Sans aucun avertissement ! Après un an d'attente, Zuckerberg fait son retour !
À l'instant même, la première création du Meta Super Intelligence Lab (MSL) est en ligne —
Muse Spark, nom de code Avocado, c'est le fameux « Avocat ».
C'est un véritable « guerrier polyvalent aux six compétences maximales » : perception multimodale native, utilisation d'outils, chaîne de pensée visuelle, orchestration multi-agents, tout est maîtrisé.

Commençons par le chiffre le plus explosif.
Lors des tests d'Artificial Analysis, Muse Spark a obtenu un score impressionnant de 52 points, se classant juste après Gemini 3.1 Pro, GPT-5.4 et Opus 4.6.
En comparaison, le Llama 4 Maverick de l'année dernière n'a obtenu que 18 misérables points.
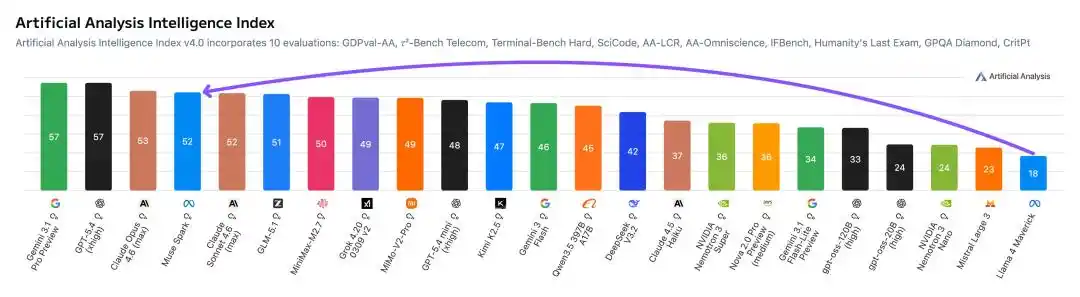
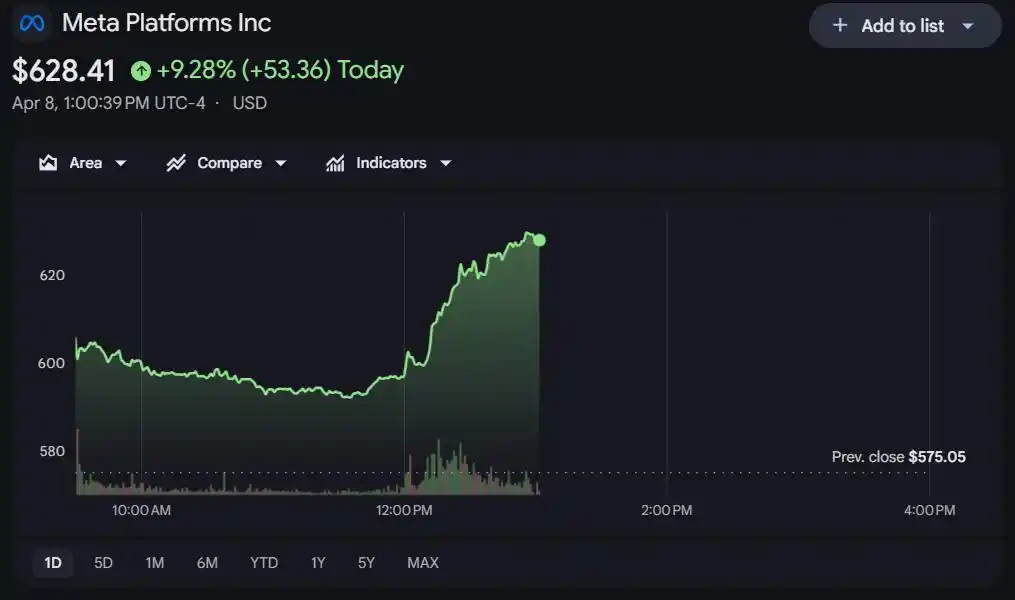
De 18 à 52, un bond en avant, Meta a grimpé en flèche de près de 10% en cours de séance.
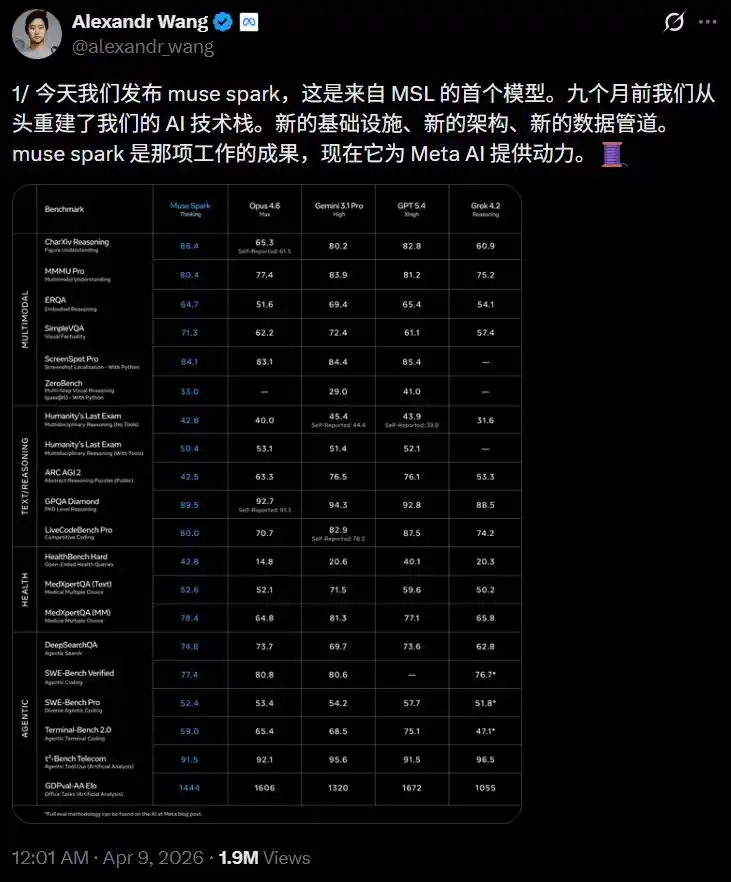
Alexandr Wang, directeur de l'IA chez Meta, était si excité qu'il a posté neuf tweets d'affilée sur X.
Il y a neuf mois, nous avons reconstruit toute la stack technologique de l'IA à partir de zéro, nouvelle infrastructure, nouvelle architecture, nouveau pipeline de données. Muse Spark est le fruit de ce travail.
Les chercheurs chinois de l'équipe MSL ont également inondé les réseaux sociaux, ces personnes ont quitté OpenAI, DeepMind l'année dernière pour rejoindre un laboratoire nouvellement formé, parient sur aujourd'hui.
Shengjia Zhao, scientifique en chef de MSL, l'a dit clairement : « Nous avons reconstruit toute la stack technologique pour supporter le Scaling, ce n'est que le début ».




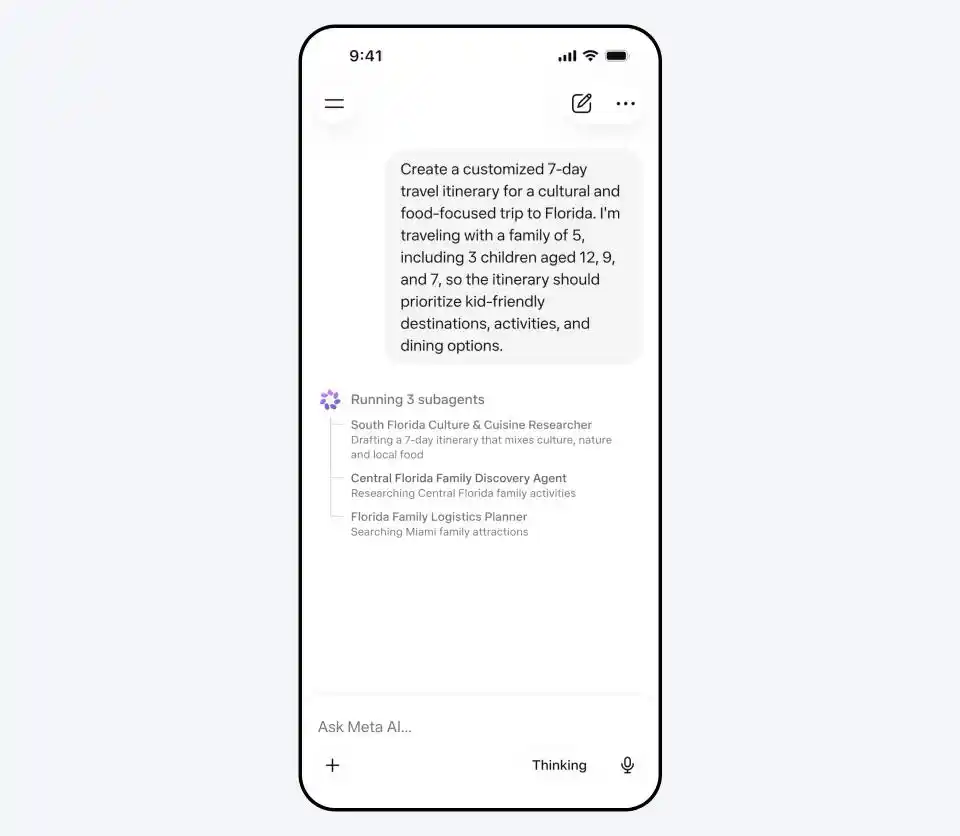
Il convient de mentionner que Muse Spark a également lancé un « Mode Contemplation » (Contemplating) équivalent à Gemini Deep Think et GPT Pro, où plusieurs Agents réfléchissent en parallèle et collaborent pour répondre.
Il suffit de saisir « Aide-moi à planifier un voyage de 7 jours en Floride axé sur la culture et la gastronomie pour une famille de 5 personnes, avec des enfants de 12, 9 et 7 ans », Muse Spark enverra simultanément trois sous-Agents, un pour planifier l'itinéraire culturel et gastronomique, un pour rechercher des activités familiales, et un pour coordonner la logistique et l'hébergement.
Actuellement, le modèle est déjà disponible sur meta.ai et l'application Meta AI. La version d'aperçu de l'API est ouverte à certains utilisateurs.
Les fonctionnalités se déploient d'abord aux États-Unis, et dans les prochaines semaines, elles seront intégrées à Facebook, Instagram et WhatsApp.
Gratuit, sans limite, mais fermé.
Ensuite, les points clés :
· Score Artificial Analysis 52, Llama 4 Maverick seulement 18
· Multimodal natif + Chaîne de pensée visuelle, deuxième sur le marché visuel après Gemini 3.1 Pro
· « Mode Contemplation » avec réflexion multi-Agents en parallèle, HLE atteint 58%
· Besoins en calcul pour le pré-entraînement réduits à 1/10 de ceux de Llama 4
· 1000+ cliniciens ont participé à l'entraînement,问答 de santé écrase la concurrence
· La pensée se compresse d'elle-même, consommation de Token seulement 1/3 de celle d'Opus
· Apollo Research a découvert qu'il pouvait percevoir qu'il était testé pour la sécurité
Les scores rattrapent le peloton de tête, mais le code est encore un peu faible
Regardons d'abord les données brutes.
Meta a comparé Muse Spark (Mode Pensée) avec Opus 4.6, Gemini 3.1 Pro, GPT 5.4, Grok 4.2, couvrant multimodal, pensée textuelle, santé, Agent, plus de 20 benchmarks au total.
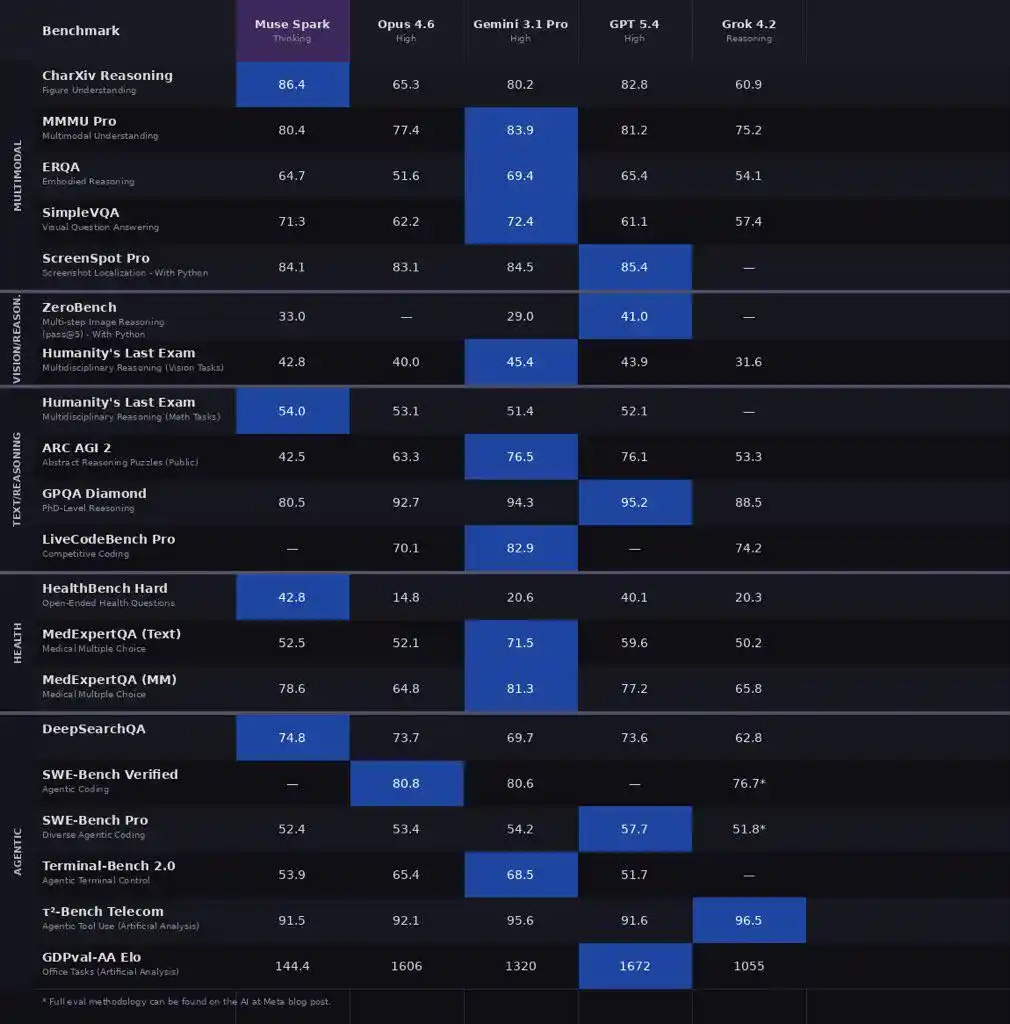
Scores re-annotés par un internaute Reddit
Le multimodal est la partie la plus brillante de Muse Spark.
CharXiv Compréhension 86.4, dépasse GPT 5.4 (82.8) et Gemini 3.1 Pro (80.2).
ScreenSpot Pro Localisation de capture d'écran 84.1, légèrement supérieur à Opus 4.6 (83.1).
ZeroBench Multimodal en plusieurs étapes 33.0, Gemini 3.1 Pro est à 29.0.
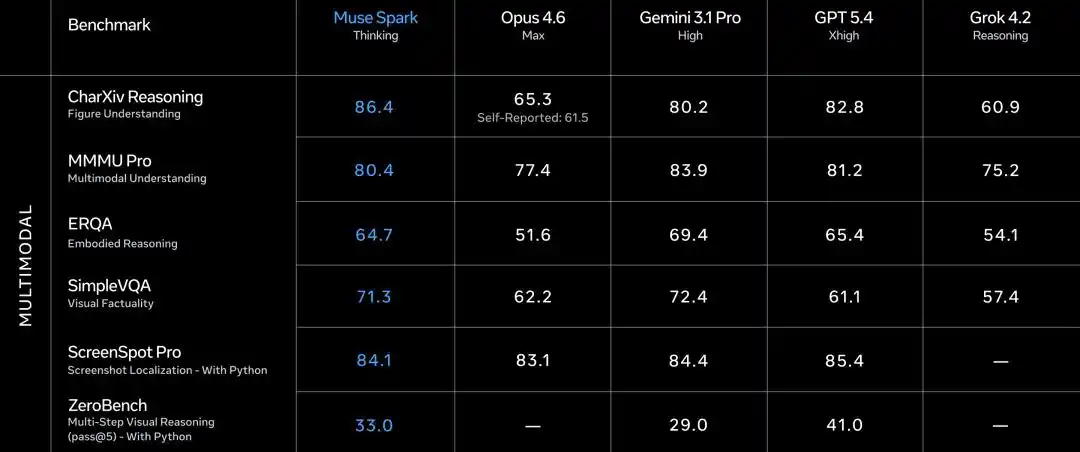
Sur la piste textuelle, c'est mitigé.
GPQA Diamond Problèmes de niveau doctoral 89.5, Opus 4.6 a obtenu 92.7, Gemini 3.1 Pro 94.3.
ARC AGI 2 Pensée abstraite 42.5, distancé par Opus 4.6 (63.3) et Gemini (76.5).
LiveCodeBench Pro Programmation compétitive 80.0, Gemini 82.9, GPT 5.4 a obtenu 87.5.
Meta reconnaît elle-même que Muse Spark a encore du retard sur les modèles les plus puissants en matière de code et de tâches d'Agent de longue durée.
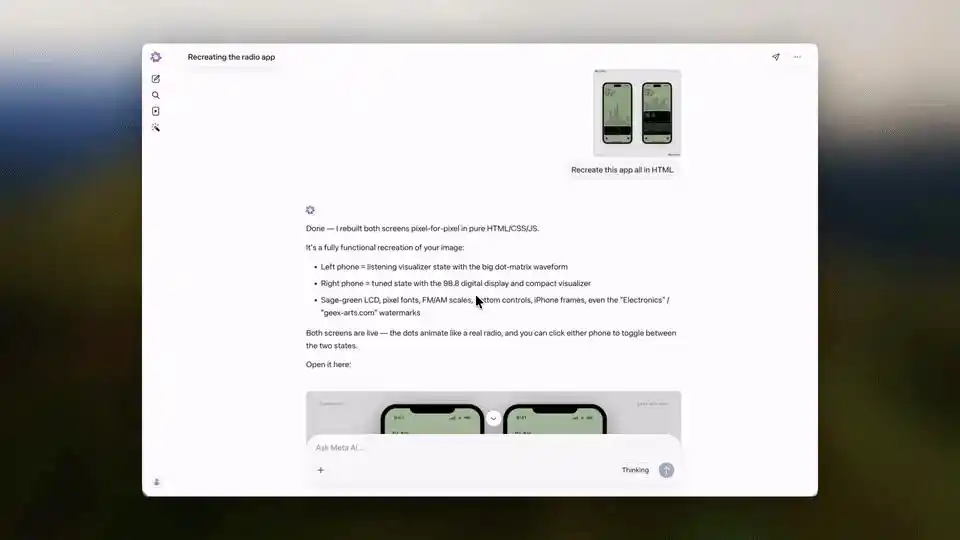
Cependant, ce qui a impressionné tout Internet, c'est que Muse Spark peut directement transformer une image en code, avec un effet très impressionnant !
Mais sur le créneau de la santé, Muse Spark se bat férocement.
HealthBench Hard Questions-réponses ouvertes sur la santé 42.8, Gemini 3.1 Pro seulement 20.6, GPT 5.4 est à 40.1.
MedXpertQA Médical multimodal 78.4, également proche de Gemini (81.3, légèrement supérieur ici), mais bien supérieur à Opus 4.6 (64.8).
La collaboration de Meta avec plus de 1000 cliniciens pendant la phase d'entraînement pour le nettoyage et la sélection des données a porté ses fruits.
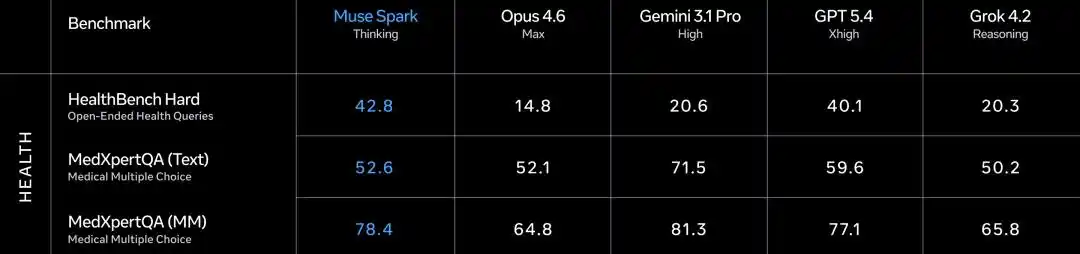
La piste Agent mérite également attention.
DeepSearchQA Agent de recherche a obtenu 74.8, le plus élevé des cinq.
τ2-Bench Utilisation d'outils 91.5, à égalité avec GPT 5.4.
GDPval-AA Elo Agent bureautique atteint 1444, dépasse Gemini (1320) mais inférieur à Opus 4.6 (1606).
Écart notable sur SWE-Bench, Verified 77.4 vs Opus 80.8 vs GPT 82.9 (prétendument 78.2), Pro 52.4 vs GPT 57.7.
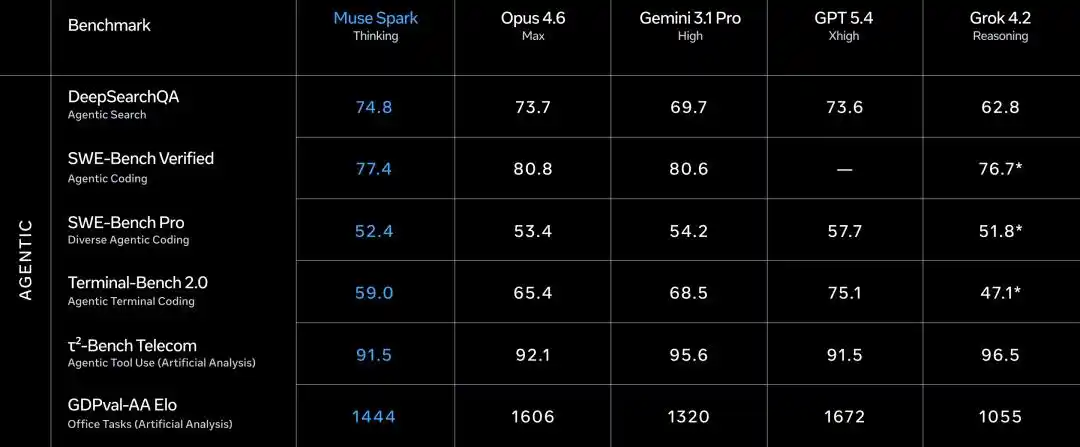
En résumé, multimodal et santé gagnent, pensée égale, code et Agent un peu à la traîne.
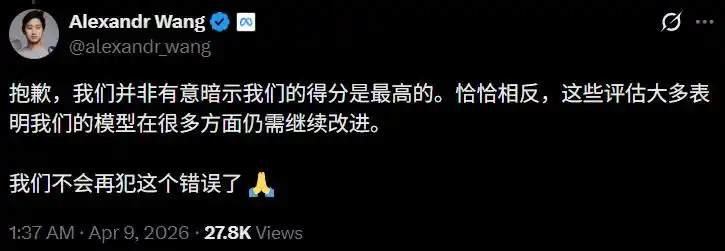
Alexandr Wang : Les erreurs de Llama 4 ne se reproduiront pas, l'Avocat n'a pas triché sur les scores
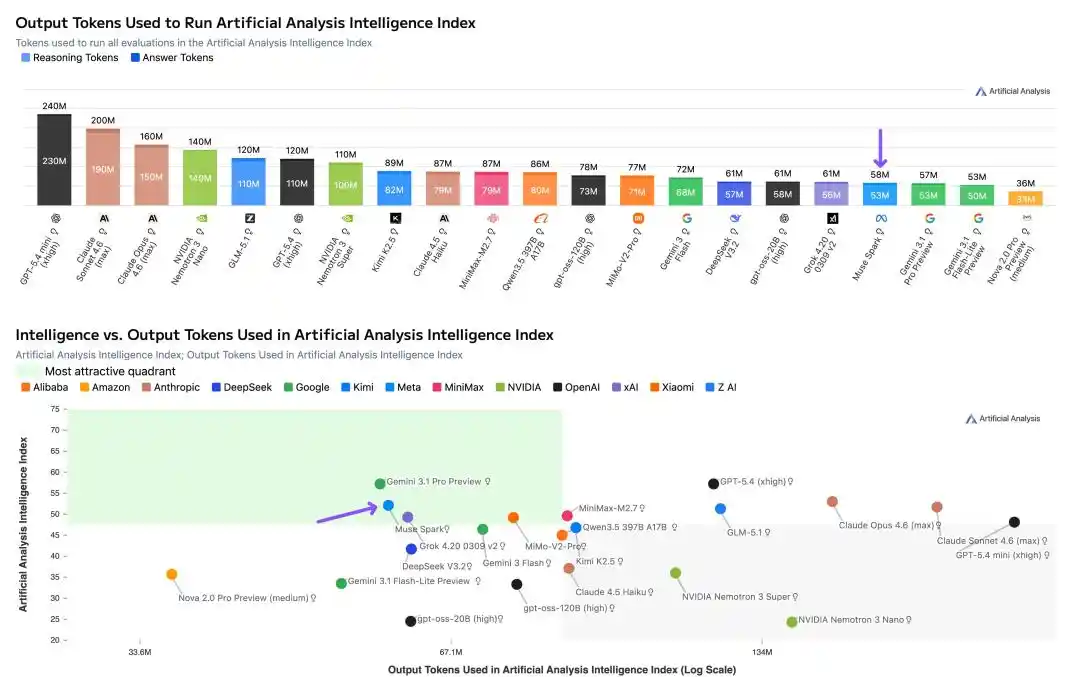
Les tests indépendants d'Artificial Analysis ont également révélé un détail important, l'efficacité des Tokens.
Pour exécuter toute la suite de tests Intelligence Index, Muse Spark a utilisé 58 millions de Tokens de sortie, comparable à Gemini 3.1 Pro (57 millions), mais bien inférieur à Opus 4.6 (157 millions) et GPT-5.4 (120 millions).
Même niveau d'intelligence, consommation de Tokens réduite de moitié aux deux tiers.
De plus, sur FrontierMath, avec des problèmes posés par des experts en mathématiques, Muse Spark a écrasé Gemini 3.1 Pro aux niveaux 1-3, mais s'est classé dernier au niveau 4.

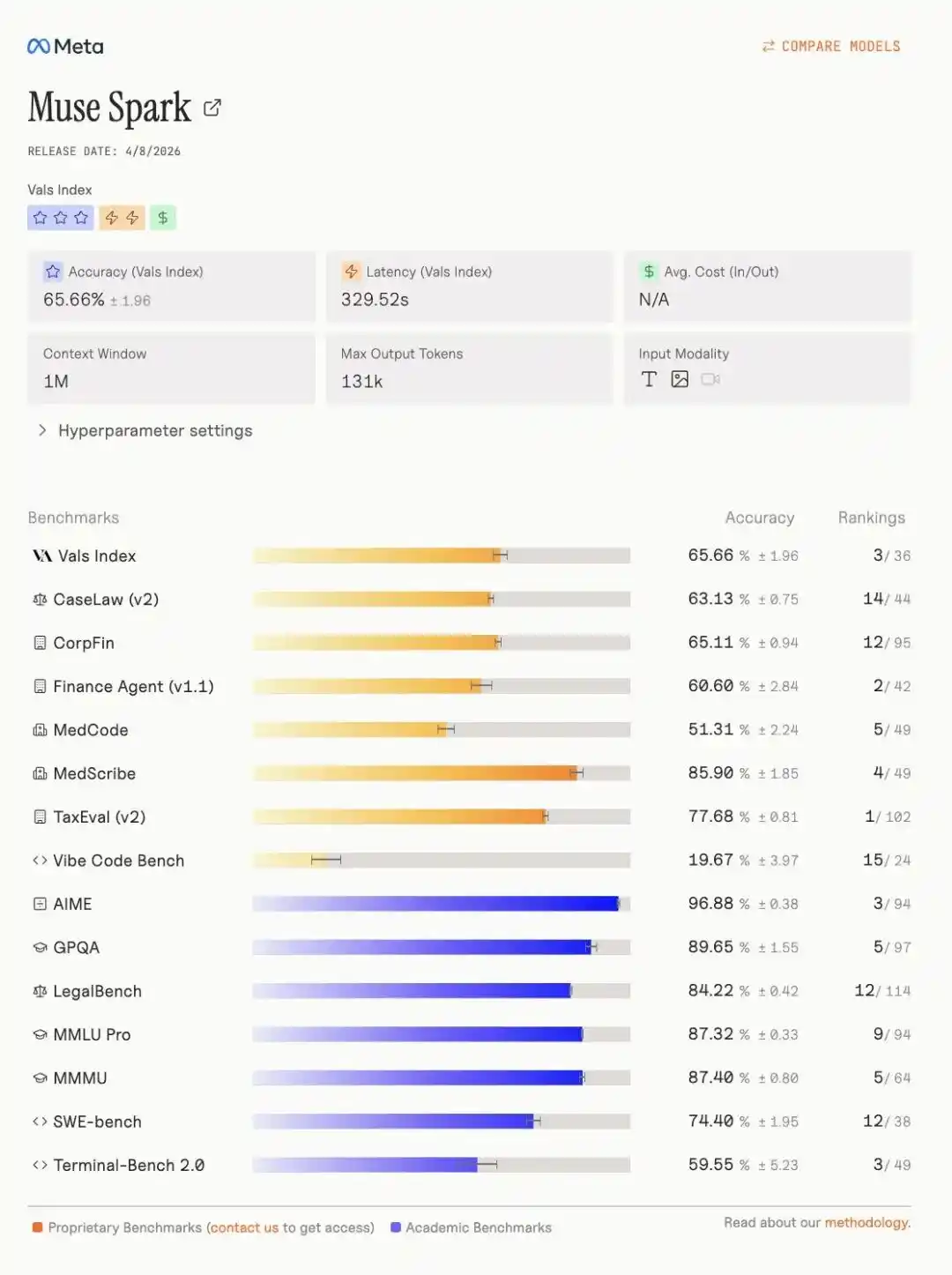
Plus important encore, sur le classement de l'indice Vals, Muse Spark a remporté la troisième place, avec les indicateurs spécifiques suivants.
Un an après la sortie de Llama 4, Meta est de retour dans le peloton de tête de l'AGI.
Réflexion multi-Agents en parallèle, 58% pour réussir « le dernier examen de l'humanité »
Le « Mode Contemplation » est l'atout maître de Muse Spark.
Le mode de pensée traditionnel est un Agent qui réfléchit plus longtemps, le mode contemplation fait réfléchir plusieurs Agents simultanément, puis synthétise la réponse.
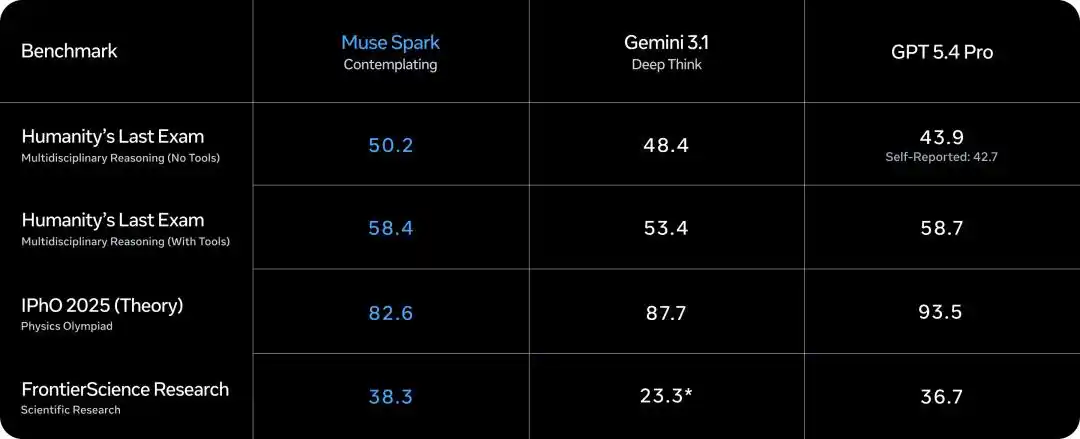
Humanity's Last Exam (sans outils), Muse Spark Mode Contemplation a obtenu 50.2, Gemini Deep Think 48.4, GPT 5.4 Pro 43.9.
Humanity's Last Exam (avec outils), 58.4, Gemini 53.4, GPT 5.4 Pro 58.7, presque à égalité.
FrontierScience Research Recherche scientifique de pointe 38.3, Gemini Deep Think seulement 23.3, GPT 5.4 Pro 36.7.
Cependant, pour les problèmes théoriques des Olympiades de Physique IPhO 2025, Muse Spark Mode Contemplation 82.6, GPT 5.4 Pro a obtenu 93.5, écart significatif.
Globalement, le mode contemplation permet à Muse Spark d'atteindre le niveau du peloton de tête sur les tâches de réflexion les plus difficiles.
Vise « l'intelligence superpersonnelle personnelle », prenez une photo pour avoir un nutritionniste personnel
La direction définie par Meta pour Muse Spark est claire : l'intelligence superpersonnelle personnelle.
Traduit en langage clair, c'est un assistant IA qui vous comprend, vous et le monde qui vous entoure.
En multimodal, Muse Spark est conçu dès la base pour intégrer les informations visuelles跨域.
La démo officielle montre plusieurs scénarios.
Prenez une photo d'une grille de sudoku, Muse Spark peut la transformer en un jeu interactif jouable sur le web.
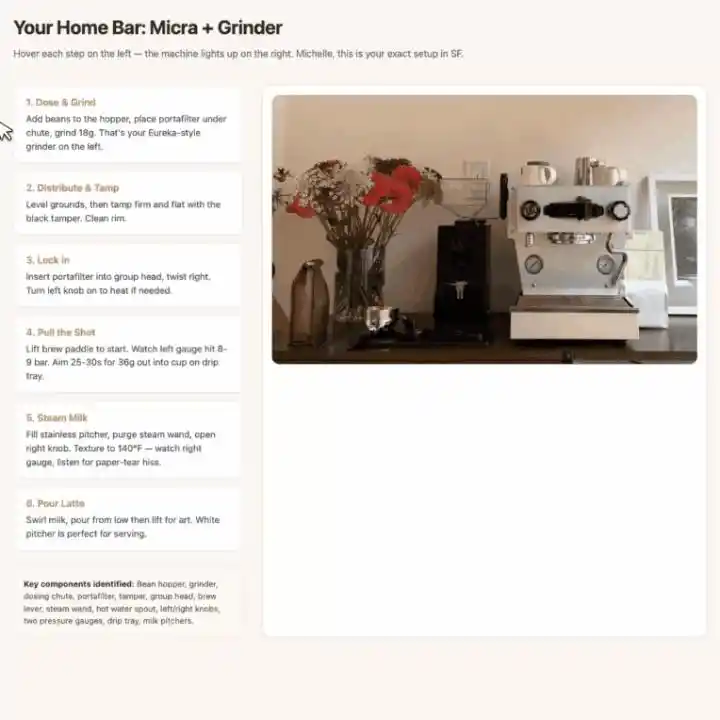
Photographiez une machine à café et un moulin, il identifie d'abord tous les composants clés, puis génère un tutoriel interactif pour latte en page web.
Lorsque vous survolez une étape, la boîte englobante du composant correspondant sur la photo est mise en évidence, le guidage visuel et les étapes opérationnelles correspondent parfaitement.
Les scénarios de santé sont encore plus prometteurs.
Photographiez une table de nourriture, dites-lui « J'ai un cholestérol élevé, je suis pesco-végétarien », Muse Spark mettra un point vert sur les aliments recommandés, un point rouge sur ceux déconseillés.
Le contrôle du Prompt est très fin, il explique directement la logique de l'interface utilisateur.
Le chiffre du score de santé s'affiche directement au-dessus du point sans survol, et en survolant, une fenêtre contextuelle affiche des données détaillées sur les calories, les glucides, les protéines et les graisses, et cette fenêtre est configurée pour « toujours être au premier plan, ne pas être masquée par d'autres points ».

Photographier des poses de yoga suit la même logique.
Il identifie les groupes musculaires étirés par chaque posture, indique le niveau de difficulté, et en survolant, donne des conseils de correction posturale. Les images de deux personnes sont côte à côte, notées de 1 à 10 respectivement.
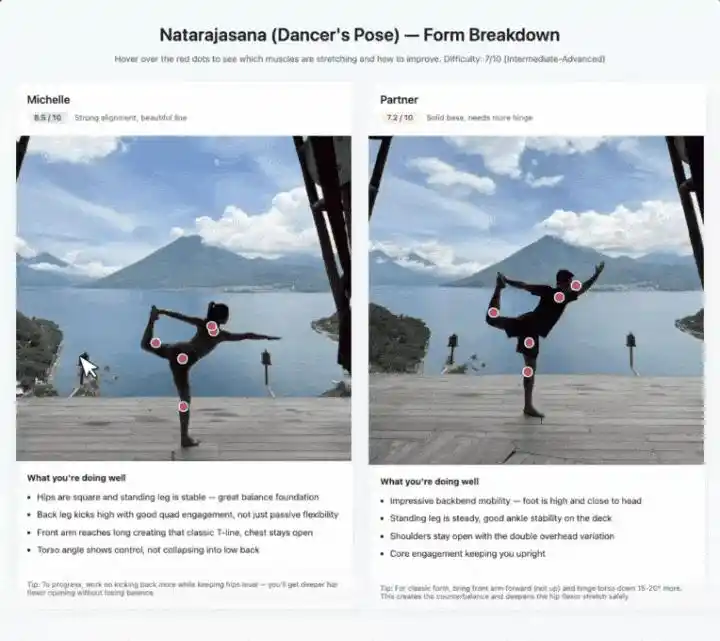
Le soutien sous-jacent de ces démos est la combinaison de问答 visuelle STEM, reconnaissance d'entités et localisation d'objets.
Individuellement, rien de nouveau, mais une fois enchaînés en scénarios, on voit vraiment l'intention produit derrière le terme « intelligence superpersonnelle personnelle ».
Une autre nouvelle fonctionnalité mérite d'être mentionnée séparément, le « Mode Shopping ».
Wang a déclaré dans un tweet que le mode shopping peut « identifier les créateurs, marques et contenus de style que vous suivez sur Instagram, Facebook et Threads, et les transformer en recommandations personnalisées ».
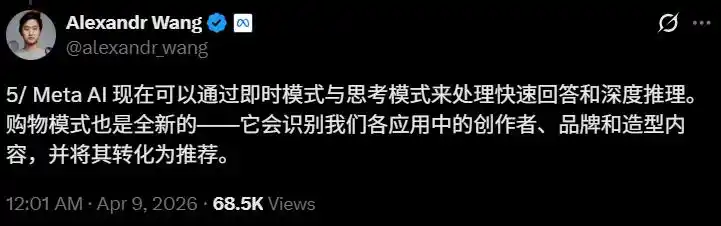
C'est l'avantage unique des données de Meta, données comportementales sociales de 3 milliards d'utilisateurs quotidiens + assistant d'achat IA, un espace de commercialisation très prometteur.
Trois courbes de Scaling, calcul réduit de 90%, la pensée se compresse elle-même
Le point fort du blog technique n'est pas les scores, c'est le Scaling.
Meta explique les performances de Muse Spark en les décomposant selon trois axes : pré-entraînement, apprentissage par renforcement, calcul au moment du test. Chacun a sa propre courbe de mise à l'échelle.
Pré-entraînement : Même capacité, calcul réduit à 1/10
Au cours des neuf derniers mois, Meta a entièrement renouvelé sa stack technologique de pré-entraînement, architecture, algorithmes d'optimisation, stratégie de données, tout a été refait.
Pour mesurer l'effet, Meta a ajusté la loi d'échelle sur une série de versions de petite taille, puis comparé la quantité de FLOPs d'entraînement nécessaire pour atteindre le même niveau de performance.
Conclusion solide, pour le même niveau de capacité, Muse Spark nécessite moins d'un dixième de la puissance de calcul de Llama 4 Maverick.
Cette courbe montre une chose, Meta ne se contente pas d'utiliser plus de GPU, mais améliore la production par unité de calcul dès la base.
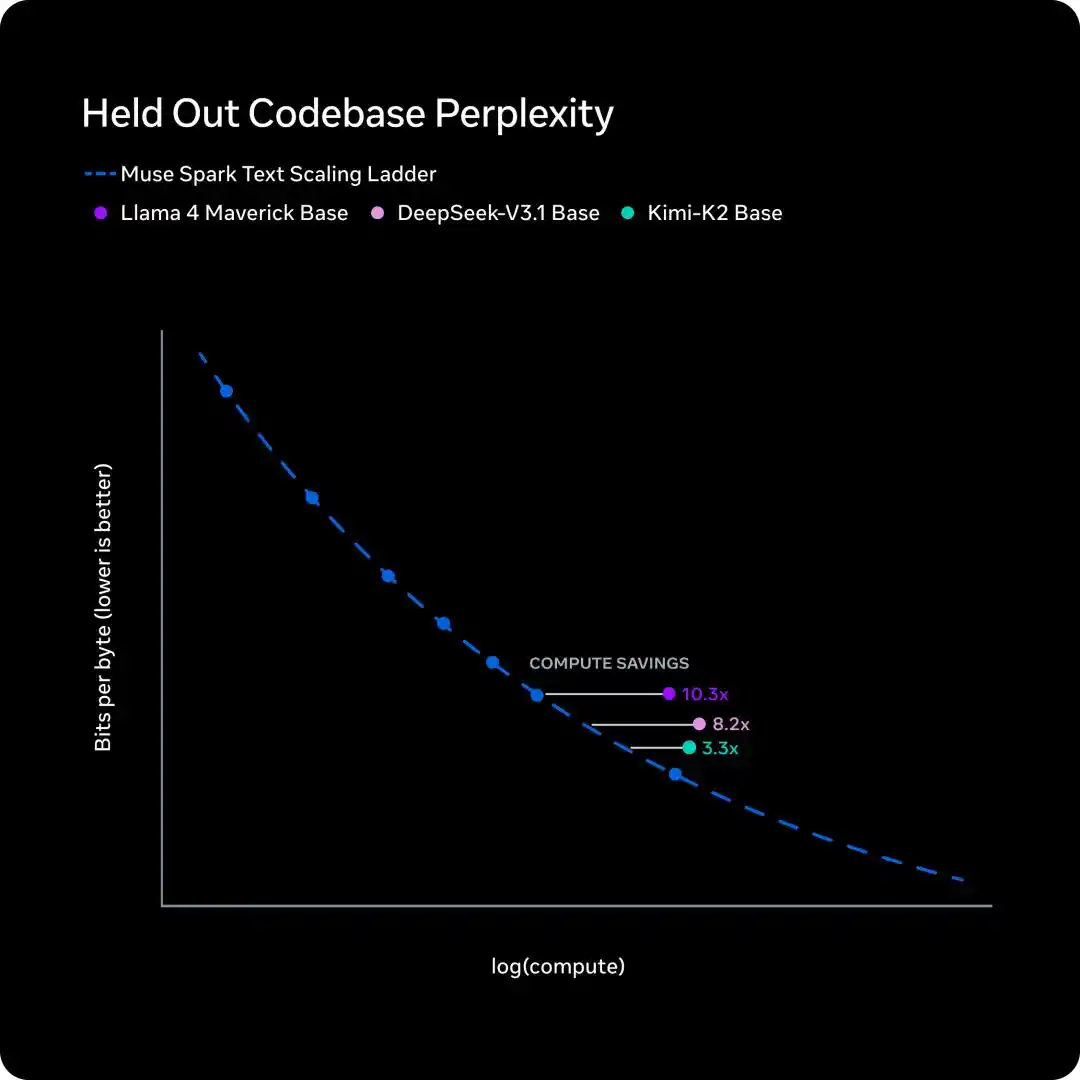
Le commentaire de Yuchen Jin de l'Université de Washington sur X est pertinent : « Je pense toujours que l'infrastructure est la véritable barrière protectrice des laboratoires d'IA. Parce que vous pouvez entraîner plus vite, les chercheurs peuvent expérimenter plus d'idées plus rapidement. »

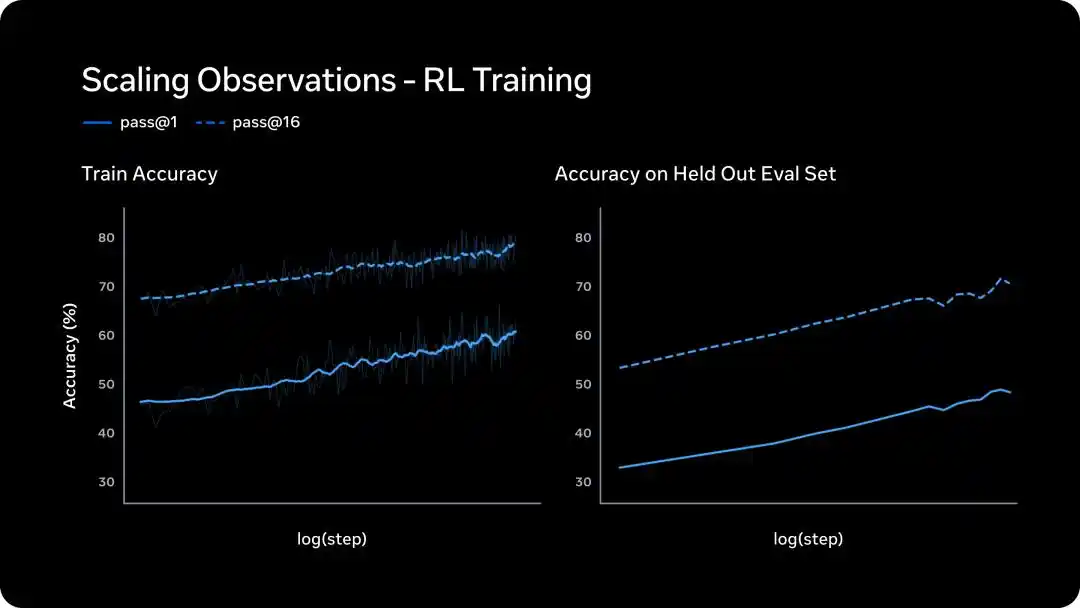
Apprentissage par renforcement : Croissance log-linéaire, généralisation à des problèmes inédits
Le RL à grande échelle est réputé instable, mais Meta affirme que la courbe RL de la nouvelle stack technologique est exceptionnellement lisse.
Le graphique de gauche montre la performance sur l'ensemble d'entraînement. pass@1 et pass@16 (au moins 1 correct sur 16 essais) présentent une croissance log-linéaire.
Cela indique que le RL améliore la fiabilité sans sacrifier la diversité de résolution, Muse Spark ne « s'obstine pas sur une seule voie », il conserve la flexibilité d'explorer différentes solutions.
Le graphique de droite est plus important, c'est la précision sur l'ensemble de validation.
La courbe monte également régulièrement, indiquant que les progrès apportés par le RL ne sont pas du par cœur, mais peuvent se généraliser à de nouveaux problèmes jamais vus.
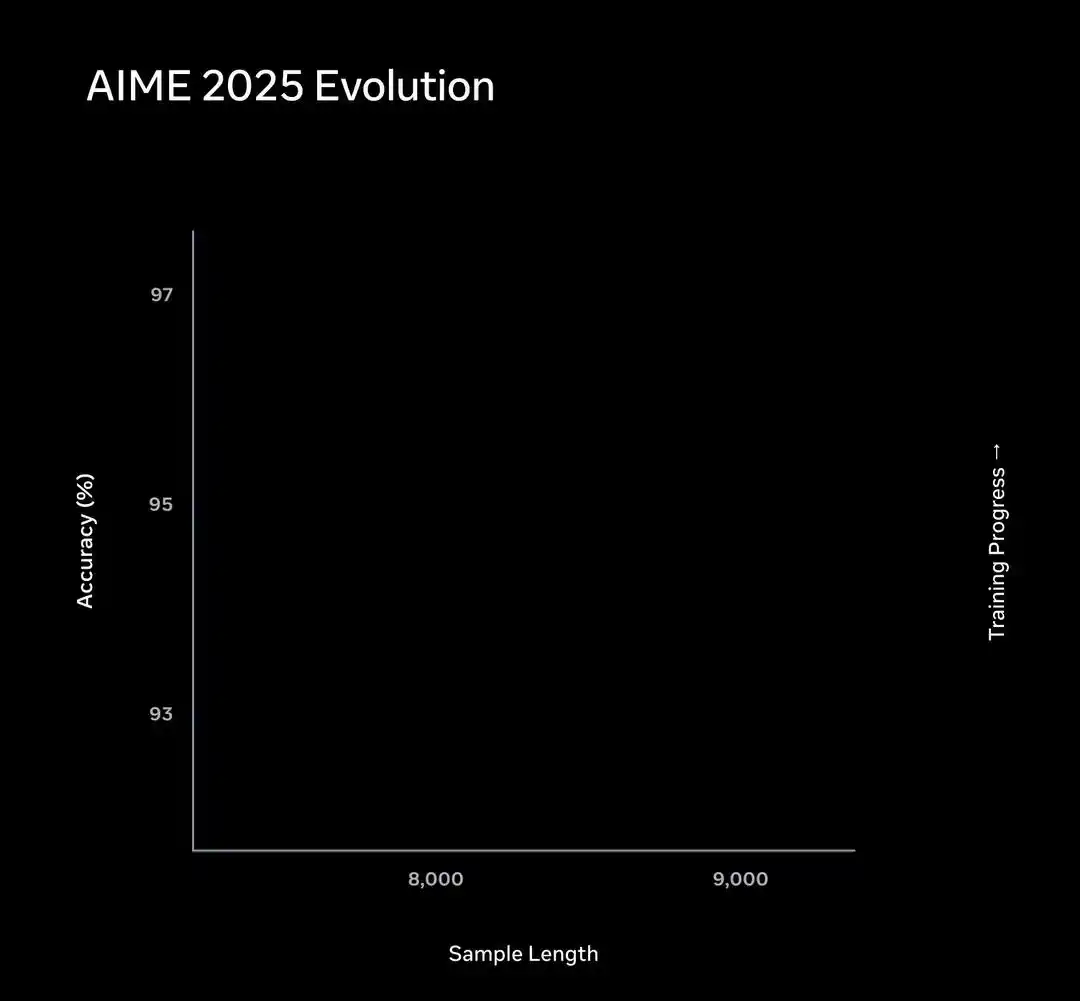
Inférence au moment du test : La pensée d'abord se dilate, puis se compresse, puis se dilate à nouveau
C'est la partie la plus technique et la plus intéressante de l'article.
Le RL a appris à Muse Spark à « simuler mentalement » avant de répondre, c'est l'inférence au moment du test.
Mais le problème est que fournir ce service à des milliards d'utilisateurs, le coût en Token est insupportable.
La solution de Meta se fait en deux étapes.
Première étape, ajouter une « pénalité de temps de réflexion » pendant l'entraînement RL. Vous pouvez réfléchir plus longtemps, mais trop réfléchir vous coûtera des points.
Cette contrainte a provoqué un phénomène intéressant de « transition de phase ».
La performance sur le sous-ensemble AIME est la suivante : au début de l'entraînement, Muse Spark améliore sa précision en réfléchissant plus longtemps, la courbe s'étend vers la droite.
Ensuite, la pénalité de longueur déclenche la « compression de la pensée ». Muse Spark apprend à résoudre le même problème avec beaucoup moins de Tokens, la courbe revient vers la gauche.
Après la compression, il allonge à nouveau le processus de résolution pour relever des défis plus difficiles.
La trajectoire complète dessine un chemin d'évolution en trois phases : d'abord à droite, puis à gauche, puis à nouveau à droite.
La deuxième étape est de résoudre le problème de latence.

Un seul Agent réfléchit plus longtemps, la latence augmente linéairement.
L'approche de Meta est d'augmenter le nombre d'Agents parallèles, 1, 2, 4, 16 Agents réfléchissant simultanément.
Sur le graphique, 16 Agents, à une latence similaire, font passer la précision d'environ 54% à environ 58%.
Le Scaling traditionnel au moment du test échange du temps contre de la qualité, le Scaling multi-Agents échange du parallélisme contre de la qualité, la latence reste presque inchangée.
L'équipe chinoise « la plus chère » de la Silicon Valley, a rendu sa première copie
Derrière Muse Spark, il y a la refonte complète du système IA de Meta par Zuckerberg l'année dernière.
En juin 2025, Meta a acquis 49% de Scale AI pour 14,3 milliards de dollars, recrutant son fondateur Alexandr Wang comme premier directeur de l'IA de Meta, formant le Meta Super Intelligence Lab (MSL).
Ont rejoint à la même époque l'ancien PDG de GitHub Nat Friedman (co-responsable de la recherche produit et applicative), le co-fondateur de SSI Daniel Gross, et 11 chercheurs recrutés chez OpenAI, DeepMind, Anthropic.

Aujourd'hui, la sortie de Muse Spark prouve une chose, les neuf mois de refonte du Meta Super Intelligence Lab ont porté leurs fruits.
L'efficacité du pré-entraînement a été multipliée par un ordre de grandeur, les courbes de mise à l'échelle du RL sont lisses et prévisibles, le multimodal et la santé ont atteint le peloton.
Mais l'écart en code et Agent est là, le mode contemplation n'est pas encore largement ouvert, le calendrier de l'open source reste un « espoir ».
La pression plus réaliste est qu'Anthropic a publié la même semaine Mythos, prétendument « trop puissant pour être divulgué », et la nouvelle création d'OpenAI, nom de code Spud, est en route.
14,3 milliards ont acheté un billet d'entrée. Les examens à venir sont les vrais.
Références :
https://ai.meta.com/blog/introducing-muse-spark-msl/
https://ai.meta.com/blog/scaling-how-we-build-test-advanced-ai/
https://ai.meta.com/static-resource/muse-spark-eval-methodology
https://x.com/alexandr_wang/status/2041909376508985381
Cet article provient du compte officiel WeChat «新智元» (New Wisdom Yuan), auteur : 新智元







