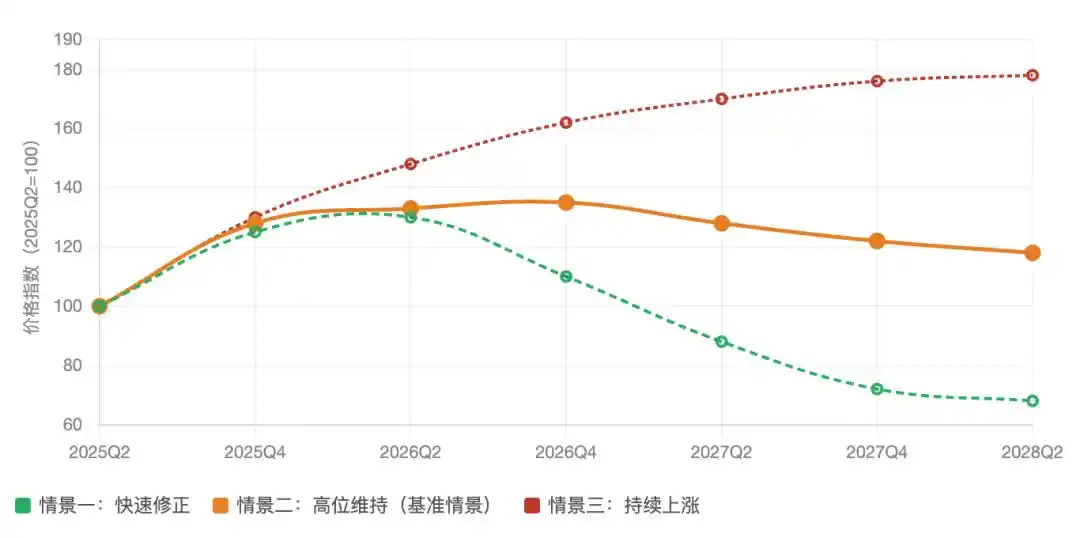
Tendance de l'indice des prix de la puissance de calcul : Trois scénarios prévisionnels (Q2 2025 – Q2 2028)
Q2 2025 = Base 100 | Estimation de l'indice de prix moyen des API d'inférence globale, incluant l'effet de hausse

Donc, avant 2027, la "puissance de calcul gratuite" ne deviendra pas réalité. Le point d'inflexion des prix dépendra réellement du moment où l'efficacité de planification de la puissance de calcul nationale pourra rattraper substantiellement celle du Nvidia H100. D'après les progrès techniques actuels, ce point se situera probablement entre 2027 et 2028.
Et pendant cette fenêtre, les fournisseurs de cloud ont toutes les raisons d'"augmenter les prix en premier", car ils savent que la fenêtre ne restera pas ouverte éternellement.
07
Conclusion : Un jeu structurel du côté de l'offre
Ce que cette hausse des prix révèle, ce n'est pas le grand récit des "rites de passage de la commercialisation de l'IA", mais une réalité industrielle plus concrète : Lorsqu'une révolution de l'efficacité et une explosion de la demande se produisent simultanément, les prix peuvent ne pas baisser, mais au contraire augmenter. Le paradoxe de Jevons était valable à l'ère du charbon, il l'est tout autant à l'ère de la puissance de calcul.
Pour les PME d'applications IA, plutôt que de débattre de qui récolte, il est plus judicieux de faire un calcul sérieux : dans leur scénario métier, combien de Tokens sont encore consommés inutilement ?
Économiser des Tokens est la plus solide des protections à notre époque.
Cet article provient du compte WeChat public "Qiangdiao Next" (ID : leo89203898), auteur : Wen Xin, éditeur : Xiaobai





