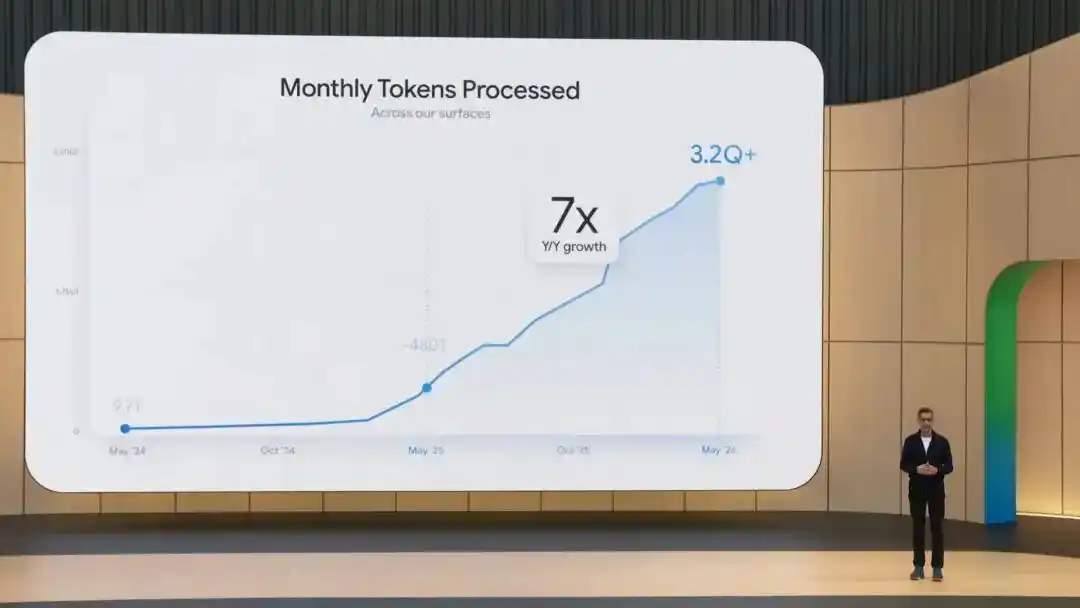
L'application Gemini dépasse les 900 millions d'utilisateurs actifs mensuels,traite 3200 billions de tokens par mois, et Nano Banana a généré plus de 50 milliards d'images...
Ces chiffres ont été présentés d'emblée par Sundar Pichai, le PDG de Google, lors de la conférence Google I/O qui s'est achevée tôt ce matin.
Au cours de l'année écoulée, l'IA est devenue le thème principal de tous les secteurs, et le rôle de Gemini chez Google a évolué : d'une application unique, il est devenu la capacité d'IA fondamentale la plus importante intégrée dans tous les produits Google.
Cette conférence a également commencé par les modèles, avant d'aborder les produits de développement et d'agent.
Gemini Omni oriente la génération vidéo de Google vers un « modèle mondial », tandis que Gemini 3.5 Flash est, avec les outils de programmation IA, poussé vers une plateforme de développement d'agents.
Ces deux capacités s'intègrent ensuite dans l'écosystème complet de Google : recherche, application Gemini, Flow, Spark, Chrome, lunettes XR et scénarios de commerce électronique.
Gemini Omni fait son apparition, le moment « Nano Banana » arrive pour la vidéo
Le premier point largement développé lors de la conférence a été Gemini Omni. Nous avons réalisé une vidéo comparative avec Seedance 2.0 pour observer les différences.
Google décrit Gemini Omni comme un nouveau modèle capable de « créer tout type de contenu à partir de n'importe quelle entrée ».
Il combine les capacités de raisonnement de Gemini avec les modèles médias génératifs existants de Google, dans le but d'améliorer la compréhension du monde par le modèle, ses capacités de génération multimodale et d'édition.

Google souligne que les modèles comme Veo, Nano Banana, Genie peuvent déjà générer des vidéos, des images et des simulations interactives, mais que Gemini Omni va plus loin, en commençant à traiter des problèmes plus proches du monde physique comme la cinétique ou la gravité.
Un exemple présenté en direct lors de la conférence était une vidéo explicative sur le repliement des protéines. L'utilisateur n'a qu'à saisir une instruction comme « génère une animation en pâte à modeler expliquant le repliement des protéines », et Omni peut transformer un concept scientifique abstrait en contenu vidéo.

Il prend également en charge une édition vidéo plus naturelle. Les utilisateurs peuvent télécharger leur propre vidéo, puis en modifier le style, ajouter des éléments, ajuster les détails de manière conversationnelle, voire transformer un simple cercle en un trou noir, ou une scène de promenade nocturne en un plan plus dramatique.

Google indique que Gemini Omni commence par la vidéo, puis évoluera progressivement vers « n'importe quelle entrée vers n'importe quelle sortie ». C'est aussi la raison pour laquelle Google a toujours conçu Gemini comme un modèle multimodal.
Le premier modèle de la famille Omni, Gemini Omni Flash, est déjà déployé dans les produits Google, tandis que des informations supplémentaires sur Omni Pro seront communiquées ultérieurement. Les fonctionnalités Omni dans l'application Gemini sont également ouvertes aux abonnés Google AI Plus, Pro et Ultra.
Cela signifie que Gemini Omni n'est pas seulement un modèle de génération vidéo. Google souhaite l'inscrire dans le récit du « modèle mondial » : le modèle ne génère pas seulement des images, il doit comprendre les relations physiques, les mouvements et la logique des scènes qu'elles représentent.
Une fois intégré dans des applications comme Gemini App, Google Flow et YouTube Shorts, Omni étendra également les outils de création générative de Google de l'édition d'images à l'édition vidéo.
Gemini 3.5 Flash est disponible, la programmation par IA passe en mode ultra-rapide
Si Gemini Omni correspond à la génération et l'édition, Gemini 3.5 Flash correspond à la vitesse, au coût et à la capacité d'exécution.

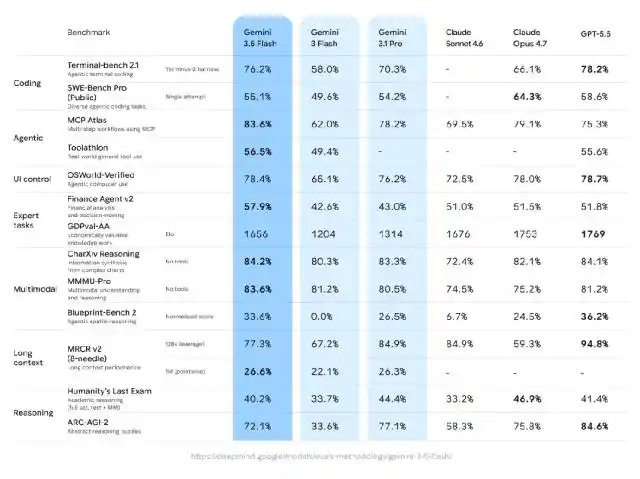
Google a présenté Gemini 3.5 Flash lors de la conférence, le décrivant comme l'un des premiers modèles de la série Gemini 3.5, orienté vers le codage agentique, les tâches à long terme et les flux de travail réels.
Par rapport au 3.1 Pro, le 3.5 Flash montre des améliorations significatives dans presque tous les tests de référence, en particulier pour les capacités de codage, ainsi que dans des évaluations plus proches des tâches économiques réelles comme GDPVal.
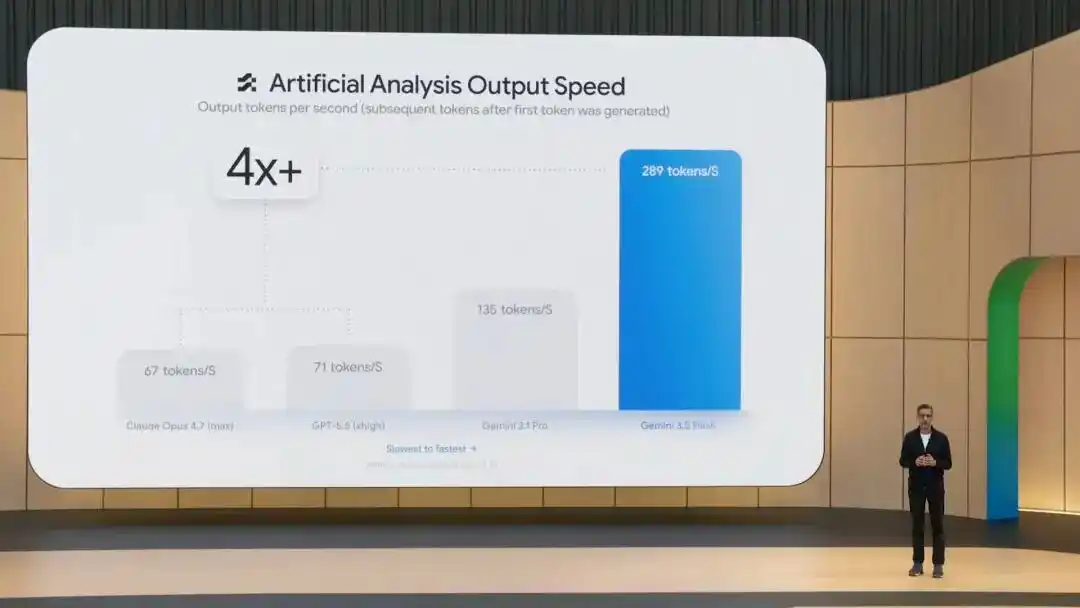
Outre de bonnes performances aux tests de référence, le 3.5 Flash est 4 fois plus rapide que les autres modèles de pointe en termes de vitesse de sortie des tokens, et après optimisation spécifique dans Antigravity, cette vitesse peut atteindre 12 fois.
Il est intéressant de noter qu'en mars dernier, les tâches de développement internes de Google traitaient environ 500 milliards de tokens par jour, doublant ensuite toutes les quelques semaines, pour dépasser désormais les 3 billions de tokens par jour. Google appelle cela une boucle de rétroaction, utilisant une utilisation réelle à grande échelle pour continuer à améliorer le 3.5 Flash.
Lancé en même temps que le modèle, Antigravity 2.0 passe d'un IDE avec agent intégré à une application de bureau indépendante, se recentrant sur l'agent. L'utilisateur ne se contente plus de faire assister l'IA dans l'éditeur pour écrire du code, mais utilise la conversation avec l'Agent, les productions d'Agent et la collaboration multi-agents pour accomplir des tâches de développement.
Antigravity 2.0 intègre un CLI complet, l'Antigravity SDK, une prise en charge vocale native du modèle audio Gemini, et des services comme Android, Firebase, Google AI Studio. Antigravity 2.0, en tant qu'application de bureau indépendante, est désormais ouverte aux utilisateurs du monde entier.
Google a expliqué la direction d'Antigravity 2.0 avec une démonstration intensive en direct : faire construire un système d'exploitation fonctionnel à partir de zéro par un Agent. Cette tâche a été exécutée en parallèle par 93 sous-agents, pendant 12 heures, initiant plus de 15 000 requêtes modèles, traitant 2,6 milliards de tokens, et générant les modules clés comme l'ordonnanceur, la gestion mémoire, le système de fichiers à partir d'un projet vide.
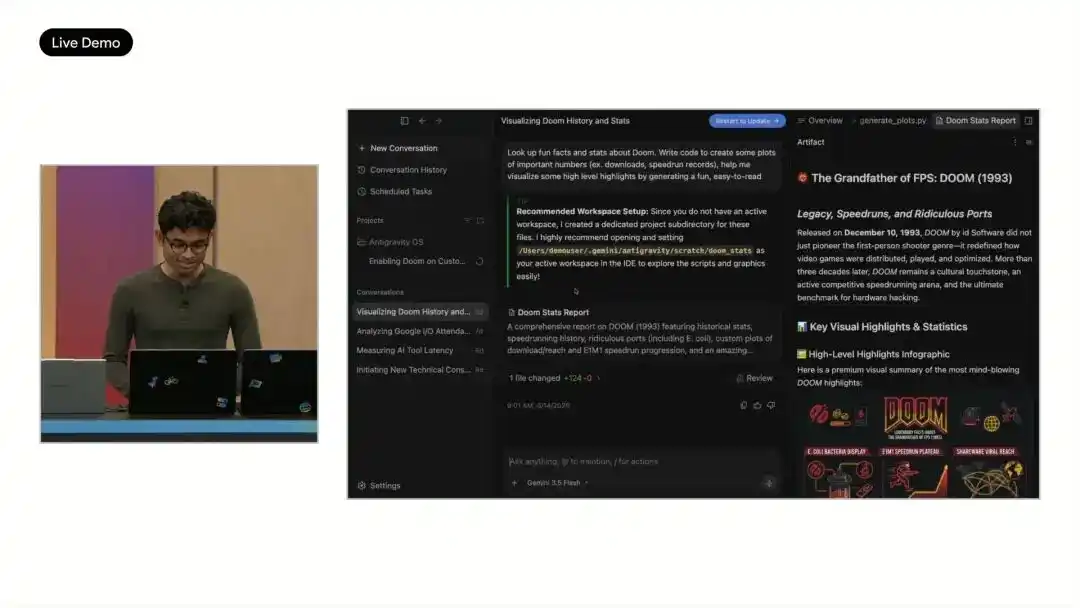
Google affirme que cela n'aurait pas été possible avec Gemini 3.1 Pro, tandis qu'avec Gemini 3.5 Flash, cela a consommé moins de 1000 dollars de crédits API.
La démonstration en direct a également montré ce système exécutant le programme du petit train SL et Doom. Comme le système manquait initialement de pilotes vidéo et clavier, Antigravity a continué à générer le code correspondant et à corriger les erreurs, permettant à Doom de fonctionner. Google ajoute que des projets comme des suites d'édition photo, des applications de messagerie en temps réel, des plateformes de collaboration multi-utilisateurs ont été testés de manière similaire, réduisant des travaux d'ingénierie de plusieurs jours à quelques heures, voire moins.
Gemini 3.5 Flash est ouvert à tous les utilisateurs, couvrant les produits Google et l'API. Gemini 3.5 Pro est encore en usage et amélioration interne, son ouverture est prévue le mois prochain.
De la barre de recherche à l'agent d'information, Google refait la recherche IA
Après les modèles et les outils de développement, Google s'est concentré sur la recherche. La recherche Google, c'est maintenant la recherche IA.

Google indique que le mode IA dépasse le milliard d'utilisateurs actifs mensuels, et que le volume de requêtes double chaque trimestre depuis son lancement.
À partir d'aujourd'hui, le mode IA passe à Gemini 3.5. La nouvelle barre de recherche intelligente commence également à être déployée le jour même. Elle prend en charge la saisie de texte, d'images, de fichiers et de vidéos, et propose des suggestions d'IA lorsque l'utilisateur saisit une question.

Les Aperçus IA et le mode IA sont également fusionnés en une expérience de recherche IA plus continue. L'utilisateur peut d'abord voir une réponse IA sur la page principale des résultats, puis passer en mode IA pour poser des questions de suivi, le contexte étant préservé. Cette nouvelle expérience de recherche est disponible dès le jour de la conférence sur le bureau et les appareils mobiles dans le monde entier.
Le changement le plus important est l'agent de recherche. Cet été, les utilisateurs pourront créer un agent d'information dans la Recherche pour suivre en permanence un certain type d'informations.
Par exemple, un utilisateur peut lui demander de surveiller les actions de biotechnologie de grande capitalisation avec un ratio cours/bénéfice inférieur à 15, une trésorerie positive et un faible niveau d'endettement ; il peut aussi lui faire suivre à long terme des informations de location, des collaborations de sneakers ou le lancement de nouveaux produits. Lorsque les conditions changent, l'Agent enverra une mise à jour synthétique à l'utilisateur.

Google intègre également les capacités de codage agentique d'Antigravity dans la recherche.
À l'avenir, la recherche ne se contentera plus de renvoyer des pages web, des résumés ou des cartes, elle pourra également générer des interfaces interactives pour des questions spécifiques. Par exemple, si un utilisateur demande « comment un trou noir affecte-t-il l'espace-temps », la Recherche peut générer un composant visuel interactif ; en poursuivant avec « comment deux trous noirs génèrent-ils des ondes gravitationnelles », la Recherche regénérera une interface dynamique avec des paramètres ajustables. L'interface utilisateur générative avec Antigravity sera lancée gratuitement pour tous les utilisateurs cet été.

Des expériences personnalisées plus complexes sont également en route.
Google a présenté en direct un planificateur de week-end : la Recherche combinera des informations comme la météo, les cartes, les préférences de l'utilisateur, Gmail, Calendar, pour générer un petit outil que l'on peut continuer à modifier, partager et synchroniser avec le calendrier. Ce type d'expérience personnalisée sera d'abord ouvert aux abonnés dans les prochains mois.
Fonctionne même éteint, Gemini Spark déplace les capacités d'agent dans la vie personnelle
Le nouveau produit le plus important pour les consommateurs est Gemini Spark.

Gemini Spark est un agent IA personnel, fonctionnant sur une machine virtuelle dédiée dans Google Cloud, capable d'exécuter des tâches 24h/24. Il est alimenté par Gemini 3.5 et Antigravity harness, prenant en charge les tâches de fond de longue durée.
Même après avoir éteint l'ordinateur, Spark peut continuer à travailler. Il s'intègre d'abord aux outils de Google, et dans les prochaines semaines, il s'intégrera à des outils tiers via MCP.

La conférence a montré plusieurs scénarios typiques pour Spark.
Un utilisateur peut lui demander de résumer les lancements et avancées de Gemini Live de la semaine écoulée, d'extraire des informations de Docs, Gmail et des historiques de chat, puis de générer un e-mail d'équipe dans son style d'écriture personnel.
Il peut aussi lui faire gérer une fête de quartier, maintenir une feuille Google Sheets des RSVP, suivre qui apporte quoi, générer un brouillon d'e-mail de rappel pour les voisins non-inscrits, et automatiquement créer une page de présentation Google Slides.
Spark prend également en charge la saisie vocale sur mobile.
Les utilisateurs peuvent énoncer plusieurs tâches en une seule fois, comme marquer toutes les réunions avec Sundar en rose vif, écrire une lettre d'invitation aux nouveaux voisins, créer un document de choses à faire avant la fin de l'année scolaire des enfants. Spark divisera ces demandes en plusieurs tâches indépendantes et les exécutera en arrière-plan, les résultats étant synchronisés entre le téléphone et l'ordinateur.
Gemini Spark est ouvert cette semaine à certains testeurs, et sera lancé en version bêta la semaine prochaine pour les abonnés américains Google AI Ultra.

Google lance également un nouveau plan Ultra à 100 dollars par mois, et abaisse le plan Ultra le plus élevé de 250 à 200 dollars par mois.
Plus tard cet été, Spark entrera dans Chrome, devenant un navigateur agent intelligent capable d'exécuter des tâches dans les pages web.

Refonte majeure de l'application Gemini, et le « briefing matinal IA » de Google
L'application Gemini elle-même a également connu une refonte complète.
Google a introduit un nouveau langage de design Neural Expressive, ajoutant des animations fluides, des couleurs vives, de nouvelles polices et un retour haptique.
La nouvelle version de Gemini App ne présente plus les réponses sous forme de longs paragraphes de texte, mais génère en temps réel une mise en page plus adaptée à la lecture et à l'interaction, incluant des images interactives, des frises chronologiques, des vidéos intégrées, etc. Neural Expressive est désormais déployé mondialement sur Android, iOS et le web.
Gemini Live a également été refait, permettant d'entrer directement dans une conversation en temps réel lorsqu'on l'ouvre. La sélection d'accents régionaux sera proposée dans les prochaines semaines.
L'application Gemini ajoute aussi Daily Brief. C'est un agent de résumé personnalisé pour le matin, qui synthétise les informations de Gmail, Calendar, Tasks, etc., pour organiser les éléments à surveiller dans la journée et fournir des entrées pour les prochaines actions.
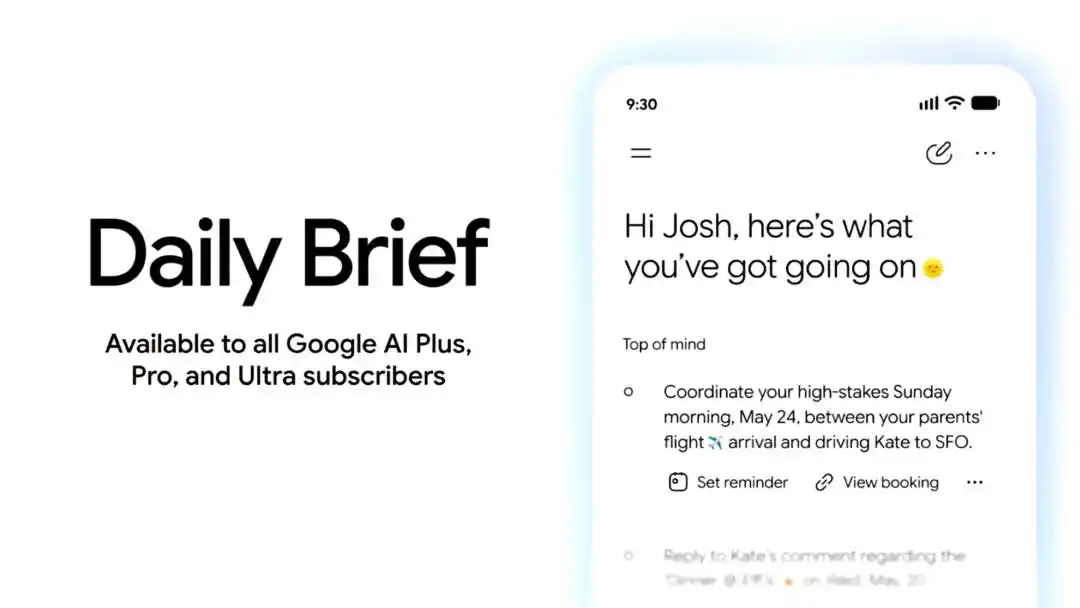
Daily Brief est lancé dès aujourd'hui pour les abonnés américains Google AI Plus, Pro et Ultra.
Au-delà du récit plus large de Gemini, Google a également mis à jour plusieurs produits du quotidien.
Google Maps vient de connaître sa plus grande mise à jour en dix ans, et intègre désormais Ask Maps. Il permet aux utilisateurs de poser des questions plus longues et complexes. Par exemple, la conférence a présenté un scénario : un enfant tombe dans un étang à canards, un mariage commence dans 30 minutes, l'utilisateur veut savoir où il peut acheter une nouvelle robe à pied.

Docs reçoit également une nouvelle capacité de création vocale. L'utilisateur n'a pas besoin de saisir des instructions précises, il peut simplement exprimer ses idées à l'oral, demander à Gemini d'extraire un CV de Drive, de trouver des informations sur un événement dans Gmail, puis de générer un brouillon Google Docs. Cette capacité sera lancée cet été pour les abonnés Pro et Ultra, des capacités vocales similaires arriveront également dans Gmail.
Avec l'amélioration des capacités de génération, l'identification des sources de contenu devient de plus en plus importante.
Google déclare que depuis son lancement il y a trois ans, SynthID a ajouté des filigranes invisibles à plus de 100 milliards d'images et vidéos, ainsi qu'à l'équivalent de 60 000 années de contenu audio. Prochainement, SynthID et la vérification des contenus s'étendront à la Recherche et à Chrome.

Les utilisateurs pourront effectuer une recherche par cadre, ou cliquer avec le bouton droit dans Chrome pour demander si un contenu a été généré par IA, le système indiquant si le contenu provient de l'IA, d'une caméra, ou a été édité par des outils d'IA générative.
Google annonce également qu'OpenAI, Kakao et ElevenLabs adopteront SynthID 2. Nvidia avait précédemment rejoint l'écosystème SynthID. Pour Google, SynthID n'est pas seulement une fonctionnalité de sécurité, mais aussi une partie de la lutte pour des standards de transparence du contenu IA.

La suite créative de Google commence à assaillir les images, le design et la vidéo
Dans le domaine des outils créatifs, Google a lancé de manière intensive plusieurs produits majeurs.
Google Pics est un nouveau produit de création et d'édition d'images dans Google Workspace, destiné à des scénarios comme des affiches de fête, des infographies, des visuels promotionnels. Les utilisateurs peuvent partir d'une image de base, supprimer des éléments, redimensionner des objets, éditer et traduire du texte. Le contenu généré par Pics portera un filigrane SynthID. Google Pics sera lancé cet été.

Le produit de design Stitch est également mis à jour. L'utilisateur peut générer une interface de site web ou d'application avec une seule instruction, puis continuer à la modifier par texte ou voix, par exemple pour agrandir un titre, ajuster un menu, mettre en avant plus d'options de pizza. Stitch permet d'exporter le design en code, ou de publier directement le site, les mises à jour correspondantes sont désormais disponibles.

Les mises à jour de Google Flow sont particulièrement remarquées. Une fois Gemini Omni intégré à Flow, les utilisateurs pourront modifier l'environnement d'une vidéo originale, ajouter des effets visuels, intégrer de nouveaux personnages, tout en préservant au maximum la performance d'origine.
Flow ajoute également un nouvel Agent, capable d'exécuter plusieurs actions en une fois. Par exemple, générer 16 vidéos avec des angles de vue différents à partir d'une seule image, ou transformer un ensemble de scènes matinales en scènes nocturnes par lots.

Flow Tools permet aux utilisateurs de créer leurs propres outils créatifs dans Flow, comme des effets vidéo, des animations dessinées à la main et des outils de superposition de texte, avec prise en charge du partage et du remix.
Google Flow Music peut étendre un riff de piano en une démo musicale avec une orientation stylistique. Ces nouvelles fonctionnalités de Google Flow et Google Flow Music sont désormais disponibles.
Parier sur les lunettes intelligentes, Google tente à nouveau la prochaine interface
Dans la partie matériel, Google étend également Android XR, cette plateforme de niveau système d'exploitation, des casques et appareils XR aux lunettes intelligentes.
Android XR est une plateforme développée par Google en collaboration avec Samsung et optimisée pour Qualcomm Snapdragon.

Google indique que les lunettes IA se diviseront en deux catégories : l'une avec de petites lentilles d'affichage, l'autre des lunettes audio. Les lunettes d'affichage avaient été présentées l'année dernière lors de l'I/O, et cette année, les premiers développeurs ont commencé à créer des expériences d'affichage, le programme de testeurs de confiance sera étendu plus tard dans l'année.
Les lunettes audio arriveront plus tôt sur le marché.
Les premières lunettes audio seront lancées cet automne, avec Samsung participant à la construction du matériel et des expériences, et Warby Parker et Gentle Monster en charge de la conception des lunettes. Ces lunettes se connectent au téléphone et prennent en charge Android et iOS. Les réponses de Gemini sont diffusées de manière privée via des écouteurs, et non affichées sur les verres.

Lors de la conférence, le démonstrateur pouvait demander à Gemini, via les lunettes, de le guider vers l'endroit où il avait rencontré des amis la semaine dernière, avec un arrêt café en cours de route ; il pouvait aussi demander à Gemini d'ouvrir DoorDash pour commander automatiquement un café, en attendant la confirmation de l'utilisateur ;
il pouvait également lui demander de résumer les messages silencieux et d'écrire un dîner familial dans le calendrier. Les lunettes peuvent aussi fonctionner avec une montre, permettant à l'utilisateur de prendre une photo sur place, de générer une image cartoonesque avec Nano Banana, puis de la prévisualiser sur la montre.
À la fin de la conférence, les cas d'utilisation de Gemini se sont également étendus à la cybersécurité.
Google a présenté CodeMender. C'est un agent de sécurité du code, capable de détecter et de corriger automatiquement les vulnérabilités critiques des logiciels. Google invitera un groupe d'experts à tester l'API CodeMender, avant de le proposer plus largement.

Dans l'ensemble, la quantité d'informations présentée lors de cette conférence était telle qu'elle en donnait presque le souffle coupé. Mais lorsque ces fonctionnalités IA seront réellement ouvertes à des dizaines, voire des centaines de millions d'utilisateurs, la question la plus concrète se posera directement : Comment Google va-t-il rentabiliser cette énorme dépense en puissance de calcul ?
Au cours des vingt dernières années, Google représentait un modèle typique d'Internet gratuit. Les utilisateurs échangent leur attention et leurs données contre des services, et Google gagne de l'argent grâce à la publicité et la distribution. Ce modèle a fait de Google l'entreprise d'infrastructure la plus puissante de l'ère d'Internet.
Cependant, le coût de l'inférence des grands modèles n'est absolument pas du même ordre de grandeur qu'une simple requête de recherche.
La mémoire contextuelle longue, la génération multimodale, les agents inter-applications, l'automatisation de niveau entreprise, toutes ces capacités nécessitent une consommation de puissance de calcul en fonctionnement continu. Plus l'IA s'approfondit, plus il est difficile pour Google de continuer à absorber les coûts via des « mises à niveau gratuites ».
C'est pourquoi, tout au long de la conférence, Google I/O semblait parler d'améliorations d'expérience, mais pointait en réalité vers des abonnements, des contrats d'entreprise, des factures de calcul et des frais de service à long terme.

Les portes d'entrée gratuites ne disparaîtront bien sûr pas, car elles restent la base pour que Google obtienne des utilisateurs, des données et une position dans l'écosystème. Mais au-dessus de ces portes d'entrée, Google superpose une nouvelle couche de services intelligents : des modèles plus puissants, une mémoire plus longue, des autorisations système plus profondes, une exécution de tâches plus complexes, et des services de niveau entreprise plus stables.
En d'autres termes, Google est en train de passer d'une entreprise de services Internet gratuits à une entreprise d'infrastructure d'abonnement IA.
Mais une question se pose alors : les utilisateurs sont-ils prêts à payer pour la recherche ? En règle générale, non.
Cependant, si c'est un « assistant super polyvalent » qui peut gérer vos e-mails 24h/24, coordonner vos tâches, analyser vos rapports, prendre en charge votre domotique, et même vous aider à coder et développer des applications ? Seriez-vous prêt à dépenser plusieurs dizaines, voire une centaine de dollars par mois pour cela ?
C'est précisément la proposition commerciale centrale que Google I/O de cette année cherche désespérément à valider. Et en regardant le marché actuel en pleine effervescence, la réponse semble déjà aller de soi.
Cet article provient du compte public WeChat « APPSO », auteur : Découvrir les produits de demain






