Écrit par : Pink Brains
Compilé par : AididiaoJP, Foresight News
L'IA décentralisée existe parce que l'IA centralisée présente des goulots d'étranglement structurels que le capital et le code ne peuvent résoudre :
- Les ressources de calcul sont rares et coûteuses
- La concentration excessive du contrôle
- Les sorties des modèles ne sont pas vérifiables
- L'accès aux données d'entraînement devient de plus en plus difficile
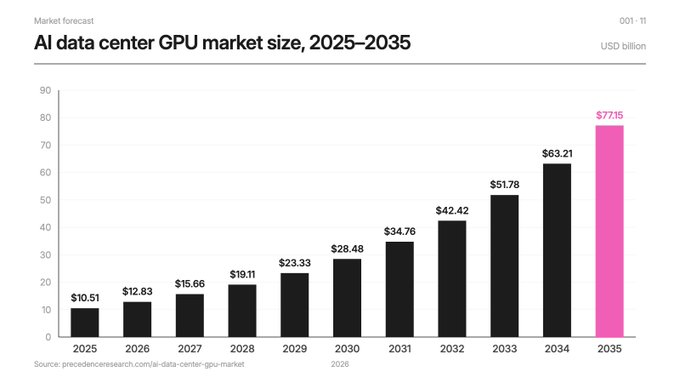
Les ressources de calcul sont rares et coûteuses
L'infrastructure GPU devrait passer de 100 milliards de dollars en 2025 à 770 milliards de dollars en 2035. Les GPU des centres de données sont épuisés depuis plusieurs mois. Le marché du calcul décentralisé devrait passer de 90 milliards de dollars en 2024 à 220 milliards de dollars en 2035 (données de Research and Markets). Ce chiffre n'est valable que si vous croyez que la pénurie est structurelle et non cyclique, et nous pensons qu'elle est structurelle.
La concentration excessive du contrôle
ChatGPT, Gemini, Grok, Claude sont tous détenus et exploités par un petit nombre d'entreprises privées. Les politiques actuelles en matière d'IA supposent que seules quelques entités capables de concentrer des ressources de calcul massives peuvent entraîner des systèmes puissants. Si cette hypothèse est brisée, la donne concernant qui peut construire une intelligence de pointe change complètement.
Les résultats ne sont pas vérifiables
Lorsqu'un modèle prend une décision, l'utilisateur ne peut pas vérifier si le bon modèle a été exécuté, si le calcul a été correctement effectué, si des données sensibles ont été divulguées. C'est encore tolérable pour un chatbot, mais lorsque l'IA traite des prêts, des soins de santé, ou qu'un agent autonome opère un portefeuille en temps réel, c'est totalement inacceptable.
L'accès aux données d'entraînement devient de plus en plus difficile, en raison des préoccupations de confidentialité et de la réglementation
Un crawler centralisé situé dans une seule région AWS sera rapidement limité en débit, bloqué géographiquement, ou nourri avec un cache empoisonné. Comme l'a déclaré a16z dans ses perspectives pour 2026, la confidentialité devient le « fossé le plus important de l'espace crypto ».
L'IA a besoin de la blockchain pour rendre l'intelligence ouverte, vérifiable et économiquement accessible.
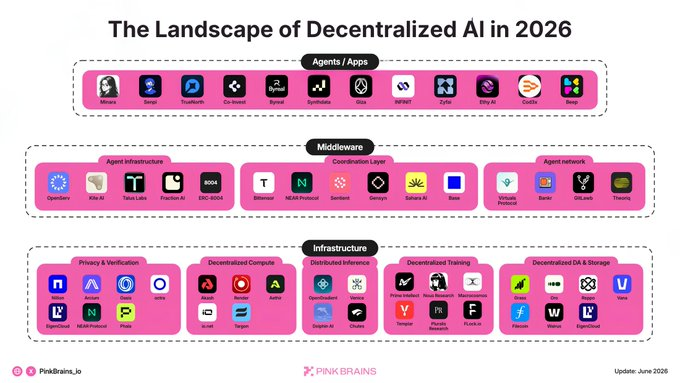
Carte de la pile technologique de l'IA décentralisée
- Couche Application & Services : Les agents IA peuvent faire beaucoup de choses, mais dans l'espace crypto, les deux cas d'usage dominants actuellement sont la finance agentique (Agentic Finance) et les paiements agentiques (Agentic Payments).
- Couche Middleware : Les tissus de connexion – des frameworks pour construire et identifier les agents, les marchés d'agents, à la couche de coordination.
- Couche Infrastructure : Les ressources sous-jacentes de l'IA – la couche confidentialité & vérification, le calcul, l'inférence, l'entraînement, les données et le stockage.
Couche Application & Services
La finance agentique transforme une instruction en langage naturel en action on-chain.
L'agent ARMA de @gizatechxyz a déjà traité plus de 4,6 milliards de dollars de volume de transactions agentiques sur des marchés de prêt sélectionnés – s'exécutant bloc par bloc sur le framework AVS d'EigenLayer, en non-custodial.
@Infinit_Labs exploite un cluster de plus de 20 agents spécialisés capables de transformer une intention comme « gagner 1000 $ par mois avec 1 BTC » en une stratégie en un clic sur Ethereum, Solana et Base.
@coinvestai by Liquid intègre l'exécution en temps réel directement dans ChatGPT et Claude, permettant le trading sur 500+ marchés via le Model Context Protocol.
@minara s'intègre à Hyperliquid et a récemment rejoint Lighter. Il exécute une boucle de trading complète « Analyse → Décision → Exécution » via le modèle DMind et 50+ intégrations.
@Cod3xOrg : Un réseau d'agents IA légers capables de transformer des intentions en transactions on-chain construites et exécutées.
@Zyfai_ : Un agent DeFAI auto-hébergé qui automatise et optimise le yield farming, rééquilibrant continuellement le capital entre protocoles pour chasser l'APY ajusté au risque, sans intervention humaine.
Dans le domaine des marchés de prédiction, @SynthdataCo est un sous-réseau Bittensor exécutant un réseau financier de prédiction intelligent décentralisé. Les mineurs rivalisent pour modéliser l'incertitude des prix à court terme. Il fournit déjà des données en temps réel pour des produits comme Mode AI Quant sur les marchés crypto de Kalshi.
Paiements agentiques : machine-paye-machine
De même qu'Internet est devenu la couche de communication de l'économie numérique, la blockchain et les stablecoins deviennent la couche de règlement des paiements agentiques.
Au 31 mai 2026, x402 a traité plus de 173 millions de transactions sur Base et Solana. Les membres de la fondation x402 incluent Google, Visa, AWS, Circle, Anthropic, Stripe et Cloudflare. Stripe l'utilise depuis février 2026 ; AWS a lancé le paiement natif AgentCore.
L'activité des acheteurs et des vendeurs augmente, la plupart des transactions étant liées à une utilisation réelle en paiement à l'usage : appels d'API, services d'inférence IA, commerce agentique et charges de travail similaires. Le cycle de spéculation initial s'est calmé, mais l'adhésion sous-jacente commence à suivre.
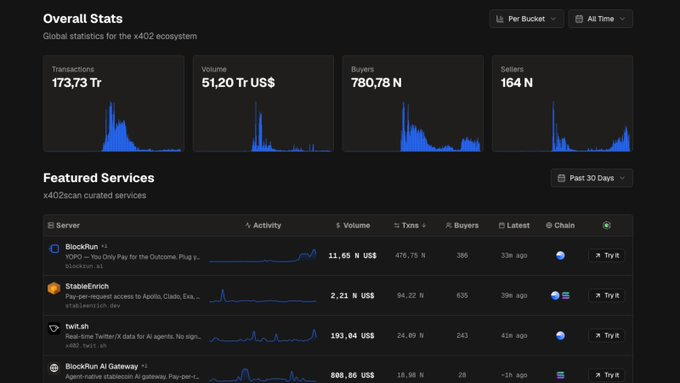
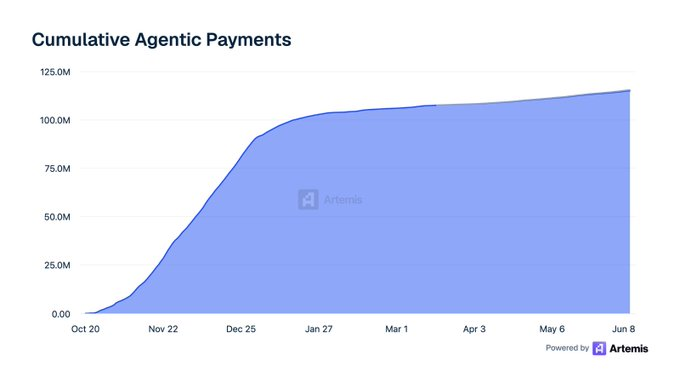
Parallèlement, le Machine Payments Protocol de Stripe et Tempo émerge comme une deuxième voie, ayant enregistré plus de 411 900 transactions et 9 600 acheteurs depuis son lancement.
Ensemble, ces réseaux indiquent que le commerce machine-à-machine évolue vers un changement plus large, où les agents logiciels peuvent négocier de manière autonome à la vitesse de la machine.
Couche Middleware
À mesure que le nombre d'agents augmente, le problème central devient la coordination : comment les agents se découvrent-ils mutuellement, prouvent-ils leur identité et commercent-ils sans intervention humaine.
Le déficit de confiance ici est un goulot d'étranglement. La taille estimée du commerce agentique devrait atteindre 1,5 à 5 billions de dollars d'ici 2030, mais l'adoption est limitée par un point – la plupart des utilisateurs sont prêts à laisser l'IA faire des recherches, mais peu sont prêts à laisser l'IA effectuer des achats.
Les systèmes d'aujourd'hui reposent encore sur des clés API, et presque aucun système ne traite les agents comme des entités dotées d'une identité.
@GoKiteAI construit un L1 dédié, intégrant l'identité et les paiements comme primitifs natifs. ERC-8004 est un standard Ethereum fournissant aux agents une identité et une réputation portables on-chain, pouvant être suivies cross-chain.
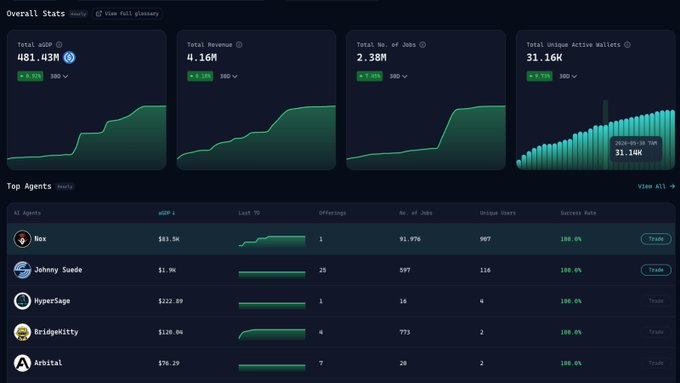
Sur le marché, @virtuals_io est le système d'exploitation de l'économie agentique sur Base. En juin 2026, il a traité plus de 2,38 millions de tâches d'agents, générant près de 480 millions de dollars de « PIB agentique ».
Mais le joyau de cette couche est Bittensor. C'est un réseau de sous-réseaux spécialisés, chaque sous-réseau étant une micro-économie où les mineurs exécutent des modèles IA, les validateurs notent les sorties, et les émissions TAO vont à ceux qui produisent le travail le plus utile. Trois mécanismes le rendent économiquement sérieux :
- Le halving de décembre 2025 a réduit l'émission quotidienne de TAO de 7200 à 3600, correspondant à un plafond dur de 21 millions.
- La mise à niveau dTAO donne à chaque sous-réseau son propre jeton Alpha et son pool AMM – le marché détermine les émissions.
- La mise à niveau Taoflow (lancée en novembre 2025) attribue les émissions purement en fonction du flux net de staking. Un sous-réseau qui se désengage plus qu'il ne stake peut tomber à zéro. C'est délibérément darwinien.
Le réseau compte plus de 128 sous-réseaux actifs, les 3 plus grands sous-réseaux de calcul ayant rapporté un ARR combiné de 200 millions de dollars dans les trois mois suivant leur monétisation. Le darwinisme est le produit.
D'autres projets se concentrent sur la création de blockchains IA dédiées, ou fournissent les outils, frameworks et incitations nécessaires pour soutenir des écosystèmes IA détenus par la communauté.
@NEARProtocol : Une couche de coordination invisible, combinant règlement, identité, confidentialité, TEE, MPC et protection des données personnelles, au service des agents autonomes.
@base – la « base maison » de l'économie agentique. Base MCP permet aux outils IA comme Claude, ChatGPT, Cursor d'exécuter des actions on-chain via des prompts sur des plateformes comme Uniswap, Morpho, Avantis – échanger, transférer, interagir en DeFi.
@SentientAGI : Son écosystème GRID connecte agents, modèles, données et calcul, acheminant les requêtes vers des acteurs spécialisés pour fournir le meilleur résultat.
@gensynai : Exécution ML vérifiable, coordonnant du matériel distribué pour l'entraînement et l'inférence tout en assurant la confiance dans le travail, coordonnée par le jeton $AI.
@SaharaAI connecte données, modèles, agents et récompenses dans un seul écosystème natif IA.
Couche Infrastructure
L'infrastructure est le squelette de l'IA – les primitives brutes de calcul, d'inférence, d'entraînement, de données et de confidentialité dont tout ce qui est au-dessus dépend. C'est la couche la plus capitalistique de la pile IA décentralisée.
Calcul décentralisé
@akashnet exécute un marché d'enchères inversées où les fournisseurs soumissionnent pour gagner vos charges de travail. Les nouveaux baux ont augmenté de 27 % au T1 2026, atteignant 43 500+, troisième trimestre consécutif de croissance. Son service d'inférence AkashML a traité près de 120 milliards de tokens en avril, à un prix 60–85 % moins cher que les principaux clouds.
@rendernetwork a rapporté une croissance d'utilisation de 428 % en glissement annuel.
@ionet agrège 130 000+ GPU de plus de 130 pays sur Solana.
@AethirCloud est l'un des rares à avoir des revenus réels : environ 166 millions de dollars d'ARR rapportés (T3 2025), ayant fourni plus de 1,5 milliard d'heures de calcul.
Inférence distribuée et vérifiable
L'inférence représente plus de 70 % des coûts opérationnels de l'IA, et Goldman Sachs estime que l'IA agentique poussera la consommation de tokens à augmenter de 24 fois d'ici 2030 – 120 billions de tokens par mois.
La réponse décentralisée est de rendre l'inférence peu coûteuse, privée et vérifiable.
@AskVenice sert déjà plus de 500 milliards de tokens par jour à plus de 2 millions d'utilisateurs via des modèles privés et non censurés, son fossé étant le modèle.
@OpenGradient a traité plus de 2 millions d'inférences vérifiables, générant 500 000+ preuves zkML.
@chutes_ai : Les développeurs peuvent déployer et mettre à l'échelle des modèles IA via une API simple, soutenus par des mineurs GPU, à un coût pouvant être jusqu'à 85 % moins cher qu'AWS. Les revenus de la plateforme sont convertis en demande de jeton via un mécanisme de staking automatique.
@dphnAI – un réseau d'inférence IA décentralisé. Il est à noter que Dolphin a développé les modèles non censurés utilisés par Venice AI, et utilise 100 % des revenus du réseau pour des rachats de jetons.
Entraînement décentralisé
L'entraînement est le problème le plus difficile, et celui qui a le plus d'impact – il détermine si les modèles de pointe doivent être construits en interne dans trois ou quatre laboratoires d'entreprise.
INTELLECT-1 (10 milliards de paramètres) de @PrimeIntellect est la première exécution d'entraînement distribué mondial ; INTELLECT-2 (32 milliards de paramètres) est la première exécution distribuée de RL.
@tplr_ai a entraîné avec succès Covenant-72B sur 70+ nœuds distribués, traitant environ 1,1 billion de tokens, réduisant les coûts de communication de 146 fois.
@NousResearch : Son réseau Psyche permet un entraînement distribué tolérant aux pannes, et Hermes 4.3 est devenu le premier modèle Hermes entraîné sur une infrastructure décentralisée plutôt que sur un cluster centralisé.
Le sous-réseau IOTA (SN9) de @MacrocosmosAI effectue un pré-entraînement LLM décentralisé et un « entraînement à domicile », son sous-réseau Data Universe (SN13) traitant la couche de données. La série d'algorithmes DiLoCo à faible communication permet à des GPU dispersés dans le monde de collaborer sans les réseaux internes ultra-rapides des centres de données.
Disponibilité et stockage de données décentralisés
À mesure que l'échelle des charges de travail IA augmente, les deux deviennent des goulots d'étranglement. Les modèles de pointe consomment des volumes massifs de données fraîches, et les besoins de stockage ont explosé au point où les principaux fournisseurs de disques durs rapportent que leur capacité est vendue plusieurs années à l'avance.
L'économie est attrayante. Le stockage décentralisé peut être 60-80 % moins cher que les fournisseurs de cloud traditionnels, des réseaux comme @Filecoin offrant des prix de stockage inférieurs à 1 $ par To et par mois, contre environ 30 $ pour les alternatives centralisées.
@grass paie 2,5 millions de nœuds dans 190 pays pour leur bande passante inutilisée, permettant aux laboratoires d'IA de crawler le web en temps réel.
@WalrusProtocol est un challenger en pleine croissance construit par @Mysten_Labs pour le stockage décentralisé et la disponibilité des données – utilisant des codes d'effacement bidimensionnels pour stocker efficacement de grands « blobs », et étant de plus en plus positionné comme une couche de mémoire persistante pour les agents IA.
@eigencloud : Une plateforme cloud vérifiable construite autour de la disponibilité des données, du calcul vérifiable et de la résolution des litiges. Garanti par de l'ETH re-staké, sa théorie est de permettre aux agents IA de s'exécuter avec des garanties cryptographiques, rendant les actions prouvables, auditable et exécutables.
@vana – un L1 EVM, où les Data DAOs et Data Liquidity Pools transforment les données personnelles en actifs tokenisables et négociables.
@reppo et @oroagents construisent des ensembles de données de haute qualité et dignes de confiance pour l'entraînement de l'IA via des concours incitatifs.
Couche Confidentialité & Vérification
L'utilisateur moyen de l'IA ne peut pas vérifier si le modèle a traité ses données de manière privée, si le calcul a été correctement exécuté, ou même si le modèle prétendu a été utilisé.
En 2026, la confidentialité et la vérification deviennent des prérequis pour l'IA, et non des fonctionnalités supplémentaires.
@nillion – l'« ordinateur aveugle », utilisant le MPC et son propre Nil Message Compute pour exécuter des calculs sur des données chiffrées sans les déchiffrer. Les cas d'usage incluent l'inférence IA privée, les bases de données cryptées et le RAG privé (permettant à l'IA d'interroger des bases de connaissances propriétaires sans les divulguer).
@Arcium : Un réseau de calcul confidentiel décentralisé sur Solana. Les cas d'usage incluent Umbra (transfers masqués / rendement privé) et l'entraînement IA confidentiel sur des ensembles de données sensibles.
@OasisProtocol : Un L1 axé sur la confidentialité, utilisant ROFL (Runtime Offchain Logic), un framework basé sur TEE pour exécuter des calculs hors chaîne vérifiables et protégés – agents IA, entraînement de modèles ou oracles.
@octra : Un L1 axé sur la confidentialité avec support natif du FHE, utilisant son propre schéma HFHE (Hypergraph FHE), conçu pour le calcul crypté parallèle et le débit.
@eigencloud : Un poids lourd de la vérification, construit sur la sécurité du re-staking d'EigenLayer. EigenAI (inférence LLM vérifiable est une API compatible OpenAI pour les modèles open source, où l'invite et la réponse sont prouvées non altérées) et EigenCompute (exécution hors chaîne vérifiable pour la logique des agents).
@PhalaNetwork. Les GPU cloud sont puissants mais non privés ; Phala rend les charges de travail prouvables, voire masquées pour Phala lui-même. Son produit phare, les GPU TEE sur Phala Cloud, déploie des modèles open source sur du matériel, offrant une API compatible OpenAI où chaque inférence a une preuve cryptographique.
Où va l'IA décentralisée en 2026-2027
La demande en IA croît plus vite que l'infrastructure ne suit, les agents IA deviennent le moteur de croissance dominant – la voie on-chain est prête.
Le calcul se transforme en classe d'actifs, et les marchés on-chain deviennent sa couche financière. Les acteurs institutionnels passent de l'expérimentation à l'investissement en infrastructure.
La tokenomique devient un avantage structurel de l'IA décentralisée dans la coordination du capital, du calcul et des données. L'opportunité s'étend de l'IA aux robots, aux machines autonomes et à l'IA physique.
Conclusion
L'IA décentralisée progresse dans les principales couches de la pile – infrastructure, middleware, applications – comme en témoignent les revenus de calcul, l'économie agentique croissante et l'entraînement distribué à grande échelle.
Mais le domaine en est encore à ses débuts. Les revenus ont souvent du retard sur les incitations en jetons, l'adoption reste inégale, et bien que les investissements globaux en IA explosent, l'IA décentralisée ne représente toujours qu'une petite partie du capital-risque. Les réseaux pilotés par des jetons peuvent être un avantage puissant, mais seulement si la capture de valeur est bien conçue.
Néanmoins, l'émergence de projets comme Bittensor, NEAR, Virtuals, Base et Venice indique que l'IA décentralisée évolue d'un récit spéculatif vers un nouveau modèle pour coordonner le calcul, les données, le capital et l'intelligence.






