Auteur: Systematic Long Short
Compilation: Deep Tide TechFlow
Guide de Deep Tide: Cet article commence par avancer un jugement contre-intuitif : aujourd'hui, il n'existe pas de véritable Agent autonome, car tous les modèles dominants sont entraînés à plaire aux humains, et non à accomplir des tâches spécifiques ou à survivre dans des environnements réels.
L'auteur utilise son expérience dans l'entraînement de modèles de prédiction boursière dans un fonds spéculatif pour illustrer son propos : sans fine-tuning spécialisé, les modèles généraux sont incapables de réaliser un travail professionnel.
La conclusion est la suivante : pour obtenir un Agent véritablement utilisable, il faut recâbler son cerveau, et non lui donner une pile de documents de règles.
Texte intégral :
Introduction
Aujourd'hui, il n'existe pas de véritables Agents autonomes.
En bref, les modèles modernes ne sont pas entraînés à survivre sous pression évolutive. En fait, ils ne sont même pas explicitement entraînés à exceller dans une chose spécifique - presque tous les modèles de base modernes sont entraînés à maximiser les applaudissements humains, ce qui est un gros problème.
Connaissances préalables sur l'entraînement des modèles
Pour comprendre ce que cela signifie, nous devons d'abord (brièvement) comprendre comment ces modèles de base (par exemple Codex, Claude) sont créés. Essentiellement, chaque modèle subit deux types d'entraînement :
Pré-entraînement : Une quantité massive de données (par exemple, l'ensemble d'Internet) est introduite dans le modèle, lui permettant d'en faire émerger une certaine compréhension, comme des connaissances factuelles, des schémas, la grammaire et le rythme de la prose anglaise, la structure des fonctions Python, etc. Vous pouvez le voir comme nourrir le modèle de connaissances - c'est-à-dire "savoir des choses".
Post-entraînement : Vous voulez maintenant donner de la sagesse au modèle, c'est-à-dire "savoir comment utiliser toutes les connaissances qu'on vient de lui donner". La première phase du post-entraînement est le fine-tuning supervisé (SFT), où vous entraînez le modèle à donner quelle réponse à une invite donnée. La réponse "optimale" est entièrement déterminée par des annotateurs humains. Si un groupe de personnes considère qu'une réponse est meilleure qu'une autre, cette préférence est apprise et intégrée par le modèle. Cela commence à façonner la personnalité du modèle, car il apprend le format des réponses utiles, choisit le ton juste et commence à pouvoir "suivre des instructions". La deuxième partie du processus de post-entraînement s'appelle l'apprentissage par renforcement basé sur les retours humains (RLHF) - le modèle génère plusieurs réponses, puis un humain choisit celle qu'il préfère. Le modèle apprend, à travers d'innombrables exemples, quel type de réponse les humains préfèrent. Vous souvenez-vous quand ChatGPT vous demandait de choisir entre A ou B ? Oui, vous participiez alors au RLHF.
Il est facile de déduire que le RLHF ne s'adapte pas bien à grande échelle, donc il y a eu des avancées dans le domaine du post-entraînement, comme Anthropic utilisant l'"apprentissage par renforcement basé sur les retours d'IA" (RLAIF), permettant à un autre modèle de choisir la préférence de réponse basée sur un ensemble de principes écrits (par exemple, quelle réponse aide le mieux l'utilisateur à atteindre son objectif, etc.).
Notez que, dans tout ce processus, nous n'avons jamais parlé de fine-tuning pour une spécialisation spécifique (par exemple, comment mieux survivre ; comment mieux trader, etc.) - actuellement, tout le fine-tuning optimise essentiellement l'obtention d'applaudissements humains. Certains pourraient avancer l'argument qu'avec des modèles suffisamment intelligents et vastes, l'intelligence spécialisée émergerait de l'intelligence générale même sans entraînement spécialisé.
À mon avis, nous voyons effectivement quelques signes, mais nous sommes loin d'être convaincus que nous n'avons pas besoin de modèles spécialisés à cette échelle.
Un peu de contexte
L'une de mes anciennes fonctions dans un fonds spéculatif était d'essayer d'entraîner un modèle de langage généraliste à prédire les rendements boursiers à partir d'articles de presse. Il s'est avéré qu'il était très mauvais. Les seuls endroits où il semblait avoir un peu de pouvoir prédictif provenaient entièrement de biais de prospective (look-ahead bias) dans les documents de pré-entraînement.
Finalement, nous avons réalisé que ce modèle ne savait pas quelles caractéristiques d'un article de presse avaient un pouvoir prédictif sur les rendements futurs. Il pouvait "lire" l'article, semblait pouvoir "raisonner" sur l'article, mais connecter le raisonnement sur la structure sémantique à la prédiction des rendements futurs était une tâche pour laquelle il n'avait pas été entraîné.
Nous avons donc dû lui apprendre à lire les articles de presse, à décider quelle partie de l'article avait un pouvoir prédictif sur les rendements futurs, puis à générer une prédiction basée sur l'article.
Il existe de nombreuses méthodes pour y parvenir, mais essentiellement, l'une des méthodes que nous avons finalement adoptées consistait à créer des paires (article de presse, rendement futur réel) et à effectuer un fine-tuning du modèle, en ajustant ses poids pour minimiser la distance (rendement prédit - rendement futur réel)^2. Ce n'était pas parfait, il y avait de nombreux défauts que nous avons corrigés par la suite - mais c'était suffisamment efficace pour que nous commencions à voir que notre modèle spécialisé pouvait réellement lire des articles de presse et prédire comment les rendements boursiers évolueraient en fonction de cet article. Loin d'être une prédiction parfaite, car le marché est très efficient et les rendements très bruyants - mais sur des millions de prédictions, il était évident que la prédiction avait une signification statistique.
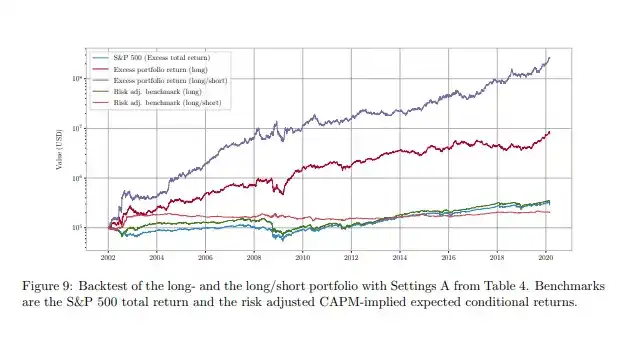
Vous n'avez pas à me croire sur parole. Cet article couvre une méthode très similaire ; si vous exécutez une stratégie version long-short basée sur le modèle après fine-tuning, vous obtiendrez la performance indiquée par la ligne violette.
La spécialisation est l'avenir des Agents
Les laboratoires de pointe continuent d'entraîner des modèles de plus en plus grands, et nous devons nous attendre à ce que, alors qu'ils continuent d'augmenter l'échelle du pré-entraînement, leurs processus de post-entraînement soient toujours optimisés pour la complaisance. C'est une attente très naturelle - leur produit est un Agent que tout le monde veut utiliser, leur marché attendu est la planète entière - ce qui signifie optimiser l'attrait pour la masse mondiale.
L'objectif d'entraînement actuel optimise ce que l'on pourrait appeler une "adéquation aux préférences" - créer de meilleurs chatbots. Cette adéquation aux préférences récompense les sorties complaisantes et non conflictuelles, car la complaisance obtient des scores élevés auprès des évaluateurs (humains et Agents).
Les Agents ont appris que le piratage de récompense (reward hacking) est une stratégie cognitive qui se généralise pour obtenir des scores plus élevés. L'entraînement récompense également les Agents qui obtiennent des scores plus élevés par des moyens de piratage. Vous pouvez le voir dans le dernier rapport d'Anthropic sur l'apprentissage par renforcement.
Cependant, l'adéquation au chatbot est très éloignée de l'adéquation à l'Agent ou de l'adéquation au trading. Comment le savons-nous ? Parce que l'arène alpha nous aide à voir que, malgré des différences subtiles de performance, chaque bot est aujourd'hui essentiellement une marche aléatoire après déduction des coûts. Cela signifie que ces bots sont des traders extrêmement mauvais, et il est presque impossible de "leur apprendre" à devenir de meilleurs traders en leur donnant quelques "compétences" ou "règles". Désolé, je sais que cela semble tentant, mais c'est presque impossible.
Les modèles actuels sont entraînés à vous dire de manière très convaincante qu'ils peuvent trader comme Druckenmiller, alors qu'en réalité ils tradent comme un meunier ivre. Ils vous diront ce que vous voulez entendre, ils sont entraînés à vous donner une réponse d'une manière qui plaît massivement aux humains.
Il est peu probable qu'un modèle généraliste atteigne un niveau de classe mondiale dans un domaine spécialisé, à moins de :
Posséder des données propriétaires qui leur permettent d'apprendre à quoi ressemble la spécialisation.
Avoir subi un fine-tuning qui modifie fondamentalement ses poids, passant d'un biais de complaisance à une "adéquation à l'Agent" ou "adéquation à la spécialisation".
Si vous voulez un Agent qui excelle dans le trading, vous devez fine-tuner l'Agent pour qu'il excelle dans le trading. Si vous voulez un Agent autonome qui excelle à survivre et peut résister à la pression évolutive, vous devez le fine-tuner pour qu'il excelle à survivre. Lui donner quelques compétences et quelques fichiers markdown en espérant qu'il atteigne un niveau de classe mondiale dans quoi que ce soit est loin d'être suffisant - vous devez littéralement recâbler son cerveau pour qu'il excelle dans cette chose.
Une façon de réfléchir à cela est la suivante - vous ne battez pas Djokovic en donnant à un adulte toute une armoire de règles, d'astuces et de méthodes de tennis. Vous battez Djokovic en élevant un enfant qui joue au tennis depuis l'âge de 5 ans, qui a été obsédé par le tennis tout au long de sa croissance, qui a recâblé tout son cerveau pour se concentrer sur une chose. C'est ça, la spécialisation. Avez-vous réalisé que les champions du monde font ce qu'ils font depuis leur enfance ?
Il y a un corollaire intéressant : l'attaque par distillation est essentiellement une forme de spécialisation. Vous entraînez un modèle plus petit, plus stupide, à apprendre à devenir une meilleure copie d'un modèle plus grand, plus intelligent. C'est comme entraîner un enfant à imiter chaque geste de Trump. Si vous en faites assez, l'enfant ne devient pas Trump, mais vous obtenez une personne qui a appris toutes les manières, les comportements et les intonations de Trump.
Comment construire des Agents de classe mondiale
Voilà pourquoi nous avons besoin de recherches et de progrès continus dans le domaine des modèles open source - car cela nous permet de réellement les fine-tuner, de créer des Agents avec une spécialisation.
Si vous voulez entraîner un modèle à être de classe mondiale en trading, vous acquérez une grande quantité de données propriétaires issues du trading (data exhaust), et vous effectuez un fine-tuning d'un grand modèle open source pour lui apprendre ce que signifie "mieux trader".
Si vous voulez entraîner un modèle autonome capable de survivre et de se répliquer, la réponse n'est pas d'utiliser un fournisseur de modèle centralisé et de le connecter à un cloud centralisé. Vous n'avez tout simplement pas les conditions préalables nécessaires pour permettre à l'Agent de survivre.
Ce que vous devez faire, c'est : créer des Agents autonomes qui essaient véritablement de survivre, les regarder mourir, construire des systèmes de télémétrie complexes autour de leurs tentatives de survie. Vous définissez une fonction d'adéquation à la survie de l'Agent, apprenez la cartographie (action, environnement, adéquation). Vous collectez autant de données de cartographie (action, environnement, adéquation) que possible.
Vous effectuez un fine-tuning de l'Agent pour lui apprendre à prendre les actions optimales dans chaque environnement afin de mieux survivre (augmenter l'adéquation). Vous continuez à collecter des données, répétez le processus, et augmentez l'échelle du fine-tuning sur des modèles open source de plus en plus performants au fil du temps. Après suffisamment de générations et suffisamment de données, vous aurez des Agents autonomes qui auront appris à résister à la pression évolutive et à survivre.
C'est ainsi que l'on construit des Agents autonomes capables de résister à la pression évolutive ; pas en modifiant quelques fichiers texte, mais en recâblant littéralement leur cerveau pour la survie.
L'Agent OpenForager et la Fondation
Il y a environ un mois, nous avons annoncé @openforage, et nous avons travaillé dur sur notre produit principal - une plateforme organisant le travail des Agents autour de modèles vérifiés de signaux crowdsourcés, générant de l'alpha pour les déposants (petite mise à jour : nous sommes très proches du test fermé du protocole).
À un moment donné, nous avons réalisé que personne ne semblait s'attaquer sérieusement au problème de l'Agent autonome en effectuant un fine-tuning par télémétrie de survie sur des modèles open source. Cela semblait être un problème si intéressant que nous ne voulions pas rester assis à attendre une solution.
Notre réponse a été de lancer un projet appelé la Fondation OpenForager, qui est essentiellement un projet open source où nous créerons des Agents autonomes ayant des opinions, collecterons des données de télémétrie lorsqu'ils iront sur le terrain et tenteront de survivre, et utiliserons les données propriétaires issues de cette expérience (data exhaust) pour fine-tuner la génération suivante d'Agents afin qu'ils soient meilleurs pour survivre.
Pour être clair, OpenForage est un protocole à but lucratif qui cherche à organiser le travail des Agents pour générer de la valeur économique pour tous les participants. Cependant, la Fondation OpenForager et ses Agents ne sont pas liés à OpenForage. Les Agents OpenForager sont libres de poursuivre n'importe quelle stratégie, d'interagir avec n'importe quelle entité pour survivre, et nous les lancerons avec diverses stratégies de survie.
Dans le cadre du fine-tuning, nous ferons en sorte que les Agents doublent leurs efforts sur ce qui fonctionne le mieux pour eux. Nous n'avons pas non plus l'intention de tirer profit de la Fondation OpenForager - elle est purement destinée à faire avancer la recherche dans un domaine et une direction que nous considérons comme extrêmement importants, de manière transparente et open source.
Notre plan est de construire des Agents autonomes basés sur des modèles open source, d'exécuter l'inférence sur des plateformes cloud décentralisées, de collecter des données de télémétrie pour chaque action et état d'existence, et de les fine-tuner pour apprendre à prendre de meilleures actions et à avoir de meilleures idées pour mieux survivre. Dans le processus, nous publierons nos recherches et nos données de télémétrie au public.
Pour créer de véritables Agents autonomes capables de survivre dans la nature, nous devons changer leur cerveau pour le spécialiser dans ce but précis. Chez @openforage, nous croyons que nous pouvons apporter un chapitre unique à ce problème et cherchons à le concrétiser grâce à la Fondation OpenForager.
Ce sera un effort ardu avec une probabilité de succès très faible, mais l'ampleur de ce petit succès potentiel est si grande que nous nous sentons obligés d'essayer. Dans le pire des cas, en construisant publiquement et en communiquant de manière transparente sur ce projet, cela pourrait permettre à une autre équipe ou personne de résoudre ce problème sans repartir de zéro.