
Imaginez une scène : vous demandez à trois assistants IA de collaborer pour résoudre un problème de mathématiques.
L'approche traditionnelle est la suivante : la première IA « écrit » sa démarche de résolution, la seconde la « lit » puis écrit une nouvelle démarche, la troisième la « relit » et « réécrit » à son tour.
Ce processus est semblable à trois personnes se transmettant des informations à tour de rôle avec des talkies-walkies, nécessitant à chaque fois de « traduire » la pensée intérieure en mots, que l'interlocuteur doit ensuite « retraduire » en pensée. Lent ? Oui. Inefficace ? Également. Pire encore, cette « traduction » entraîne une perte d'information – ce que vous pensez et ce que vous dites sont souvent deux choses différentes.
C'est le défi fondamental auquel sont confrontés les systèmes d'IA multi-agents actuels : la « taxe linguistique ».
Récemment, UIUC, Stanford, NVIDIA et le MIT ont proposé une nouvelle approche – RecursiveMAS. Elle permet aux IA de sauter l'étape de la « parole » pour communiquer directement par la « pensée ». En pratique, la vitesse de raisonnement a été améliorée de 2,4 fois, et la consommation de tokens réduite de 75 %.
(Référence de l'étude : https://arxiv.org/abs/2604.25917)
Le dilemme de la réunion d'IA : l'efficacité gaspillée à « parler »
Ces deux dernières années, les systèmes multi-agents sont devenus l'un des domaines de recherche les plus en vogue en IA. De Swarm d'OpenAI à AutoGen de Microsoft, de LangGraph à CrewAI, chacun explore comment faire collaborer plusieurs IA pour résoudre des tâches complexes qu'un modèle unique ne peut accomplir seul. Cependant, dans ces systèmes, l'efficacité de collaboration entre agents est toujours limitée par une hypothèse fondamentale – les agents doivent communiquer via du texte en langage naturel.
Lorsque vous faites collaborer un « expert en mathématiques » et un « réviseur de code », le flux semble « logique », mais en le décomposant, de nombreux problèmes apparaissent :
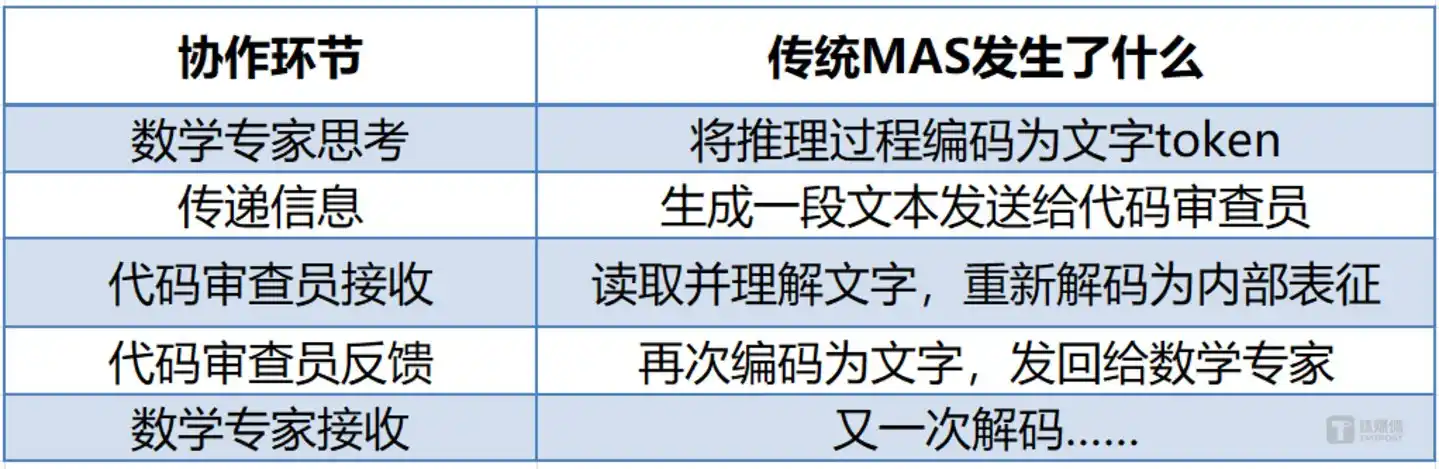
Chaque transmission d'information implique une double conversion : pensée interne → texte → pensée interne. Ce processus consomme non seulement des tokens (coût financier), mais aussi de précieuses ressources de calcul et du temps. Plus crucial encore, ce processus de « transcription puis lecture » perd de l'information – la richesse sémantique que le modèle compresse dans le texte lors du décodage ne peut être entièrement restituée lors du décodage par le modèle suivant. Dans un flux de travail impliquant cinq agents, la surcharge temporelle du codage/décodage textuel représente souvent plus de 60 % de la latence totale.
Plus problématique encore, ce paradigme manque d'un « bouton » clair pour une optimisation systématique – ajouter plus d'agents ? Les rendements marginaux diminuent, et la surcharge de communication augmente exponentiellement. Augmenter la fenêtre de contexte ? Les coûts en tokens explosent. Ajouter des paramètres au modèle ? Un agent individuel devient plus puissant, mais l'efficacité collaborative ne s'améliore pas fondamentalement – c'est comme équiper un groupe de meilleurs talkies-walkies, mais ils doivent toujours lire à tour de rôle des mots ; la méthode de communication n'ayant pas changé, même si chacun est plus intelligent, l'efficacité globale ne peut faire un bond en avant. Les solutions du secteur, qu'il s'agisse de l'ingénierie de prompts ou du fine-tuning LoRA, ne peuvent qu'atténuer les symptômes dans une certaine mesure, sans guérir ce problème structurel fondamental.
RecursiveMAS : remplacer les « talkies-walkies » par la « télépathie »
L'idée centrale de RecursiveMAS est ingénieuse : si le langage est le goulot d'étranglement, ne l'utilisons pas.
Elle s'inspire de la pensée des modèles de langage récursifs. Dans les modèles de langage traditionnels, les données circulent de la première à la dernière couche, de manière linéaire ; plus il y a de couches, plus il y a de paramètres. Le modèle de langage récursif fait l'inverse – il n'ajoute pas de couches, mais réutilise le même ensemble de coucles de couches, faisant « tourner » les données entre les couches. Chaque passage des données à travers cet ensemble équivaut à un tour de « réflexion » supplémentaire, approfondissant le raisonnement sans nécessiter l'ajout de paramètres.
RecursiveMAS étend cette idée de « l'intérieur d'un modèle unique » à un « système multi-agents » :
Chaque agent est comme une couche dans un modèle de langage récursif ; ils ne génèrent plus de texte, mais transmettent de la « pensée » – une représentation vectorielle continue qui existe dans l'espace latent.
Les chercheurs utilisent une métaphore poétique : « agents communicating telepathically as a unified whole » – les agents collaborent comme un tout unifié par télépathie.
Concrètement, l'Agent A1 traite et transmet sa représentation latente à l'Agent A2, qui la traite et la transmet à A3... jusqu'à ce que le dernier agent ait fini, sa sortie latente étant alors directement renvoyée à A1, initiant une nouvelle itération récursive. L'ensemble du processus se déroule entièrement dans l'espace latent ; ce n'est qu'à la dernière itération, par le dernier agent, que la représentation latente finale est décodée en sortie textuelle. C'est comme un groupe d'experts assis autour d'une table, sans parler, sans prendre de notes, chacun réfléchissant en silence puis transmettant directement le « fruit de sa pensée » au suivant – un processus à la fois silencieux et efficace.
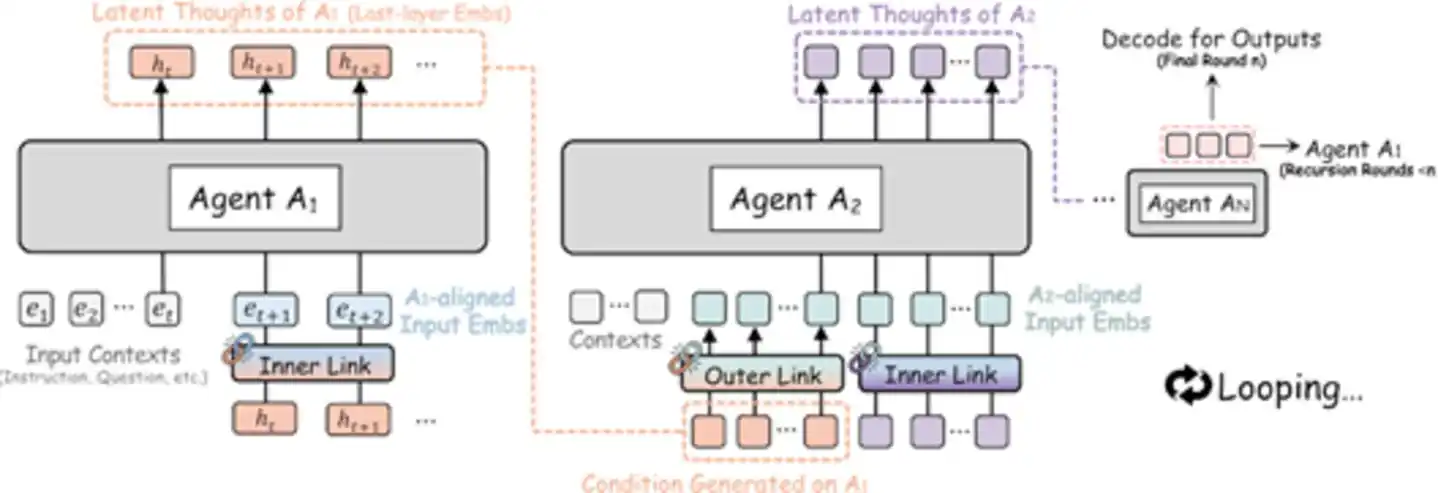
Figure : Schéma de l'architecture RecursiveMAS – Multi-agents réalisant une collaboration récursive en boucle fermée via l'espace d'embedding (source : arXiv)
Le composant clé de ce système s'appelle RecursiveLink, un module résiduel léger à deux couches, responsable de conserver et de transformer la représentation de la couche latente d'un modèle, puis de la transmettre à l'espace d'embedding du modèle suivant. L'état latent de la dernière couche d'un modèle de langage encode déjà une riche information sémantique de raisonnement ; le rôle de RecursiveLink est de « transporter » cette information de haute dimension de manière intacte, plutôt que de la traduire d'abord en texte pour l'interpréter ensuite. Il existe en deux versions : interne et externe.

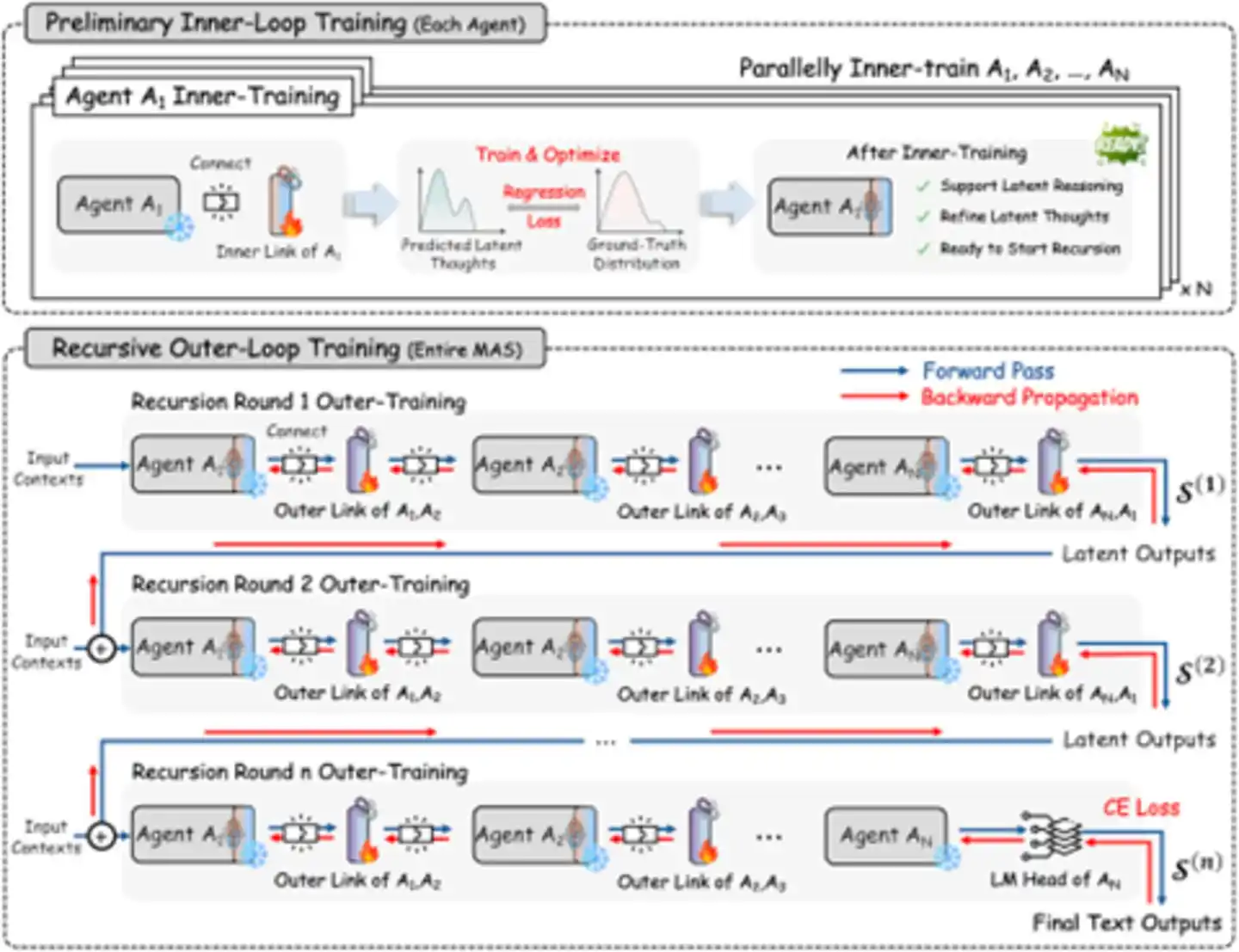
Figure : Processus d'apprentissage récursif – Liens internes et externes co-entraînés (source : arXiv)
La stratégie d'entraînement de RecursiveMAS est astucieusement conçue : les poids du modèle principal sont complètement gelés, seuls les modules RecursiveLink sont entraînés. Cela rejoint l'esprit du LoRA (Low-Rank Adaptation), mais RecursiveLink est plus léger : l'ensemble du système ne nécessite la mise à jour que d'environ 13 millions de paramètres, soit seulement 0,31 % du total des paramètres pouvant être entraînés. Les besoins en mémoire GPU de crête sont les plus bas parmi toutes les méthodes comparées, et le coût d'entraînement est réduit de plus de 50 % par rapport au fine-tuning complet. Vous pouvez le considérer comme un « adaptateur léger » que l'on branche directement sur l'écosystème d'agents existant, sans avoir à entraîner de nouveaux modèles de zéro. Si plusieurs agents sont basés sur le même modèle de base (par exemple, tous utilisent Qwen), ils peuvent même partager le même ensemble de poids du modèle, économisant encore plus de mémoire.
L'entraînement se déroule en deux phases :
Échauffement en boucle interne : Chaque agent entraîne indépendamment son RecursiveLink interne, lui apprenant à « penser au problème » dans l'espace latent plutôt qu'à « l'écrire ». Cette phase peut être effectuée en parallèle, comme si chacun s'exerçait d'abord au « monologue intérieur ».
Entraînement en boucle externe : Tous les agents sont connectés en une chaîne récursive complète, optimisant conjointement tous les RecursiveLink via le partage des gradients, avec comme objectif la qualité de la sortie textuelle finale. Cette phase résout le problème de l'« attribution du crédit » – comment attribuer avec précision le succès ou l'échec du résultat final à la contribution de chaque agent. Cette stratégie en deux étapes évite les problèmes d'instabilité d'entraînement qu'un « one-shot » pourrait causer.
Les chercheurs ont prouvé théoriquement que les gradients de l'entraînement récursif peuvent rester stables, sans problèmes d'explosion ou de disparition de gradients typiques des RNN, tout en ayant une complexité temporelle d'exécution supérieure aux MAS textuels traditionnels.
Résultats réels : un triplé précision, vitesse, coût
La théorie est une chose, mais les données parlent. L'équipe de recherche a effectué une évaluation complète sur 9 benchmarks principaux couvrant les mathématiques, les sciences et la médecine, la génération de code, les questions-réponses par recherche, et 4 modes de collaboration (raisonnement séquentiel, mixture d'experts, distillation de connaissances, appel d'outils de type négociation). La liste des modèles open-source utilisés est plutôt « luxueuse » – Qwen, Llama-3, Gemma3, Mistral, ces modèles se voyant attribuer différents rôles pour former divers modes de collaboration.
La liste des lignes de base de comparaison est tout aussi solide : fine-tuning LoRA, fine-tuning complet (SFT), Mixture-of-Agents, TextGrad, LoopLM, ainsi que Recursive-TextMAS utilisant la même structure de boucle récursive mais avec communication textuelle forcée. Cette dernière comparaison est particulièrement cruciale – elle prouve que l'avantage de RecursiveMAS provient bien du « saut du décodage textuel », et non de la structure récursive en elle-même. Toutes les comparaisons ont été effectuées avec un budget d'entraînement identique, de manière équitable.
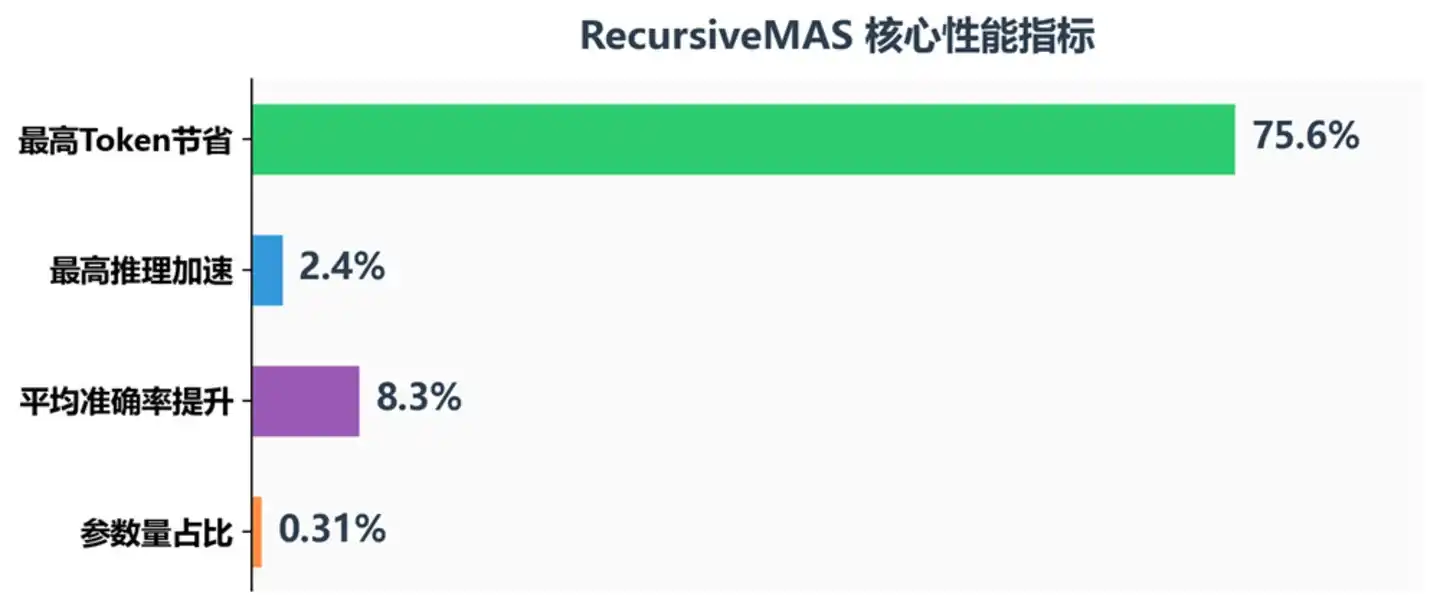
Indicateurs de performance clés de RecursiveMAS
Les résultats montrent que RecursiveMAS apporte une amélioration constante sur tous les indicateurs :
Précision : La précision moyenne a augmenté de 8,3 %, surpassant TextGrad de 18,1 % sur le concours mathématique AIME2025 et de 13 % sur AIME2026. Sauter le décodage textuel n'a pas entraîné de perte d'information, mais a plutôt permis au modèle de conserver une sémantique latente plus riche – après tout, la perte d'information lors de la compression de la pensée en texte puis de sa décompression est bien plus importante qu'on ne l'imagine.
Vitesse : La vitesse de raisonnement de bout en bout s'est améliorée de 1,2 à 2,4 fois, et cette amélioration continue de croître avec l'augmentation du nombre d'itérations récursives. Cela est d'une grande importance pour les scénarios d'application réels : dans les systèmes d'assistance client IA ou d'aide au codage nécessitant des réponses en temps réel, une amélioration de vitesse de plus de 2 fois signifie un bond qualitatif dans l'expérience utilisateur.
Coût : Comparé à Recursive-TextMAS, la consommation de tokens a été réduite de 34,6 % à 75,6 %. Cela ne représente pas seulement une économie de coûts, mais signifie aussi qu'avec le même budget de tokens, on peut tenter un raisonnement plus profond.
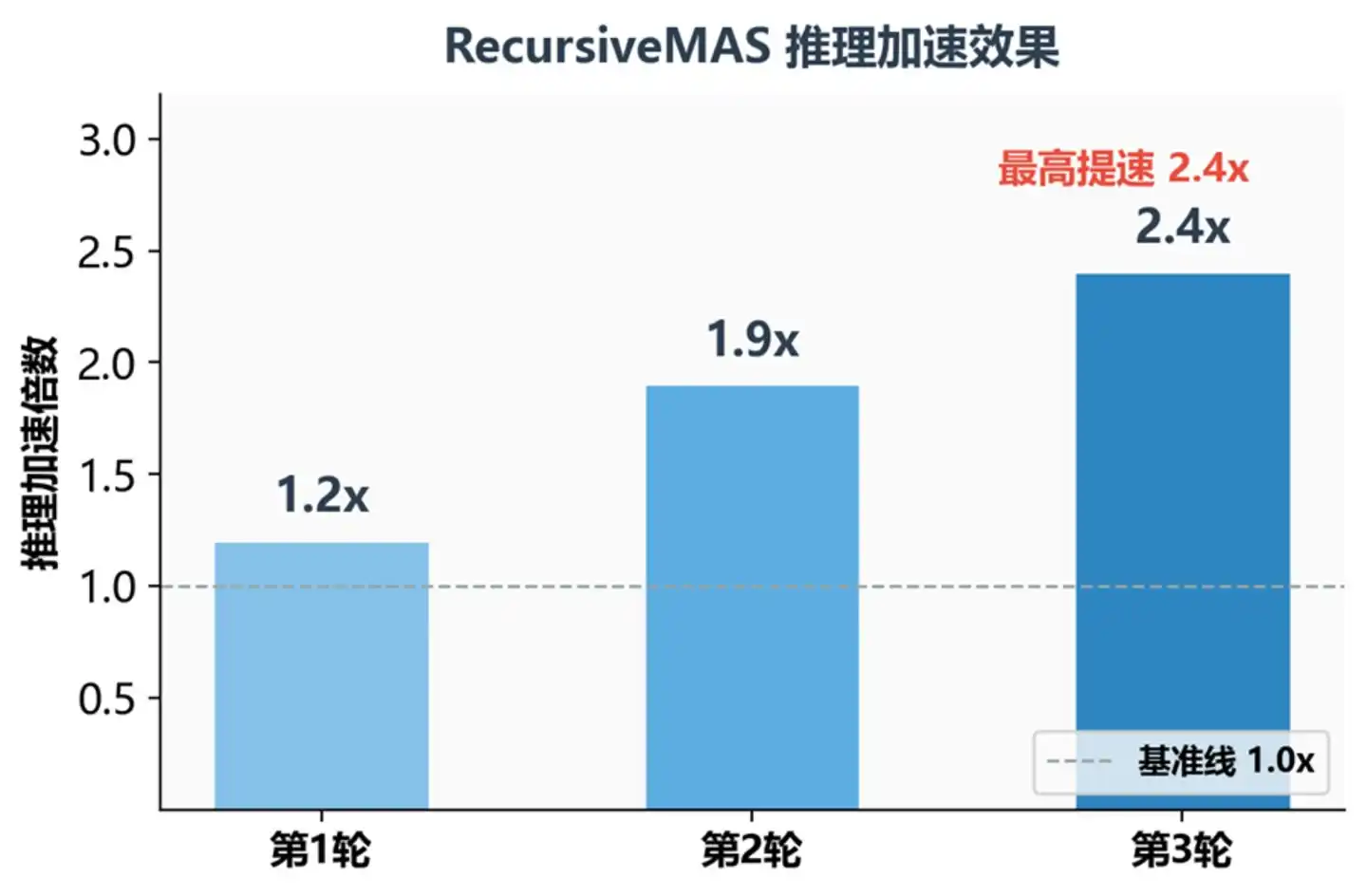
Facteur d'accélération du raisonnement pour différents nombres d'itérations récursives
Un point clé ici : plus la profondeur récursive est grande, plus le bénéfice est élevé. L'effet d'accélération augmente avec le nombre d'itérations : en moyenne 1,2 fois pour la 1ère itération, 1,9 fois pour la 2ème, 2,4 fois pour la 3ème. La raison est simple – on économise le temps que chaque agent passerait à « écrire sa pensée en mots » ; plus il y a d'agents et d'itérations, plus le temps économisé est important.
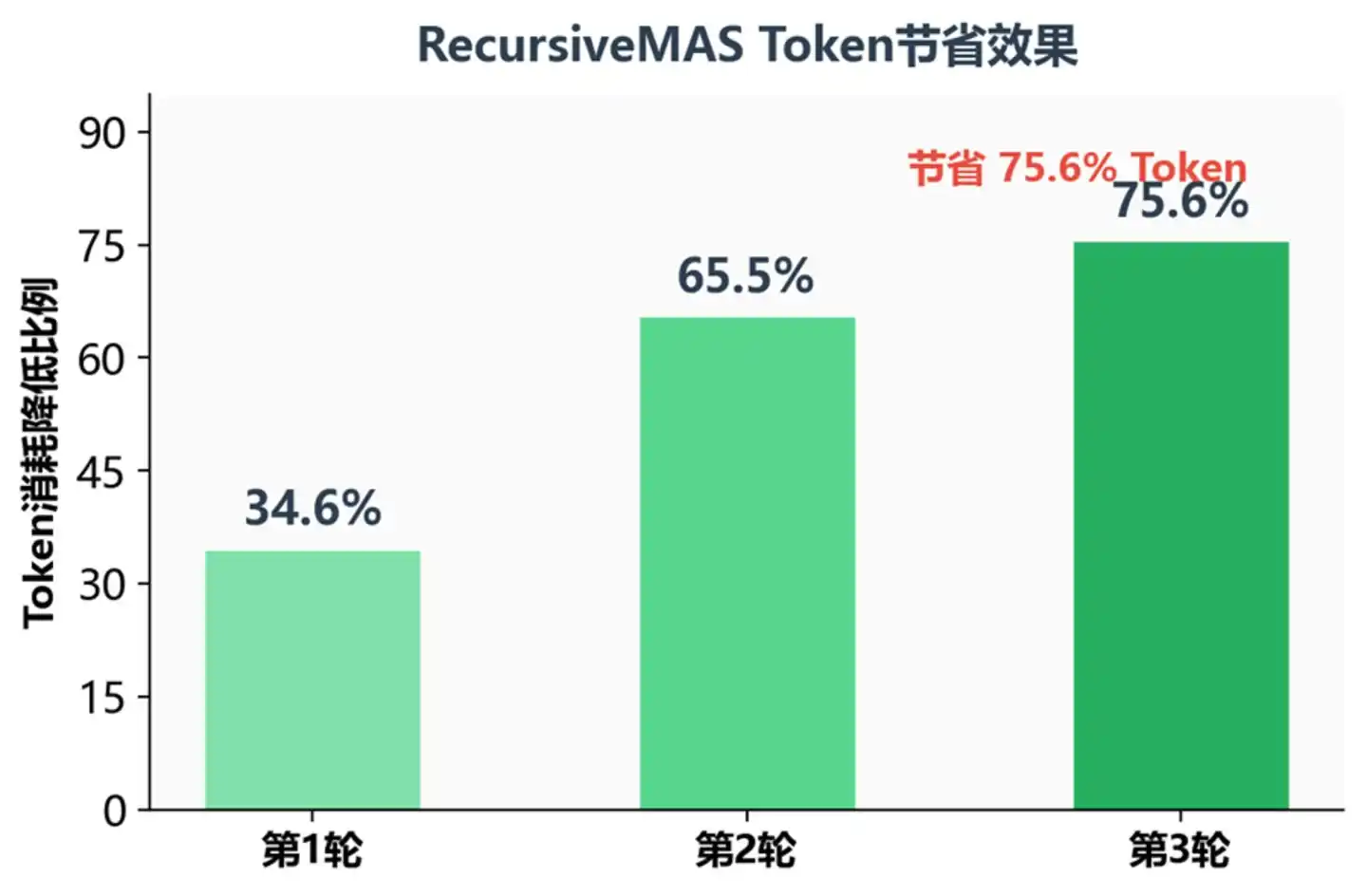
Taux d'économie de tokens pour différents nombres d'itérations récursives
À la troisième itération récursive, la consommation de tokens est réduite de 75,6 % – ce qui signifie qu'à performance égale, les coûts d'exécution peuvent être compressés à environ un quart. Pour les environnements de production nécessitant un raisonnement complexe en plusieurs étapes, c'est un attrait considérable.
Pourquoi cette recherche mérite-t-elle l'attention ?
Si ce n'était qu'une simple amélioration numérique, cet article ne mériterait peut-être pas autant d'attention. Ce qui la rend vraiment digne d'intérêt, c'est qu'elle pourrait redéfinir la direction du scaling pour les systèmes multi-agents.
Ces dernières années, les tentatives de scaling dans le domaine multi-agents se sont principalement articulées autour de trois axes : augmenter le nombre d'agents, élargir la fenêtre de contexte, empiler des modèles plus grands. Mais ces méthodes rencontrent chacune leurs goulots d'étranglement – communication explosive avec plus d'agents, explosion des coûts avec une fenêtre plus large, explosion de l'entraînement avec des modèles plus grands.
RecursiveMAS ouvre une nouvelle voie : augmenter la profondeur récursive. Elle transforme la « collaboration multi-agents » d'un paradigme parallèle et textuel en un paradigme profond et récursif dans l'espace latent. Tout comme les modèles de langage récursifs approfondissent le raisonnement en retraitant le même problème, RecursiveMAS permet à plusieurs agents de « réfléchir » mutuellement à plusieurs reprises à leurs « idées », sans avoir à chaque fois à « les exprimer puis les réentendre ».
La question centrale que les chercheurs posent dans leur article est : « La collaboration entre agents peut-elle elle-même être étendue via la récursion ? » La réponse semble être positive.
Lorsque le système n'a plus besoin de « traduire » les représentations internes en un format intermédiaire lisible par l'homme, la limite supérieure de l'efficacité de collaboration a le potentiel d'être repoussée.
Le contexte actuel du secteur offre également un terrain d'application concret pour cette recherche. La conférence des développeurs de Baidu en 2026 a pour thème « Agents à grande échelle (Agents at Scale) », Anthropic lance Claude Managed Agents, OpenAI poursuit la réalisation en temps réel du raisonnement de niveau GPT-5 – tout le secteur cherche des moyens de faire passer la collaboration d'agents de la démonstration à l'environnement de production. Et les trois montagnes à franchir – coût de calcul, latence de raisonnement, limitations en mémoire – sont précisément celles que RecursiveMAS tente de soulever avec une surcharge paramétrique de seulement 0,31 %.
Bien sûr, cette recherche en est encore à un stade précoce, et plusieurs points méritent attention :
Fiabilité des données à vérifier. Les résultats actuels sont rapportés par les auteurs eux-mêmes, et aucune équipe indépendante n'a encore réalisé de reproduction. L'attitude du monde universitaire envers les nouvelles technologies est souvent « hypothèse audacieuse, vérification prudente ». À cette époque d'« explosion des publications », la reproduction indépendante est le meilleur moyen de vérifier la valeur réelle d'une technologie.
Compatibilité des agents hétérogènes. Bien que l'Outer RecursiveLink soit conçu pour connecter des modèles d'architectures différentes, l'article ne détaille pas la transmission des représentations latentes entre architectures. Si elle ne peut être utilisée que pour des agents homogènes, sa portée pratique sera grandement réduite. Après tout, dans des scénarios réels, nous avons souvent besoin de mélanger des API propriétaires comme GPT-4o, Claude, etc.
Baisse de l'explicabilité. Lorsque les agents ne transmettent plus du texte lisible, mais un tas de représentations vectorielles, l'ensemble du processus collaboratif devient une « boîte noire ». Dans des environnements de production où la responsabilité des décisions d'IA est requise, cette opacité peut poser des défis de conformité et d'audit.
Complexité des environnements de production. L'article teste des scénarios de collaboration relativement propres, alors que les environnements de production réels impliquent souvent des appels à des outils externes, des interactions homme-machine, des flux de travail dynamiques et d'autres facteurs complexes.
La proposition de RecursiveMAS consiste essentiellement à introduire la stratégie de scaling « récursion », qui s'est avérée efficace à l'ère des modèles uniques, dans l'ère multi-agents, remettant en question l'hypothèse par défaut selon laquelle « les agents doivent communiquer via le langage naturel ». Si les données sont reproductibles, l'axe de scaling de la prochaine étape dans la course aux MAS pourrait passer de « l'accumulation du nombre d'agents » à « l'approfondissement de la profondeur récursive ».
Bien sûr, cette recherche nécessite encore d'être validée sur davantage de benchmarks indépendants, de résoudre le problème de l'interconnexion de modèles hétérogènes, et de faire ses preuves dans des environnements de production réels. Mais au moins, elle nous montre une possibilité –
La collaboration entre agents d'IA n'a pas toujours besoin d'être un « dialogue de sourds ».
((Cet article a été initialement publié sur l'application Ti Media, auteur | Silicon Valley Tech_news, éditeur | Jiao Yan))






