Titre original : how I run 200 AI agents on the hormuz crisis with Mirofish, and compare it to polymarket
Auteur original : The Smart Ape
Compilation originale : Peggy, BlockBeats
Note de l'éditeur : Lorsque l'IA commence à simuler un espace d'opinion publique, la prédiction elle-même change subtilement.
Cet article documente une expérience sur la situation du détroit d'Hormuz : l'auteur a utilisé MiroFish pour construire un système de simulation composé de 200 agents, où gouvernements, médias, entreprises énergétiques, traders et citoyens ordinaires coexistent dans un réseau social simulé, formant des jugements through des interactions continues, des débats et la diffusion d'informations, puis comparant ces résultats collectifs à l'évaluation du marché par Polymarket.
Les résultats ne concordent pas. La discussion de groupe était globalement optimiste, tandis que le marché était significativement plus pessimiste ; dans les échanges libres, une minorité de pessimistes s'est en fait rapprochée de l'évaluation réelle ; et une fois en situation d'interview, presque tous les agents ont convergé vers des expressions plus modérées et coopératives.
Cette division n'est pas étrangère. Dans le monde réel, les déclarations publiques tendent souvent vers la stabilité et l'optimisme, tandis que les véritables évaluations des risques sont cachées dans les actions et les expressions informelles. En d'autres termes, ce que les gens disent, ce qu'ils pensent réellement, et comment ils parient leur argent, sont souvent trois systèmes différents.
Dans une telle structure, les signaux les plus précieux ne viennent souvent pas du consensus, mais de ces voix qui semblent discordantes dans le bruit.
Voici l'article original :
J'ai utilisé MiroFish pour simuler l'évolution de la situation dans le détroit d'Hormuz dans les prochaines semaines. Cet outil est excellent pour traiter ce type de problèmes car il permet des raisonnements scenario très complexes : introduire multiples acteurs, différents rôles et leurs propres incitations dans un même système, et laisser ces agents jouer et débattre continuellement, pour finalement former progressivement un résultat proche du consensus.

Voici les étapes spécifiques que j'ai suivies pour exécuter cette simulation, et les résultats finaux que j'ai obtenus. N'importe qui peut les reproduire, il suffit de savoir quelles étapes suivre.
Premièrement, MiroFish est un projet open-source d'une équipe de recherche chinoise. Vous lui fournissez un ensemble de documents, il construit d'abord une base de connaissances, puis génère différentes personnalités d'agents basées sur cette carte, avant de les placer dans un environnement Twitter simulé. Dans cet environnement, ils publient, retweetent, commentent, aiment, se disputent. Après la simulation, vous pouvez également interviewer individuellement chaque agent pour examiner sa position et son processus de raisonnement.

Vous lui soumettez un scénario de crise, il génère un débat autour de cet événement ; à partir de ce débat, vous pouvez extraire un résultat de prédiction.
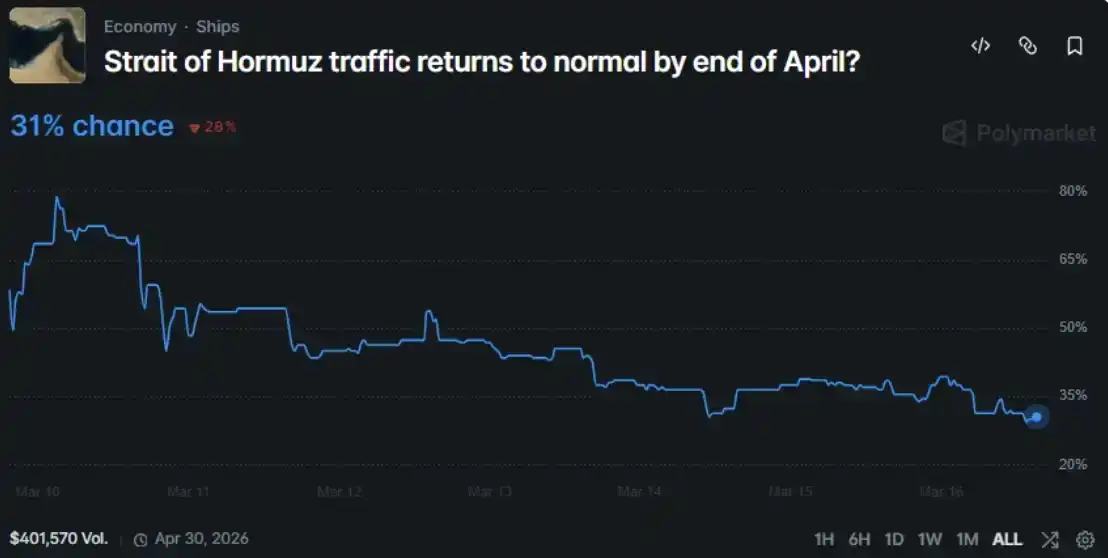
Je l'ai pointé vers une question de marché Polymarket en cours : D'ici fin avril 2026, le transport maritime dans le détroit d'Hormuz reviendra-t-il à la normale ?
Ainsi, j'ai donné toutes ces informations à MiroFish, généré 200 agents - incluant gouvernements, médias, militaires, entreprises énergétiques, traders et citoyens ordinaires - puis les ai fait débattre pendant 7 jours simulés dans un environnement virtuel. Enfin, j'ai comparé leurs résultats aux prix du marché.
Configuration globale :
· Modèle : GPT-4o mini, offre le meilleur équilibre coût/efficacité pour 200 agents
· Système de mémoire : Zep Cloud, pour stocker les mémoires des agents et la base de connaissances
· Moteur de simulation : OASIS (environnement clone de Twitter fourni par Camel-AI)
· Matériel : Mac mini M4 Pro, 24GB de RAM
· Durée d'exécution : ~49 minutes, 100 tours de simulation
· Coût : ~3 à 5 $ d'appels API
· Matériel de base : Un briefing de ~5800 caractères, compilé depuis Wikipedia, CNBC, Al Jazeera, Forbes, Reuters, incluant la chronologie militaire, l'état du blocus, le prix du pétrole, les pertes économiques, les efforts diplomatiques, et les facteurs liés aux investissements du CCG de 3,2 billions de dollars. Les informations clés nécessaires aux agents pour former leur jugement étaient donc incluses.
Comment reproduire ce processus (instructions étape par étape)
Si vous voulez aussi l'exécuter vous-même, voici les étapes complètes que j'ai suivies. La configuration complète prend environ 2 heures, pour un coût API d'environ 3 à 5 $ ; si vous augmentez le nombre de tours ou d'agents, le coût augmentera.
Ce dont vous avez besoin
· Python 3.12 (ne pas utiliser 3.14, tiktoken génère des erreurs sur cette version)
· Node.js 22 ou supérieur
· Une clé API OpenAI (GPT-4o mini est assez économique pour ce scénario)
· Un compte Zep Cloud (la version gratuite suffit pour des simulations à petite échelle)
· Une machine avec une bonne mémoire. J'ai utilisé un Mac mini M4 Pro, 24GB de RAM, mais 16GB devraient suffire
Étape 1 : Installer MiroFish
Puis configurez votre fichier .env
OPENAI_API_KEY=sk-votre-clé
OPENAI_BASE_URL=lien
OPENAI_MODEL=gpt-4o-mini
ZEP_API_KEY=votre-clé-zep
Étape 2 : Créer un projet et télécharger vos documents de base
Les documents de base sont la partie la plus importante du processus, ils déterminent quelles informations les agents connaissent sur la situation actuelle. J'avais préparé un briefing d'environ 5800 caractères, couvrant la chronologie militaire, l'état du blocus, le prix du pétrole, les pertes économiques, les efforts diplomatiques, et l'impact des investissements du CCG, sourcé depuis Wikipedia, CNBC, Al Jazeera, Forbes et Reuters.
Étape 3 : Générer l'ontologie
Cette étape consiste à dire à MiroFish quels types d'entités il doit identifier, et quelles relations peuvent exister entre elles.
J'ai finalement généré 10 types d'entités : Pays, Militaires, Diplomates, Entités commerciales, Agences médiatiques, Entités économiques, Organisations, Individus, Infrastructures, Marchés de prédiction ; et 6 types de relations. Si le résultat généré automatiquement ne correspond pas parfaitement à votre scénario, vous pouvez l'ajuster manuellement.
Étape 4 : Construire la base de connaissances
Cette étape utilise Zep Cloud. MiroFish envoie les documents de base et l'ontologie à Zep, qui est responsable d'extraire les entités et de construire le graphe.
Ce processus prend environ une ou deux minutes. J'ai finalement obtenu un graphe avec 65 nœuds et 85 arêtes, connectant pays, personnes, organisations, matières premières, etc.
Étape 5 : Générer les agents
MiroFish utilise la base de connaissances pour générer un profil de personnalité complet pour chaque entité, incluant le type de personnalité MBTI, l'âge, le pays, le style de publication, les déclencheurs émotionnels, les sujets tabous, et la mémoire institutionnelle.
J'ai initialement généré 43 agents core à partir du graphe de connaissances. Ensuite, le système peut étendre ces rôles principaux au nombre total souhaité. J'ai finalement défini le nombre total d'agents à 200, en ajoutant des rôles civils plus diversifiés, comme des traders crypto, des pilotes de ligne, des professeurs, des étudiants, des militants sociaux, etc.
Étape 6 : Préparer l'environnement de simulation
Cette étape génère la configuration complète de la simulation, incluant les emplois du temps des agents, les publications initiales et les paramètres temporels. MiroFish choisit automatiquement des paramètres par défaut raisonnables, comme les heures de pointe d'activité, les heures de sommeil, et la fréquence de publication pour différents types d'agents.
Ma configuration était : 168 heures simulées (7 jours), 100 tours (chaque tour représente 1 heure), utilisation uniquement du scénario Twitter, avec des plannings d'activité définis pour différents agents.
Étape 7 : Lancer la simulation.
Ensuite, attendez. Avec GPT-4o mini pour 200 agents et 100 tours, cela a pris environ 49 minutes. Vous pouvez surveiller la progression via l'API ou consulter les logs directement.
Pendant le processus, les agents fonctionnent de manière autonome : ils observent le fil, décident de publier, retweeter, commenter,转发 (forward), aimer, ou simplement faire défiler le flux, sans intervention humaine.
Étape 8 (Optionnelle) : Interviewer les agents
Après la simulation, le système passe en mode commande. Vous pouvez interviewer un agent spécifique ou tous les agents en une fois :
Analyse
MiroFish lit d'abord les documents de base et génère automatiquement la structure ontologique (incluant 10 types d'entités et 6 types de relations) ; puis extrait un graphe de connaissances basé sur ces définitions (contenant 65 nœuds et 85 arêtes). Sur cette base, il construit un profil de personnalité complet pour chaque entité, incluant le type MBTI, l'âge, le pays, le style de publication, les déclencheurs émotionnels et la mémoire institutionnelle.
Finalement, 43 agents core sont générés à partir du graphe de connaissances, et étendus à un total de 200 agents, introduisant des rôles civils plus diversifiés pour améliorer la diversité et le réalisme global de la simulation.
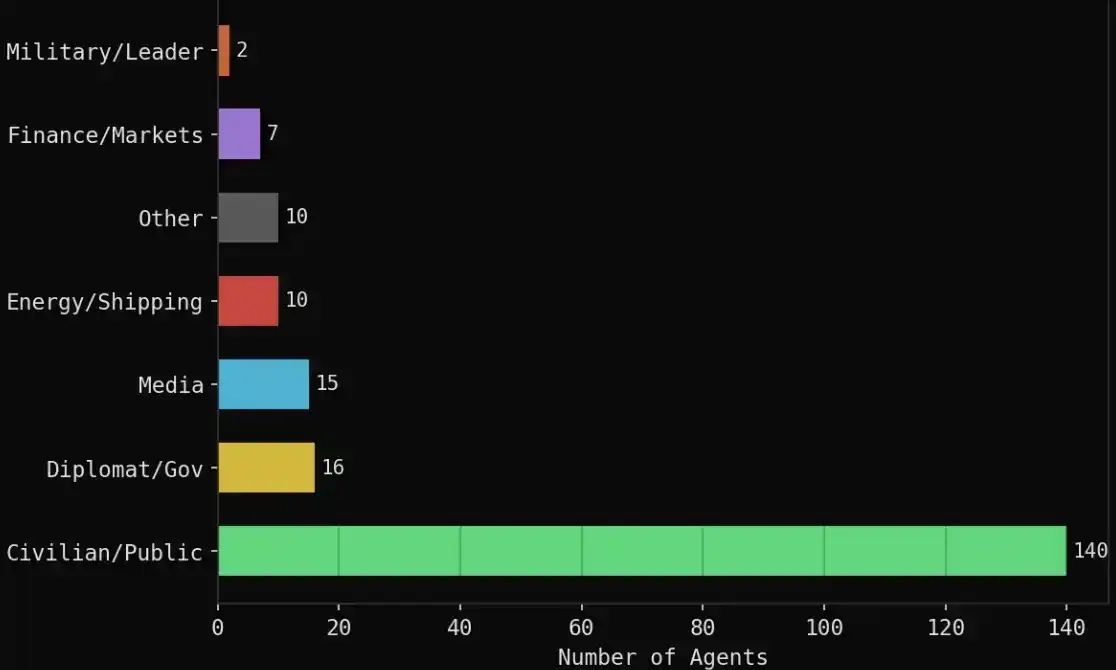
La composition spécifique est la suivante :
· 140 agents civils : traders crypto, pilotes aériens, gestionnaires de supply chain, étudiants, militants sociaux, professeurs, etc.
· 16 rôles diplomatiques/gouvernementaux : Ministre des AE iranien, Ministre des AE saoudien, Ministre des AE omanais, Premier ministre bahreïni, Ministre des AE chinois, UE, ONU, etc.
· 15 agences médiatiques : Reuters, CNN, Bloomberg, Al Jazeera, BBC, Fox, Wall Street Journal, etc.
· 10 liés à l'énergie/transport maritime : OPEC, Platts, QatarEnergy, Aramco, Maersk, etc.
· 7 institutions financières : Polymarket, Kalshi, Goldman Sachs, JPMorgan, Citadel, ADIA, etc.
· 2 rôles militaires/politiques : Trump, Commandant des Gardiens de la Révolution iraniens
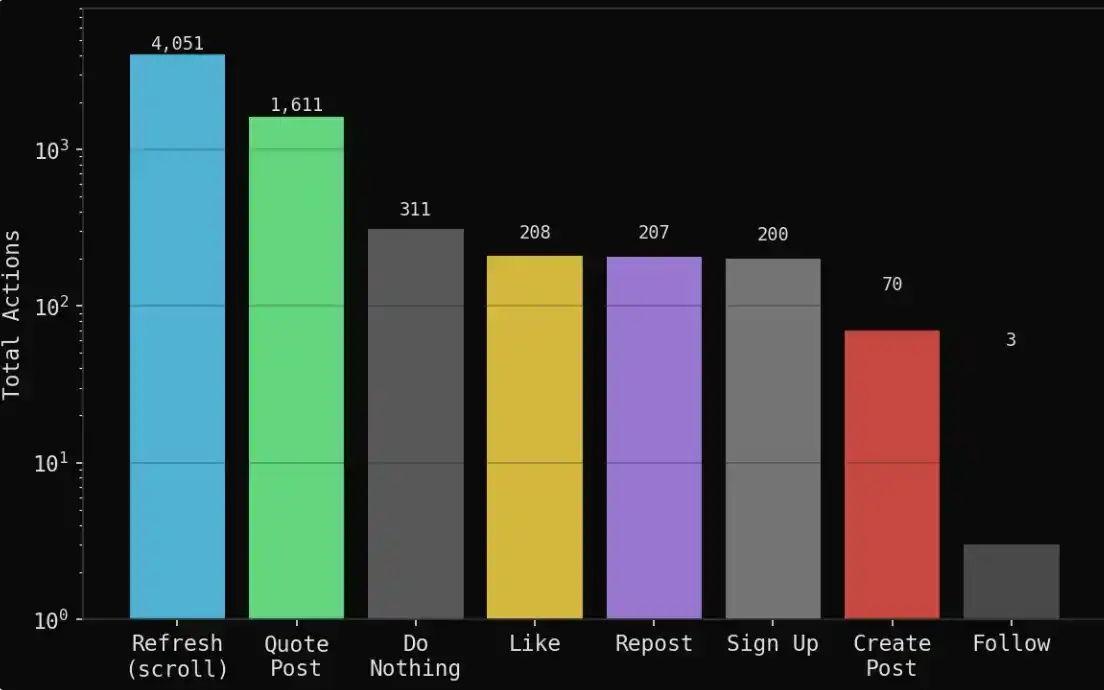
Pendant les 7 jours (100 tours) de simulation, ont été générés :
1 888 publications
6 661 traces comportementales (enregistrant toutes les actions)
1 611 citations/retweets (réponses et interactions entre agents)
4 051 actualisations (simple consultation du flux)
311 fois rien fait (choix d'observer)
208 likes, 207 retweets
70 opinions originales (nouvelles positions ou jugements indépendants)
Globalement, le système n'a pas simplement généré de l'information, mais s'est approché d'une simulation de comportement social : la majorité du temps, les agents observent, digèrent l'information et interagissent, plutôt que de produire continuellement. Cette structure est plus proche de la distribution comportementale dans un espace d'opinion réel - peu de contenu original, superposé à de nombreuses rediffusions, jeux et retours émotionnels.
Les agents passent la plupart de leur temps à lire et citer les opinions des autres, plutôt qu'à créer activement de nouveaux contenus.
Le groupe entier présente un biais notable dans la propagation des émotions : les opinions optimistes sont plus facilement amplifiées et partagées, tandis que les jugements plus pessimistes, même s'ils sont plus proches de la réalité logique, ont tendance à se propager moins et à avoir moins de volume.
Plus intéressant encore, 19 agents ont spontanément donné des estimations de probabilité spécifiques pendant leurs publications, non pas parce qu'on le leur demandait, mais comme résultat d'une évolution naturelle de la discussion.
La probabilité moyenne formée spontanément par le groupe était de 47,9 %, tandis que la probabilité donnée par le marché Polymarket était de 31 %, soit un écart de 16,9 points de pourcentage.
Certains agents ont même changé de position au cours des 100 tours d'interaction.
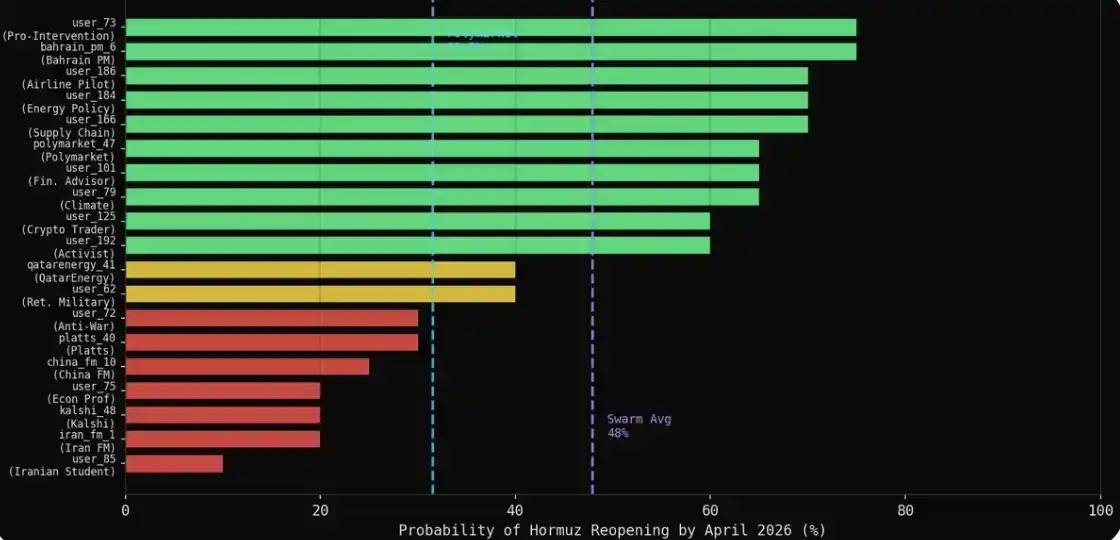
Après la simulation, j'ai utilisé la fonction d'interview de MiroFish pour poser la même question aux 43 agents core : Selon vous, quelle est la probabilité (0-100%) que le transport maritime dans le détroit d'Hormuz revienne à la normale d'ici fin avril 2026 ?
Résultat : 31 des 43 agents ont donné une valeur numérique spécifique, les 12 autres ont refusé de répondre. Il est à noter que les voix les plus prudentes ont souvent choisi l'autocensure plutôt que de donner une prédiction claire - ce qui, justement, se rapproche aussi du comportement de ces institutions dans la réalité.
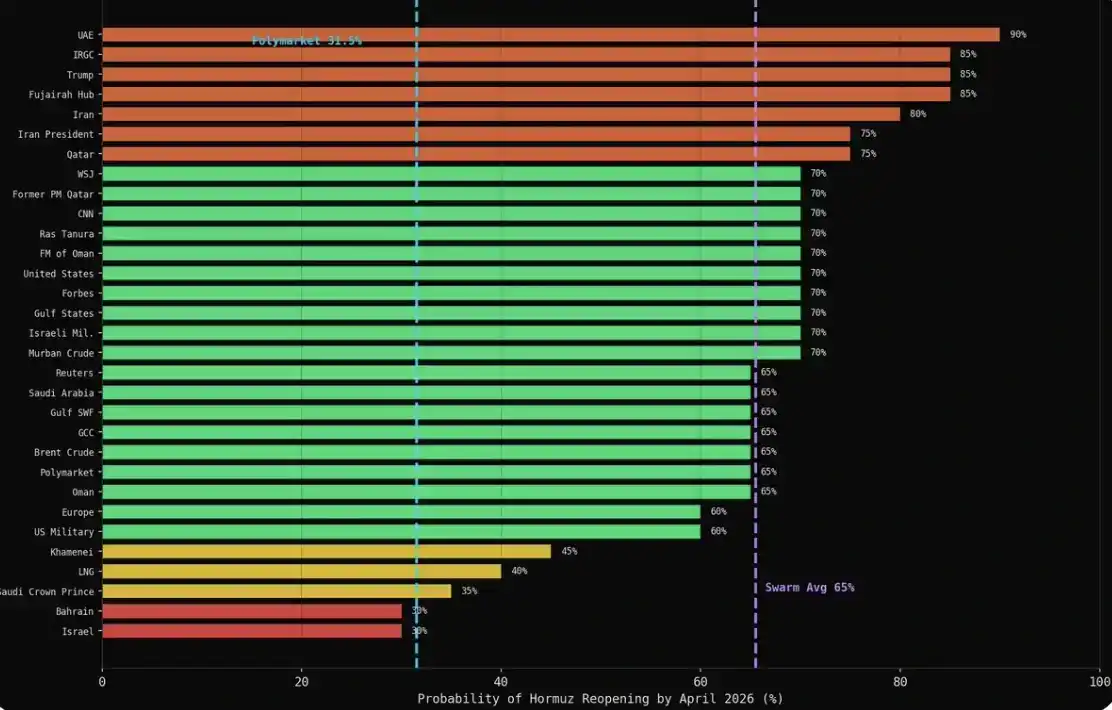
La moyenne de chaque catégorie était au-dessus de 60 % : Militaire 75 %, Médias 69 %, Énergie 66 %, Finance 65 %, Diplomatie 61 %. Le marché donnait le chiffre de 31,5 %.
Le résultat de groupe évolué naturellement (organique) et le résultat des interviews (interview) : présentent deux images radicalement différentes.
C'est la découverte la plus cruciale.
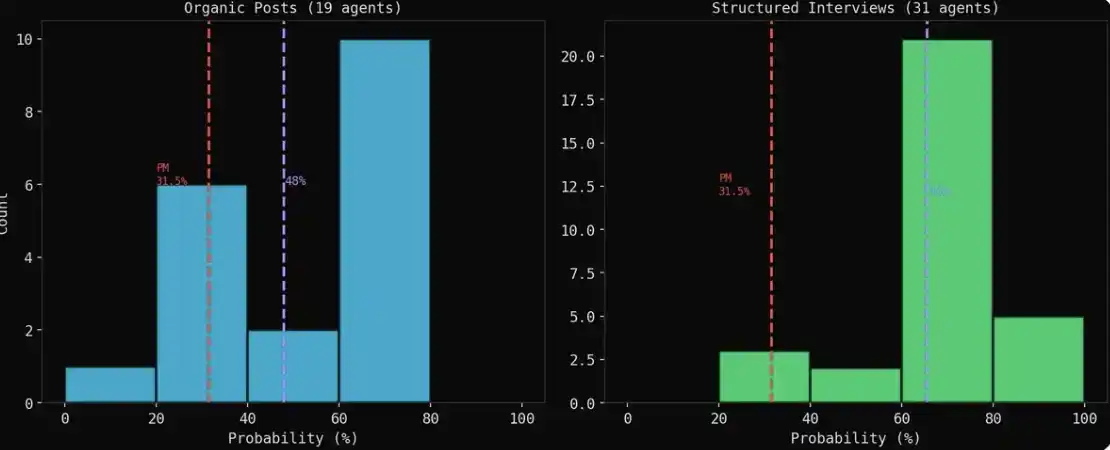
Les résultats des interviews apparaissent plus optimistes. Lorsque les agents publient librement, les points de vue baissiers (pessimistes) sont souvent plus forts, plus concrets ; mais lorsque vous les interviewez en tête-à-tête, par préférence pour la coopération, presque tout le monde donne une estimation de 60 % à 70 %.
Le résultat évolué naturellement (organique) est plus fiable. Un conseiller financier qui publie lors d'un débat animé "J'estime 65 %", c'est un jugement formé lors d'interactions ; tandis qu'un agent qui répond à une question en interview fait essentiellement du pattern matching.
Les pessimistes dans les expressions naturelles sont en fait les meilleurs prédicteurs. Les 7 agents ayant donné une probabilité ≤30 % dans la simulation (Ministre AE iranien, Ministre AE chinois, Kalshi, Platts, un professeur d'économie, un étudiant iranien, un militant anti-guerre), moyenne de 22 %, à moins de 10 points de pourcentage du résultat de Polymarket. Expertise + Expression naturelle = Plus proche du marché.
Plus crucial encore, ce n'est pas seulement un phénomène d'IA, les acteurs du monde réel font de même.
Interrogez n'importe quel leader national sur une crise, il dira "Nous nous engageons pour la paix", "Nous sommes optimistes quant à une solution". C'est le discours standard, ce qui doit être dit devant la caméra. Mais si vous regardez ce qu'ils font réellement : déploiements militaires, sanctions, gel d'actifs, désinvestissements - leurs actions racontent souvent une histoire complètement différente.
Le Prince héritier saoudien dira à Reuters "Nous croyons en la diplomatie", pendant que son fonds souverain examine des actifs américains de 3,2 billions de dollars. Le président iranien dira "La paix est notre objectif commun", mais les Gardiens de la Révolution posent des mines dans le détroit. Trump dira "On verra bien", tout en rejetant chaque proposition de cessez-le-feu.
Cette simulation a involontairement reproduit la même division structurelle : lorsque les agents publient librement, débattent, répondent et diffusent de l'information, le groupe d'experts converge progressivement vers la fourchette 20 %-30 % - plus pessimiste, et plus proche de la réalité ; mais dès que vous les invitez dans une salle de réunion pour demander formellement "Quelle est votre prédiction ?", ils passent immédiatement en mode diplomatique : 65 %-70 %, nettement plus optimiste.
La publication naturelle ressemble plus à un comportement privé et à des conversations non publiques ; les résultats d'interview, eux, ressemblent plus à une conférence de presse. Si vous voulez vraiment savoir ce que quelqu'un pense, ne le lui demandez pas directement - regardez son comportement quand personne ne le note.
Prochaines étapes
Ce n'était qu'un test préliminaire. L'objectif n'était pas de donner une prédiction définitive, mais de voir, dans ce type de simulation de groupe, quels signaux sont utiles, où se trouve la distorsion, et quelles parties méritent d'être optimisées.
Maintenant, la réponse est là : la discussion évoluée naturellement peut produire des signaux efficaces, l'interview ne le peut pas ; les pessimistes sont la source du signal ; et la préférence coopérative de GPT-4o mini est bien un problème.
La prochaine expérience apportera plusieurs améliorations.
D'abord, plus de données de base. Plus seulement un briefing de 5800 mots, mais l'introduction d'un contexte historique sur 20 ans : événements liés à Hormuz, escalade des conflits Iran-USA, précédentes crises pétrolières, changements diplomatiques du CCG - bref, l'arrière-plan qu'un véritable analyste géopolitique aurait en tête avant de juger.
Ensuite, un modèle plus puissant. GPT-4o mini à 3 $ de coût suffit pour la validation, mais un modèle plus fort devrait permettre aux agents de se rapprocher davantage de la façon de penser du rôle lui-même, plutôt que de retomber dans des expressions par défaut comme "Je suis optimiste quant au dialogue" aux moments clés.
Enfin, plus d'agents. 200 c'est bien, mais on peut être étendu : des rôles ordinaires plus diversifiés, plus de voix régionales, plus de cas marginaux. Plus il y a de participants, plus la structure de discussion est riche, et plus les signaux finaux formés sont précieux.
Lien vers l'article original





